1. Client发出请求
1.1 HTTP 1.1
可以保持长连接,但是每个不同的请求之间,client要向server发一个请求头
请求无法并行执行的,在一个连接里面
假设如果不合并的话需要建立N个连接,那么合并就可以省去(N-1)*RTT的时间,RTT指网络延迟(在传输介质中传输所用的时间,即从报文开始进入网络到它开始离开网络之间的时间)。
1.2 TCP丢包问题
慢启动,拥塞控制窗口
TCP报文乱序到达,合并后的文件可以允许队首丢包以后在队中补上来,但是分开资源的时候,前一个资源未加载完成后面的资源是不能加载的,会有更严重的队首阻塞问题,丢包率会严重影响Keep alive情况下多个文件的传输速率。
1.3 浏览器线程数限制
多为2-6个线程,会在每个连接上串行发送若干个请求。TCP连接太多,会给服务器造成很大的压力的。
1.4 DNS缓存问题
每次请求都需要找DNS缓存,多个请求就需要查找多次,而且缓存有可能被无故清空
2. 服务器处理请求
每个请求需要使用一个连接,建立一个线程,分配一部分CPU, 对于CPU而言,是种负担,尤其是一般来说建立了连接以后,哪怕发回了请求,这个连接还会保持一段时间才会timeout。
这种时候,维持连接是对服务器资源的一种巨大的浪费。
3. HTTP 2.0
上面描述的所有都是基于HTTP/1.1的一些特性,或者说弊端,有长连接但是无法并行处理请求,TCP的慢启动和拥塞控制,队首阻塞问题都给整个性能带来很多弊端,因此我们有了HTTP2.0来做针对性的改进。很有意思的东西,直接看图:
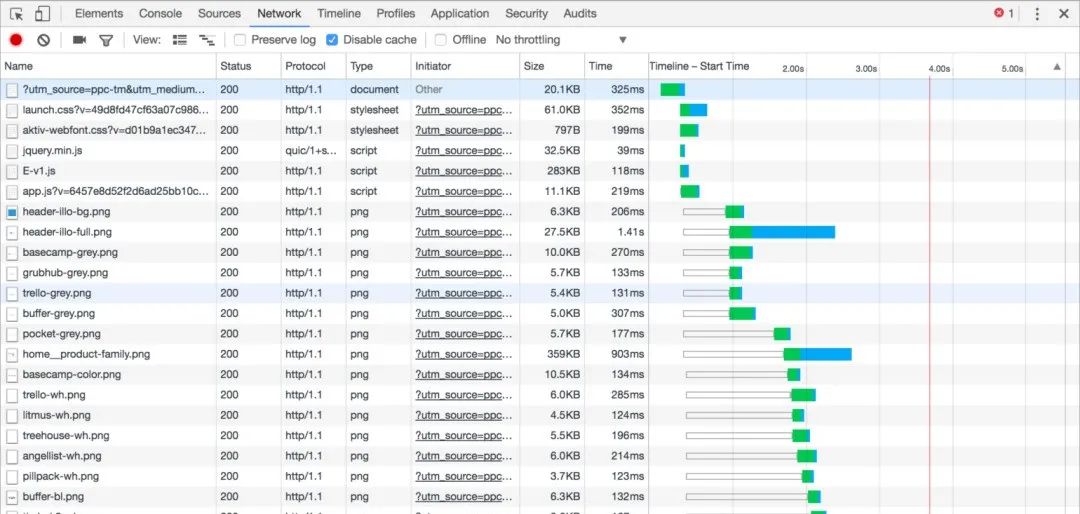 HTTP/1.1 network的请求图
HTTP/1.1 network的请求图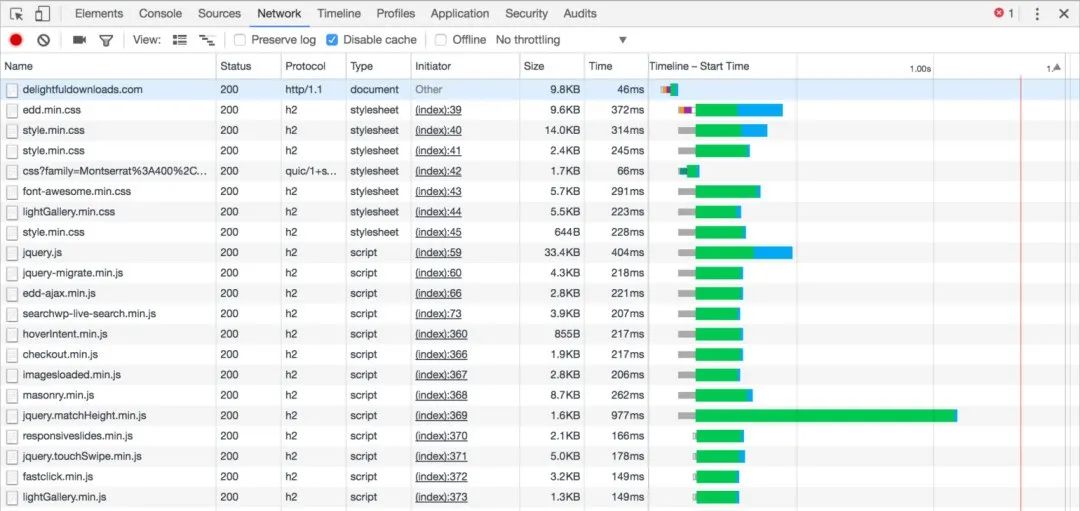 HTTP/2 network的请求图
HTTP/2 network的请求图
就是这么酷炫,HTTP/2多了很多特性来解决HTTP/1.1的很多问题
3.1 Fully multiplexed
解决了队首阻塞的问题。对于同一个TCP连接,现在可以发送多个请求,接收多个回应了!在HTTP/1.1里面,如果在一个连接里上一个请求发生了丢包,那么后面的所有请求都必须等第一个请求补上包,收到回应以后才能继续执行。而在HTTP/2里面,可以直接并行处理。
