转载1:https://blog.csdn.net/WZZ18191171661/article/details/79494534
转载2:https://zhuanlan.zhihu.com/p/42745788
转载3:https://github.com/unsky/FPN/blob/master/models/pascal_voc/FPN/FP_Net_end2end/train.prototxt
论文题目:Feature Pyramid Networks for Object Detection
论文链接:论文链接
论文代码:Caffe版本代码链接
1. 骨干架构(FPN)
卷积网络的一个重要特征:深层网络容易响应语义特征,浅层网络容易响应图像特征。但是到了物体检测领域,这个特征便成了一个重要的问题,高层网络虽然能响应语义特征,但是由于Feature Map的尺寸较小,含有的几何信息并不多,不利于物体检测;浅层网络虽然包含比较多的几何信息,但是图像的语义特征并不多,不利于图像的分类,这个问题在小尺寸物体检测上更为显著和,这也就是为什么物体检测算法普遍对小物体检测效果不好的最重要原因之一。很自然地可以想到,使用合并了的深层和浅层特征来同时满足分类和检测的需求。
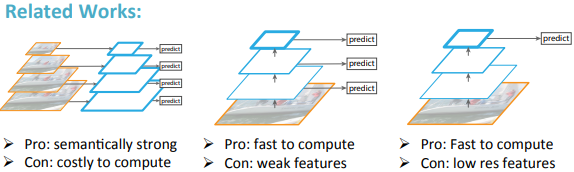
FPN使用的是图像金字塔的思想以解决物体检测场景中小尺寸物体检测困难的问题,传统的图像金字塔方法(图1.a)采用输入多尺度图像的方式构建多尺度的特征,该方法的最大问题便是识别时间为单幅图的k倍,其中k是缩放的尺寸个数。Faster R-CNN等方法为了提升检测速度,使用了单尺度的Feature Map(图1.b),但单尺度的特征图限制了模型的检测能力,尤其是训练集中覆盖率极低的样本(例如较大和较小样本)。不同于Faster R-CNN只使用最顶层的Feature Map,SSD[6]利用卷积网络的层次结构,从VGG的第conv4_3开始,通过网络的不同层得到了多尺度的Feature Map(图1.c),该方法虽然能提高精度且基本上没有增加测试时间,但没有使用更加低层的Feature Map,然而这些低层次的特征对于检测小物体是非常有帮助的。
针对上面这些问题,FPN采用了SSD的金字塔内Feature Map的形式。与SSD不同的是,FPN不仅使用了VGG中层次深的Feature Map,并且浅层的Feature Map也被应用到FPN中。并通过自底向上(bottom-up),自顶向下(top-down)以及横向连接(lateral connection)将这些Feature Map高效的整合起来,在提升精度的同时并没有大幅增加检测时间(图1.d)。
通过将Faster R-CNN的RPN和Fast R-CNN的骨干框架换成FPN,Faster R-CNN的平均精度从51.7%提升到56.9%。
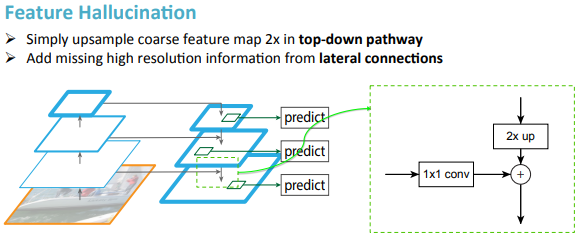

残差网络得到的C1-C5由于经历了不同的降采样次数,所以得到的Feature Map的尺寸也不同。为了提升计算效率,首先FPN使用 进行了降维,得到P5,然后使用双线性插值进行上采样,将P5上采样到和C4相同的尺寸。
之后,FPN也使用 卷积对P4进行了降维,由于降维并不改变尺寸大小,所以P5和P4具有相同的尺寸,FPN直接把P5单位加到P4得到了更新后的P4。基于同样的策略,我们使用P4更新P3,P3更新P2。这整个过程是从网络的顶层向下层开始更新的,所以叫做自顶向下路径。
FPN使用单位加的操作来更新特征,这种单位加操作叫做横向连接。由于使用了单位加,所以P2,P3,P4,P5应该具有相同数量的Feature Map(源码中该值为256),所以FPN使用了 卷积进行降维。
在更新完Feature Map之后,FPN在P2,P3,P4,P5之后均接了一个 卷积操作(通道数为512,代码片段1第22-25行),该卷积操作是为了减轻上采样的混叠效应(aliasing effect)。

不同尺度的ROI,使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?这里作者定义了一个系数Pk,其定义为:
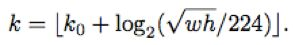
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
FPN的代码出现在./mrcnn/model.py中,核心代码如下:
# Build the shared convolutional layers. # Bottom-up Layers # Returns a list of the last layers of each stage, 5 in total. # Don't create the thead (stage 5), so we pick the 4th item in the list. if callable(config.BACKBONE): _, C2, C3, C4, C5 = config.BACKBONE(input_image, stage5=True, train_bn=config.TRAIN_BN) else: _, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE, stage5=True, train_bn=config.TRAIN_BN) # Top-down Layers # TODO: add assert to varify feature map sizes match what's in config P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5) P4 = KL.Add(name="fpn_p4add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5), KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)]) P3 = KL.Add(name="fpn_p3add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4), KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)]) P2 = KL.Add(name="fpn_p2add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3), KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)]) # Attach 3x3 conv to all P layers to get the final feature maps. P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2) P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3) P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4) P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5) # P6 is used for the 5th anchor scale in RPN. Generated by # subsampling from P5 with stride of 2. P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5) # Note that P6 is used in RPN, but not in the classifier heads. rpn_feature_maps = [P2, P3, P4, P5, P6] mrcnn_feature_maps = [P2, P3, P4, P5]
1.1 自底向上路径
自底向上方法反映在上面代码的第6行或者第8行,自底向上即是卷积网络的前向过程,在Mask R-CNN中,用户可以根据配置文件选择使用ResNet-50或者ResNet-101。代码中的resnet_graph就是一个残差块网络,其返回值C2,C3,C4,C5,是每次池化之后得到的Feature Map,该函数也实现在./mrcnn/model.py中(代码片段2)。需要注意的是在残差网络中,C2,C3,C4,C5经过的降采样次数分别是2,3,4,5即分别对应原图中的步长分别是4,8,16,32。这里之所以没有使用C1,是考虑到由于C1的尺寸过大,训练过程中会消耗很多的显存。
def resnet_graph(input_image, architecture, stage5=False, train_bn=True): """Build a ResNet graph. architecture: Can be resnet50 or resnet101 stage5: Boolean. If False, stage5 of the network is not created train_bn: Boolean. Train or freeze Batch Norm layres """ assert architecture in ["resnet50", "resnet101"] # Stage 1 x = KL.ZeroPadding2D((3, 3))(input_image) x = KL.Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True)(x) x = BatchNorm(name='bn_conv1')(x, training=train_bn) x = KL.Activation('relu')(x) C1 = x = KL.MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x) # Stage 2 x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1), train_bn=train_bn) x = identity_block(x, 3, [64, 64, 256], stage=2, block='b', train_bn=train_bn) C2 = x = identity_block(x, 3, [64, 64, 256], stage=2, block='c', train_bn=train_bn) # Stage 3 x = conv_block(x, 3, [128, 128, 512], stage=3, block='a', train_bn=train_bn) x = identity_block(x, 3, [128, 128, 512], stage=3, block='b', train_bn=train_bn) x = identity_block(x, 3, [128, 128, 512], stage=3, block='c', train_bn=train_bn) C3 = x = identity_block(x, 3, [128, 128, 512], stage=3, block='d', train_bn=train_bn) # Stage 4 x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a', train_bn=train_bn) block_count = {"resnet50": 5, "resnet101": 22}[architecture] for i in range(block_count): x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i), train_bn=train_bn) C4 = x # Stage 5 if stage5: x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a', train_bn=train_bn) x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b', train_bn=train_bn) C5 = x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c', train_bn=train_bn) else: C5 = None return [C1, C2, C3, C4, C5]
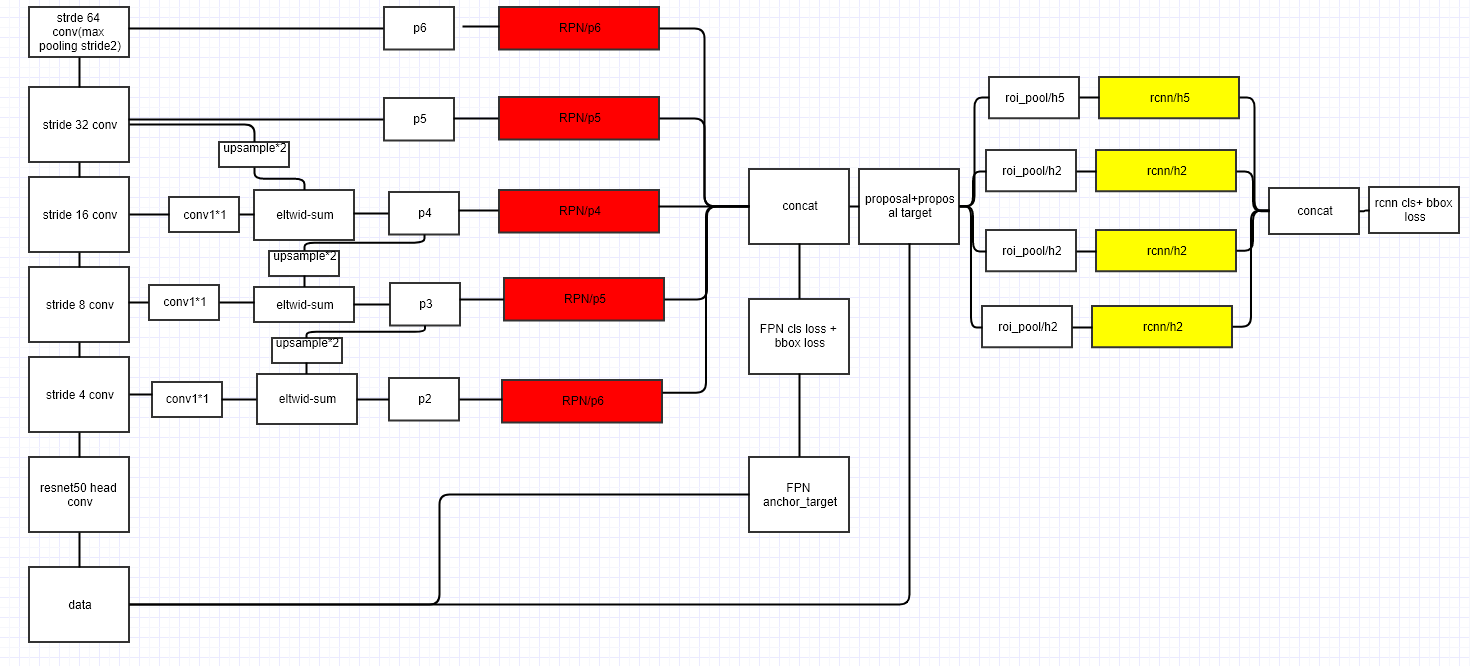
Caffe网络结构图,可以使用netron工具查看进一步细节(https://github.com/unsky/FPN/blob/master/models/pascal_voc/FPN/FP_Net_end2end/train.prototxt):
