之前用.Net做过一些自动化爬虫程序,听大牛们说使用python来写爬虫更便捷,按捺不住抽空试了一把,使用Python抓取百度街景影像。
这两天,武汉迎来了一个德国总理默克尔这位大人物,又刷了一把武汉长江大桥,今天就以武汉长江大桥为例,使用Python抓取该位置的街景影像。

百度街景URL分析
基于http抓包工具,可以很轻松的获取到浏览百度街景时的http请求数据。如下图所示,即是长江大桥某位置点街景影像切片:

该切片对应的URL请求为:
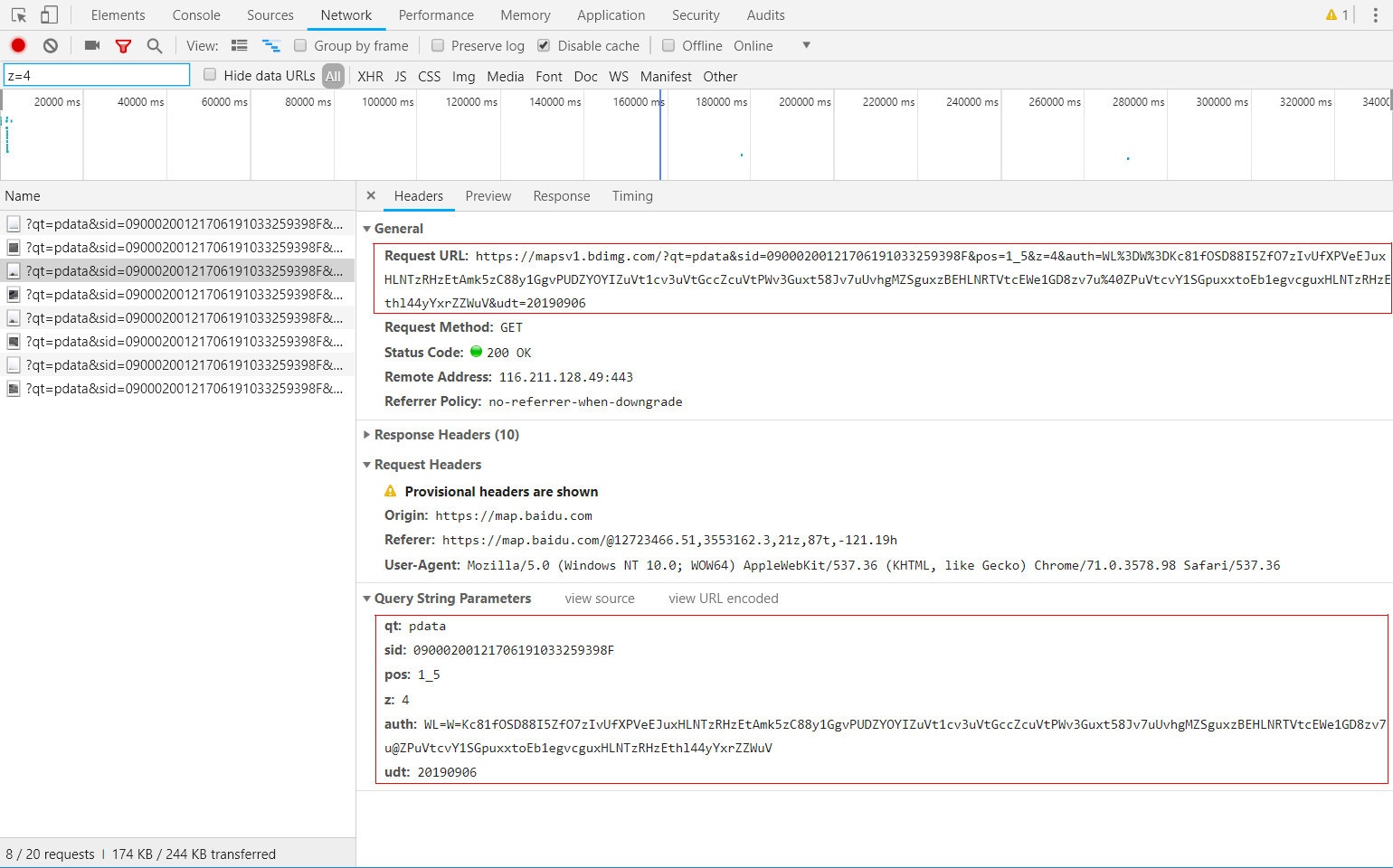
细致分析该URL请求,并经过模拟测试,可以总结出如下初步结论
请求影像切片所需的几个关键参数分别为:
① sid:代表某个具体的街景点位;
② pos:代表该切片在完整的全景影像图上的切片坐标;
③ z:代表街景影像切片级别。
单个位置的街景影像图可以生产出多种级别的切片,不同的级别下,切片的数量是不同的;切片的坐标使用行号、列号予以区分。
明确了以上百度街景影像的切片规则,就可以用代码开撸了。
Python源码
要求:一次性抓取连续10个全景点的所有级别切片信息。
源码如下:
import urllib2
import threading
from optparse import OptionParser
# from bs4 import BeautifulSoup
import sys
import re
import urlparse
import Queue
import hashlib
import os
def download(url, path, name):
conn = urllib2.urlopen(url)
if not os.path.exists(path):
os.makedirs(path)
f = open(path + name, 'wb')
f.write(conn.read())
f.close()
fp = open("E:\Workspaces\Python\panolist.txt", "r")