另外,HTTP 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
3.2 Header Compression
所有的HTTP request和response都有header,但是header里很可能包含缓存信息,导致他的大小会迅速增大的。但是在一个连接里大部分请求的请求头其实携带的信息都很类似,所以HTTP/2使用了索引表,存储了第一次出现的请求的请求头,然后后面的类似的请求只需要携带这个索引的数字就好了。头部压缩平均减少了30%的头部大小,加快了整体的网络中传输的速度。
这两点是和本文关系最大的,有了这两点,实质上合并HTTP请求的好处在HTTP/2的协议下,已经基本上消失了。合并不合并请求,更多的是看业务上的需求,后端的一些配置。
4. 总结
It’s a trade-off. 其实最重要的是看你传输什么东西,因为合并HTTP请求实质上是减少了网络延时,但是如果你在服务器上处理的时间远远大于网络延时的时间的时候,那么合并HTTP请求并不会给你带来很多性能上的提升。
而且大数据量的传输一定会降低浏览器的cache hit rate,对于缓存的利用率会降低很多。但是对于HTTP请求携带的数据量比较少的情况,合并请求带来的性能提升会是显而易见的。
5. 方案
将相似或重复请求在上游系统中合并后发往下游系统,可以大大降低下游系统的负载,提升系统整体吞吐率。文章介绍了 hystrix collapser、ConcurrentHashMultiset、自实现BatchCollapser 三种请求合并技术,并通过其具体实现对比各自适用的场景。
前言
工作中,我们常见的请求模型都是”请求-应答”式,即一次请求中,服务给请求分配一个独立的线程,一块独立的内存空间,所有的操作都是独立的,包括资源和系统运算。我们也知道,在请求中处理一次系统 I/O 的消耗是非常大的,如果有非常多的请求都进行同一类 I/O 操作,那么是否可以将这些 I/O 操作都合并到一起,进行一次 I/O 操作,是否可以大大降低下游资源服务器的负担呢?
