keepalived:
HTTP_GET //使用keepalived获取后端real server健康状态检测
SSL_GET(https) //这里以为这后端使用的是http协议
TCP_CHECK
下面演示基于TCP_CHECK做检测
# man keepalived //查看TCP_CHECK配置段
# TCP healthchecker
TCP_CHECK
{
# ======== generic connection options
# Optional IP address to connect to.
# The default is the realserver IP //默认使用real server的IP
connect_ip <IP ADDRESS> //可省略
# Optional port to connect to
# The default is the realserver port
connect_port <PORT> //可省略
# Optional interface to use to
# originate the connection
bindto <IP ADDRESS>
# Optional source port to
# originate the connection from
bind_port <PORT>
# Optional connection timeout in seconds.
# The default is 5 seconds
connect_timeout <INTEGER>
# Optional fwmark to mark all outgoing
# checker packets with
fwmark <INTEGER>
# Optional random delay to start the initial check
# for maximum N seconds.
# Useful to scatter multiple simultaneous
# checks to the same RS. Enabled by default, with
# the maximum at delay_loop. Specify 0 to disable
warmup <INT>
# Retry count to make additional checks if check
# of an alive server fails. Default: 1
retry <INT>
# Delay in seconds before retrying. Default: 1
delay_before_retry <INT>
} #TCP_CHECK
# cd /etc/keepalived
# vim keepalived.conf //两台keepalived都要设置
1 virtual_server 192.168.184.150 80 { //这里可以合并 2 delay_loop 6 3 lb_algo wrr 4 lb_kind DR 5 net_mask 255.255.0.0 6 protocol TCP 7 sorry_server 127.0.0.1 80 8 9 real_server 192.168.184.143 80 { 10 weight 1 11 TCP_CHECK { 12 connect_timeout 3 13 } 14 } 15 16 real_server 192.168.184.144 80 { 17 weight 2 18 TCP_CHECK { 19 connect_timeout 3 20 } 21 } 22 }
systemctl restart keepalived
# systemctl status keepalived
1 ● keepalived.service - LVS and VRRP High Availability Monitor 2 Loaded: loaded (/usr/lib/systemd/system/keepalived.service; disabled; vendor preset: disabled) 3 Active: active (running) since Thu 2018-12-13 23:11:06 CST; 1min 32s ago 4 Process: 6233 ExecStart=/usr/sbin/keepalived $KEEPALIVED_OPTIONS (code=exited, status=0/SUCCESS) 5 Main PID: 6234 (keepalived) 6 CGroup: /system.slice/keepalived.service 7 ├─6234 /usr/sbin/keepalived -D 8 ├─6235 /usr/sbin/keepalived -D 9 └─6236 /usr/sbin/keepalived -D 10 11 Dec 13 23:11:11 node1 Keepalived_healthcheckers[6235]: Check on service [192.168.184.144]:80 failed after 1 retry. 12 Dec 13 23:11:11 node1 Keepalived_healthcheckers[6235]: Removing service [192.168.184.144]:80 from VS [192.168.184.150]:80 13 Dec 13 23:11:11 node1 Keepalived_healthcheckers[6235]: Remote SMTP server [127.0.0.1]:25 connected. 14 Dec 13 23:11:11 node1 Keepalived_healthcheckers[6235]: SMTP alert successfully sent. 15 Dec 13 23:11:14 node1 Keepalived_vrrp[6236]: Sending gratuitous ARP on eth0 for 192.168.184.150 16 Dec 13 23:11:14 node1 Keepalived_vrrp[6236]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth0 for 192.168.184.150 17 Dec 13 23:11:14 node1 Keepalived_vrrp[6236]: Sending gratuitous ARP on eth0 for 192.168.184.150 18 Dec 13 23:11:14 node1 Keepalived_vrrp[6236]: Sending gratuitous ARP on eth0 for 192.168.184.150 19 Dec 13 23:11:14 node1 Keepalived_vrrp[6236]: Sending gratuitous ARP on eth0 for 192.168.184.150 20 Dec 13 23:11:14 node1 Keepalived_vrrp[6236]: Sending gratuitous ARP on eth0 for 192.168.184.150 //发送广播地址已经添加 21 You have new mail in /var/spool/mail/root
如果两个后端的real server都上线,可以查看当前的状态

