一 shell脚本的编写&基础语法:
1 条件判断:
数字比较:
-eq 等于;-ne 不等于;-gt 大于;-lt 小于;-ge 大于等于;-le 小于等于;
字符串比较
不相等 "$A" !="$B" 相等"$A" =="$B"
2 循环:
while true循环:
while :
do
内容
done
while循环
while [ $i -le 100 ]
do
let i+=2
done
for循环,可以遍历指定数组;
a=(1 2 3 4 6 7 8 9 10 11 12 13)
for i in "${!a[@]}";
do
echo "${a[$i]}"
done
3 $?返回上一条指令结果:
function add(){
return `expr $1 + $2`
}
add 23 50 #此处返回73
if [ $? -eq 73 ]
then
echo "yyy $?"
else
echo "nnn $?"
fi
注:结果输出为yyy 0;因为18行返回的是16行的结果;
4 获得键盘输入:
read -p "are you ok?(y/n)" to_continue
if [ -z $to_continue ] #结果为空
then
exit -1
else
if [ $to_continue != 'y' ] #结果不等于y
then
echo "exit"
exit -1
fi
fi
5 获取文件中每一行数据,并输出
cat 文件名 | while read line
do
echo $line
done
6 带颜色的字体输出
字体颜色
#30:黑 ;#31:红 ;#32:绿 ;#33:黄 ;#34:蓝色 ;#35:紫色 ;#36:深绿 ;#37:白色
背景颜色
#40:黑 ;#41:深红 ;#42:绿 ;#43:黄色 ;#44:蓝色 ;#45:紫色 ;#46:深绿 ;#47:白色
echo -e "e[47;35m你好e[0m"白底紫字
7 输出结果到屏幕(控制台)同时写入文件
假设run.sh有输出,则
sh run.sh | sed "w log"
结果写入log;
输入一条命令的同时,利用tee命令将结果输出到文件,例如ifconfig | tee ifconfig.log
8 shell中引号的区别:单引号,双引号,反引号(一般是键盘ESC下边那个)
上代码:
name=tim
echo '1 $name has $800'
echo "2 $name has $800"
echo '3 $name has $800'
echo "4 $name has $800"
echo '5 ls ./'
echo "6 ls ./"
echo `ls ./`
输出:
1 $name has $800
2 tim has 00
3 $name has $800
4 tim has $800
5 ls ./
6 ls ./
文件列表
说明:
1 单引号将所有内容当做字符,一视同仁,忽略所有的命令和特殊字符;双引号可以包含特殊字符并解析,并且需要输出特殊字符,需要加;反引号内部是一个命令,会先执行命令,然后返回结果;
2 输出说明:
1是单引号,所以直接输出结果;2是双引号,所以对$name进行解析;3是单引号,同1;4想输出$字符,加转义字符;5,6直接输出;7 执行ls操作,返回文件列表;
9 字符串操作
字符串拼接:
str1=“”
str1=$str1"xxxx "
二 .sh脚本成熟的代码段,操作命令集锦
1 喜闻乐见的小指令:
a 一句话指令
du -sh/du -sh *
du -sh * | sort -h -r 按照大小排序;
df -h
gdb --args
find . -name "*.cpp"|xargs cat|wc -l 统计代码行数;
find ./file/ -size +2M 查找file文件夹下文件尺寸大于2M的文件;
b 软链
建立软链 ln -s 实际存在文件 目标文件;
删除软链 rm ./软链文件名
对软链文件的操作,等同于对原文件的操作;
c 查看机器信息
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l,查看有多少个CPU;
cat /proc/cpuinfo| grep "cpu cores"| uniq 每个CPU对应的核数;
一般机器是两个CPU,里面多核;
查看centos系统版本:cat /etc/redhat-release;
d 计算文本中某一列的均值,grep -r 某些关键字符串 文件 | awk '{sum += $8}END{print sum/NR}'
awk缺省的切分是空格,如果需要按照:来切分,则需要修改脚本为:grep 某字符串 ./log文件 | awk -F ':' '{print $17}' | awk '{sum+=$1}END{print sum/NR}' 注意:-F设置分割符号
e 查看端口是否被占用
ss -lntpd 展示所有端口;
ss -lntpd | grep :22 寻找端口号22被什么程序占用;
