RPC(Remote Procedure Call):远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的思想。
- 作者:李金葵来源:51CTO技术栈|2019-06-17 08:21
【51CTO.com原创稿件】RPC(Remote Procedure Call):远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的思想。
RPC 是一种技术思想而非一种规范或协议,常见 RPC 技术和框架有:
- 应用级的服务框架:阿里的 Dubbo/Dubbox、Google gRPC、Spring Boot/Spring Cloud。
- 远程通信协议:RMI、Socket、SOAP(HTTP XML)、REST(HTTP JSON)。
- 通信框架:MINA 和 Netty。
目前流行的开源 RPC 框架还是比较多的,有阿里巴巴的 Dubbo、Facebook 的 Thrift、Google 的 gRPC、Twitter 的 Finagle 等。
下面重点介绍三种:
- gRPC:是 Google 公布的开源软件,基于***的 HTTP 2.0 协议,并支持常见的众多编程语言。RPC 框架是基于 HTTP 协议实现的,底层使用到了 Netty 框架的支持。
- Thrift:是 Facebook 的开源 RPC 框架,主要是一个跨语言的服务开发框架。
用户只要在其之上进行二次开发就行,应用对于底层的 RPC 通讯等都是透明的。不过这个对于用户来说需要学习特定领域语言这个特性,还是有一定成本的。
- Dubbo:是阿里集团开源的一个极为出名的 RPC 框架,在很多互联网公司和企业应用中广泛使用。协议和序列化框架都可以插拔是极其鲜明的特色。
完整的 RPC 框架
在一个典型 RPC 的使用场景中,包含了服务发现、负载、容错、网络传输、序列化等组件,其中“RPC 协议”就指明了程序如何进行网络传输和序列化。
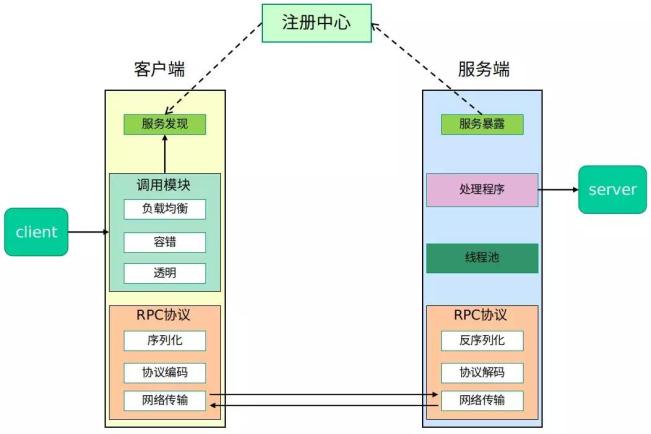
图 1:完整 RPC 架构图
如下是 Dubbo 的设计架构图,分层清晰,功能复杂:

图 2:Dubbo 架构图

RPC 核心功能
RPC 的核心功能是指实现一个 RPC 最重要的功能模块,就是上图中的”RPC 协议”部分:

图 3:RPC 核心功能
一个 RPC 的核心功能主要有 5 个部分组成,分别是:客户端、客户端 Stub、网络传输模块、服务端 Stub、服务端等。
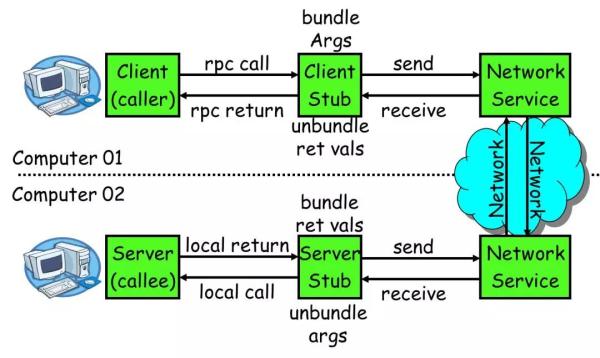
图 4:RPC 核心功能图
下面分别介绍核心 RPC 框架的重要组成:
- 客户端(Client):服务调用方。
- 客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端。
- 服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理。
- 服务端(Server):服务的真正提供者。
- Network Service:底层传输,可以是 TCP 或 HTTP。
Python 自带 RPC Demo
Server.py:
- from SimpleXMLRPCServer import SimpleXMLRPCServer
- def fun_add(a,b):
- totle = a + b
- return totle
- if __name__ == '__main__':
- s = SimpleXMLRPCServer(('0.0.0.0', 8080)) #开启xmlrpcserver
- s.register_function(fun_add) #注册函数fun_add
- print "server is online..."
