https://www.w3cschool.cn/jenkins/

手册简介
Jenkins是一个开源的持续集成的服务器,Jenkins开源帮助我们自动构建各类项目。Jenkins强大的插件式,使得Jenkins可以集成很多软件,可能帮助我们持续集成我们的工程项目。
手册说明

Jenkins是一个独立的开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能。前身是Hudson是一个可扩展的持续集成引擎。可用于自动化各种任务,如构建,测试和部署软件。Jenkins可以通过本机系统包Docker安装,甚至可以通过安装Java Runtime Environment的任何机器独立运行。
主要用于:
- 持续、自动地构建/测试软件项目,如CruiseControl与DamageControl。
- 监控一些定时执行的任务。
环境搭建
Jenkins支持各个平台上的搭建过程,开发我们主要在Linux和win7上玩转Jenkins,这边主要通过win7下介绍Jenkins玩法,Linux上大同小异。
Jenkins特点:
- 开源免费;
- 跨平台,支持所有的平台;
- master/slave支持分布式的build;
- web形式的可视化的管理页面;
- 安装配置超级简单;
- tips及时快速的帮助;
- 已有的200多个插件
Jenkins 介绍
Jenkins是一个独立的开源自动化服务器,可用于自动化各种任务,如构建,测试和部署软件。Jenkins可以通过本机系统包Docker安装,甚至可以通过安装Java Runtime Environment的任何机器独立运行。
说明
本说明是针对使用需要Java 8的“独立”Jenkins发行版。还建议使用超过512MB RAM的系统。
- 下载Jenkins。
- 在下载目录中打开终端并运行 java -jar jenkins.war --httpPort=8080
- 浏览http://localhost:8080并按照说明完成安装。
- 许多Pipeline示例需要 在与Jenkins相同的计算机上安装Docker。Docker安装下载教程:点击查看
安装完成后,开始将Jenkins运行并创建Pipeline。
Jenkins Pipeline是一套插件,支持将连续输送Pipeline实施和整合到Jenkins。Pipeline提供了一组可扩展的工具,用于将“复制代码”作为代码进行建模。
Jenkinsfile 是一个包含Jenkins Pipeline定义的文本文件,并被检入源代码控制。这是“Pipeline代码”的基础; 处理连续输送Pipeline的一部分应用程序,以像其他代码一样进行版本检查。创建Jenkinsfile提供了一些直接的好处:
- 自动创建所有分支和拉请求的Pipeline
- Pipeline上的代码审查/迭代
- Pipeline的审计跟踪
- Pipeline的唯一真实来源 ,可以由项目的多个成员查看和编辑。
虽然在Web UI或a中定义Pipeline的语法 Jenkinsfile是相同的,但通常认为最佳做法是在Jenkinsfile中定义Pipeline并检查源控制。
Jenkins 如何创建Pipeline
开始创建您的第一个Pipeline
快速入门Pipeline:
- 将其中一个示例复制到您的存储库并将其命名Jenkinsfile
- 单击Jenkins中的New Item菜单
- 为您的新项目提供名称(例如我的Pipeline),然后选择多分支Pipeline
- 单击添加源按钮,选择要使用的存储库的类型并填写详细信息。
- 点击保存按钮并观看您的第一条Pipeline运行!