g ls
ls 显示当前文件夹下所有文件
ll/ls -l ,(a) + 显示一些细节信息,名称排序
ls -lt (b) + 按照时间排序/ls -t,仅按照时间排序;
ls -R 若目录下有文件,则以下之文件亦皆依序列出;
ls -r 将文件以相反次序显示(原定依英文字母次序)
ls -S/ls -Sr,按照文尺寸,从大到小/从小到大排序;
ls -Sl / ls -Slr or ll -S / ll -Sr 按照文尺寸,从大到小/从小到大排序,显示详细信息;
ls -h 表示”–human-readable”,单位是k或者M ,比较容易看清楚结果
2 sort 对ip排序:
命令说明:
”-t” : 表示以那个字符做分割
“-k” :和-t结合使用,表示取那一段为关键字进行排序,后面跟数据,1…n,表示取第几段,也可以是范围如1,3,表示将第1段到第3段作为一个整体来排序
“-n” :以数字进行排序
“-r” :倒序
# 按升序排序
sort -t'.' -k1,1n -k2,2n -k3,3n -k4,4n ip.txt
# 按降序排序
sort -t'.' -k1,1nr -k2,2nr -k3,3nr -k4,4nr ip.txt
3 查看机器/程序信息
lscpu 查看cpu 信息;
查看centos系统版本:cat /etc/redhat-release
rpm -e gcc-4.4.6-4.tl1.x86_64删除已有gcc版本;
rpm -q gcc 检查是否安装;
yum info gcc 查看自带的gcc版本
rpm -Uvh *.rpm 安装rpm;
ps(Process Status)
PID,进程分配的id;PPID,该id的父id;
ps -ef,显示所有进程信息,连同命令行
ps -aux 列出目前所有的正在内存当中的程序,比ps -ef多了内存,cpu等信息;
显示某个进程占用内存,命令:
ps -ef | grep "xx name" |grep -v grep |grep -v gdb| awk '{print $2}' | xargs -I {} cat /proc/{}/status |grep -e VmRSS |awk '{printf $2/1048576;print "GB"}'
grep -v 排除掉含有某些内容的行;
程序信息存储在/proc/{}/status 中,VmRss是内存信息;
xargs 的一个选项 -I,使用 -I 指定一个替换字符串 {},这个字符串在 xargs 扩展时会被替换掉,当 -I 与 xargs 结合使用,每一个参数命令都会被执行一次:
示例:ls *.js | xargs -t -I '{}' mv {} {}.backup
mv a.js a.js.backup
mv b.js b.js.backup
三 linux基础定义
1 ~/.bashrc
这个可以认为是linux系统的启动项,每次启动的时候都会运行一些这里边的命令;
常见的有:
alias rm='rm -i'//修改某些指令;
export LD_LIBRARY_PATH=……//制定环境变量;LD_LIBRARY_PATH是linux系统的环境变量,直接去其目录下去找lib库等;
2 gcc
gcc(gnu collect compiler)是一组编译工具的总称;它主要完成的工作任务是“预处理”和“编译”,以及提供了与编译器紧密相关的运行库的支持,如libgcc_s.so、libstdc++.so等;
3 glibc
glibc是gnu发布的libc库,也即c运行库。glibc是linux系统中最底层的api(应用程序开发接口),几乎其它任何的运行库都会倚赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现,主要的如下:
(1)string,字符串处理
(2)signal,信号处理
(3)dlfcn,管理共享库的动态加载
(4)direct,文件目录操作
(5)elf,共享库的动态加载器,也即interpreter
(6)iconv,不同字符集的编码转换
(7)inet,socket接口的实现
(8)intl,国际化,也即gettext的实现
(9)io
(10)linuxthreads
(11)locale,本地化
(12)login,虚拟终端设备的管理,及系统的安全访问
(13)malloc,动态内存的分配与管理
(14)nis
(15)stdlib,其它基本功能
4 binutils
binutils提供了一系列用来创建、管理和维护二进制目标文件的工具程序,如汇编(as)、连接(ld)、静态库归档(ar)、反汇编(objdump)、elf结构分析工具(readelf)、无效调试信息和符号的工具(strip)等。通常,binutils与gcc是紧密相集成的,没有binutils的话,gcc是不能正常工作的;
5 linux下边的文件夹及其作用;
data
etc
mnt 一般是空的,用于挂载其他文件系统;
opt