name: "ResNet-50" layer { name: 'input-data' type: 'Python' top: 'data' top: 'im_info' top: 'gt_boxes' python_param { module: 'roi_data_layer.layer' layer: 'RoIDataLayer' param_str: "'num_classes': 21" } } layer { bottom: "data" top: "conv1" name: "conv1" type: "Convolution" convolution_param { num_output: 64 kernel_size: 7 pad: 3 stride: 2 } } layer { bottom: "conv1" top: "conv1" name: "bn_conv1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "conv1" top: "conv1" name: "scale_conv1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "conv1" top: "conv1" name: "conv1_relu" type: "ReLU" } layer { bottom: "conv1" top: "pool1" name: "pool1" type: "Pooling" pooling_param { kernel_size: 3 stride: 2 pool: MAX } } layer { bottom: "pool1" top: "res2a_branch1" name: "res2a_branch1" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2a_branch1" top: "res2a_branch1" name: "bn2a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch1" top: "res2a_branch1" name: "scale2a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "pool1" top: "res2a_branch2a" name: "res2a_branch2a" type: "Convolution" convolution_param { num_output: 64 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2a_branch2a" top: "res2a_branch2a" name: "bn2a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch2a" top: "res2a_branch2a" name: "scale2a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a_branch2a" top: "res2a_branch2a" name: "res2a_branch2a_relu" type: "ReLU" } layer { bottom: "res2a_branch2a" top: "res2a_branch2b" name: "res2a_branch2b" type: "Convolution" convolution_param { num_output: 64 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res2a_branch2b" top: "res2a_branch2b" name: "bn2a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch2b" top: "res2a_branch2b" name: "scale2a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a_branch2b" top: "res2a_branch2b" name: "res2a_branch2b_relu" type: "ReLU" } layer { bottom: "res2a_branch2b" top: "res2a_branch2c" name: "res2a_branch2c" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2a_branch2c" top: "res2a_branch2c" name: "bn2a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch2c" top: "res2a_branch2c" name: "scale2a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a_branch1" bottom: "res2a_branch2c" top: "res2a" name: "res2a" type: "Eltwise" } layer { bottom: "res2a" top: "res2a" name: "res2a_relu" type: "ReLU" } layer { bottom: "res2a" top: "res2b_branch2a" name: "res2b_branch2a" type: "Convolution" convolution_param { num_output: 64 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2b_branch2a" top: "res2b_branch2a" name: "bn2b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2b_branch2a" top: "res2b_branch2a" name: "scale2b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2b_branch2a" top: "res2b_branch2a" name: "res2b_branch2a_relu" type: "ReLU" } layer { bottom: "res2b_branch2a" top: "res2b_branch2b" name: "res2b_branch2b" type: "Convolution" convolution_param { num_output: 64 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res2b_branch2b" top: "res2b_branch2b" name: "bn2b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2b_branch2b" top: "res2b_branch2b" name: "scale2b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2b_branch2b" top: "res2b_branch2b" name: "res2b_branch2b_relu" type: "ReLU" } layer { bottom: "res2b_branch2b" top: "res2b_branch2c" name: "res2b_branch2c" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2b_branch2c" top: "res2b_branch2c" name: "bn2b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2b_branch2c" top: "res2b_branch2c" name: "scale2b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a" bottom: "res2b_branch2c" top: "res2b" name: "res2b" type: "Eltwise" } layer { bottom: "res2b" top: "res2b" name: "res2b_relu" type: "ReLU" } layer { bottom: "res2b" top: "res2c_branch2a" name: "res2c_branch2a" type: "Convolution" convolution_param { num_output: 64 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2c_branch2a" top: "res2c_branch2a" name: "bn2c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2c_branch2a" top: "res2c_branch2a" name: "scale2c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2c_branch2a" top: "res2c_branch2a" name: "res2c_branch2a_relu" type: "ReLU" } layer { bottom: "res2c_branch2a" top: "res2c_branch2b" name: "res2c_branch2b" type: "Convolution" convolution_param { num_output: 64 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res2c_branch2b" top: "res2c_branch2b" name: "bn2c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2c_branch2b" top: "res2c_branch2b" name: "scale2c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2c_branch2b" top: "res2c_branch2b" name: "res2c_branch2b_relu" type: "ReLU" } layer { bottom: "res2c_branch2b" top: "res2c_branch2c" name: "res2c_branch2c" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2c_branch2c" top: "res2c_branch2c" name: "bn2c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2c_branch2c" top: "res2c_branch2c" name: "scale2c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2b" bottom: "res2c_branch2c" top: "res2c" name: "res2c" type: "Eltwise" } layer { bottom: "res2c" top: "res2c" name: "res2c_relu" type: "ReLU" } layer { bottom: "res2c" top: "res3a_branch1" name: "res3a_branch1" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res3a_branch1" top: "res3a_branch1" name: "bn3a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch1" top: "res3a_branch1" name: "scale3a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2c" top: "res3a_branch2a" name: "res3a_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res3a_branch2a" top: "res3a_branch2a" name: "bn3a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch2a" top: "res3a_branch2a" name: "scale3a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a_branch2a" top: "res3a_branch2a" name: "res3a_branch2a_relu" type: "ReLU" } layer { bottom: "res3a_branch2a" top: "res3a_branch2b" name: "res3a_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3a_branch2b" top: "res3a_branch2b" name: "bn3a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch2b" top: "res3a_branch2b" name: "scale3a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a_branch2b" top: "res3a_branch2b" name: "res3a_branch2b_relu" type: "ReLU" } layer { bottom: "res3a_branch2b" top: "res3a_branch2c" name: "res3a_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3a_branch2c" top: "res3a_branch2c" name: "bn3a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch2c" top: "res3a_branch2c" name: "scale3a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a_branch1" bottom: "res3a_branch2c" top: "res3a" name: "res3a" type: "Eltwise" } layer { bottom: "res3a" top: "res3a" name: "res3a_relu" type: "ReLU" } layer { bottom: "res3a" top: "res3b_branch2a" name: "res3b_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3b_branch2a" top: "res3b_branch2a" name: "bn3b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3b_branch2a" top: "res3b_branch2a" name: "scale3b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3b_branch2a" top: "res3b_branch2a" name: "res3b_branch2a_relu" type: "ReLU" } layer { bottom: "res3b_branch2a" top: "res3b_branch2b" name: "res3b_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3b_branch2b" top: "res3b_branch2b" name: "bn3b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3b_branch2b" top: "res3b_branch2b" name: "scale3b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3b_branch2b" top: "res3b_branch2b" name: "res3b_branch2b_relu" type: "ReLU" } layer { bottom: "res3b_branch2b" top: "res3b_branch2c" name: "res3b_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3b_branch2c" top: "res3b_branch2c" name: "bn3b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3b_branch2c" top: "res3b_branch2c" name: "scale3b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a" bottom: "res3b_branch2c" top: "res3b" name: "res3b" type: "Eltwise" } layer { bottom: "res3b" top: "res3b" name: "res3b_relu" type: "ReLU" } layer { bottom: "res3b" top: "res3c_branch2a" name: "res3c_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3c_branch2a" top: "res3c_branch2a" name: "bn3c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3c_branch2a" top: "res3c_branch2a" name: "scale3c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3c_branch2a" top: "res3c_branch2a" name: "res3c_branch2a_relu" type: "ReLU" } layer { bottom: "res3c_branch2a" top: "res3c_branch2b" name: "res3c_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3c_branch2b" top: "res3c_branch2b" name: "bn3c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3c_branch2b" top: "res3c_branch2b" name: "scale3c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3c_branch2b" top: "res3c_branch2b" name: "res3c_branch2b_relu" type: "ReLU" } layer { bottom: "res3c_branch2b" top: "res3c_branch2c" name: "res3c_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3c_branch2c" top: "res3c_branch2c" name: "bn3c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3c_branch2c" top: "res3c_branch2c" name: "scale3c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3b" bottom: "res3c_branch2c" top: "res3c" name: "res3c" type: "Eltwise" } layer { bottom: "res3c" top: "res3c" name: "res3c_relu" type: "ReLU" } layer { bottom: "res3c" top: "res3d_branch2a" name: "res3d_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3d_branch2a" top: "res3d_branch2a" name: "bn3d_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3d_branch2a" top: "res3d_branch2a" name: "scale3d_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3d_branch2a" top: "res3d_branch2a" name: "res3d_branch2a_relu" type: "ReLU" } layer { bottom: "res3d_branch2a" top: "res3d_branch2b" name: "res3d_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3d_branch2b" top: "res3d_branch2b" name: "bn3d_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3d_branch2b" top: "res3d_branch2b" name: "scale3d_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3d_branch2b" top: "res3d_branch2b" name: "res3d_branch2b_relu" type: "ReLU" } layer { bottom: "res3d_branch2b" top: "res3d_branch2c" name: "res3d_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3d_branch2c" top: "res3d_branch2c" name: "bn3d_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3d_branch2c" top: "res3d_branch2c" name: "scale3d_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3c" bottom: "res3d_branch2c" top: "res3d" name: "res3d" type: "Eltwise" } layer { bottom: "res3d" top: "res3d" name: "res3d_relu" type: "ReLU" } layer { bottom: "res3d" top: "res4a_branch1" name: "res4a_branch1" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res4a_branch1" top: "res4a_branch1" name: "bn4a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch1" top: "res4a_branch1" name: "scale4a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3d" top: "res4a_branch2a" name: "res4a_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res4a_branch2a" top: "res4a_branch2a" name: "bn4a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch2a" top: "res4a_branch2a" name: "scale4a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a_branch2a" top: "res4a_branch2a" name: "res4a_branch2a_relu" type: "ReLU" } layer { bottom: "res4a_branch2a" top: "res4a_branch2b" name: "res4a_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4a_branch2b" top: "res4a_branch2b" name: "bn4a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch2b" top: "res4a_branch2b" name: "scale4a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a_branch2b" top: "res4a_branch2b" name: "res4a_branch2b_relu" type: "ReLU" } layer { bottom: "res4a_branch2b" top: "res4a_branch2c" name: "res4a_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4a_branch2c" top: "res4a_branch2c" name: "bn4a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch2c" top: "res4a_branch2c" name: "scale4a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a_branch1" bottom: "res4a_branch2c" top: "res4a" name: "res4a" type: "Eltwise" } layer { bottom: "res4a" top: "res4a" name: "res4a_relu" type: "ReLU" } layer { bottom: "res4a" top: "res4b_branch2a" name: "res4b_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4b_branch2a" top: "res4b_branch2a" name: "bn4b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4b_branch2a" top: "res4b_branch2a" name: "scale4b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4b_branch2a" top: "res4b_branch2a" name: "res4b_branch2a_relu" type: "ReLU" } layer { bottom: "res4b_branch2a" top: "res4b_branch2b" name: "res4b_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4b_branch2b" top: "res4b_branch2b" name: "bn4b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4b_branch2b" top: "res4b_branch2b" name: "scale4b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4b_branch2b" top: "res4b_branch2b" name: "res4b_branch2b_relu" type: "ReLU" } layer { bottom: "res4b_branch2b" top: "res4b_branch2c" name: "res4b_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4b_branch2c" top: "res4b_branch2c" name: "bn4b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4b_branch2c" top: "res4b_branch2c" name: "scale4b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a" bottom: "res4b_branch2c" top: "res4b" name: "res4b" type: "Eltwise" } layer { bottom: "res4b" top: "res4b" name: "res4b_relu" type: "ReLU" } layer { bottom: "res4b" top: "res4c_branch2a" name: "res4c_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4c_branch2a" top: "res4c_branch2a" name: "bn4c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4c_branch2a" top: "res4c_branch2a" name: "scale4c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4c_branch2a" top: "res4c_branch2a" name: "res4c_branch2a_relu" type: "ReLU" } layer { bottom: "res4c_branch2a" top: "res4c_branch2b" name: "res4c_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4c_branch2b" top: "res4c_branch2b" name: "bn4c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4c_branch2b" top: "res4c_branch2b" name: "scale4c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4c_branch2b" top: "res4c_branch2b" name: "res4c_branch2b_relu" type: "ReLU" } layer { bottom: "res4c_branch2b" top: "res4c_branch2c" name: "res4c_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4c_branch2c" top: "res4c_branch2c" name: "bn4c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4c_branch2c" top: "res4c_branch2c" name: "scale4c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4b" bottom: "res4c_branch2c" top: "res4c" name: "res4c" type: "Eltwise" } layer { bottom: "res4c" top: "res4c" name: "res4c_relu" type: "ReLU" } layer { bottom: "res4c" top: "res4d_branch2a" name: "res4d_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4d_branch2a" top: "res4d_branch2a" name: "bn4d_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4d_branch2a" top: "res4d_branch2a" name: "scale4d_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4d_branch2a" top: "res4d_branch2a" name: "res4d_branch2a_relu" type: "ReLU" } layer { bottom: "res4d_branch2a" top: "res4d_branch2b" name: "res4d_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4d_branch2b" top: "res4d_branch2b" name: "bn4d_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4d_branch2b" top: "res4d_branch2b" name: "scale4d_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4d_branch2b" top: "res4d_branch2b" name: "res4d_branch2b_relu" type: "ReLU" } layer { bottom: "res4d_branch2b" top: "res4d_branch2c" name: "res4d_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4d_branch2c" top: "res4d_branch2c" name: "bn4d_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4d_branch2c" top: "res4d_branch2c" name: "scale4d_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4c" bottom: "res4d_branch2c" top: "res4d" name: "res4d" type: "Eltwise" } layer { bottom: "res4d" top: "res4d" name: "res4d_relu" type: "ReLU" } layer { bottom: "res4d" top: "res4e_branch2a" name: "res4e_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4e_branch2a" top: "res4e_branch2a" name: "bn4e_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4e_branch2a" top: "res4e_branch2a" name: "scale4e_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4e_branch2a" top: "res4e_branch2a" name: "res4e_branch2a_relu" type: "ReLU" } layer { bottom: "res4e_branch2a" top: "res4e_branch2b" name: "res4e_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4e_branch2b" top: "res4e_branch2b" name: "bn4e_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4e_branch2b" top: "res4e_branch2b" name: "scale4e_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4e_branch2b" top: "res4e_branch2b" name: "res4e_branch2b_relu" type: "ReLU" } layer { bottom: "res4e_branch2b" top: "res4e_branch2c" name: "res4e_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4e_branch2c" top: "res4e_branch2c" name: "bn4e_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4e_branch2c" top: "res4e_branch2c" name: "scale4e_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4d" bottom: "res4e_branch2c" top: "res4e" name: "res4e" type: "Eltwise" } layer { bottom: "res4e" top: "res4e" name: "res4e_relu" type: "ReLU" } layer { bottom: "res4e" top: "res4f_branch2a" name: "res4f_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4f_branch2a" top: "res4f_branch2a" name: "bn4f_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4f_branch2a" top: "res4f_branch2a" name: "scale4f_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4f_branch2a" top: "res4f_branch2a" name: "res4f_branch2a_relu" type: "ReLU" } layer { bottom: "res4f_branch2a" top: "res4f_branch2b" name: "res4f_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4f_branch2b" top: "res4f_branch2b" name: "bn4f_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4f_branch2b" top: "res4f_branch2b" name: "scale4f_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4f_branch2b" top: "res4f_branch2b" name: "res4f_branch2b_relu" type: "ReLU" } layer { bottom: "res4f_branch2b" top: "res4f_branch2c" name: "res4f_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4f_branch2c" top: "res4f_branch2c" name: "bn4f_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4f_branch2c" top: "res4f_branch2c" name: "scale4f_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4e" bottom: "res4f_branch2c" top: "res4f" name: "res4f" type: "Eltwise" } layer { bottom: "res4f" top: "res4f" name: "res4f_relu" type: "ReLU" } layer { bottom: "res4f" top: "res5a_branch1" name: "res5a_branch1" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res5a_branch1" top: "res5a_branch1" name: "bn5a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch1" top: "res5a_branch1" name: "scale5a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4f" top: "res5a_branch2a" name: "res5a_branch2a" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res5a_branch2a" top: "res5a_branch2a" name: "bn5a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch2a" top: "res5a_branch2a" name: "scale5a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a_branch2a" top: "res5a_branch2a" name: "res5a_branch2a_relu" type: "ReLU" } layer { bottom: "res5a_branch2a" top: "res5a_branch2b" name: "res5a_branch2b" type: "Convolution" convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res5a_branch2b" top: "res5a_branch2b" name: "bn5a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch2b" top: "res5a_branch2b" name: "scale5a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a_branch2b" top: "res5a_branch2b" name: "res5a_branch2b_relu" type: "ReLU" } layer { bottom: "res5a_branch2b" top: "res5a_branch2c" name: "res5a_branch2c" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5a_branch2c" top: "res5a_branch2c" name: "bn5a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch2c" top: "res5a_branch2c" name: "scale5a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a_branch1" bottom: "res5a_branch2c" top: "res5a" name: "res5a" type: "Eltwise" } layer { bottom: "res5a" top: "res5a" name: "res5a_relu" type: "ReLU" } layer { bottom: "res5a" top: "res5b_branch2a" name: "res5b_branch2a" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5b_branch2a" top: "res5b_branch2a" name: "bn5b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5b_branch2a" top: "res5b_branch2a" name: "scale5b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5b_branch2a" top: "res5b_branch2a" name: "res5b_branch2a_relu" type: "ReLU" } layer { bottom: "res5b_branch2a" top: "res5b_branch2b" name: "res5b_branch2b" type: "Convolution" convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res5b_branch2b" top: "res5b_branch2b" name: "bn5b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5b_branch2b" top: "res5b_branch2b" name: "scale5b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5b_branch2b" top: "res5b_branch2b" name: "res5b_branch2b_relu" type: "ReLU" } layer { bottom: "res5b_branch2b" top: "res5b_branch2c" name: "res5b_branch2c" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5b_branch2c" top: "res5b_branch2c" name: "bn5b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5b_branch2c" top: "res5b_branch2c" name: "scale5b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a" bottom: "res5b_branch2c" top: "res5b" name: "res5b" type: "Eltwise" } layer { bottom: "res5b" top: "res5b" name: "res5b_relu" type: "ReLU" } layer { bottom: "res5b" top: "res5c_branch2a" name: "res5c_branch2a" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5c_branch2a" top: "res5c_branch2a" name: "bn5c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5c_branch2a" top: "res5c_branch2a" name: "scale5c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5c_branch2a" top: "res5c_branch2a" name: "res5c_branch2a_relu" type: "ReLU" } layer { bottom: "res5c_branch2a" top: "res5c_branch2b" name: "res5c_branch2b" type: "Convolution" convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res5c_branch2b" top: "res5c_branch2b" name: "bn5c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5c_branch2b" top: "res5c_branch2b" name: "scale5c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5c_branch2b" top: "res5c_branch2b" name: "res5c_branch2b_relu" type: "ReLU" } layer { bottom: "res5c_branch2b" top: "res5c_branch2c" name: "res5c_branch2c" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5c_branch2c" top: "res5c_branch2c" name: "bn5c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5c_branch2c" top: "res5c_branch2c" name: "scale5c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5b" bottom: "res5c_branch2c" top: "res5c" name: "res5c" type: "Eltwise" } layer { bottom: "res5c" top: "res5c" name: "res5c_relu" type: "ReLU" } layer { bottom: "res5c" top: "res6" name: "pool_res6" type: "Pooling" pooling_param { kernel_size: 3 stride: 2 pool: MAX } } ####lateral layer { bottom: "res6" top: "p6" name: "p6" param { lr_mult: 1.0 } param { lr_mult: 2.0 } type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } layer { bottom: "res5c" top: "p5" name: "p5" param { lr_mult: 1.0 } param { lr_mult: 2.0 } type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } layer { name: "upP5" type: "Deconvolution" bottom: "p5" top: "upP5" convolution_param { kernel_h : 4 kernel_w : 4 stride_h: 2 stride_w: 2 pad_h: 1 pad_w: 1 num_output: 256 group: 256 bias_term: false weight_filler { type: "bilinear" } } param { lr_mult: 0 decay_mult: 0 } } layer { bottom: "res4f" top: "c4" name: "newC4" param { lr_mult: 1.0 } param { lr_mult: 2.0 } type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0.0 } } } layer { name: "p4" type: "Eltwise" bottom: "c4" bottom: "upP5" top: "p4" eltwise_param { operation: SUM } } layer { bottom: "p4" top: "p4_lateral" name: "p4_lateral" param { lr_mult: 1.0 } param { lr_mult: 2.0 } type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0.0 } } } layer { name: "upP4" type: "Deconvolution" bottom: "p4_lateral" top: "upP4" convolution_param { kernel_h : 4 kernel_w : 4 stride_h: 2 stride_w: 2 pad_h: 1 pad_w: 1 num_output: 256 group: 256 bias_term: false weight_filler { type: "bilinear" } } param { lr_mult: 0 decay_mult: 0 } } layer { bottom: "res3d" top: "c3" name: "newC3" param { lr_mult: 1.0 } param { lr_mult: 2.0 } type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0.0 } } } layer { name: "p3" type: "Eltwise" bottom: "c3" bottom: "upP4" top: "p3" eltwise_param { operation: SUM } } layer { bottom: "p3" top: "p3_lateral" name: "p3_lateral" param { lr_mult: 1.0 } param { lr_mult: 2.0 } type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0.0 } } } layer { bottom: "res2c" top: "c2" name: "newC2" param { lr_mult: 1.0 } param { lr_mult: 2.0 } type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0.0 } } } layer { name: "upP2" type: "Deconvolution" bottom: "p3_lateral" top: "upP2" convolution_param { kernel_h : 4 kernel_w : 4 stride_h: 2 stride_w: 2 pad_h: 1 pad_w: 1 num_output: 256 group: 256 bias_term: false weight_filler { type: "bilinear" } } param { lr_mult: 0 decay_mult: 0 } } layer { name: "p2" type: "Eltwise" bottom: "c2" bottom: "upP2" top: "p2" eltwise_param { operation: SUM } } #### #========= RPN/p2 ============ layer { name: "rpn_conv/3x3/p2" type: "Convolution" bottom: "p2" top: "rpn/output/p2" param { lr_mult: 1.0 name: "rpn_conv_3x3_w" } param { lr_mult: 2.0 name: "rpn_conv_3x3_b" } convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_relu/3x3/p2" type: "ReLU" bottom: "rpn/output/p2" top: "rpn/output/p2" } layer { name: "rpn_cls_score/p2" type: "Convolution" bottom: "rpn/output/p2" top: "rpn_cls_score/p2" param { lr_mult: 1.0 name: "rpn_cls_score_w" } param { lr_mult: 2.0 name: "rpn_cls_score_b" } convolution_param { num_output: 12 # 2(bg/fg) * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_bbox_pred/p2" type: "Convolution" bottom: "rpn/output/p2" top: "rpn_bbox_pred/p2" param { lr_mult: 1.0 name: "rpn_bbox_pred_w" } param { lr_mult: 2.0 name: "rpn_bbox_pred_b" } convolution_param { num_output: 24 # 4 * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } ###### layer { bottom: "rpn_cls_score/p2" top: "rpn_cls_score_reshape_/p2" name: "rpn_cls_score_reshape_/p2" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 dim:0} } } layer { bottom: "rpn_bbox_pred/p2" top: "rpn_bbox_pred_reshape/p2" name: "rpn_bbox_pred_reshape/p2" type: "Reshape" reshape_param { shape { dim: 0 dim: 0 dim: -1 } } } layer { bottom: "rpn_cls_score_reshape_/p2" top: "rpn_cls_score_reshape/p2" name: "rpn_cls_score_reshape/p2" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 } } } #####CLS out layer { name: "fpn_out/p2" type: "Softmax" bottom: "rpn_cls_score_reshape_/p2" top: "fpn_out/p2" } layer { bottom: "fpn_out/p2" top: "fpn_out_reshape/p2" name: "fpn_out_reshape/p2" type: "Reshape" reshape_param { shape {dim: 0 dim: 12 dim: -1 dim: 0 } } } #========= RPN/p3 ============ layer { name: "rpn_conv/3x3/p3" type: "Convolution" bottom: "p3" top: "rpn/output/p3" param { lr_mult: 1.0 name: "rpn_conv_3x3_w" } param { lr_mult: 2.0 name: "rpn_conv_3x3_b" } convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_relu/3x3/p3" type: "ReLU" bottom: "rpn/output/p3" top: "rpn/output/p3" } layer { name: "rpn_cls_score/p3" type: "Convolution" bottom: "rpn/output/p3" top: "rpn_cls_score/p3" param { lr_mult: 1.0 name: "rpn_cls_score_w" } param { lr_mult: 2.0 name: "rpn_cls_score_b" } convolution_param { num_output: 12 # 2(bg/fg) * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_bbox_pred/p3" type: "Convolution" bottom: "rpn/output/p3" top: "rpn_bbox_pred/p3" param { lr_mult: 1.0 name:"rpn_bbox_pred_w" } param { lr_mult: 2.0 name:"rpn_bbox_pred_b" } convolution_param { num_output: 24 # 4 * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } ###### layer { bottom: "rpn_cls_score/p3" top: "rpn_cls_score_reshape_/p3" name: "rpn_cls_score_reshape_/p3" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 dim:0} } } layer { bottom: "rpn_bbox_pred/p3" top: "rpn_bbox_pred_reshape/p3" name: "rpn_bbox_pred_reshape/p3" type: "Reshape" reshape_param { shape { dim: 0 dim: 0 dim: -1 } } } layer { bottom: "rpn_cls_score_reshape_/p3" top: "rpn_cls_score_reshape/p3" name: "rpn_cls_score_reshape/p3" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 } } } #####CLS out layer { name: "fpn_out/p3" type: "Softmax" bottom: "rpn_cls_score_reshape_/p3" top: "fpn_out/p3" } layer { bottom: "fpn_out/p3" top: "fpn_out_reshape/p3" name: "fpn_out_reshape/p3" type: "Reshape" reshape_param { shape {dim: 0 dim: 12 dim: -1 dim: 0 } } } #========= RPN/p4 ============ layer { name: "rpn_conv/3x3/p4" type: "Convolution" bottom: "p4" top: "rpn/output/p4" param { lr_mult: 1.0 name: "rpn_conv_3x3_w" } param { lr_mult: 2.0 name: "rpn_conv_3x3_b" } convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_relu/3x3/p4" type: "ReLU" bottom: "rpn/output/p4" top: "rpn/output/p4" } layer { name: "rpn_cls_score/p4" type: "Convolution" bottom: "rpn/output/p4" top: "rpn_cls_score/p4" param { lr_mult: 1.0 name:"rpn_cls_score_w" } param { lr_mult: 2.0 name:"rpn_cls_score_b" } convolution_param { num_output: 12 # 2(bg/fg) * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_bbox_pred/p4" type: "Convolution" bottom: "rpn/output/p4" top: "rpn_bbox_pred/p4" param { lr_mult: 1.0 name:"rpn_bbox_pred_w" } param { lr_mult: 2.0 name:"rpn_bbox_pred_b" } convolution_param { num_output: 24 # 4 * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } ###### layer { bottom: "rpn_cls_score/p4" top: "rpn_cls_score_reshape_/p4" name: "rpn_cls_score_reshape_/p4" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 dim:0} } } layer { bottom: "rpn_bbox_pred/p4" top: "rpn_bbox_pred_reshape/p4" name: "rpn_bbox_pred_reshape/p4" type: "Reshape" reshape_param { shape { dim: 0 dim: 0 dim: -1 } } } layer { bottom: "rpn_cls_score_reshape_/p4" top: "rpn_cls_score_reshape/p4" name: "rpn_cls_score_reshape/p4" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 } } } #####CLS out layer { name: "fpn_out/p4" type: "Softmax" bottom: "rpn_cls_score_reshape_/p4" top: "fpn_out/p4" } layer { bottom: "fpn_out/p4" top: "fpn_out_reshape/p4" name: "fpn_out_reshape/p4" type: "Reshape" reshape_param { shape {dim: 0 dim: 12 dim: -1 dim: 0 } } } #========= RPN/p5 ============ layer { name: "rpn_conv/3x3/p5" type: "Convolution" bottom: "p5" top: "rpn/output/p5" param { lr_mult: 1.0 name:"rpn_conv_3x3_w" } param { lr_mult: 2.0 name:"rpn_conv_3x3_b" } convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_relu/3x3/p5" type: "ReLU" bottom: "rpn/output/p5" top: "rpn/output/p5" } layer { name: "rpn_cls_score/p5" type: "Convolution" bottom: "rpn/output/p5" top: "rpn_cls_score/p5" param { lr_mult: 1.0 name:"rpn_cls_score_w" } param { lr_mult: 2.0 name:"rpn_cls_score_b" } convolution_param { num_output: 12 # 2(bg/fg) * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_bbox_pred/p5" type: "Convolution" bottom: "rpn/output/p5" top: "rpn_bbox_pred/p5" param { lr_mult: 1.0 name:"rpn_bbox_pred_w" } param { lr_mult: 2.0 name:"rpn_bbox_pred_b" } convolution_param { num_output: 24 # 4 * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } ###### layer { bottom: "rpn_cls_score/p5" top: "rpn_cls_score_reshape_/p5" name: "rpn_cls_score_reshape_/p5" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 dim:0} } } layer { bottom: "rpn_bbox_pred/p5" top: "rpn_bbox_pred_reshape/p5" name: "rpn_bbox_pred_reshape/p5" type: "Reshape" reshape_param { shape { dim: 0 dim: 0 dim: -1 } } } layer { bottom: "rpn_cls_score_reshape_/p5" top: "rpn_cls_score_reshape/p5" name: "rpn_cls_score_reshape/p5" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 } } } #####CLS out layer { name: "fpn_out/p5" type: "Softmax" bottom: "rpn_cls_score_reshape_/p5" top: "fpn_out/p5" } layer { bottom: "fpn_out/p5" top: "fpn_out_reshape/p5" name: "fpn_out_reshape/p5" type: "Reshape" reshape_param { shape {dim: 0 dim: 12 dim: -1 dim: 0 } } } #========= RPN/p6 ============ layer { name: "rpn_conv/3x3/p6" type: "Convolution" bottom: "p6" top: "rpn/output/p6" param { lr_mult: 1.0 name:"rpn_conv_3x3_w" } param { lr_mult: 2.0 name:"rpn_conv_3x3_b" } convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_relu/3x3/p6" type: "ReLU" bottom: "rpn/output/p6" top: "rpn/output/p6" } layer { name: "rpn_cls_score/p6" type: "Convolution" bottom: "rpn/output/p6" top: "rpn_cls_score/p6" param { lr_mult: 1.0 name:"rpn_cls_score_w" } param { lr_mult: 2.0 name:"rpn_cls_score_b" } convolution_param { num_output: 12 # 2(bg/fg) * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "rpn_bbox_pred/p6" type: "Convolution" bottom: "rpn/output/p6" top: "rpn_bbox_pred/p6" param { lr_mult: 1.0 name:"rpn_bbox_pred_w" } param { lr_mult: 2.0 name:"rpn_bbox_pred_b" } convolution_param { num_output: 24 # 4 * 9(anchors) kernel_size: 1 pad: 0 stride: 1 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } ###### layer { bottom: "rpn_cls_score/p6" top: "rpn_cls_score_reshape_/p6" name: "rpn_cls_score_reshape_/p6" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 dim:0} } } layer { bottom: "rpn_bbox_pred/p6" top: "rpn_bbox_pred_reshape/p6" name: "rpn_bbox_pred_reshape/p6" type: "Reshape" reshape_param { shape { dim: 0 dim: 0 dim: -1 } } } layer { bottom: "rpn_cls_score_reshape_/p6" top: "rpn_cls_score_reshape/p6" name: "rpn_cls_score_reshape/p6" type: "Reshape" reshape_param { shape {dim: 0 dim: 2 dim: -1 } } } #####CLS out layer { name: "fpn_out/p6" type: "Softmax" bottom: "rpn_cls_score_reshape_/p6" top: "fpn_out/p6" } layer { bottom: "fpn_out/p6" top: "fpn_out_reshape/p6" name: "fpn_out_reshape/p6" type: "Reshape" reshape_param { shape {dim: 0 dim: 12 dim: -1 dim: 0 } } } ########rpn loss##################### layer { name: "rpn_cls_score_reshapee" type: "Concat" bottom: "rpn_cls_score_reshape/p2" bottom: "rpn_cls_score_reshape/p3" bottom: "rpn_cls_score_reshape/p4" bottom: "rpn_cls_score_reshape/p5" bottom: "rpn_cls_score_reshape/p6" top: "rpn_cls_score_reshape" concat_param { axis: 2 } } layer { name: "rpn_bbox_pred" type: "Concat" bottom: "rpn_bbox_pred_reshape/p2" bottom: "rpn_bbox_pred_reshape/p3" bottom: "rpn_bbox_pred_reshape/p4" bottom: "rpn_bbox_pred_reshape/p5" bottom: "rpn_bbox_pred_reshape/p6" top: "rpn_bbox_pred" concat_param { axis: 2 } } layer { name: 'rpn-data' type: 'Python' bottom: 'rpn_cls_score/p2' bottom: 'rpn_cls_score/p3' bottom: 'rpn_cls_score/p4' bottom: 'rpn_cls_score/p5' bottom: 'rpn_cls_score/p6' bottom: 'gt_boxes' bottom: 'im_info' top: 'rpn_labels' top: 'rpn_bbox_targets' top: 'rpn_bbox_inside_weights' top: 'rpn_bbox_outside_weights' python_param { module: 'rpn.anchor_target_layer' layer: 'AnchorTargetLayer' param_str: "'feat_stride': 4,8,16,32,64" } } layer { name: "fpn_loss_cls" type: "SoftmaxWithLoss" bottom: "rpn_cls_score_reshape" bottom: "rpn_labels" propagate_down: 1 propagate_down: 0 top: "FPNClsLoss" loss_weight: 1 loss_param { ignore_label: -1 normalization: VALID } } layer { name: "rpn_loss_bbox" type: "SmoothL1Loss" bottom: "rpn_bbox_pred" bottom: "rpn_bbox_targets" bottom: 'rpn_bbox_inside_weights' bottom: 'rpn_bbox_outside_weights' top: "FPNLossBBox" loss_weight: 1 smooth_l1_loss_param { sigma: 3.0 } } #========= RoI Proposal ============ layer { name: 'proposal' type: 'Python' bottom: 'im_info' bottom: 'rpn_bbox_pred/p2' bottom: 'rpn_bbox_pred/p3' bottom: 'rpn_bbox_pred/p4' bottom: 'rpn_bbox_pred/p5' bottom: 'rpn_bbox_pred/p6' bottom: 'fpn_out_reshape/p2' bottom: 'fpn_out_reshape/p3' bottom: 'fpn_out_reshape/p4' bottom: 'fpn_out_reshape/p5' bottom: 'fpn_out_reshape/p6' top: 'rpn_rois' python_param { module: 'rpn.proposal_layer' layer: 'ProposalLayer' param_str: "'feat_stride': 4,8,16,32,64" } } #================rois process====================== layer { name: 'roi-data' type: 'Python' bottom: 'rpn_rois' bottom: 'gt_boxes' bottom: 'data' top: 'rois/h2' top: 'rois/h3' top: 'rois/h4' top: 'rois/h5' top: 'labels' top: 'bbox_targets' top: 'bbox_inside_weights' top: 'bbox_outside_weights' python_param { module: 'rpn.proposal_target_layer' layer: 'ProposalTargetLayer' param_str: "'num_classes': 21" } } #========= RCNN ============ ######POOLING======= layer { name: "roi_pool/h2" type: "ROIPooling" bottom: "p2" bottom: "rois/h2" top: "roi_pool/h2" roi_pooling_param { pooled_w: 7 pooled_h: 7 spatial_scale: 0.25 # 1/4 } } layer { name: "roi_pool/h3" type: "ROIPooling" bottom: "p3" bottom: "rois/h3" top: "roi_pool/h3" roi_pooling_param { pooled_w: 7 pooled_h: 7 spatial_scale: 0.125 # 1/8 } } layer { name: "roi_pool/h4" type: "ROIPooling" bottom: "p4" bottom: "rois/h4" top: "roi_pool/h4" roi_pooling_param { pooled_w: 7 pooled_h: 7 spatial_scale: 0.0625 # 1/16 } } layer { name: "roi_pool/h5" type: "ROIPooling" bottom: "p5" bottom: "rois/h5" top: "roi_pool/h5" roi_pooling_param { pooled_w: 7 