春节前想看一部美剧,可惜在爱奇艺、腾讯视频上都没有资源,然后找呀找,发现了一个网站“80s手机电影网”,在这上面可以找到我想看的那部剧,不过当时还没放假,就想着白天下载好,周末再一口气看完
所以就有了一个想法:这次不用迅雷下载,看看能不能爬虫下来
OK,想到就做
1. 分析网站
网站首页如下
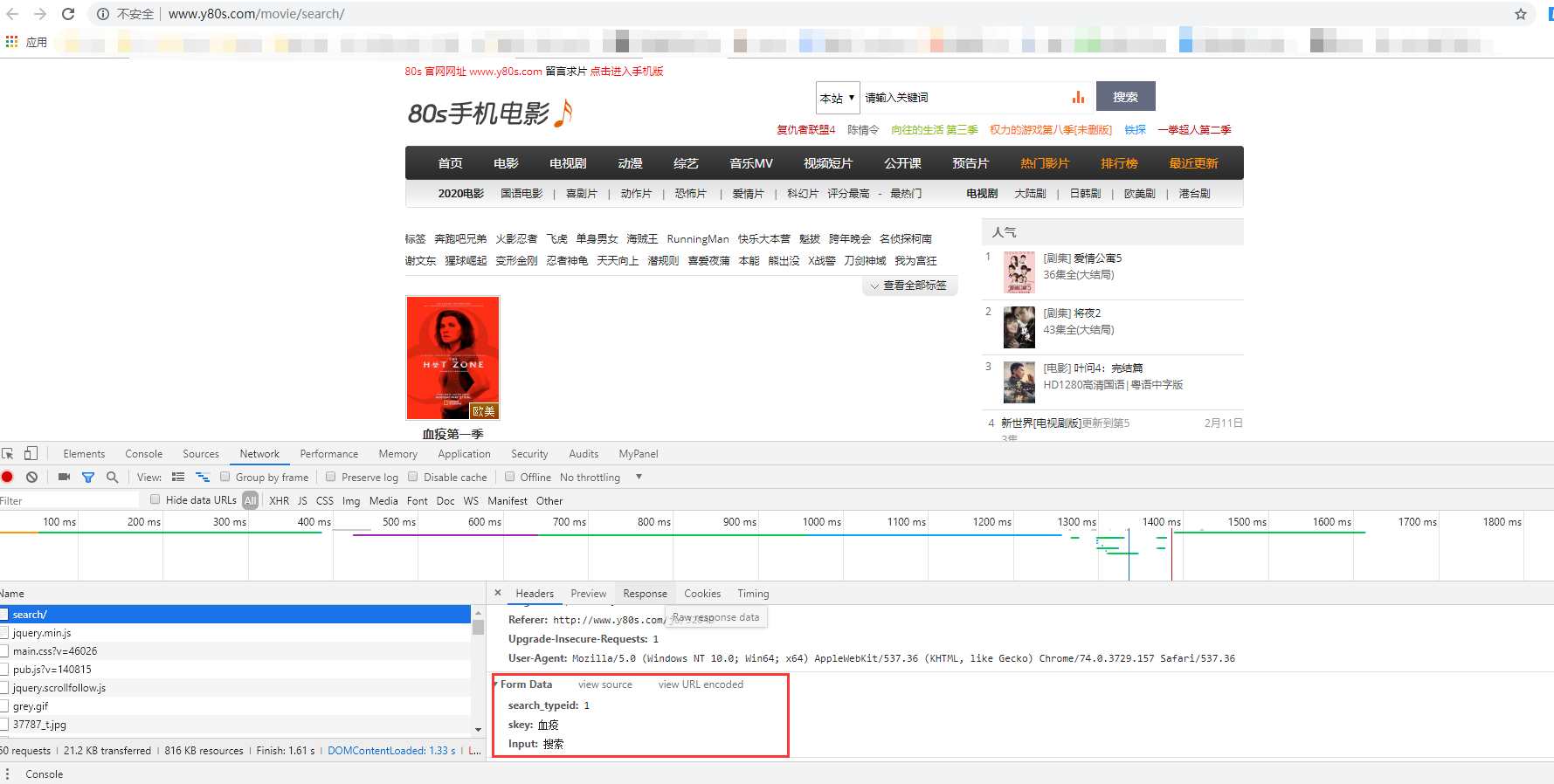
(1)先搜索一下剧名,点击搜索后,会新打开一个网页,显示搜索结果
从下图中可以看到初始的请求url以及对应的请求参数
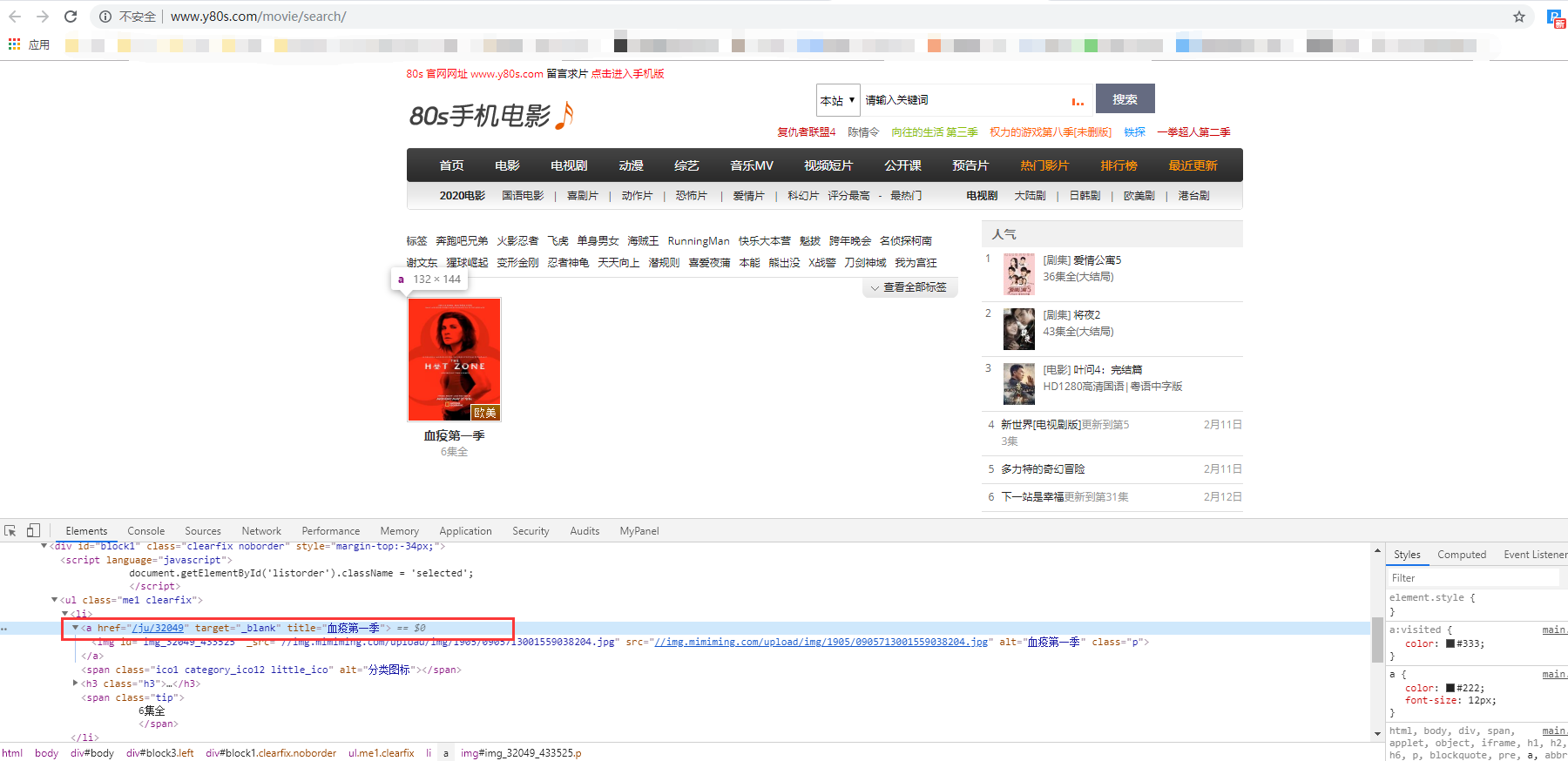
(2)然后再来看看这个页面的html内容
重点记住这个里面的一个数字:32049,后面会用到
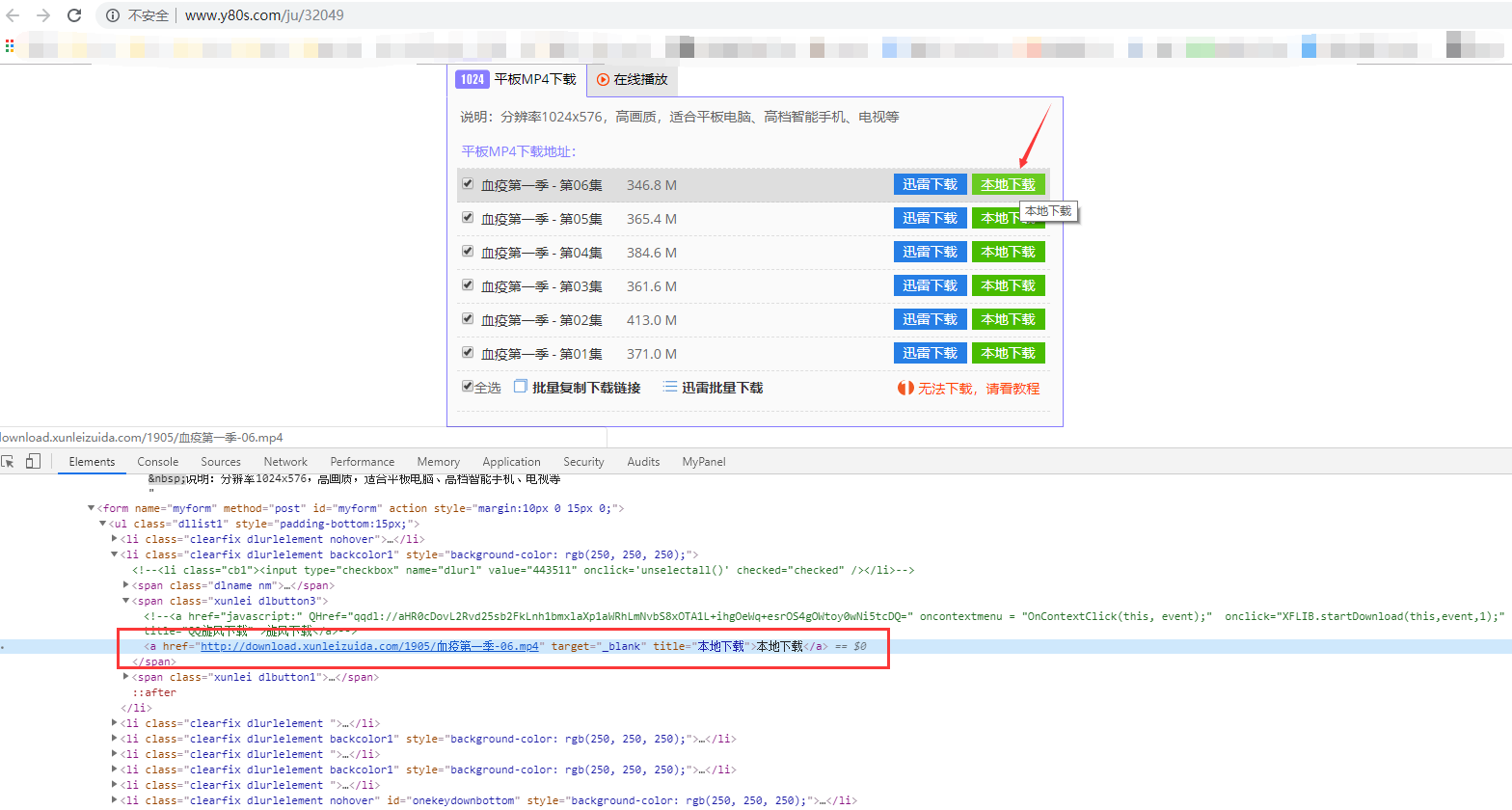
(3)再继续点击搜索结果,会跳转到对应的剧集列表页,如下
这个页面有2个重点,
一是url中的后缀数字“32049”,它就是上个页面让你记住的数字;
另一个是看下每一集对应的html内容,可以发现每一集都有一个href链接,点一下这个href链接其实浏览器就能自动下载这一集的内容了(这就比较简单了,直接爬这个url就行,不用做其他处理)
综上,要爬这部剧,需要如下2个步骤
(1)请求初始的搜索url,提取每部剧对应的数字,如32049
(2)根据32049请求剧集列表url,提取每一集对应的下载链接
2. 实际代码
(1)提取电视剧id
有很多地方都有剧名对应的数字,这里我提取title属性为剧名的a标签,然后用正则提取href中的数字
关于如何在python中使用正则表达式,可以参考:在python中使用正则表达式(一)、在python中使用正则表达式(二)、在python中使用正则表达式(三)

1 def get_tv_id(self, tv_name): 2 """获取所查询电视剧对应的id""" 3 headers = { 4 "Content-Type": "application/x-www-form-urlencoded" 5 } 6 7 data = { 8 "search_typeid": "1", 9 "skey": tv_name, # 用一个变量来表示要搜索的剧名 10 "Input": "搜索" 11 } 12 13 url = "http://www.y80s.com/movie/search/" # 请求url 14 15 response = self.get_html(url, data, headers, "post") 16 17 html = response 18 # print(html) 19 20 soup = BeautifulSoup(html, "html.parser") 21 name_label = soup.find_all("a", title=tv_name) # 获取所有title属性为影视剧名称的<a>标签,用一个变量来动态表示剧名 22 # print(soup.prettify()) 23 # print(name_label) 24 # print(name_label[0].get('href')) 25 26 ju_id = re.compile(r'(d+)', re.S) # 定义一个正则表达式,提取标签内容中的数字 27 if name_label: 28 href_value = ju_id.search(name_label[0].get('href')) 29 if href_value: 30 tv_id = href_value.group() 31 print("查询影视剧对应的id为:{}".format(tv_id)) 32 # print(type(tv_id)) # 查看获取到的tv_id的数据类型,如果是int的话,在后续拼接时需要使用str()转成字符串 33 return tv_id
(2)提取剧集列表中的下载url
首先用上一步获取的剧名id拼接请求url,然后提取每一集的下载url即可
1 def get_tv_url(self, tv_name): 2 """获取电视剧的下载url""" 3 tv_id = self.get_tv_id(tv_name) # 调用get_tv_id()方法,获取tv_id 4 url = "http://www.y80s.com/ju/" + tv_id # 利用tv_id拼接url 5 6 r = self.get_html(url,method="get") 7 html = r 8 soup = BeautifulSoup(html, "html.parser") 9 a_tv_url = soup.find_all("a", title="本地下载") # 提取title属性为"本地下载"的a标签,返回一个包含所有a标签的列表 10 # print(a_tv_url) 11 tv_url = [] 12 for t in a_tv_url: 13 tv_url.append(t.get('href')) # 用get方法获取每个a标签中的href属性值 14 print(tv_url) 15 return tv_url
整体代码