usr:系统级的目录,可以理解为C:/Windows/,/usr/lib理解为C:/Windows/System32。
/usr/local:用户级的程序目录,用户自己安装的软件会装在这里;
opt:用户级的程序目录,可以理解为D:/Software,opt有可选的意思,这里可以用于放置第三方大型软件(或游戏),当你不需要时,直接rm -rf掉即可。在硬盘容量不够时,也可将/opt单独挂载到其他磁盘上使用。
lib -> usr/lib,存放系统库;
lib64 -> usr/lib64;
bin -> usr/bin;
sbin -> usr/sbin;
四 linux基础操作
1 git相关
git配置:
cat ~/.ssh/id_rsa.pub #检查是否已经有SSH key pair
ssh-keygen -t rsa -C "name" #生成SSH key pair
cat ~/.ssh/id_rsa.pub #获取SSH key pair,将其copy到git网页版本的ssh keys的页面上即可;
配置完成,直接clone代码即可;
git常用命令:
git clone https://github.com/kaldi-asr/kaldi // 从网上复制代码;
git branch //查看本地分支信息;
git branch -a //查看所有分支,包括非本地的分支
git checkout -b 本地分支名 origin/远程分支名;eg:git checkout -b new_v origin/new_v //从远程将分支拉取至本地;
git push 代码仓库名 远程分支名:本地分支名;eg:git push origin new_a:new_a//本地提交代码;
一般可以直接git push完成操作,默认推到当前分支;
git checkout . //代码还原;
git checkout + 分支名;//代码切换至分支;
git reset --hard +提交编号;//将代码回退到某次提交
查看用户信息:
git config user.name
git config user.email
修改用户名和邮箱地址:
git config --global user.name "xxxx"
git config --global user.email "xxxx"
2 crontab
作用:相当于时钟,可以定时完成某个操作;
命令:
crontab -u root -e r l
-e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI;也可以直接打开/etc/crontab编辑;
-r : 删除目前的时程表,注:是全部删除,慎用;
-l : 列出目前的时程表
内部格式:
* * * * * 操作
- - - - -
| | | | |
| | | | +----- 星期中星期几 (0 - 7) (星期天 为0)
| | | +---------- 月份 (1 - 12)
| | +--------------- 一个月中的第几天 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)
举例:
0 */2 * * * oper 意思是每两个小时oper一下
*/2 * * * * oper 每两分钟oper一下
50 7 * * * oper 每天7:50oper
50 22 * * * oper 每天22:50
0 0 1,15 * * oper 每月1号和15号
1 * * * * oper 每小时的第一分
00 03 * * 1-5 oper 每周一至周五3点钟,
30 6 */10 * * ls 意思是每月的1、11、21、31日是的6:30执行一次ls命令
注:一般root账户,可以设置user,如果是非root账户,无需在crontab -e中设置账户,默认就是当前账户;crontab失效原因一般是:路径和权限错误,特别是sh文件,里边需 加上bin/bash等信息;
crond 是linux执行周期性任务的守护进程,命令如下:
service crond start //启动服务
service crond stop //关闭服务
service crond restart //重启服务
service crond reload //重新载入配置
service crond status //查看crontab服务状态:
注:crond一般是打开的,这时候执意要你crontab -e,就会自动的更新,无需重启等操作;
3 时间相关操作
3.1 获取当前时间
$(date +"%Y-%m-%d %H:%M:%S")
计算某个程序的耗时;代码如下:
startTime_s=`date +%s`
operateXXX
endTime_s=`date +%s`
sumTime=$[ $endTime_s - $startTime_s ]
echo "time cost : $sumTime s"
如何将耗时以s统计的,换成以分钟,小时统计的呢?