此时请求是完美响应的

把后端的143主机停止httpd服务

如果后端的两台主机全部下线,则当前的keepalived则会启用sorry服务

注意这里对于后端的两台real server,一定要保证他们的VIP安装上,不然无法返回信息。详细参考keepalived3

负载均衡一个独立的服务程序,以nginx为例
HA Services:
nginx
为了做上面的实例,根据随笔3的配置,进行以下修改:
当VIP还配置在两台real server上时,是有路由信息的

首先对两台后端的real server进行修改,real server配置了VIP,所以先把VIP去掉

# ifconfig lo:0 down //注意两台real server都要down

两台real server也配置了arp_announce和arp_ignore,都要恢复原来的状态,这里已经编写了脚本,直接执行即可
1 #!/bin/bash 2 # 3 4 vip=192.168.184.150 5 case $1 in 6 start) 7 echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore 8 echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore 9 echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce 10 echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce 11 ifconfig lo:0 $vip netmask 255.255.255.255 broadcast $vip up 12 route add -host $vip dev lo:0 13 ;; 14 stop) 15 ifconfig lo:0 down 16 echo 0 > /proc/sys/net/ipv4/conf/all/arp_ignore 17 echo 0 > /proc/sys/net/ipv4/conf/eth0/arp_ignore 18 echo 0 > /proc/sys/net/ipv4/conf/all/arp_announce 19 echo 0 > /proc/sys/net/ipv4/conf/eth0/arp_announce 20 esac
# bash -x set.sh stop
# cat /proc/sys/net/ipv4/conf/all/arp_ignore //可以进行查看是否执行成功
以上只对两台real server保留web服务
下面对两个director进行修改
# systemctl stop keepalived //首先关闭两台keepalived
# ip addr del 192.168.184.150/32 dev eth0
因为要对nginx做负载均衡,所以下面安装nginx
# yum install nginx //如果显示没有此版本,则可以取nginx的官方去查找配置yum源 http://nginx.org/en/linux_packages.html#stable
下面配置nginx成为反向代理,并且将用户的请求代理至后端的upstream
# vim /etc/nginx/nginx.conf //查看nginx的主配置文件,在http配置段添加upstream组
1 http { 2 include /etc/nginx/mime.types; 3 default_type application/octet-stream; 4 5 log_format main '$remote_addr - $remote_user [$time_local] "$request" ' 6 '$status $body_bytes_sent "$http_referer" ' 7 '"$http_user_agent" "$http_x_forwarded_for"'; 8 9 upstream webservers { //定义upstream组 10 server 192.168.184.143:80 weight=1; 如果不用端口映射的话,不用指明端口;weight指明权重,keepalived自身就可以对后端的服务器做健康状态检测,负载均衡算法是rr 11 server 192.168.184.144:80 weight=1; 12 } 13 14 server { //使用上一节中的服务器配置并对其进行修改以使其成为代理服务器配置 15 location / { 16 proxy_pass http://webservers/; 17 } 18 } 19 20 access_log /var/log/nginx/access.log main; 21 22 sendfile on; 23 #tcp_nopush on; 24 25 keepalive_timeout 65; 26 27 #gzip on; 28 29 include /etc/nginx/conf.d/*.conf; 30 }
# systemctl start nginx //启动nginx服务,这时192.168.184.141已经成为了代理服务,实现了负载均衡