- s.serve_forever() #开启循环等待
Client.py:
- from xmlrpclib import ServerProxy #导入xmlrpclib的包
- s = ServerProxy("http://172.171.5.205:8080") #定义xmlrpc客户端
- print s.fun_add(2,3)
开启服务端:

开启客户端:

Wireshark 抓包分析过程
客户端去往服务端:
- 客户端 IP:172.171.4.176
- 服务端 IP:172.171.5.95
通信使用 HTTP 协议,XML 文件传输格式。传输的字段包括:方法名 methodName,两个参数 2,3。
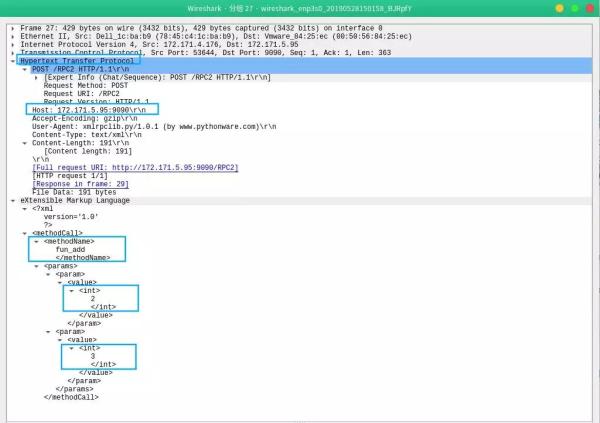
图 5:Request 抓包
服务端返回结果,字段返回值 Value,结果是 5:
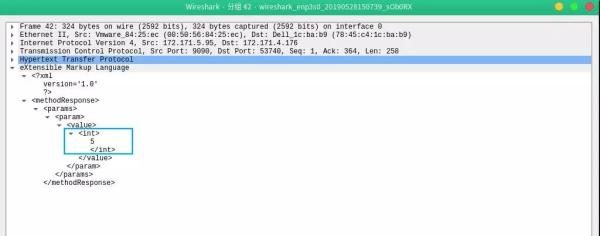
图 6:Response 抓包
在这两次网络传输中使用了 HTTP 协议,建立 HTTP 协议之间有 TCP 三次握手,断开 HTTP 协议时有 TCP 四次挥手。

图 7:基于 HTTP 协议的 RPC 连接过程
详细调用过程
Python 自带 RPC 的 Demo 小程序的实现过程,流程和分工角色可以用下图来表示:
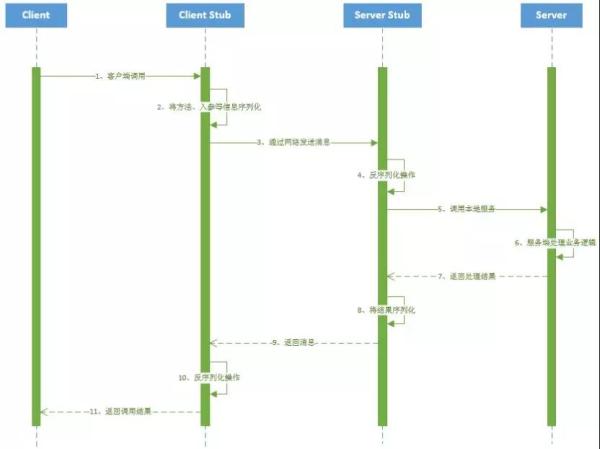
图 8:RPC 调用详细流程图
一次 RPC 调用流程如下:
- 服务消费者(Client 客户端)通过本地调用的方式调用服务。
- 客户端存根(Client Stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体。
- 客户端存根(Client Stub)找到远程的服务地址,并且将消息通过网络发送给服务端。
- 服务端存根(Server Stub)收到消息后进行解码(反序列化操作)。
- 服务端存根(Server Stub)根据解码结果调用本地的服务进行相关处理
- 服务端(Server)本地服务业务处理。
- 处理结果返回给服务端存根(Server Stub)。
- 服务端存根(Server Stub)序列化结果。
- 服务端存根(Server Stub)将结果通过网络发送至消费方。
- 客户端存根(Client Stub)接收到消息,并进行解码(反序列化)。
- 服务消费方得到最终结果。

RPC 核心之功能实现
RPC 的核心功能主要由 5 个模块组成,如果想要自己实现一个 RPC,最简单的方式要实现三个技术点,分别是:
- 服务寻址
- 数据流的序列化和反序列化
- 网络传输
服务寻址
服务寻址可以使用 Call ID 映射。在本地调用中,函数体是直接通过函数指针来指定的,但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。
所以在 RPC 中,所有的函数都必须有自己的一个 ID。这个 ID 在所有进程中都是唯一确定的。
客户端在做远程过程调用时,必须附上这个 ID。然后我们还需要在客户端和服务端分别维护一个函数和Call ID的对应表。
当客户端需要进行远程调用时,它就查一下这个表,找出相应的 Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
实现方式:服务注册中心。