可以直接使用[],如下,不过这种方式都是int数除法,比如4/3 = 1;
echo "cost : $sumTime s = $[sumTime/60] m = $[sumTime/3600] h"
如果需要小数,可以使用bc工具,用scale控制保留几位小数;
time_m=`echo "scale=2; $sumTime/60 " | bc`
time_h=`echo "scale=2; $sumTime/3600 " | bc`
echo "time cost : $sumTime s = $time_m m = $time_h h ----"
也可不使用time_m,直接加到命令中,如下;
echo "time cost : $sumTime s = `echo "scale=2; $sumTime/60 " | bc` m = `echo "scale=2; $sumTime/3600 " | bc` h"
3.2 指令修改系统时间
date 查看目前系统时间;
更新时间如下:
date -s 20201103
date -s 18:32:23
4 vim
4.1 文件编码改变
vim 内部修改
set fileencoding 查看当前文件编码;
set fenc=gbk 将文件设置成gbk模式;
外部修改
file 指令,查看文件类型;
iconv -f UTF-8 -t GBK text_1 -o text_2
iconv -f GBK -t UTF-8 text_gbk -o text_1
4.2 vim设置,在~/.vimrc文件中,之间copy弄好的~/.vimrc,~/vim即可;
syntax enable#语法高亮
highlight LineNr cterm=bold ctermfg=red#行号,前景色红色
highlight LineNr cterm=bold ctermbg=white#行号,背景色白色
set t_Co=256#鼠标批量选中部分颜色灰色
set cursorline#光标线
set colorcolumn=120#有条竖线
4.3 查看当前文档缩进是空格,还是tab : set list,^I是tab;将当前文件tab->空格: :%s/ / /g
5 scp
5.1 远程拷贝,命令:2 scp -r 源位置 目标位置,跨服务器拷贝;
5.2 不需要二次输入密码,使用nohup,并且不在控制台显示信息;
a nohup sshpass -p "密码" scp -r 要拷贝的文件 目标路径 > scp_log 2>&1 &
b nohup sshpass -p "密码" scp -r 要拷贝的文件 目标路径 &
说明:
sshapass -p 设定密码scp,无需每次输入密码;
a比b的优势是a直接将结果输入到scp_log中,b默认输出到nohup文件,并在控制台显示;
nohup 操作 & 意思执行操作,忽略所有挂断信号;
5.3 scp失效,一般是机器存储了错误的公匙,找到本机/root/.ssh/known_hosts,删除错误ip即可,下次会显示
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '[ip]:36000' (ECDSA) to the list of known hosts.
root@ip's password:
完成一次成功的scp之后,你会发现你删掉的那行有出现了在/root/.ssh/known_hosts文件中;
注:从A机器传文件到B机器,known_hosts在A机器中;另,不同用户在同一台机器上,使用不同的known_hosts;
6 环境变量
6.1 linux 路径前缀
有时候前缀太长了,耽误我们做事情,可以修改一下;
查看当前前缀:
echo $PS1
临时修改:
export PS1='u@100.100.1.1:w#'----u 用户名;w 完整路径;W 当前路径名,即,用户名@ip:路径;这样做的好处是要copy到别的环境,直接复制即可;
export PS1='W#' ----常用,直接设置成当前文件名,清爽;
永久修改:
vim ~/.bashrc
将上述操作写入文件即可;这个可以认为是初始化操作;
6.2 添加库到环境变量
echo $LD_LIBRARY_PATH //查看环境变量
export LD_LIBRARY_PATH=/data1/kaldi/tools/openfst/lib/:$LD_LIBRARY_PATH //加入到环境变量
永久添加:
vim ~/.bashrc
export LD_LIBRARY_PATH=/opt/intel/mkl/lib/intel64/:/usr/local/cuda/lib64:$LD_LIBRARY_PATH
其中~/.bashrc类似于系统的启动项,每次启动前运行他;所以可以把很多需要开始时候定义的东西加进去;
7 linux账户管理
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统;用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护;
7.1 用户账号的管理:
a 增 : useradd 选项 用户名
参数说明:
选项:
-c comment 指定一段注释性描述;
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录;
-g 用户组 指定用户所属的用户组;
-G 用户组,用户组 指定用户所属的附加组;
-s Shell文件 指定用户的登录Shell;
-u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号;