for line in fp.readlines():
line = (lambda x: x[1:-2])(line)
# url = line
for zoom in range(1, 6):
row_max = 0
col_max = 0
row_max = pow(2, zoom - 2) if zoom > 1 else 1
col_max = pow(2, zoom - 1)
for row in range(row_max):
for col in range(col_max):
z = str(zoom)
y = str(row)
x = str(col)
print(y + "_" + x)
url = line + "&pos=" + y + "_" + x + "&z=" + z
path = "E:\Workspaces\Python\pano\" + url.split('&')[1].split('=')[1] + "\" + z + "\"
name = y + "_" + x + ".jpg"
print url
print name
download(url, path, name)
fp.close()
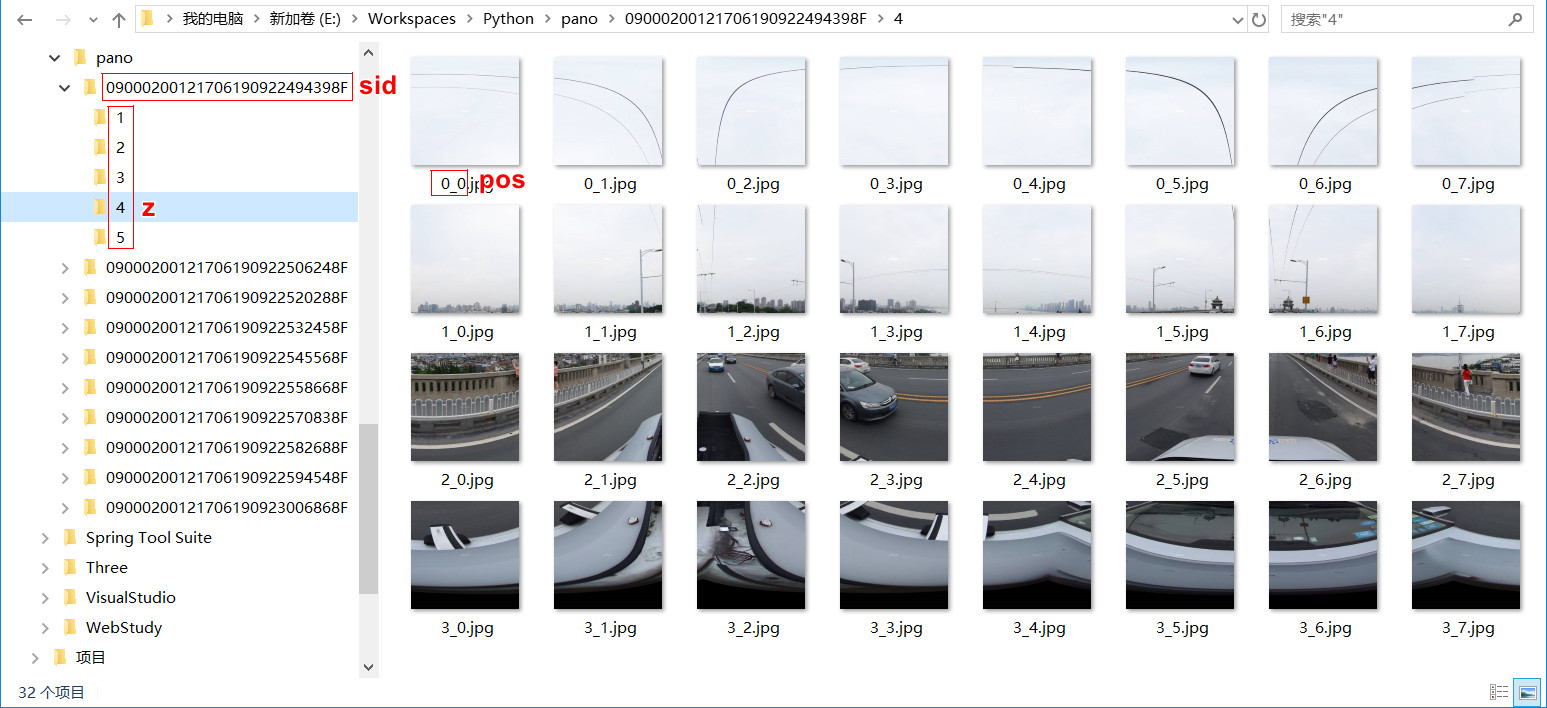
抓取结果如下,按上述分析的规则进行本地化存储,可以看到各级别下,所有的切片拼接起来,刚好是一张完整的全景图。
小结
① Python这门语言真的是蛮便捷,安装和配置都十分方便,也有很多IDE都支持,我初次使用,遇上问题就随手查Python语言手册,基本上半天完成该代码示例。
② 在爬虫程序方面,Python相关资源十分丰富,是爬虫开发的一把利器。
上述代码简要的实现了批量抓取百度街景影像切片数据,大量使用的话,建议继续处理一下,加上模拟浏览器访问的处理,否则很容易被服务方直接侦测到来自网络爬虫的资源请求,而导致封堵。
附 python爬虫入门(一)urllib和urllib2 https://www.cnblogs.com/derek1184405959/p/8448875.html