最近我工作之余的大部分时间都花在这个问题的探究上了,对比了几个现有类库,为了解决一个小问题把 hystrix javanica 的代码翻了一遍,也根据自己工作中遇到的业务需求实现了一个简单的合并类,收获还是挺大的。可能这个需求有点”偏门”,在网上搜索结果并不多,也没有综合一点的资料,索性自己总结分享一下,希望能帮到后来遇到这种问题的小伙伴。
1、 Hystrix Collapser
hystrix
开源的请求合并类库(知名的)好像也只有 Netflix 公司开源的 Hystrix 了, hystrix 专注于保持 WEB 服务器在高并发环境下的系统稳定,我们常用它的熔断器(Circuit Breaker) 来实现服务的服务隔离和灾时降级,有了它,可以使整个系统不至于被某一个接口的高并发洪流冲塌,即使接口挂了也可以将服务降级,返回一个人性化的响应。请求合并作为一个保障下游服务稳定的利器,在 hystrix 内实现也并不意外。
我们在使用 hystrix 时,常用它的 javanica 模块,以注解的方式编写 hystrix 代码,使代码更简洁而且对业务代码侵入更低。所以在项目中我们一般至少需要引用 hystrix-core 和 hystrix-javanica 两个包。
另外,hystrix 的实现都是通过 AOP,我们要还要在项目 xml 里显式配置 HystrixAspect 的 bean 来启用它。
<aop:aspectj-autoproxy/> <bean id="hystrixAspect" class="com.netflix.hystrix.contrib.javanica.aop.aspectj.HystrixCommandAspect" />
hystrix collapser 是 hystrix 内的请求合并器,它有自定义 BatchMethod 和 注解两种实现方式,自定义 BatchMethod 网上有各种教程,实现起来很复杂,需要手写大量代码,而注解方式只需要添加两行注解即可,但配置方式我在官方文档上也没找见,中文方面本文应该是独一份儿了。
其实现需要注意的是:
-
我们在需要合并的方法上添加 @HystrixCollapser 注解,在定义好的合并方法上添加 @HystrixCommand 注解;
-
single 方法只能传入一个参数,多参数情况下需要自己包装一个参数类,而 batch 方法需要 java.util.List<SingleParam>;
-
single 方法返回 java.util.concurrent.Future<SingleReturn>, batch 方法返回 java.util.List<SingleReturn>,且要保证返回的结果数量和传入的参数数量一致。
下面是一个简单的示例:
public class HystrixCollapserSample {
@HystrixCollapser(batchMethod = "batch")
public Future<Boolean> single(String input) {
return null; // single方法不会被执行到
}
public List<Boolean> batch(List<String> inputs) {
return inputs.stream().map(it -> Boolean.TRUE).collect(Collectors.toList());
}
}
源码实现
为了解决 hystrix collapser 的配置问题看了下 hystrix javanica 的源码,这里简单总结一下 hystrix 请求合并器的具体实现,源码的详细解析在我的笔记:Hystrix collasper 源码解析。
-
在 spring-boot 内注册切面类的 bean,里面包含 @HystrixCollapser 注解切面;
-
在方法执行时检测到方法被 HystrixCollapser 注解后,spring 调用 methodsAnnotatedWithHystrixCommand方法来执行 hystrix 代理;
-
hystrix 获取一个 collapser 实例(在当前 scope 内检测不到即创建);
-
hystrix 将当前请求的参数提交给 collapser, 由 collapser 存储在一个 concurrentHashMap (RequestArgumentType -> CollapsedRequest)内,此方法会创建一个 Observable 对象,并返回一个 观察此对象的 Future 给业务线程;
-
collpser 在创建时会创建一个 timer 线程,定时消费存储的请求,timer 会将多个请求构造成一个合并后的请求,调用 batch 执行后将结果顺序映射到输出参数,并通知 Future 任务已完成。
需要注意,由于需要等待 timer 执行真正的请求操作,collapser 会导致所有的请求的 cost 都会增加约 timerInterval/2 ms;
配置
hystrix collapser 的配置需要在 @HystrixCollapser 注解上使用,主要包括两个部分,专有配置和 hystrixCommand 通用配置;
专有配置包括:
-
collapserKey,这个可以不用配置,hystrix 会默认使用当前方法名;
-
batchMethod,配置 batch 方法名,我们一般会将 single 方法和 batch 方法定义在同一个类内,直接填方法名即可;
-
scope,最坑的配置项,也是逼我读源码的元凶,com.netflix.hystrix.HystrixCollapser.Scope 枚举类,有 REQUEST, GLOBAL 两种选项,在 scope 为 REQUEST 时,hystrix 会为每个请求都创建一个 collapser, 此时你会发现 batch 方法执行时,传入的请求数总为1。而且 REQUEST 项还是默认项,不明白这样请求合并还有什么意义;
-
collapserProperties, 在此选项内我们可以配置 hystrixCommand 的通用配置;
通用配置包括:
-
