博客来源于:https://blog.csdn.net/buyi_shizi/article/details/53336192;https://blog.csdn.net/dcrmg/article/details/79263415;
ResNet指出,在许多的数据库上都显示出一个普遍的现象:增加网络深度到一定程度时,更深的网络意味着更高的训练误差。
误差升高的原因是网络越深,梯度消失的现象就越明显,所以在后向传播的时候,无法有效的把梯度更新到前面的网络层,靠前的网络层参数无法更新,导致训练和测试效果变差。所以ResNet面临的问题是怎样在增加网络深度的情况下有可以有效解决梯度消失的问题。
ResNet中解决深层网络梯度消失的问题的核心结构是残差网络: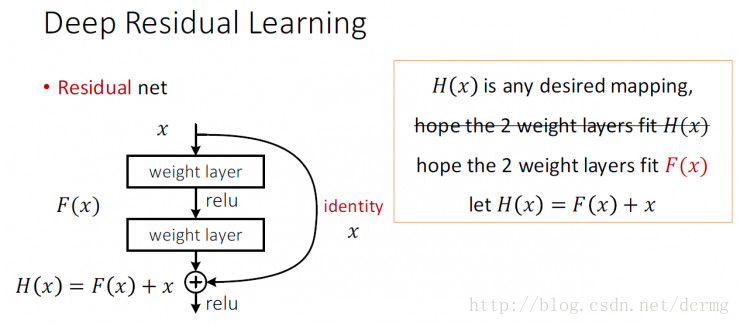

残差网络增加了一个identity mapping(恒等映射),把当前输出直接传输给下一层网络(全部是1:1传输,不增加额外的参数),相当于走了一个捷径,跳过了本层运算,这个直接连接命名为“skip connection”,同时在后向传播过程中,也是将下一层网络的梯度直接传递给上一层网络,这样就解决了深层网络的梯度消失问题。
残差网络单元其中可以分解成右图的形式,从右图中可以看出,残差网络其实是由多种路径组合的一个网络,直白了说,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(Ensembling)。如果把残差网络理解成一个Ensambling系统,那么网络的一部分就相当于少一些投票的人,如果只是删除一个基本的残差单元,对最后的分类结果应该影响很小;而最后的分类错误率应该适合删除的残差单元的个数成正比的,论文里的结论也印证了这个猜测。
对于shortcut连接的方式,作者提出了三个选项:
A. 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
C. 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。
残差网络ResNets的特点
1. 残差网络在模型表征方面并不存在直接的优势,ResNets并不能更好的表征某一方面的特征,但是ResNets允许逐层深入地表征更多的模型。
2. 残差网络使得前馈式/反向传播算法非常顺利进行,在极大程度上,残差网络使得优化较深层模型更为简单
3. “shortcut”快捷连接添加既不产生额外的参数,也不会增加计算的复杂度。快捷连接简单的执行身份映射,并将它们的输出添加到叠加层的输出。通过反向传播的SGD,整个网络仍然可以被训练成终端到端的形式。
ResNet的真面目
ResNet的确可以做到很深,但是从上面的介绍可以看出,网络很深的路径其实很少,大部分的网络路径其实都集中在中间的路径长度上,如下图a,所示;
从这可以看出其实ResNet是由大多数中度网络和一小部分浅度网络和深度网络组成的,说明虽然表面上ResNet网络很深,但是其实起实际作用的网络层数并没有很深,我们能来进一步阐述这个问题,我们知道网络越深,梯度就越小,如下图b所示;
而通过各个路径长度上包含的网络数乘以每个路径的梯度值,我们可以得到ResNet真正起作用的网络是什么样的,如下图c所示 ;
a,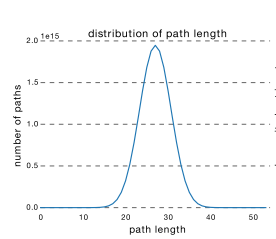 b,
b,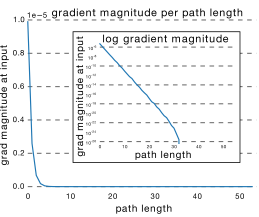 ; c,
; c,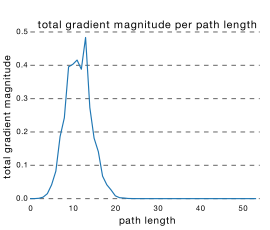
我们可以看出大多数的梯度其实都集中在中间的路径上,论文里称为effective path。
从这可以看出其实ResNet只是表面上看起来很深,事实上网络却很浅。
所示ResNet真的解决了深度网络的梯度消失的问题了吗?似乎没有,ResNet其实就是一个多人投票系统。