普遍消息存储技术的选型
- 分布式KV存储
- NewSQL存储:TiDB 文件系统:RocketMQ,kafka,RabbitMQ
- RocketMQ:所有的message存储在一个log里,不区分topic-queue
- kafka:一个log文件存储单个topic-queue
RocketMQ实现消息存储
MappedFile(映射文件)
CommitLog
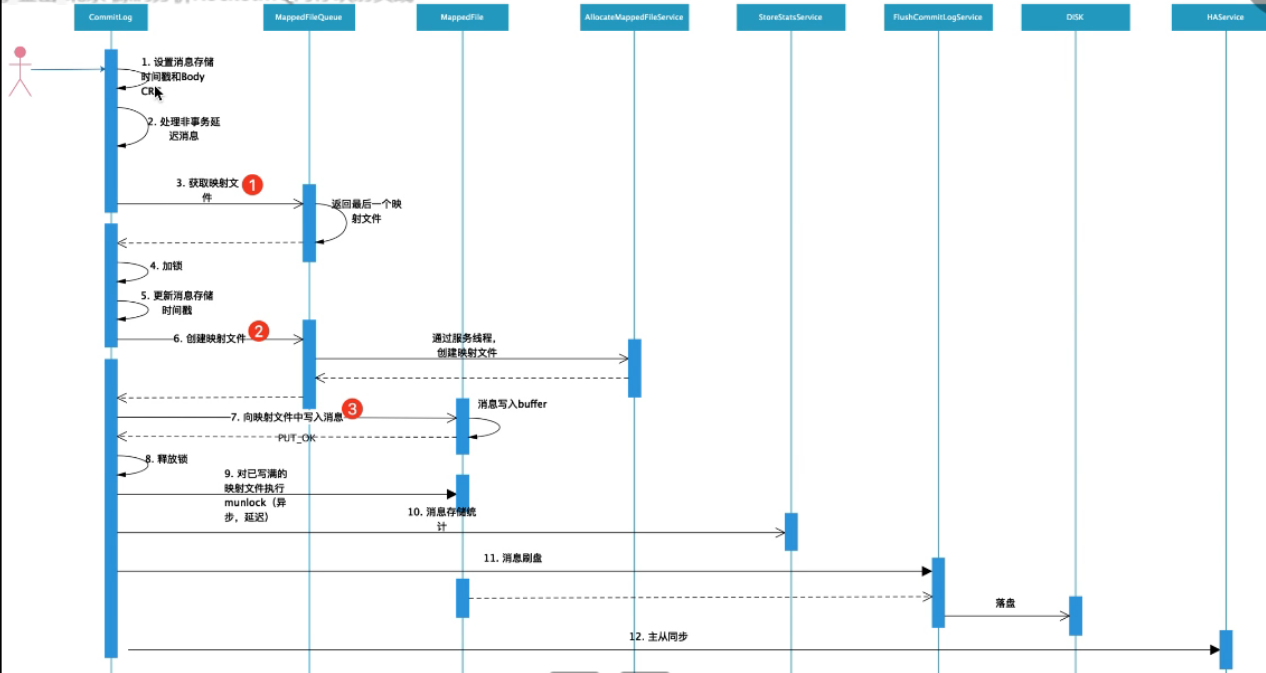
下图为CommitLog结构:MappedFile(真实的映射文件)组成MappedQueue构成

存储消息CommitLog.putMessage()
- 获取最近一个CommitLog的内存映射文件(零拷贝)
- MappedFileQueue.getLastMappedFile():从其维护的列表中获取最后一个,因为之前的都已经写满了
- MappedFileQueue.load():构建一个MappedFile,加入到列表中
- 如果最近的CommitLog文件写满了或者broker刚启动,mappedfile是空的,创建一个新的
- MappedFileQueue.getLastMappedFile(create:true)
- 计算要创建的CommitLog的起始偏移量(即映射文件的名)
- allocateMappedFileService.putRequestAndReturnMappedFile()创建两个映射文件,但其实只要创建好第一个就返回了;
- 两种创建MappedFile方式(内存映射):堆外内存池,直接创建TODO
- 创建好后,对当前映射文件进行预热MappedFile.warmMappedFile:
- 对当前映射文件的每个内存页写入一个字节ByteBuffer,当刷盘策略为同步刷盘时,执行强制刷盘,每修改pages个分页刷一次盘;
- 因为对每个Mappedfile写入假字节的时候是通过循环的形式,而写入次数为MappedFile.size(1024M) / pagesize(4k),这样占有CPU的时间太久,所以线程会主动休眠,进入就绪状态,释放CPU
- MappedFile.mlock()将当前映射文件全部的地址空间锁定在物理存储中,防止被交换到swap空间
- 把broker内部的这个message刷新到Mappedfile的内存中mappedFile.appendMessage(msg, this.appendMessageCallback),有以下两种方式
- 直接将数据写到映射文件字节缓冲区mappedByteBuffer,后mappedByteBuffer.flush()
- 先写到内存字节缓冲区writeBuffer,再从writeBuffer提交commit到文件通道FileChannel,后FileChannel.flush()
- 刷盘:handleDiskFlush()
- 同步刷盘GroupCommitService:将刷盘请求放入执行线程维护的请求队列中,超时时间内等待执行
- 异步刷盘CommitRealTimeService/FlushCommitLogService:TODO
- 主从同步:handleHA()
- sync_master:HAService将刷盘请求放入GroupTransferService维护的写请求列表中
下图为CommitLog存储消息的流程:
ConsumerQueue/Index
是消息存储的索引文件:内存存储以topic(目录)/队列id(目录)/MappedFile.....
从CommitLog中拿到message
CommitLog写入message的时候,异步构建consumerqueue存储消息索引提供消费者消费
问题:
当topic数量增多时,kafka的单个broker的TPS降低了1个数量级,而RocketMQ在海量topic的场景下,依然保持较高的TPS?
CommitLog的”随机读”对性能的影响