maxRequestsInBatch, 构造批量请求时,使用的单个请求的最大数量;
-
timerDelayInMilliseconds, 此选项配置 collapser 的 timer 线程多久会合并一次请求;
-
requestCache.enabled, 配置提交请求时是否缓存;
一个完整的配置如下:
@HystrixCollapser(
batchMethod = "batch",
collapserKey = "single",
scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL,
collapserProperties = {
@HystrixProperty(name = "maxRequestsInBatch", value = "100"),
@HystrixProperty(name = "timerDelayInMilliseconds", value = "1000"),
@HystrixProperty(name = "requestCache.enabled", value = "true")
})
2、BatchCollapser
设计
由于业务需求,我们并不太关心被合并请求的返回值,而且觉得 hystrix 保持那么多的 Future 并没有必要,于是自己实现了一个简单的请求合并器,业务线程简单地将请求放到一个容器里,请求数累积到一定量或延迟了一定的时间,就取出容器内的数据统一发送给下游系统。
设计思想跟 hystrix 类似,合并器有一个字段作为存储请求的容器,且设置一个 timer 线程定时消费容器内的请求,业务线程将请求参数提交到合并 器的容器内。
不同之处在于,业务线程将请求提交给容器后立即同步返回成功,不必管请求的消费结果,这样便实现了时间维度上的合并触发。
另外,我还添加了另外一个维度的触发条件,每次将请求参数添加到容器后都会检验一下容器内请求的数量,如果数量达到一定的阈值,将在业务线程内合并执行一次。
由于有两个维度会触发合并,就不可避免会遇到线程安全问题。为了保证容器内的请求不会被多个线程重复消费或都漏掉,我需要一个容器能满足以下条件:
-
是一种 Collection,类似于 ArrayList 或 Queue,可以存重复元素且有顺序;
-
在多线程环境中能安全地将里面的数据全取出来进行消费,而不用自己实现锁。
java.util.concurrent 包内的 LinkedBlockingDeque 刚好符合要求,首先它实现了 BlockingDeque 接口,多线程环境下的存取操作是安全的;此外,它还提供 drainTo(Collection<? super E> c, int maxElements)方法,可以将容器内 maxElements 个元素安全地取出来,放到 Collection c 中。
实现
以下是具体的代码实现:
public class BatchCollapser<E> implements InitializingBean {
private static final Logger logger = LoggerFactory.getLogger(BatchCollapser.class);
private static volatile Map<Class, BatchCollapser> instance = Maps.newConcurrentMap();
private static final ScheduledExecutorService SCHEDULE_EXECUTOR = Executors.newScheduledThreadPool(1);
private volatile LinkedBlockingDeque<E> batchContainer = new LinkedBlockingDeque<>();
private Handler<List<E>, Boolean> cleaner;
private long interval;
private int threshHold;
private BatchCollapser(Handler<List<E>, Boolean> cleaner, int threshHold, long interval) {
this.cleaner = cleaner;
this.threshHold = threshHold;
this.interval = interval;
}
@Override
public void afterPropertiesSet() throws Exception {
SCHEDULE_EXECUTOR.scheduleAtFixedRate(() -> {
try {
this.clean();
} catch (Exception e) {
logger.error("clean container exception", e);
}
}, 0, interval, TimeUnit.MILLISECONDS);
}
public void submit(E event) {
batchContainer.add(event);
if (batchContainer.size() >= threshHold) {
clean();
}
}
private void clean() {
List<E> transferList = Lists.newArrayListWithExpectedSize(threshHold);
batchContainer.drainTo(transferList, 100);
if (CollectionUtils.isEmpty(transferList)) {
return;
}
try {
cleaner.handle(transferList);
} catch (Exception e) {
logger.error("batch execute error, transferList:{}", transferList, e);
}
}
public static <E> BatchCollapser getInstance(Handler<List<E>, Boolean> cleaner, int threshHold, long interval) {