要调用服务,首先你需要一个服务注册中心去查询对方服务都有哪些实例。Dubbo 的服务注册中心是可以配置的,官方推荐使用 Zookeeper。
实现案例:RMI(Remote Method Invocation,远程方法调用)也就是 RPC 本身的实现方式。
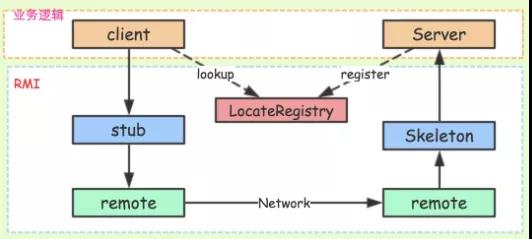
图 9:RMI 架构图
Registry(服务发现):借助 JNDI 发布并调用了 RMI 服务。实际上,JNDI 就是一个注册表,服务端将服务对象放入到注册表中,客户端从注册表中获取服务对象。
RMI 服务在服务端实现之后需要注册到 RMI Server 上,然后客户端从指定的 RMI 地址上 Lookup 服务,调用该服务对应的方法即可完成远程方法调用。
Registry 是个很重要的功能,当服务端开发完服务之后,要对外暴露,如果没有服务注册,则客户端是无从调用的,即使服务端的服务就在那里。
序列化和反序列化
客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。
但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。
这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。
只有二进制数据才能在网络中传输,序列化和反序列化的定义是:
- 将对象转换成二进制流的过程叫做序列化
- 将二进制流转换成对象的过程叫做反序列化
这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
网络传输
网络传输:远程调用往往用在网络上,客户端和服务端是通过网络连接的。
所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把 Call ID 和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。
只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。
尽管大部分 RPC 框架都使用 TCP 协议,但其实 UDP 也可以,而 gRPC 干脆就用了 HTTP2。
TCP 的连接是最常见的,简要分析基于 TCP 的连接:通常 TCP 连接可以是按需连接(需要调用的时候就先建立连接,调用结束后就立马断掉),也可以是长连接(客户端和服务器建立起连接之后保持长期持有,不管此时有无数据包的发送,可以配合心跳检测机制定期检测建立的连接是否存活有效),多个远程过程调用共享同一个连接。
所以,要实现一个 RPC 框架,只需要把以下三点实现了就基本完成了:
- Call ID 映射:可以直接使用函数字符串,也可以使用整数 ID。映射表一般就是一个哈希表。
- 序列化反序列化:可以自己写,也可以使用 Protobuf 或者 FlatBuffers 之类的。
- 网络传输库:可以自己写 Socket,或者用 Asio,ZeroMQ,Netty 之类。
RPC 核心之网络传输协议
在第三节中说明了要实现一个 RPC,需要选择网络传输的方式。

图 10:网络传输
在 RPC 中可选的网络传输方式有多种,可以选择 TCP 协议、UDP 协议、HTTP 协议。
每一种协议对整体的性能和效率都有不同的影响,如何选择一个正确的网络传输协议呢?首先要搞明白各种传输协议在 RPC 中的工作方式。