-p 设置密码,必须是秘文,不建议使用;
用户名 : 指定新账号的登录名;
举例:
实例1 # useradd –d /home/sam -m sam
此命令创建了一个用户sam,其中-d和-m选项用来为登录名sam产生一个主目录 /home/sam(/home为默认的用户主目录所在的父目录);
实例2 # useradd -s /bin/sh -g group –G adm,root gem
此命令新建了一个用户gem,该用户的登录Shell是 /bin/sh,它属于group用户组,同时又属于adm和root用户组,其中group用户组是其主组;
这里可能新建组:#groupadd group及groupadd adm
增加用户账号就是在/etc/passwd文件中为新用户增加一条记录,同时更新其他系统文件如/etc/shadow, /etc/group等;
Linux提供了集成的系统管理工具userconf,它可以用来对用户账号进行统一管理;
b 删:userdel 选项 用户名
常用的选项是 -r,它的作用是把用户的主目录一起删除;
c 改:usermod 选项 用户名
常用的选项包括-c, -d, -m, -g, -G, -s, -u以及-o等,这些选项的意义与useradd命令中的选项一样,可以为用户指定新的资源值;
另外,有些系统可以使用选项:-l 新用户名 ;这个选项指定一个新的账号,即将原来的用户名改为新的用户名;
d 查
7.2 用户密码管理
修改密码:passwd 选项 用户名
/etc/security/opasswd文件存储历史密码,如果有冲突可以修改或删除对应的历史密码;
/etc/login.defs 文件存储了一些密码要求,如果有对密码的要求不满足(比如必须带数字等),可以修改对应文件;
7.3 用户组的管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建;
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新;
7.3.1 用户组操作
增 : groupadd 选项 用户组
删 :groupdel 用户组
改:groupmod 选项 用户组
-g GID 为用户组指定新的组标识号;
-o 与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同;
-n新用户组 将用户组的名字改为新名字;
查:
7.3.2 用户组切换,适用于一个用户,有多个用户组使用命令newgrp (另一个用户组) 切换;
7.4 系统文件管理
与用户和用户组相关的信息都存放在一些系统文件中,这些文件包括/etc/passwd, /etc/shadow, /etc/group等;
7.4.1 /etc/passwd
每一行记录一个用户属性,举例如下,部分内容省略:
# cat /etc/passwd
root:x:0:0:Superuser:/:
daemon:x:1:1:System daemons:/etc:
usera:x:1000:1000::/home/usera:/bin/bash
含义是:用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
口令是加密的,所以只能看到x;
用户标识号,一般从100开始,0标识超级用户root,0~100系统备用;
组标示号对应着/etc/group文件中的一条记录;
7.4.2 /etc/shadow
/etc/shadow中的记录行与/etc/passwd中的一一对应,它由pwconv命令根据/etc/passwd中的数据自动产生;
直接pwconv运行即可;
它的文件格式与/etc/passwd类似,由若干个字段组成,字段之间用":"隔开。这些字段是:
登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
7.4.3 /etc/group
用户组的所有信息都存放在/etc/group文件中;
将用户分组是Linux 系统中对用户进行管理及控制访问权限的一种手段;
每个用户都属于某个用户组;一个组中可以有多个用户,一个用户也可以属于不同的组;
当一个用户同时是多个组中的成员时,在/etc/passwd文件中记录的是用户所属的主组,也就是登录时所属的默认组,而其他组称为附加组;
用户要访问属于附加组的文件时,必须首先使用newgrp命令使自己成为所要访问的组中的成员;
用户组的所有信息都存放在/etc/group文件中。此文件的格式也类似于/etc/passwd文件,由冒号(:)隔开若干个字段,这些字段有:
组名:口令:组标识号:组内用户列表
7.4.4 /etc/sudoers,他就是来存储操作超级账户的,默认只有root,可以把你想设置成超级用户的加进去;
7.5 给用户改变权限
vim /etc/passwd文件
root:x:0:0:root:/root:/bin/bash
peter:x:0:0::/home/peter:/bin/bash#将x后边的改成都改成0即可,权限和root就一致了,注:此操作不可取,乃是黑客常用手段;
7.6 密码要求,某些系统会对密码有要求,例如,密码必须有多少个数字,多少个小写字母之类的规则;
在/etc/pam.d/system-auth中设置;
该行内容如下:
password requisite pam_pwquality.so minlen=9 try_first_pass local_users_only retry=3 authtok_type= enforce_for_root ocredit=0 lcredit=-1 ucredit= 0 dcredit=0 [badwords=first2012++]
说明:
minlen=8 最小密码长度为8位
ucredit=-2 最少有2个大写字母
lcredit=-4 最少4个小写字符
dcredit=-1 最少1个数字
ocredit=-1 最少1个符号
remember=5 密码最近5次的不能重用
按需要进行设计即可;
7.7 vim /etc/login.defs,内存有登录信息,密码有效期等信息;
7.8 示例:
增加一个用户名和密码都是worker的组,并且设置工作目录为/data/worker/ ;然后删除它;
groupadd worker
useradd -g worker -d /data1/worker -s /bin/bash/ -m worker
passwd worker #设置密码
userdel worker
groupdel worker
rm -rf /var/spool/mail/worker
7.9 说明:
7.9.1 最好不要直接修改etc下边的文件夹;
8 程序分析
8.1 linux 运行时间优化和分析(注:会在程序执行目录下生成对应的文件,同时需要再执行目录下运行下述命令)
0 删除之前的文件内容
find -name "*.gc*" |xargs rm -rf
find -name "*.o" |xargs rm -rf
1 编译:g++ -o run -g -pg -fprofile-arcs -ftest-coverage ./main.cpp;注意,在常规编译环节加上-g -pg -fprofile-arcs -ftest-coverage即可;
2 运行可执行文件run;
3 执行runlcov.sh脚本,得到output文件,即函数cover文件,显示文件某一行是否被执行,被执行多少次的文件;
runlcov.sh:
lcov --capture --directory ./ --output-file test.info --test-name test
genhtml test.info --output-directory output --title "dyna analysis" --show-details --legend
或者genhtml test.info -o output/
lcov可能没有安装,https://sourceforge.net/projects/ltp/files/Coverage%20Analysis/LCOV-1.13/下载,运行make install进行安装;
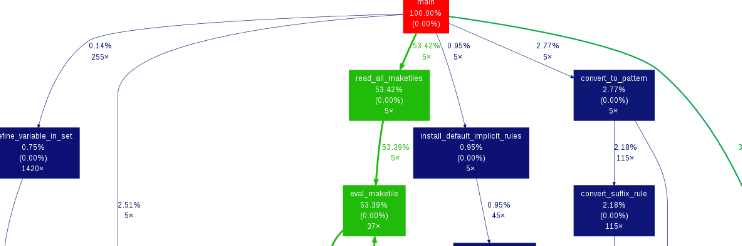
4 得到调用关系和热点函数占比
gprof -b bin(可执行文件) >log
gprof2dot.py log | dot -Tpdf -o fib-gprof.pdf
输出关系在fib-gprof.pdf文件中;
注:gprof2dot.py的git是https://github.com/jrfonseca/gprof2dot;dot需要安装yum install graphviz;生成调用关系图,如下:
8.2 内存优化
使用valgrind进行内存优化;
编译程序:g++ -o run -g3 ./main.cpp
valgrind 跑程序:valgrind -v --log-file=valgrind.log --tool=memcheck --leak-check=full --show-mismatched-frees=yes ./run
valgrind 跑程序:valgrind -v --log-file=valgrind.log --tool=memcheck --leak-check=full --show-mismatched-frees=yes --undef-value-errors=no ./run,不显示未初始化的数值
看日志:vim ./valgrind.log
71 ==29995== HEAP SUMMARY:
72 ==29995== in use at exit: 10,000 bytes in 1 blocks
73 ==29995== total heap usage: 1 allocs, 0 frees, 10,000 bytes allocated
74 ==29995==
75 ==29995== Searching for pointers to 1 not-freed blocks
76 ==29995== Checked 204,728 bytes
77 ==29995==
78 ==29995== 10,000 bytes in 1 blocks are definitely lost in loss record 1 of 1
79 ==29995== at 0x4C29BFD: malloc (in /usr/lib64/valgrind/vgpreload_memcheck-amd64-linux.so)
80 ==29995== by 0x400651: main (main.cpp:5)//具体泄漏的代码行数
81 ==29995==
82 ==29995== LEAK SUMMARY:
83 ==29995== definitely lost: 10,000 bytes in 1 blocks
84 ==29995== indirectly lost: 0 bytes in 0 blocks
85 ==29995== possibly lost: 0 bytes in 0 blocks
86 ==29995== still reachable: 0 bytes in 0 blocks
87 ==29995== suppressed: 0 bytes in 0 blocks
9 文件和权限:
9.1 ll/ls -l的结果是什么?