Class jobClass = cleaner.getClass();
if (instance.get(jobClass) == null) {
synchronized (BatchCollapser.class) {
if (instance.get(jobClass) == null) {
instance.put(jobClass, new BatchCollapser<>(cleaner, threshHold, interval));
}
}
}
return instance.get(jobClass);
}
}
以下代码内需要注意的点:
-
由于合并器的全局性需求,需要将合并器实现为一个单例,另外为了提升它的通用性,内部使用使用 concurrentHashMap 和 double check 实现了一个简单的单例工厂。
-
为了区分不同用途的合并器,工厂需要传入一个实现了 Handler 的实例,通过实例的 class 来对请求进行分组存储。
-
由于 java.util.Timer 的阻塞特性,一个 Timer 线程在阻塞时不会启动另一个同样的 Timer 线程,所以使用 ScheduledExecutorService 定时启动 Timer 线程。
# 3、ConcurrentHashMultiset
设计
上面介绍的请求合并都是将多个请求一次发送,下游服务器处理时本质上还是多个请求,最好的请求合并是在内存中进行,将请求结果简单合并成一个发送给下游服务器。如我们经常会遇到的需求:元素分值累加或数据统计,就可以先在内存中将某一项的分值或数据累加起来,定时请求数据库保存。
Guava 内就提供了这么一种数据结构:ConcurrentHashMultiset,它不同于普通的 set 结构存储相同元素时直接覆盖原有元素,而是给每个元素保持一个计数 count, 插入重复时元素的 count 值加1。而且它在添加和删除时并不加锁也能保证线程安全,具体实现是通过一个 while(true) 循环尝试操作,直到操作够所需要的数量。
ConcurrentHashMultiset 这种排重计数的特性,非常适合数据统计这种元素在短时间内重复率很高的场景,经过排重后的数量计算,可以大大降低下游服务器的压力,即使重复率不高,能用少量的内存空间换取系统可用性的提高,也是很划算的。
实现
使用 ConcurrentHashMultiset 进行请求合并与使用普通容器在整体结构上并无太大差异,具体类似于:
if (ConcurrentHashMultiset.isEmpty()) {
return;
}
List<Request> transferList = Lists.newArrayList();
ConcurrentHashMultiset.elementSet().forEach(request -> {
int count = ConcurrentHashMultiset.count(request);
if (count <= 0) {
return;
}
transferList.add(count == 1 ? request : new Request(request.getIncrement() * count));
ConcurrentHashMultiset.remove(request, count);
});
小结
最后总结一下各个技术适用的场景:
-
hystrix collapser: 需要每个请求的结果,并且不在意每个请求的 cost 会增加;
-
BatchCollapser: 不在意请求的结果,需要请求合并能在时间和数量两个维度上触发;
-
ConcurrentHashMultiset:请求重复率很高的统计类场景;
另外,如果选择自己来实现的话,完全可以将 BatchCollapser 和 ConcurrentHashMultiset 结合一下,在BatchCollapser 里使用 ConcurrentHashMultiset 作为容器,这样就可以结合两者的优势了。
如何优雅高效的合并HTTP并发请求的结果
前言
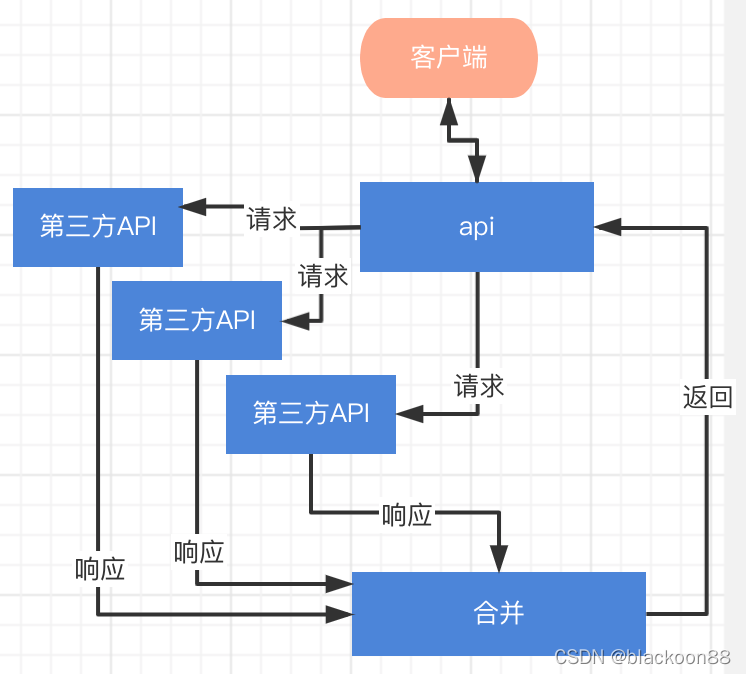
最近做到一个项目,涉及到一个应用场景:对外提供一个接口,接口的内部逻辑是要调用多次第三方接口的返回数据进行组装处理,接口的响应时间100ms以内。
对于这个问题,会涉及到异步调用请求,处理回调,等待-通知机制等过程。对于响应时间的要求,可以设置timeout来控制。
一、方案调研选择
1.一种是自己造轮子
基本思路:自己创建线程池,使用CountDownLatch 的countDown()和await()方法实现等待通知机制,调用http同步请求即可,获取结果可以通过入参方式赋值回调使用(当然也可以用Callable代替Runnable)。
主体示例代码如下:
package com.ws;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
@Slf4j
public class MyRunnable implements Runnable{
private int id ;
private long startDate;
private long endDate;
private CountDownLatch countDownLatch ;
private Callback callback;
public MyRunnable(CountDownLatch countDownLatch,Callback callback, long startDate, int id){
this.id = id ;
this.startDate = startDate;
this.countDownLatch = countDownLatch;
this.callback = callback;
}
@Override
public void run() {
try {
//同步请求逻辑 用等待代替
//http request
//...