pooled_h: 7 spatial_scale: 0.03125 # 1/32 } } #h2 layer { name: "rcnn_fc6/h2" type: "InnerProduct" bottom: "roi_pool/h2" top: "rcnn_fc6/h2" param { lr_mult: 1 name: "rcnn_fc6_w" } param { lr_mult: 2 name: "rcnn_fc6_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu6/h2" type: "ReLU" bottom: "rcnn_fc6/h2" top: "rcnn_fc6/h2" } layer { name: "drop6/h2" type: "Dropout" bottom: "rcnn_fc6/h2" top: "rcnn_fc6/h2" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc7/h2" type: "InnerProduct" bottom: "rcnn_fc6/h2" top: "fc7/h2" param { lr_mult: 1 name:"fc7_w" } param { lr_mult: 2 name: "fc7_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu7/h2" type: "ReLU" bottom: "fc7/h2" top: "fc7/h2" } layer { name: "drop7/h2" type: "Dropout" bottom: "fc7/h2" top: "fc7/h2" dropout_param { dropout_ratio: 0.5 } } layer { name: "cls_score/h2" type: "InnerProduct" bottom: "fc7/h2" top: "cls_score/h2" param { lr_mult: 1 name:"cls_score_w" } param { lr_mult: 2 name:"cls_score_b" } inner_product_param { num_output: 21 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "bbox_pred/h2" type: "InnerProduct" bottom: "fc7/h2" top: "bbox_pred/h2" param { lr_mult: 1 name:"bbox_pred_w" } param { lr_mult: 2 name:"bbox_pred_b" } inner_product_param { num_output: 84 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } #h3 layer { name: "rcnn_fc6/h3" type: "InnerProduct" bottom: "roi_pool/h3" top: "rcnn_fc6/h3" param { lr_mult: 1 name: "rcnn_fc6_w" } param { lr_mult: 2 name: "rcnn_fc6_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu6/h3" type: "ReLU" bottom: "rcnn_fc6/h3" top: "rcnn_fc6/h3" } layer { name: "drop6/h3" type: "Dropout" bottom: "rcnn_fc6/h3" top: "rcnn_fc6/h3" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc7/h3" type: "InnerProduct" bottom: "rcnn_fc6/h3" top: "fc7/h3" param { lr_mult: 1 name:"fc7_w" } param { lr_mult: 2 name: "fc7_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu7/h3" type: "ReLU" bottom: "fc7/h3" top: "fc7/h3" } layer { name: "drop7/h3" type: "Dropout" bottom: "fc7/h3" top: "fc7/h3" dropout_param { dropout_ratio: 0.5 } } layer { name: "cls_score/h3" type: "InnerProduct" bottom: "fc7/h3" top: "cls_score/h3" param { lr_mult: 1 name:"cls_score_w" } param { lr_mult: 2 name:"cls_score_b" } inner_product_param { num_output: 21 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "bbox_pred/h3" type: "InnerProduct" bottom: "fc7/h3" top: "bbox_pred/h3" param { lr_mult: 1 name:"bbox_pred_w" } param { lr_mult: 2 name:"bbox_pred_b" } inner_product_param { num_output: 84 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } #h4 layer { name: "rcnn_fc6/h4" type: "InnerProduct" bottom: "roi_pool/h4" top: "rcnn_fc6/h4" param { lr_mult: 1 name: "rcnn_fc6_w" } param { lr_mult: 2 name: "rcnn_fc6_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu6/h4" type: "ReLU" bottom: "rcnn_fc6/h4" top: "rcnn_fc6/h4" } layer { name: "drop6/h4" type: "Dropout" bottom: "rcnn_fc6/h4" top: "rcnn_fc6/h4" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc7/h4" type: "InnerProduct" bottom: "rcnn_fc6/h4" top: "fc7/h4" param { lr_mult: 1 name:"fc7_w" } param { lr_mult: 2 name: "fc7_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu7/h4" type: "ReLU" bottom: "fc7/h4" top: "fc7/h4" } layer { name: "drop7/h4" type: "Dropout" bottom: "fc7/h4" top: "fc7/h4" dropout_param { dropout_ratio: 0.5 } } layer { name: "cls_score/h4" type: "InnerProduct" bottom: "fc7/h4" top: "cls_score/h4" param { lr_mult: 1 name:"cls_score_w" } param { lr_mult: 2 name:"cls_score_b" } inner_product_param { num_output: 21 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "bbox_pred/h4" type: "InnerProduct" bottom: "fc7/h4" top: "bbox_pred/h4" param { lr_mult: 1 name:"bbox_pred_w" } param { lr_mult: 2 name:"bbox_pred_b" } inner_product_param { num_output: 84 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } #h5 layer { name: "rcnn_fc6/h5" type: "InnerProduct" bottom: "roi_pool/h5" top: "rcnn_fc6/h5" param { lr_mult: 1 name: "rcnn_fc6_w" } param { lr_mult: 2 name: "rcnn_fc6_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu6/h5" type: "ReLU" bottom: "rcnn_fc6/h5" top: "rcnn_fc6/h5" } layer { name: "drop6/h5" type: "Dropout" bottom: "rcnn_fc6/h5" top: "rcnn_fc6/h5" dropout_param { dropout_ratio: 0.5 } } layer { name: "fc7/h5" type: "InnerProduct" bottom: "rcnn_fc6/h5" top: "fc7/h5" param { lr_mult: 1 name:"fc7_w" } param { lr_mult: 2 name: "fc7_b" } inner_product_param { num_output: 4096 weight_filler { type: "xavier" } bias_filler { type: "constant" } } } layer { name: "relu7/h5" type: "ReLU" bottom: "fc7/h5" top: "fc7/h5" } layer { name: "drop7/h5" type: "Dropout" bottom: "fc7/h5" top: "fc7/h5" dropout_param { dropout_ratio: 0.5 } } layer { name: "cls_score/h5" type: "InnerProduct" bottom: "fc7/h5" top: "cls_score/h5" param { lr_mult: 1 name:"cls_score_w" } param { lr_mult: 2 name:"cls_score_b" } inner_product_param { num_output: 21 weight_filler { type: "gaussian" std: 0.01 } bias_filler { type: "constant" value: 0 } } } layer { name: "bbox_pred/h5" type: "InnerProduct" bottom: "fc7/h5" top: "bbox_pred/h5" param { lr_mult: 1 name:"bbox_pred_w" } param { lr_mult: 2 name:"bbox_pred_b" } inner_product_param { num_output: 84 weight_filler { type: "gaussian" std: 0.001 } bias_filler { type: "constant" value: 0 } } } layer { name: "cls_score_concat" type: "Concat" bottom: "cls_score/h2" bottom: "cls_score/h3" bottom: "cls_score/h4" bottom: "cls_score/h5" top: "cls_score" concat_param { axis: 0 } } layer { name: "bbox_pred_concat" type: "Concat" bottom: "bbox_pred/h2" bottom: "bbox_pred/h3" bottom: "bbox_pred/h4" bottom: "bbox_pred/h5" top: "bbox_pred" concat_param { axis: 0 } } layer { name: "loss_cls" type: "SoftmaxWithLoss" bottom: "cls_score" bottom: "labels" propagate_down: 1 propagate_down: 0 top: "RcnnLossCls" loss_weight: 1 loss_param{ ignore_label: -1 normalization: VALID } } layer { name: "loss_bbox" type: "SmoothL1Loss" bottom: "bbox_pred" bottom: "bbox_targets" bottom: "bbox_inside_weights" bottom: "bbox_outside_weights" top: "RcnnLossBBox" loss_weight: 1 }