您可能需要修改一个示例Jenkinsfile以使其与您的项目一起运行。尝试修改sh命令以运行您在本地计算机上运行的相同命令。
设置你的Pipeline后,Jenkins将自动检测在存储库中创建的任何新分支或拉请求,并为其启动运行Pipeline。
快速启动示例
以下是一些简单的复制和粘贴的一个简单的流水线与各种语言的例子。
Java
Jenkinsfile (Declarative Pipeline)
pipeline {
agent { docker 'maven:3.3.3' }
stages {
stage('build') {
steps {
sh 'mvn --version'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
/* Requires the Docker Pipeline plugin */
node('docker') {
checkout scm
stage('Build') {
docker.image('maven:3.3.3').inside {
sh 'mvn --version'
}
}
}Node.js / JavaScript
Jenkinsfile (Declarative Pipeline)
pipeline {
agent { docker 'node:6.3' }
stages {
stage('build') {
steps {
sh 'npm --version'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
/* Requires the Docker Pipeline plugin */
node('docker') {
checkout scm
stage('Build') {
docker.image('node:6.3').inside {
sh 'npm --version'
}
}
}Ruby
Jenkinsfile (Declarative Pipeline)
pipeline {
agent { docker 'ruby' }
stages {
stage('build') {
steps {
sh 'ruby --version'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
/* Requires the Docker Pipeline plugin */
node('docker') {
checkout scm
stage('Build') {
docker.image('ruby').inside {
sh 'ruby --version'
}
}
}Python
Jenkinsfile (Declarative Pipeline)
pipeline {
agent { docker 'python:3.5.1' }
stages {
stage('build') {
steps {
sh 'python --version'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
/* Requires the Docker Pipeline plugin */
node('docker') {
checkout scm
stage('Build') {
docker.image('python:3.5.1').inside {
sh 'python --version'
}
}
}PHP
Jenkinsfile (Declarative Pipeline)
pipeline {
agent { docker 'php' }
stages {
stage('build') {
steps {
sh 'php --version'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
/* Requires the Docker Pipeline plugin */
node('docker') {
checkout scm
stage('Build') {
docker.image('php').inside {
sh 'php --version'
}
}
}Jenkins 运行多个步骤
Pipeline由多个步骤组成,允许您构建,测试和部署应用程序。Jenkins Pipeline允许您以简单的方式组合多个步骤,可以帮助您建模任何类型的自动化过程。
想像一个“一步一步”,就像执行单一动作的单一命令一样。当一个步骤成功时,它移动到下一步。当步骤无法正确执行时,Pipeline将失败。
当Pipeline中的所有步骤成功完成后,Pipeline被认为已成功执行。
Linux,BSD和Mac OS
在Linux,BSD和Mac OS(或其他类Unix)系统上,该sh步骤用于在Pipeline中执行shell命令。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'echo "Hello World"'
sh '''
echo "Multiline shell steps works too"
ls -lah
'''
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
stage('Build') {
sh 'echo "Hello World"'
sh '''
echo "Multiline shell steps works too"
ls -lah
'''
}
}Windows
基于Windows的系统应该使用bat执行批处理命令的步骤。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Deploy') {
steps {
retry(3) {
sh './flakey-deploy.sh'
}
timeout(time: 3, unit: 'MINUTES') {
sh './health-check.sh'
}
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
stage('Build') {
bat 'set'
}
}超时,重试等等
有一些强大的步骤,“包装”其他步骤,可以轻松地解决问题,如重试(retry)步骤,直到成功或退出,如果步骤太长(timeout)。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Deploy') {
steps {
retry(3) {
sh './flakey-deploy.sh'
}
timeout(time: 3, unit: 'MINUTES') {
sh './health-check.sh'
}
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
stage('Deploy') {
retry(3) {
sh './flakey-deploy.sh'
}
timeout(time: 3, unit: 'MINUTES') {
sh './health-check.sh'
}
}
}“部署”阶段重试flakey-deploy.sh脚本3次,然后等待health-check.sh脚本执行最多3分钟。如果健康检查脚本在3分钟内未完成,则Pipeline将在“部署”阶段被标记为失败。
“包装”的步骤,例如timeout和retry可以包含其它步骤,包括timeout或retry。
我们可以组合这些步骤。例如,如果我们想重新部署我们的部署5次,但是在失败的阶段之前,总是不想花3分钟以上:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Deploy') {