if(id ==1){
Thread.sleep(30000);
}else{
Thread.sleep(3000);
}
callback.setResult("rusult:"+id);
endDate =System.currentTimeMillis();
System.out.println("--------"+id+"-----"+(endDate-startDate));
} catch (Exception e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
}
}
package com.ws;
import lombok.Data;
@Data
public class Callback {
public String result;
}
package com.ws;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.ThreadPoolExecutor;
@Slf4j
public class CountDownLatchTest {
public static void execute(){
try {
ThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(2);
CountDownLatch countDownLatch = new CountDownLatch(2);
log.info("--------------start---------");
List<Callback> list =new ArrayList<>();
for (int i = 0; i < 2; i++) {
Callback callback =new Callback();
MyRunnable myRunnable = new MyRunnable(countDownLatch,callback,System.currentTimeMillis(),i+1);
executor.execute(myRunnable);
list.add(callback);
}
countDownLatch.await();
list.forEach(call ->{
log.info(call.getResult());
});
executor.shutdown();
log.info("--------------end---------");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
execute();
}
}
2.一种选择开源框架来解决问题
由于响应时间和并发量要求高,采用okhttp框架来解决我们的问题,不考虑HttpClient和RestTemplate等其他框架。
选择依据:
性能上:
允许所有同一个主机地址的请求共享同一个socket连接
连接池减少请求延时
透明的GZIP压缩减少响应数据的大小
缓存响应内容,避免一些完全重复的请求
API使用上:
支持阻塞式的同步请求和带回调的异步请求,很符合我的需求。
二、业务流程图
三、基础代码
1.OkHttp客户端配置,主要是配置连接池和Dispatcher。
@Configuration
@Slf4j
public class OkHttpConfiguration {
@Resource
private PropertiesConfig propertiesConfig;
public ConnectionPool pool;
public JSONObject getPool(){
JSONObject jo = new JSONObject();
jo.put("connectionCount",pool.connectionCount());
jo.put("idleConnectionCount",pool.idleConnectionCount());
return jo;
}
@Bean
public OkHttpClient okHttpClient() {
OKHttpConfigBo okhttpConfig = propertiesConfig.getOKHttpConfig();
this.pool = pool();
return new OkHttpClient.Builder()
//.sslSocketFactory(sslSocketFactory(), x509TrustManager())
.retryOnConnectionFailure(false)
.connectionPool(this.pool)
.dispatcher(dispatcher())
.connectTimeout(okhttpConfig.getConnectTimeout()!=null?okhttpConfig.getConnectTimeout():100, TimeUnit.MILLISECONDS)
.readTimeout(okhttpConfig.getReadTimeout()!=null?okhttpConfig.getReadTimeout():50, TimeUnit.MILLISECONDS)
.writeTimeout(okhttpConfig.getWriteTimeout()!=null?okhttpConfig.getWriteTimeout():50,TimeUnit.MILLISECONDS)
.build();
}
@Bean
public Dispatcher dispatcher(){
Dispatcher dispatcher = new Dispatcher();
OKHttpConfigBo okhttpConfig = propertiesConfig.getOKHttpConfig();
dispatcher.setMaxRequests(okhttpConfig.getMaxRequest());
dispatcher.setMaxRequestsPerHost(okhttpConfig.getMaxRequestsPerHost());
return dispatcher;
}
@Bean
public X509TrustManager x509TrustManager() {
return new X509TrustManager() {
@Override
public void checkClientTrusted(X509Certificate[] x509Certificates, String s) throws CertificateException {
}
@Override
public void checkServerTrusted(X509Certificate[] x509Certificates, String s) throws CertificateException {
}
@Override
public X509Certificate[] getAcceptedIssuers() {
return new X509Certificate[0];
}
};
}
@Bean
public SSLSocketFactory sslSocketFactory() {
try {
//信任任何链接
SSLContext sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, new TrustManager[]{x509TrustManager()}, new SecureRandom());
return sslContext.getSocketFactory();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (KeyManagementException e) {
e.printStackTrace();
}
return null;
}
/**
* Create a new connection pool with tuning parameters appropriate for a single-user application.
