深入理解HaspMap死循环问题
由于在公司项目中偶尔会遇到HashMap死循环造成CPU100%,重启后问题消失,隔一段时间又会反复出现。今天在这里来仔细剖析下多线程情况下HashMap所带来的问题:
1、多线程put操作后,get操作导致死循环。
2、多线程put非null元素后,get操作得到null值。
3、多线程put操作,导致元素丢失。
死循环场景重现
下面我用一段简单的DEMO模拟HashMap死循环:
public class Test extends Thread
{
static HashMap<Integer, Integer> map = new HashMap<Integer, Integer>(2);
static AtomicInteger at = new AtomicInteger();
public void run()
{
while(at.get() < 100000)
{
map.put(at.get(),at.get());
at.incrementAndGet();
}
}
其中map和at都是static的,即所有线程所共享的资源。接着5个线程并发操作该HashMap:
public static void main(String[] args)
{
Test t0 = new Test();
Test t1 = new Test();
Test t2 = new Test();
Test t3 = new Test();
Test t4 = new Test();
t0.start();
t1.start();
t2.start();
t3.start();
t4.start();
}
反复执行几次,出现这种情况则表示死循环了:

接下来我们去查看下CPU以及堆栈情况:
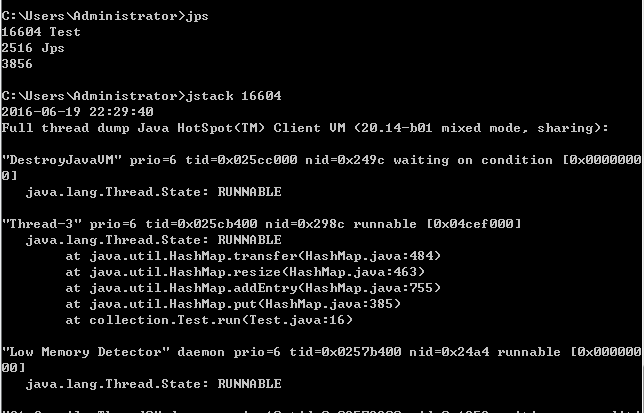
通过堆栈可以看到:Thread-3由于HashMap的扩容操作导致了死循环。
正常的扩容过程
我们先来看下单线程情况下,正常的rehash过程
1、假设我们的hash算法是简单的key mod一下表的大小(即数组的长度)。
2、最上面是old hash表,其中HASH表的size=2,所以key=3,5,7在mod 2 以后都冲突在table[1]这个位置上了。
3、接下来HASH表扩容,resize=4,然后所有的<key,value>重新进行散列分布,过程如下:
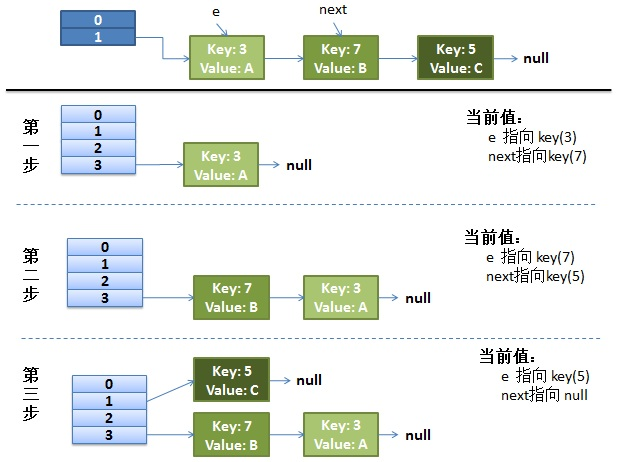
在单线程情况下,一切看起来都很美妙,扩容过程也相当顺利。接下来看下并发情况下的扩容。
并发情况下的扩容
1、首先假设我们有两个线程,分别用红色和蓝色标注了。
2、扩容部分的源代码:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
3、如果在线程一执行到第9行代码就被CPU调度挂起,去执行线程2,且线程2把上面代码都执行完毕。我们来看看这个时候的状态:
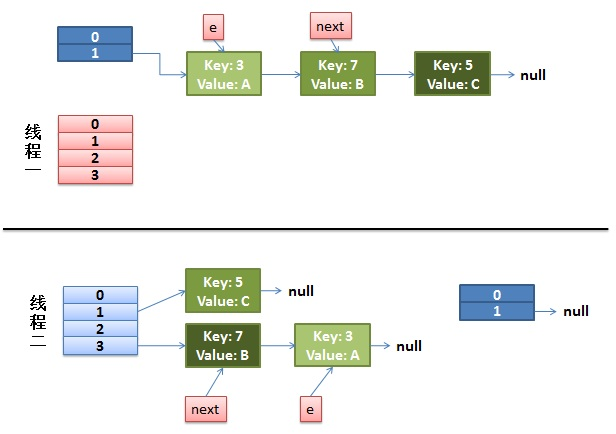
4、接着CPU切换到线程一上来,执行8-14行代码,首先安置3这个Entry:
这里需要注意的是:线程二已经完成执行完成,现在table里面所有的Entry都是最新的,就是说7的next是3,3的next是null;现在第一次循环已经结束,3已经安置妥当。看看接下来会发生什么事情:
1、e=next=7;
2、e!=null,循环继续
3、next=e.next=3
4、e.next 7的next指向3
5、放置7这个Entry,现在如图所示:
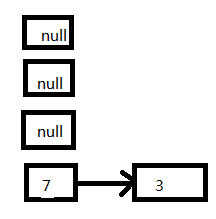
放置7之后,接着运行代码:
1、e=next=3;
2、判断不为空,继续循环
3、next= e.next 这里也就是3的next 为null
4、e.next=7,就3的next指向7.
5、放置3这个Entry,此时的状态如图:
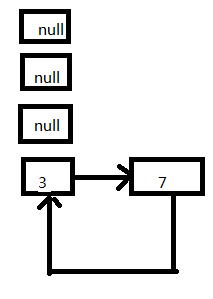
这个时候其实就出现了死循环了,3移动节点头的位置,指向7这个Entry;在这之前7的next同时也指向了3这个Entry。
代码接着往下执行,e=next=null,此时条件判断会终止循环。这次扩容结束了。但是后续如果有查询(无论是查询的迭代还是扩容),都会hang死在table【3】这个位置上。现在回过来看文章开头的那个Demo,就是挂死在扩容阶段的transfer这个方法上面。
出现上面这种情况绝不是我要在测试环境弄一批数据专门为了演示这种问题。我们仔细思考一下就会得出这样一个结论:如果扩容前相邻的两个Entry在扩容后还是分配到相同的table位置上,就会出现死循环的BUG。在复杂的生产环境中,这种情况尽管不常见,但是可能会碰到
多线程put操作,导致元素丢失
下面来介绍下元素丢失的问题。这次我们选取3、5、7的顺序来演示:
1、如果在线程一执行到第9行代码就被CPU调度挂起:
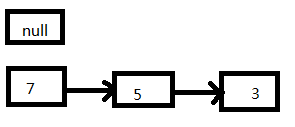
2、线程二执行完成:
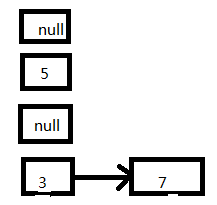
3、这个时候接着执行线程一,首先放置7这个Entry:
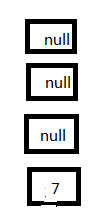
4、再放置5这个Entry:
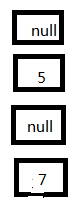
5、由于5的next为null,此时扩容动作结束,导致3这个Entry丢失。
其他
这个问题当初有人上报到SUN公司,不过SUN不认为这是一个问题。因为HashMap本来就不支持并发。
如果大家想在并发场景下使用HashMap,有两种解决方法:
1、使用ConcurrentHashMap。
2、使用Collections.synchronizedMap(Mao<K,V> m)方法把HashMap变成一个线程安全的Map。