另外一个节点192.168.184.142需要同样的文件
# scp nginx.conf node2:/etc/nginx //把同样的配置复制到node2上,启动服务后同样没有问题。
接下来就配置利用keepalived高可用使用nginx
本地keepalived做高可用时,探测心跳用到的可能是私有地址,但通过配置VIP作为公网地址接收外面访问的,所以VIP在哪个主机上,那个主机就是负载均衡器。
接下来配置keepalived在高可用中使用nginx,此时只需要在两台主机上启动keepalivd做高可用,nginx做代理服务,然后配置一个VIP作为用户的访问入口,VIP在哪个主机上,那个主机就是master。但有一个问题:两台keepalived在本地做高可用时探测彼此的心跳用到的可能是私有地址,但VIP是公网地址,所以VIP所在接口就是负载均衡器。
ipvs是通过添加ipvs规则,但nginx是服务,有可能存在套接字争用,所以需要监控nginx服务。
nginx和httpd服务存在可能争用端口的问题,所以需要写一个脚本监控nginx服务,如果nginx服务不在线,就让所在主机的优先级降低
keepalived如何实现监控nginx是否在线?
# yum -y install psmisc //安装killall https://www.banaspati.net/centos/how-to-install-killall-command-on-centos-7.html
# killall -0 nginx //在nginx启动的时候,执行此命令没有任何输出
# echo $? //输出0,证明上个命令执行的结果是正确的
# killall -0 nginx //如果nginx没有启动,这里会有提示
nginx: no process found
# echo $? //输入为1,证明上面的命令执行错误
因此以上可以作为nginx服务是否启动的标准
# vim /etc/keepalived/keepalived.conf //两个节点即keepalived高可用节点上都要进行此配置
1 ! Configuration File for keepalived 2 3 global_defs { 4 notification_email { 5 root@localhost 6 } 7 notification_email_from kaadmin@localhost 8 smtp_server 127.0.0.1 9 smtp_connect_timeout 30 10 router_id LVS_DEVEL 11 vrrp_mcast_group4 224.0.1.118 12 # vrrp_skip_check_adv_addr 13 # vrrp_strict 14 # vrrp_garp_interval 0 15 # vrrp_gna_interval 0 16 } 17 18 vrrp_script chk_mt { //很少用此脚本 19 script "/etc/keepalived/down.sh" 20 interval 1 21 weight -2 22 } 23 24 vrrp_script chk_nginx { //添加此段判断nginx服务是否在线 25 script "killall -0 nginx &>/dev/null" //执行此命令,自动返回0或者1 26 interval 1 //如果执行是被,间隔1秒 27 weight -10 //此主机权重减10 28 } 29 30 vrrp_instance VI_1 { 31 state MASTER 32 interface eth0 33 virtual_router_id 51 34 priority 100 35 advert_int 1 36 authentication { 37 auth_type PASS 38 auth_pass 1111 39 } 40 virtual_ipaddress { 41 192.168.184.150 42 } 43 track_script { //在对应的vrrp实例中配置IP时,调用此脚本,把此脚本的检测结果当作nginx服务器是否在线的判断标准,如果检测nginx不在线,则此主机权重减10,确保只有nginx在线的主机是 44 chk_nginx //主节点 45 } 46 notify_master "/etc/keepalived/notify.sh master" 47 notify_backup "/etc/keepalived/notify.sh backup" 48 notify_fault "/etc/keepalived/notify.sh fault" 49 }

如果把脚本script "killall -0 nginx &>/dev/null" 直接定义在配置文件中,启动keepalived是无法执行的,所以还是需要把执行的命令定义为另一个脚本,并把脚本路径写在此处,如下:script "/etc/keepalived/chk.sh"
# vim /etc/keepalived/chk.sh
1 #!/bin/bash 2 # 3 4 killall -0 nginx &>/dev/null
# systemctl status nginx //同时保证两台keepalived的nginx服务是启动的
# systemctl start keepalived //两台代理服务器(即141、142)启用keepalived服务
此时无论是keepalived高可用主机1(即192.168.184.141)或者主机2(即192.168.184.142)都可以利用nginx代理服务把请求利用负载均衡的方式代理到后端的服务器组。




# systemctl status keepalived //在master-141上启动keepalived

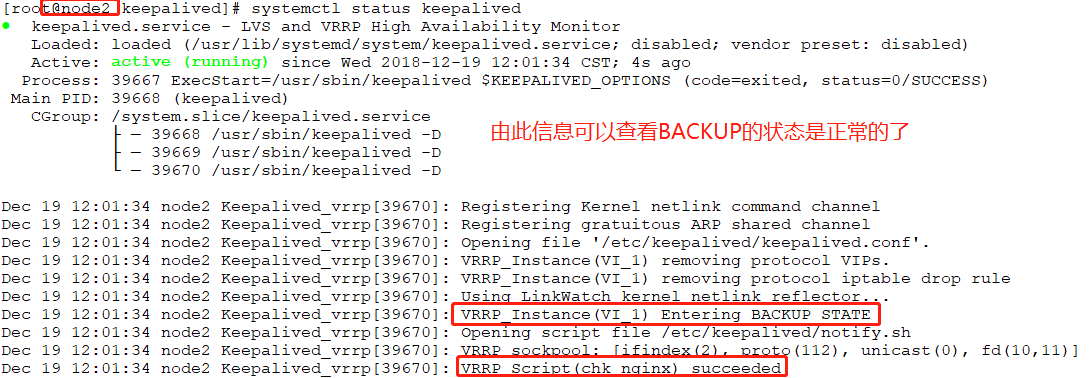
# systemctl status keepalived //在BACKUP-142上启动keepalived