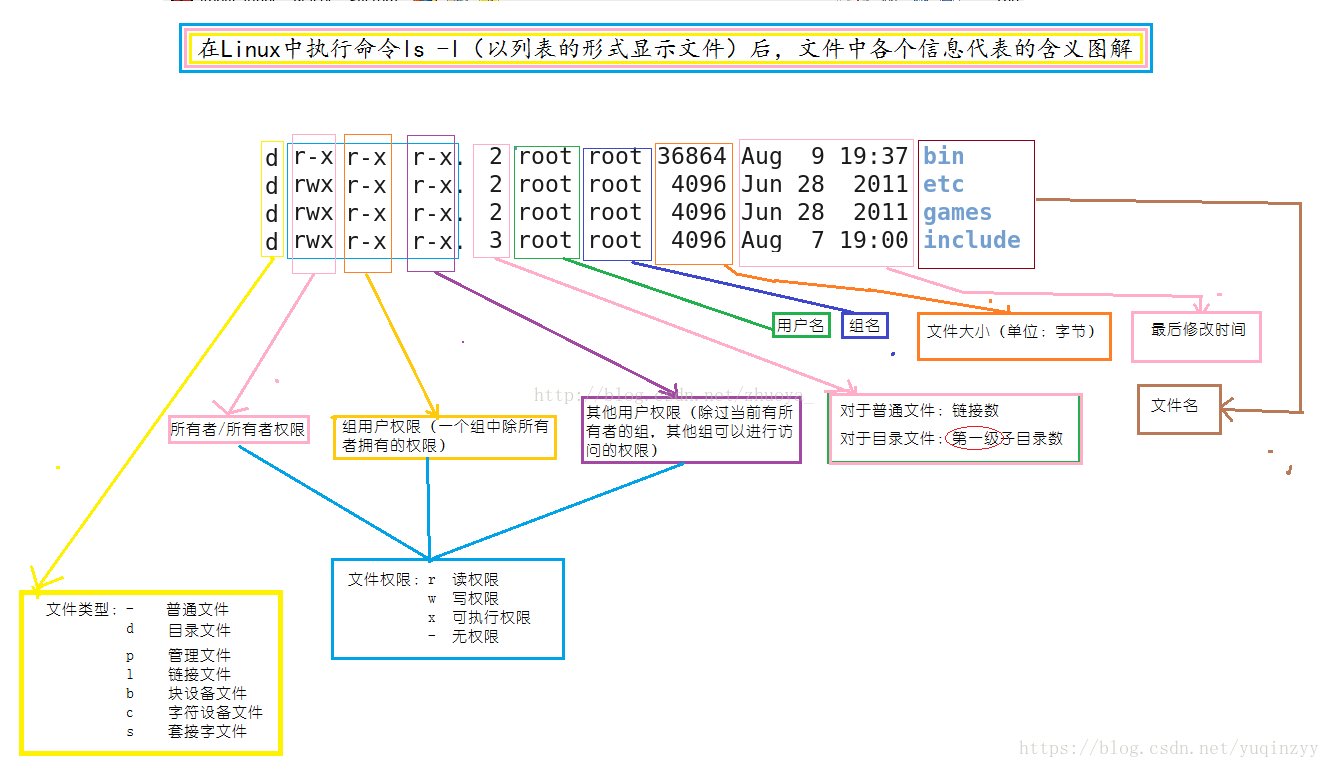
linux每一个用户都属于一个组,不能独立于组外。linux的文件权限需要定义三个实体对它的权限:文件所有者;文件所在组;其他组;
所有者:
一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者
可以使用chown【change owner】 用户名 文件名来修改文件的所有者,例如更改error.log的所有者为zhangsan;
chown zhangsan error.log #更改所有者为zhangsan;
chown .home error.log #更改用户组为home
所在组:
当用户创建了一个文件后,这个文件的所在组就是该用户所在的用户组;
可以使用chgrp【change group】来改变文件的所在组;
chgrp home error.log #修改文件的所在组为home
9.2 修改权限
修改权限的命令是chmod,而改变权限的方式分为两种
1.数字改变权限法
Linux的文件基本权限只有九个,分别是onwer,group,other三种身份,所以我们可以用数字来代表权限,其中 r : 4 w : 2 x : 1
每种身份设置权限为数字的累加,比如将error.log文件设置成所有人都有RWX权限,则 chmod 777 error.log
因为[-rwxrwxrwx]实际上是[4+2+1][4+2+1][4+2+1]也就是777了。如果我们将权限变为[-rwxr-xr--]则[4+2+1][4+0+1][4+0+0]即为754
2 符号改变法实际上就是对不同实体设置权限,其中我们只要懂的三个部分的含义就可以
| chmod | u | +(加入) | 文件或目录 |
| g | =(设置) | ||
| o | |||
| a | -(除去) |
举几个例子来说明吧,设置用户对error.log有rwx权限,所在组和其他组有rx权限: chmod u=rwx,go=rx error.log
设置用户对error.log有rwx权限,所在组有rx权限,其他组有r权限 chomd u=rwx,g==rx,o=r errlog.log
所有用户的可执行权限 chmod a-x error.log
五 linux软件安装&使用
1 安装python
从python官网上现在最新的代码包,https://www.python.org/downloads/
copy到服务器上,解压;
./configure
make & make install
期间,报错,报错ModuleNotFoundError: No module named '_ctypes'
解决办法:3.7版本需要一个新的包libffi-devel,安装此包之后再次进行编译安装
#yum install libffi-devel -y
#make install
最后会在/usr/local/bin里有程序包;
运行python3 -V即可显示正确的version;
2 安装ssl
libssl-dev是ubuntu系统的库,而centos系统对应的是openssl-devel ,
所以运行centos中运行yum install openssl-devel,ubuntu系统运行apt-get install libssl-dev
3 linux 离线安装gcc4.8.5:
1 获取离线安装包: https://pan.baidu.com/s/1J-wVsAoTmfn_iiOnYSrmZA 密码:beee
2 将这些包上传到待安装的系统中,执行安装命令:
rpm -ivh *.rpm --nodeps --force
3 装好时候报错: libc.so.6: version `GLIBC_2.14' not found