1 # coding: utf-8 2 """ 3 author: 我是冰霜 4 describe: 爬虫80s电影网 5 create_time: 2020/01/18 6 """ 7 8 import re 9 from bs4 import BeautifulSoup 10 from requests.exceptions import RequestException 11 import requests 12 13 class DownloadTV: 14 @staticmethod 15 def get_html(url, data=None, header=None, method=None): 16 """获取一个url的html格式文本内容""" 17 18 if method == "get": 19 response = requests.get(url, params=data, headers=header) 20 else: 21 response = requests.post(url, data=data, headers=header) 22 try: 23 if response.status_code == 200: 24 response.encoding = response.apparent_encoding 25 # print(response.status_code) 26 # print(response.text) 27 return response.text 28 return None 29 except RequestException: 30 print("请求失败") 31 return None 32 33 def get_tv_id(self, tv_name): 34 """获取所查询电视剧对应的id""" 35 headers = { 36 "Content-Type": "application/x-www-form-urlencoded" 37 } 38 39 data = { 40 "search_typeid": "1", 41 "skey": tv_name, # 用一个变量来表示要搜索的剧名 42 "Input": "搜索" 43 } 44 45 url = "http://www.y80s.com/movie/search/" # 请求url 46 47 response = self.get_html(url, data, headers, "post") 48 49 html = response 50 # print(html) 51 52 soup = BeautifulSoup(html, "html.parser") 53 name_label = soup.find_all("a", title=tv_name) # 获取所有title属性为影视剧名称的<a>标签,用一个变量来动态表示剧名 54 # print(soup.prettify()) 55 # print(name_label) 56 # print(name_label[0].get('href')) 57 58 ju_id = re.compile(r'(d+)', re.S) # 定义一个正则表达式,提取标签内容中的数字 59 if name_label: 60 href_value = ju_id.search(name_label[0].get('href')) 61 if href_value: 62 tv_id = href_value.group() 63 print("查询影视剧对应的id为:{}".format(tv_id)) 64 # print(type(tv_id)) # 查看获取到的tv_id的数据类型,如果是int的话,在后续拼接时需要使用str()转成字符串 65 return tv_id 66 67 def get_tv_url(self, tv_name): 68 """获取电视剧的下载url""" 69 tv_id = self.get_tv_id(tv_name) # 调用get_tv_id()方法,获取tv_id 70 url = "http://www.y80s.com/ju/" + tv_id # 利用tv_id拼接url 71 72 r = self.get_html(url,method="get") 73 html = r 74 soup = BeautifulSoup(html, "html.parser") 75 a_tv_url = soup.find_all("a", title="本地下载") # 提取title属性为"本地下载"的a标签,返回一个包含所有a标签的列表 76 # print(a_tv_url) 77 tv_url = [] 78 for t in a_tv_url: 79 tv_url.append(t.get('href')) # 用get方法获取每个a标签中的href属性值 80 print(tv_url) 81 return tv_url 82 83 84 if __name__ == '__main__': 85 test = DownloadTV() 86 test.get_tv_url("血疫第一季")
运行一下