以上问题的解决办法:
https://github.com/acassen/keepalived/issues/901
https://warlord0blog.wordpress.com/2018/05/15/nginx-and-keepalived/
# useradd -g users -M keepalived_script
另外在查看主机2即192.168.184.142的keepalived的状态时,按照主机1的配置,把killall -0 nginx &>/dev/null另外定义一个脚本一直出现执行/etc/keepalived/chk.sh返回的状态是1,情况如下:

由于无法排除原因,本此实验把chk.sh中的执行命令换成如下命令:
# vim /etc/keepalived/chk.sh
#!/bin/bash # #killall -0 nginx &>/dev/null [ "`ps -aux | grep nginx | wc -l`" -ge 2 ]
此时查看BACKUP的keepalived返回的状态就是0

出现以上情况的办法:https://github.com/acassen/keepalived/issues/901
1 ! Configuration File for keepalived 2 3 global_defs { 4 notification_email { 5 root@localhost 6 } 7 notification_email_from kaadmin@localhost 8 smtp_server 127.0.0.1 9 smtp_connect_timeout 30 10 router_id LVS_DEVEL 11 vrrp_mcast_group4 224.0.1.118 12 vrrp_skip_check_adv_addr 13 enable_script_security //添加此行即可 14 vrrp_strict 15 vrrp_garp_interval 0 16 vrrp_gna_interval 0 17 }
# systemctl status keepalived //此时BACKUP一切正常
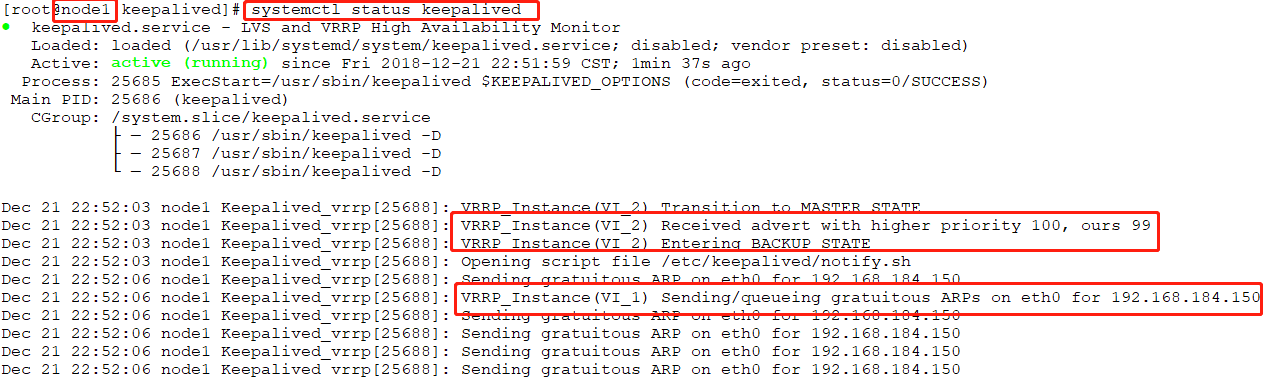
在192.168.184.141即master主机上查看IP,可以看到VIP在此主机上

此时在浏览器中访问VIP即可查看:


下面把node1上的nginx服务下线,查看VIP是否能自动把VIP转移到node2上:
# systemctl stop nginx


# ip addr list

# systemctl status keepalived


再次使用浏览器访问时,node2依然可以把用户请求分发到后端的upstream组
其实作为高可用的备节点时,主机上的nginx服务是不启动的,只有主机是MASTER才启动nginx服务。
有一个问题:当两台keepalived高可用nginx代理服务时,那么当master主机上的nginx代理服务工作正常时,backup节点上的nginx代理服务是否要先停掉?
最好的办法是backup节点的nginx代理服务一直在线。
假如master节点只是nginx服务进程故障,而其他服务完好,那么就让nginx服务只需重启即可,如何让nginx自动重启?
# vim notify.sh //两台主机都要修改
1 #!/bin/bash 2 # 3 4 vip=172.168.184.150 5 contact='root@localhost' 6 7 notify() { 8 mailsubject="`hostname` to be $1: $vip floating" 9 mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1" 10 echo $mailbody | mail -s "$mailsubject" $contact 11 } 12 13 case "$1" in 14 master) 15 notify master 16 systemctl restart nginx.service //当主机成为主节点时启动起来 17 exit 0 18 ;; 19 20 backup) 21 notify backup 22 systemctl restart nginx.service //当成为备节点时也重启 23 exit 0 24 ;; 25 fault) 26 notify fault 27 exit 0 28 ;; 29 30 *) 31 echo 'Usage: `basename $0` {master|backup|fault}' 32 exit 1 33 esac
# scp notify.sh node2://etc/keepalived/
# systemctl stop nginx //此时这里会发现其实master节点上的nginx代理是无法停止的,因为当master转为backup时,notify.sh依然重启backup上的
//nginx服务,除非master节点上nginx因为故障无法启动或者master宕机或者80端口被占用。
# systemctl stop nginx;systemctl start httpd //此时master的nginx就无法启动了
# systemcctl stop httpd //此时nginx会自动启动的

以上就是利用keepalived高可用nginx代理服务
以上是单主模型,双主模型如何配置?双主模型时,两台master都在向后做负载均衡调度。
基于以上配置,再做修改
# vim keepalived //两台都要修改
1 ! Configuration File for keepalived 2 3 global_defs { 4 notification_email { 5 root@localhost 6 } 7 notification_email_from kaadmin@localhost 8 smtp_server 127.0.0.1 9 smtp_connect_timeout 30 10 router_id LVS_DEVEL 11 #vrrp_mcast_group4 224.0.1.118 12 vrrp_skip_check_adv_addr 13 vrrp_strict 14 vrrp_garp_interval 0 15 vrrp_gna_interval 0 16 } 17 18 vrrp_script chk_mt { 19 script "/etc/keepalived/down.sh" 20 interval 1 21 weight -2 22 } 23 24 vrrp_script chk_nginx { 25 script "/etc/keepalived/chk.sh" 26 interval 1 27 weight -10 28 } 29 30 vrrp_instance VI_1 { 31 state MASTER 32 interface eth0 33 virtual_router_id 51 34 priority 100 35 advert_int 1 36 authentication { 37 auth_type PASS 38 auth_pass 1111 39 } 40 virtual_ipaddress { 41 192.168.184.150/32 42 } 43 track_script { 44 chk_nginx 45 } 46 notify_master "/etc/keepalived/notify.sh master" 47 notify_backup "/etc/keepalived/notify.sh backup" 48 notify_fault "/etc/keepalived/notify.sh fault" 49 } 50 51 vrrp_instance VI_2 { //添加实例2,红色加粗部分是需要修改的地方 52 state BACKUP 53 interface eth0 54 virtual_router_id 52 55 priority 99 56 advert_int 1 57 authentication { 58 auth_type PASS 59 auth_pass 2222 60 } 61 virtual_ipaddress { 62 192.168.184.151/32 63 } 64 track_script { 65 chk_nginx 66 } 67 notify_master "/etc/keepalived/notify.sh master" 68 notify_backup "/etc/keepalived/notify.sh backup" 69 notify_fault "/etc/keepalived/notify.sh fault" 70 }
# vim notify.sh //修改
1 #!/bin/bash 2 # 3 4 vip=172.168.184.150 5 contact='root@localhost' 6 7 notify() { 8 mailsubject="`hostname` to be $1: $vip floating" 9 mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1" 10 echo $mailbody | mail -s "$mailsubject" $contact 11 } 12 13 case "$1" in 14 master) 15 notify master 16 # systemctl restart nginx.service //此处就需要注销了,因为在双主模型下,假如主机1上的实例1故障,那么主机1上的实例2就会成为此主机的master,如果此时成为master还要重启, 17 exit 0 //那么主机2上的master同样也要重启,因为主机1上的实例2就是主机2上的实例1.下面 backup) 原理同样 18 ;; 19 20 backup) 21 notify backup 22 # systemctl restart nginx.service 23 exit 0 24 ;;
fault) 25 notify fault 26 exit 0 27 ;; 28 29 *) 30 echo 'Usage: `basename $0` {master|backup|fault}' 31 exit 1 32 esac 33
# vim keepalived.conf 在主机2即192.168.184.142上配置,这里的添加的内容和主机1上的实例2保持一致即可
vrrp_instance VI_2 { state MASTER //变为主节点 interface eth0 virtual_router_id 52 priority 100 //优先级提高 advert_int 1 authentication { auth_type PASS auth_pass 2222 } virtual_ipaddress { 192.168.184.151/32
#192.168.184.151/32 dev eno16777736 label eno16777736:2 //注意如果是长网卡名,可以这样修改
} track_script { chk_nginx } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" }
此时两台主机的keepalived是完美的