基于 TCP 协议的 RPC 调用
由服务的调用方与服务的提供方建立 Socket 连接,并由服务的调用方通过 Socket 将需要调用的接口名称、方法名称和参数序列化后传递给服务的提供方,服务的提供方反序列化后再利用反射调用相关的方法。
***将结果返回给服务的调用方,整个基于 TCP 协议的 RPC 调用大致如此。
但是在实例应用中则会进行一系列的封装,如 RMI 便是在 TCP 协议上传递可序列化的 Java 对象。
基于 HTTP 协议的 RPC 调用
该方法更像是访问网页一样,只是它的返回结果更加单一简单。
其大致流程为:由服务的调用者向服务的提供者发送请求,这种请求的方式可能是 GET、POST、PUT、DELETE 等中的一种,服务的提供者可能会根据不同的请求方式做出不同的处理,或者某个方法只允许某种请求方式。
而调用的具体方法则是根据 URL 进行方法调用,而方法所需要的参数可能是对服务调用方传输过去的 XML 数据或者 JSON 数据解析后的结果,***返回 JOSN 或者 XML 的数据结果。
由于目前有很多开源的 Web 服务器,如 Tomcat,所以其实现起来更加容易,就像做 Web 项目一样。
两种方式对比
基于 TCP 的协议实现的 RPC 调用,由于 TCP 协议处于协议栈的下层,能够更加灵活地对协议字段进行定制,减少网络开销,提高性能,实现更大的吞吐量和并发数。
但是需要更多关注底层复杂的细节,实现的代价更高。同时对不同平台,如安卓,iOS 等,需要重新开发出不同的工具包来进行请求发送和相应解析,工作量大,难以快速响应和满足用户需求。
基于 HTTP 协议实现的 RPC 则可以使用 JSON 和 XML 格式的请求或响应数据。
而 JSON 和 XML 作为通用的格式标准(使用 HTTP 协议也需要序列化和反序列化,不过这不是该协议下关心的内容,成熟的 Web 程序已经做好了序列化内容),开源的解析工具已经相当成熟,在其上进行二次开发会非常便捷和简单。
但是由于 HTTP 协议是上层协议,发送包含同等内容的信息,使用 HTTP 协议传输所占用的字节数会比使用 TCP 协议传输所占用的字节数更高。
因此在同等网络下,通过 HTTP 协议传输相同内容,效率会比基于 TCP 协议的数据效率要低,信息传输所占用的时间也会更长,当然压缩数据,能够缩小这一差距。
使用 RabbitMQ 的 RPC 架构
在 OpenStack 中服务与服务之间使用 RESTful API 调用,而在服务内部则使用 RPC 调用各个功能模块。
正是由于使用了 RPC 来解耦服务内部功能模块,使得 OpenStack 的服务拥有扩展性强,耦合性低等优点。
OpenStack 的 RPC 架构中,加入了消息队列 RabbitMQ,这样做的目的是为了保证 RPC 在消息传递过程中的安全性和稳定性。
下面分析 OpenStack 中使用 RabbitMQ 如何实现 RPC 的调用。
RabbitMQ 简介
以下摘录自知乎:
对于初学者,举一个饭店的例子来解释这三个分别是什么吧。不是***恰当,但是应该足以解释这三者的区别。
RPC:假设你是一个饭店里的服务员,顾客向你点菜,但是你不会做菜,所以你采集了顾客要点什么之后告诉后厨去做顾客点的菜,这叫 RPC(remote procedure call),因为厨房的厨师相对于服务员而言是另外一个人(在计算机的世界里就是 Remote 的机器上的一个进程)。厨师做好了的菜就是RPC的返回值。