https://blog.csdn.net/qq805934132/article/details/82893724
https://blog.csdn.net/cpplang/article/details/8462768/
4 安装高版本的gcc(至少5.3.1以上);
yum install centos-release-scl
yum install devtoolset-4-gcc-c++-7.3.1
source /opt/rh/devtoolset-7/enable
gcc --version
注意:有些机器不支持安装5.3.1 通过命令【 yum --disablerepo="*" --enablerepo="*scl*" search gcc 】来看库中有声明版本;
source /opt/rh/devtoolset-7/enable 每次运行前source一下;
注:yum可能出错:报错如下:
#yum
File "/usr/bin/yum", line 30
except KeyboardInterrupt, e:
^
SyntaxError: invalid syntax
原因:这是因为yum 采用python作为命令解释器,但是有时候我们python默认为3.5,但是yum只支持2.7;所以报错;
修改/usr/bin/yum文件第一行,#!/usr/bin/python改成#!/usr/bin/python2.7即可;
5 xshell使用
直接复制渠道,可以避免每次输入token和密码;
工具->选项->键盘和鼠标,可以设置快捷键,提升工作效率;
六 GPU & nvidia
1 常用gpu型号
NVIDIA Tesla系列GPU适用于高性能计算(HPC)、深度学习等超大规模数据计算,Tesla系列GPU能够处理解析PB级的数据,速度比使用传统CPU快几个数量级,NVIDIA Tesla GPU系列P4、T4、P40以及V100是Tesla GPU系列的明星产品,云服务器吧分享NVIDIA Tesla GPU系列P4、T4、P40以及V100参数性能对比:
NVIDIA TESLA V100,采用NVIDIA Volta架构,适合要求苛刻的 双精度 计算工作流程,渲染性能比Tesla P100提升了高达80%,每个GPU均可提供125 teraflops的推理性能;
NVIDIA TESLA P40,支持多种行业标准的2U服务器,可提供出色的推理性能、INT8精度和24GB板载内存;
NVIDIA TESLA T4,帧缓存高达P4的2倍,性能高达M60的2倍;
NVIDIA TESLA P4,能效高达CPU的60倍;
性能&价格:Tesla V100 > Tesla P40 > Tesla T4 > Tesla P4
注:T4,架构更高级,技术更先进,超过P4;P40技术落后一点,但是核心多,显存大,所以价格可能会贵点;
2 gpu信息查看
运行nvidia-smi
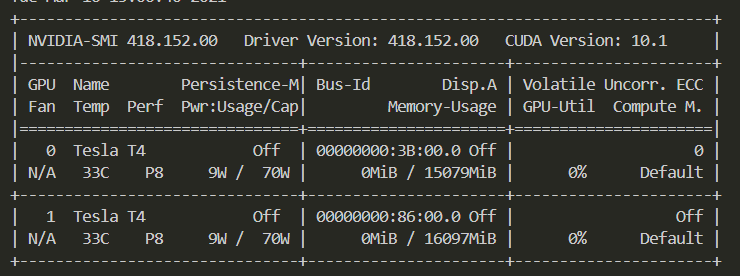
- Fan:显示风扇转速,数值在0到100%之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
- Temp:显卡内部的温度,单位是摄氏度;
- Perf:表征性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能;
- Pwr:能耗表示;
- Bus-Id:涉及GPU总线的相关信息;
- Disp.A:是Display Active的意思,表示GPU的显示是否初始化;
- Memory Usage:显存的使用率;
- Volatile GPU-Util:浮动的GPU利用率;
- Compute M:计算模式;
- 查看显存:即Memory Usage下边,已经使用/总显存,图中,15079Mib,16097Mib即显存,15G和16G;