两台新添加的VIP实现了双主模型,同时同时可以利用nginx代理服务对后端的upstream进行负载均衡
# systemctl stop nginx //此时把node1上的nginx代理服务停掉,它是不会重启的。所以在node1上的VIP:192.168.184.150就转移到node2上了

查看node2上的IP,可以看出150和151都在node2上
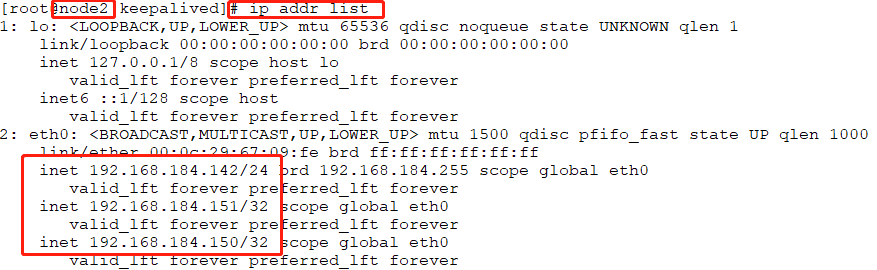
此时在对两个VIP:192.168.184.151和192.168.184.152进行访问时,依然都会得到之前的响应
此时如果手动把node1节点上的nginx代理服务启动起来的话,node1就会把master:192.168.184.150夺回来。
以上原理是这样的:
在node1上master是192.168.184.150,backup是192.168.184.151
在node2上master是192.168.184.151,backup是192.168.184.150
当node1的nginx代理服务故障时,node1就无法提供服务,无论是master还是backup都不再起作用,此时如果node2上的nginx代理服务是正常的,node2上的backup即node1上的master就会把node1上的VIP抢过来附加在node2上的网卡上,此时node2上就会有两个VIP,一主一丛同时工作了。
双主节点如何发挥作用?通过DNS做轮询,通过ipvs或nginx代理服务负载均衡至后端的real server或者upstream,
如果基于会话绑定的话,会有一定的风险,因为首先客户端的访问会先经过DNS域名解析后得到高可用其中一台director的IP地址,然后客户端访问IP地址,假如director1采用的算法是IP hash算法,那么来自客户端的同一个请求将始终定向至同一个upstream sever,假如客户端清空了DNS缓存,那么此时DNS解析的结果就有可能定向至另一个director,那么就有50%的可能此次客户端的请求被调度至另一个upstream server。
使用会话保持的场景,除了对缓存服务器外,其他很少用,一般会话信息都保存在session server
另外一种场景,如果nginx代理服务后是缓存服务器,采用什么算法?建议使用DH算法,但DH算法nginx不支持,虽然LVS支持DH算法,但是LVS无法理解URL,所以没有意义。要做的是不但可以分析URL,还要能把同一个URL发送到同一个缓存服务器。
对用户的请求做哈希http://www.zsythink.net/archives/1182
数据不变,多次计算哈希结果就不变。把哈希结果编码成16进制的数字,用这个数字对后端的服务器数量取模,因为不管哈希值是多少,除2取模后要么是1要么是0,如果用户请求的URL不变,那么哈希计算结果是不变的,对后端服务器取模的结果也不会改变。
博客作业:
keepalived 高可用 ipvs
nginx