任务队列和消息队列:本质都是队列,所以就只举一个任务队列的例子。假设这个饭店在高峰期顾客很多,而厨师只有很少的几个,所以服务员们不得不把单子按下单顺序放在厨房的桌子上,供厨师们一个一个做,这一堆单子就是任务队列,厨师们每做完一个菜,就从桌子上的订单里再取出一个单子继续做菜。
角色分担如下图:
图 11:RabbitMQ 在 RPC 中角色
使用 RabbitMQ 的好处:
- 同步变异步:可以使用线程池将同步变成异步,但是缺点是要自己实现线程池,并且强耦合。使用消息队列可以轻松将同步请求变成异步请求。
- 低内聚高耦合:解耦,减少强依赖。
- 流量削峰:通过消息队列设置请求***值,超过阀值的抛弃或者转到错误界面。
- 网络通信性能提高:TCP 的创建和销毁开销大,创建 3 次握手,销毁 4 次分手,高峰时成千上万条的链接会造成资源的巨大浪费,而且操作系统每秒处理 TCP 的数量也是有数量限制的,必定造成性能瓶颈。
RabbitMQ 采用信道通信,不采用 TCP 直接通信。一条线程一条信道,多条线程多条信道,公用一个 TCP 连接。
一条 TCP 连接可以容纳***条信道(硬盘容量足够的话),不会造成性能瓶颈。
RabbitMQ 的三种类型的交换器
RabbitMQ 使用 Exchange(交换机)和 Queue(队列)来实现消息队列。
在 RabbitMQ 中一共有三种交换机类型,每一种交换机类型都有很鲜明的特征。
基于这三种交换机类型,OpenStack 完成两种 RPC 的调用方式。首先简单介绍三种交换机。
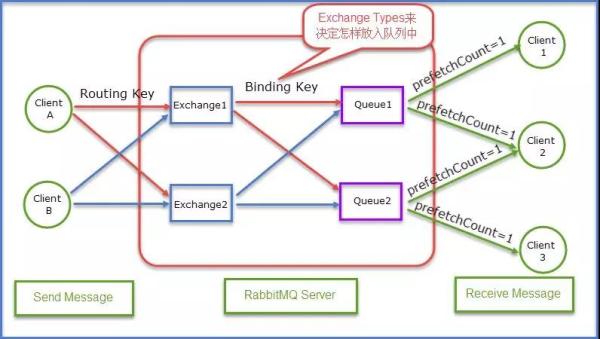
图 12:RabbitMQ 架构图
①广播式交换器类型(Fanout)
该类交换器不分析所接收到消息中的 Routing Key,默认将消息转发到所有与该交换器绑定的队列中去。
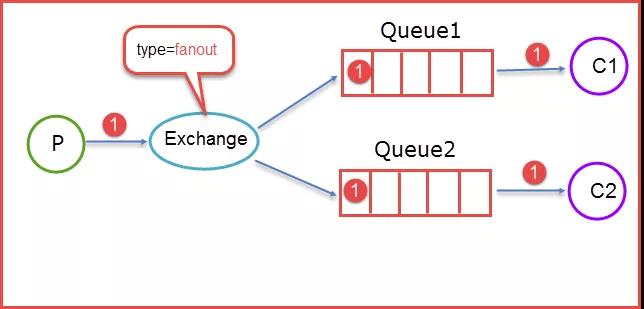
图 13:广播式交换机
②直接式交换器类型(Direct)
该类交换器需要精确匹配 Routing Key 与 Binding Key,如消息的 Routing Key = Cloud,那么该条消息只能被转发至 Binding Key = Cloud 的消息队列中去。

图 14:直接式交换机
③主题式交换器(Topic Exchange)
该类交换器通过消息的 Routing Key 与 Binding Key 的模式匹配,将消息转发至所有符合绑定规则的队列中。
Binding Key 支持通配符,其中“*”匹配一个词组,“#”匹配多个词组(包括零个)。
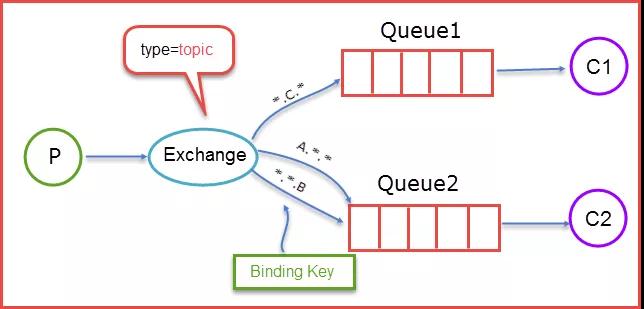
图 15:主题式交换机
注:以上四张图片来自博客园,如有侵权,请联系作者:https://www.cnblogs.com/dwlsxj/p/RabbitMQ.html。
当生产者发送消息 Routing Key=F.C.E 的时候,这时候只满足 Queue1,所以会被路由到 Queue 中。
如果 Routing Key=A.C.E 这时候会被同时路由到 Queue1 和 Queue2 中,如果 Routing Key=A.F.B 时,这里只会发送一条消息到 Queue2 中。
Nova 基于 RabbitMQ 实现两种 RPC 调用:
- RPC.CALL(调用)
- RPC.CAST(通知)
其中 RPC.CALL 基于请求与响应方式,RPC.CAST 只是提供单向请求,两种 RPC 调用方式在 Nova 中均有典型的应用场景。