* The tuning parameters in this pool are subject to change in future OkHttp releases. Currently
*/
@Bean
public ConnectionPool pool() {
OKHttpConfigBo okhttpConfig = propertiesConfig.getOKHttpConfig();
Integer maxIdleConnections = okhttpConfig.getMaxIdleConnections();
Long keepAliveDuration = okhttpConfig.getKeepAliveDuration();
return new ConnectionPool(maxIdleConnections!=null?maxIdleConnections:200, keepAliveDuration!=null?keepAliveDuration:5, TimeUnit.MINUTES);
}
}
2.异步请求
public static Call asyncPost(String url, String jsonParams,HttpRequestCallback callback) {
String responseBody = "";
RequestBody requestBody = RequestBody.create(MediaType.parse("application/json; charset=utf-8"), jsonParams);
Request request = new Request.Builder()
.url(url)
.post(requestBody)
.build();
Response response = null;
Call call = null;
try {
call =okHttpClient.newCall(request);
call.enqueue(callback);
} catch (Exception e) {
logger.error("okhttp3 post error >> ex = {}", ExceptionUtils.getStackTrace(e));
}
return call;
}
3.实现回调接口
@Data
@Slf4j
public class HttpRequestCallback implements Callback {
public Long startTime;
public volatile Integer RespCode;
public String RespMessage;
public String RespBody;
public Long endTime;
public Integer priority;
public String dsp_id;
public MediaResponse mediaResponse;
@Override
public void onFailure(Call call, IOException e) {
if(e!=null){
this.setEndTime(System.currentTimeMillis());
this.setRespMessage("request dsp fail");
if(e instanceof SocketTimeoutException){
this.setRespCode(ADStatusEnum.Timeout.getCode());
}else{
this.setRespCode(ADStatusEnum.SEVEN.getCode());
}
}
synchronized (this){
this.notify();
}
}
@Override
public void onResponse(Call call, Response response) throws IOException {
this.setRespMessage(response.message());
if (response.isSuccessful()) {
this.setRespBody(response.body().string());
}
this.setEndTime(System.currentTimeMillis());
this.setRespCode(response.code());
if (response != null) {
response.close();
}
synchronized (this){
this.notify();
}
}
4.等待通知机制
List<HttpRequestCallback> callbacks = new ArrayList<>();
//调用异步请求,讲回调函数加到callbacks,此处代码省略
callbacks.forEach(call ->{
synchronized (call){
if(call.getRespCode()==null){
try {
call.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
注意:不要使用循环等待,会过量消耗CPU,如果不想使用wait()和notify(),可以试下调用返回的call,是否可以起到等待通知的等价效果。
四、配置优化
连接池参数
maxIdleConnections:可以复用同host的个数
keepAliveDuration:keep-alive(TCP连接复用时长),也就是建立连接的握手时间可以省略 单位分钟。
分发器dispatcher参数
maxRequest:最大请求数
maxRequestsPerHost:每个Host最大请求
根据服务器的资源和业务的特点,调整这两个参数可以加大并发量
超时时间参数
connectTimeout:建立创建TCP连接的时间,通过连接预热可以减少这块的时间;
readTimeout:inputstream时间,可以理解为获取返回数据的最大时间;
writeTimeout:outstream时间,可以理解为写入请求数据的最大时间;
响应时间100ms,配置如下
ReadTimeout=100,writeTimeout=50;connectTimeout=60.
总结
在OkHttp中分别对Request和Response进行了封装,并通过Request对象构建了Call对象,请求由分发器进行维护和分发。对于同步请求,分发器直接在调用的线程中进行请求;而对于异步请求,主要是利用线程池进行,在请求结束后对准备请求的队列进行筛选,将合适的请求放入到运行队列当中并对异步请求进行相应的回调,通知调用者。
————————————————