RPC.CALL
RPC.CALL 是一种双向通信流程,即 RabbitMQ 接收消息生产者生成的系统请求消息,消息消费者经过处理之后将系统相应结果反馈给调用程序。
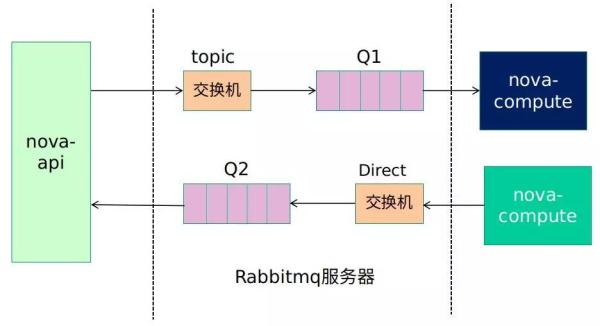
图 16:RPC.CALL 原理图
一个用户通过 Dashboard 创建一个虚拟机,界面经过消息封装后发送给 NOVA-API。
NOVA-API 作为消息生产者,将该消息以 RPC.CALL 方式通过 Topic 交换器转发至消息队列。
此时,Nova-Compute 作为消息消费者,接收该信息并通过底层虚拟化软件执行相应虚拟机的启动进程。
待用户虚拟机成功启动之后,Nova-Compute 作为消息生产者通过 Direct 交换器和响应的消息队列将虚拟机启动成功响应消息反馈给 Nova-API。
此时 Nova-API 作为消息消费者接收该消息并通知用户虚拟机启动成功。

RPC.CALL 工作原理如下图:
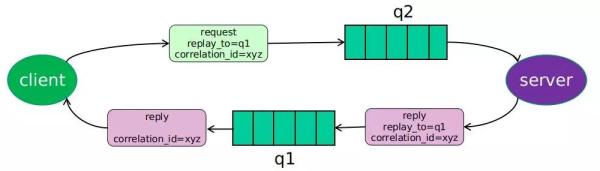
图 17:RPC.CALL 具体实现图
工作流程:
- 客户端创建 Message 时指定 reply_to 队列名、correlation_id 标记调用者。
- 通过队列,服务端收到消息。调用函数处理,然后返回。
- 返回的队列是 reply_to 指定的队列,并携带 correlation_id。
- 返回消息到达客户端,客户端根据 correlation_id 判断是哪一个函数的调用返回。
如果有多个线程同时进行远程方法调用,这时建立在 Client Server 之间的 Socket 连接上会有很多双方发送的消息传递,前后顺序也可能是随机的。
Server 处理完结果后,将结果消息发送给 Client,Client 收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
Client 线程每次通过 Socket 调用一次远程接口前,生成一个唯一的 ID,即 Request ID(Request ID必需保证在一个 Socket 连接里面是唯一的),一般常常使用 AtomicLong 从 0 开始累计数字生成唯一 ID。
RPC.CAST
RPC.CAST 的远程调用流程与 RPC.CALL 类似,只是缺少了系统消息响应流程。
一个 Topic 消息生产者发送系统请求消息到 Topic 交换器,Topic 交换器根据消息的 Routing Key 将消息转发至共享消息队列。
与共享消息队列相连的所有 Topic 消费者接收该系统请求消息,并把它传递给响应的服务端进行处理。
其调用流程如图所示:
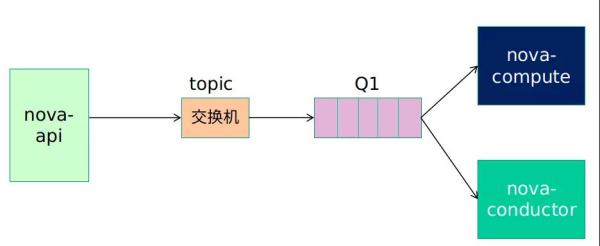
图 18:RPC.CAST 原理图
连接设计
RabbitMQ 实现的 RPC 对网络的一般设计思路:消费者是长连接,发送者是短连接。但可以自由控制长连接和短连接。
一般消费者是长连接,随时准备接收处理消息;而且涉及到 RabbitMQ Queues、Exchange 的 auto-deleted 等没特殊需求没必要做短连接。发送者可以使用短连接,不会长期占住端口号,节省端口资源。
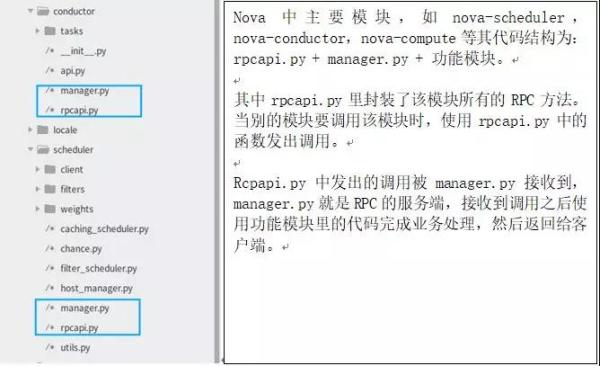
Nova 中 RPC 代码设计:
简单对比 RPC 和 Restful API
RESTful API 架构
REST ***的几个特点为:资源、统一接口、URI 和无状态。
①资源
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,就是一个具体的实在。
②统一接口
RESTful 架构风格规定,数据的元操作,即 CRUD(Create,Read,Update 和 Delete,即数据的增删查改)操作,分别对应于 HTTP 方法:GET 用来获取资源,POST 用来新建资源(也可以用于更新资源),PUT 用来更新资源,DELETE 用来删除资源,这样就统一了数据操作的接口,仅通过 HTTP 方法,就可以完成对数据的所有增删查改工作。
③URL
可以用一个 URI(统一资源定位符)指向资源,即每个 URI 都对应一个特定的资源。
要获取这个资源,访问它的 URI 就可以,因此 URI 就成了每一个资源的地址或识别符。
④无状态
所谓无状态的,即所有的资源,都可以通过 URI 定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而改变。有状态和无状态的区别,举个简单的例子说明一下。
如查询员工的工资,如果查询工资是需要登录系统,进入查询工资的页面,执行相关操作后,获取工资的多少,则这种情况是有状态的。
因为查询工资的每一步操作都依赖于前一步操作,只要前置操作不成功,后续操作就无法执行。
如果输入一个 URI 即可得到指定员工的工资,则这种情况是无状态的,因为获取工资不依赖于其他资源或状态。
且这种情况下,员工工资是一个资源,由一个 URI 与之对应,可以通过 HTTP 中的 GET 方法得到资源,这是典型的 RESTful 风格。
RPC 和 Restful API 对比
面对对象不同:
- RPC 更侧重于动作。
- REST 的主体是资源。
RESTful 是面向资源的设计架构,但在系统中有很多对象不能抽象成资源,比如登录,修改密码等而 RPC 可以通过动作去操作资源。所以在操作的全面性上 RPC 大于 RESTful。
传输效率:
- RPC 效率更高。RPC,使用自定义的 TCP 协议,可以让请求报文体积更小,或者使用 HTTP2 协议,也可以很好的减少报文的体积,提高传输效率。
复杂度:
- RPC 实现复杂,流程繁琐。
- REST 调用及测试都很方便。
RPC 实现(参见***节)需要实现编码,序列化,网络传输等。而 RESTful 不要关注这些,RESTful 实现更简单。
灵活性:
- HTTP 相对更规范,更标准,更通用,无论哪种语言都支持 HTTP 协议。
- RPC 可以实现跨语言调用,但整体灵活性不如 RESTful。
总结
RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,实现复杂。
HTTP 主要用于对外的异构环境,浏览器接口调用,App 接口调用,第三方接口调用等。
RPC 使用场景(大型的网站,内部子系统较多、接口非常多的情况下适合使用 RPC):
- 长链接。不必每次通信都要像 HTTP 一样去 3 次握手,减少了网络开销。
- 注册发布机制。RPC 框架一般都有注册中心,有丰富的监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。
- 安全性,没有暴露资源操作。
- 微服务支持。就是最近流行的服务化架构、服务化治理,RPC 框架是一个强力的支撑。