steps {
timeout(time: 3, unit: 'MINUTES') {
retry(5) {
sh './flakey-deploy.sh'
}
}
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
stage('Deploy') {
timeout(time: 3, unit: 'MINUTES') {
retry(5) {
sh './flakey-deploy.sh'
}
}
}
}完成
当Pipeline完成执行后,您可能需要运行清理步骤或根据Pipeline的结果执行某些操作。可以在本post节中执行这些操作。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Test') {
steps {
sh 'echo "Fail!"; exit 1'
}
}
}
post {
always {
echo 'This will always run'
}
success {
echo 'This will run only if successful'
}
failure {
echo 'This will run only if failed'
}
unstable {
echo 'This will run only if the run was marked as unstable'
}
changed {
echo 'This will run only if the state of the Pipeline has changed'
echo 'For example, if the Pipeline was previously failing but is now successful'
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
try {
stage('Test') {
sh 'echo "Fail!"; exit 1'
}
echo 'This will run only if successful'
} catch (e) {
echo 'This will run only if failed'
// Since we're catching the exception in order to report on it,
// we need to re-throw it, to ensure that the build is marked as failed
throw e
} finally {
def currentResult = currentBuild.result ?: 'SUCCESS'
if (currentResult == 'UNSTABLE') {
echo 'This will run only if the run was marked as unstable'
}
def previousResult = currentBuild.previousBuild?.result
if (previousResult != null && previousResult != currentResult) {
echo 'This will run only if the state of the Pipeline has changed'
echo 'For example, if the Pipeline was previously failing but is now successful'
}
echo 'This will always run'
}
}Jenkins 定义执行环境
在上一节中, 您可能已经注意到agent每个示例中的指令。该 agent指令告诉Jenkins在哪里以及如何执行Pipeline或其子集。如您所料,agent所有Pipeline都是必需的。
在引擎盖下,有几件事情agent会发生:
有几种方法可以定义代理在Pipeline中使用,对于本次巡视,我们将仅关注使用短暂的Docker container。
Pipeline设计用于容易地使用Docker图像和容器在里面运行。这允许Pipeline定义所需的环境和工具,而无需手动配置各种系统工具和对代理的依赖。这种方法允许您几乎可以使用可以打包在Docker容器中的任何工具 。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent {
docker { image 'node:7-alpine' }
}
stages {
stage('Test') {
steps {
sh 'node --version'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
/* Requires the Docker Pipeline plugin to be installed */
docker.image('node:7-alpine').inside {
stage('Test') {
sh 'node --version'
}
}
}当Pipeline执行时,Jenkins将自动启动指定的容器并执行其中定义的步骤:
[Pipeline] stage
[Pipeline] { (Test)
[Pipeline] sh
[guided-tour] Running shell script
+ node --version
v7.4.0
[Pipeline] }
[Pipeline] // stage
[Pipeline] }混合和匹配不同容器或其他代理时,在执行Pipeline时可以有很大的灵活性,有关更多配置选项,请继续使用“使用环境变量”。
Jenkins 使用环境变量
Jenkins 环境变量可以全局设置,如下面的示例或每个阶段。您可能会期望,每个阶段设置环境变量意味着它们将仅适用于定义它们的阶段。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
environment {
DISABLE_AUTH = 'true'
DB_ENGINE = 'sqlite'
}
stages {
stage('Build') {
steps {
sh 'printenv'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
withEnv(['DISABLE_AUTH=true',
'DB_ENGINE=sqlite']) {
stage('Build') {
sh 'printenv'
}
}
}这种从内部定义环境变量的方法Jenkinsfile 对于指示脚本(例如a)可以非常有用Makefile,以不同的方式配置构建或测试,以在Jenkins内部运行它们。
环境变量的另一个常见用途是在构建或测试脚本中设置或覆盖“虚拟”凭据。因为(显而易见)将凭据直接放入一个不好的主意Jenkinsfile,Jenkins Pipeline允许用户快速而安全地访问预定义的凭据,而Jenkinsfile无需知道其价值。
环境证书
如果您的Jenkins环境配置了凭据,例如构建秘密或API令牌,那么可以将它们轻松插入环境变量中,以便在Pipeline中使用。下面的代码片段用于“秘密文本”类型的凭据。
environment {
AWS_ACCESS_KEY_ID = credentials('AWS_ACCESS_KEY_ID')
AWS_SECRET_ACCESS_KEY = credentials('AWS_SECRET_ACCESS_KEY')
}正如第一个例子,这些变量将在全局或每个阶段可用,具体取决于environment指令 在哪里Jenkinsfile。
第二种最常见的凭证类型是“用户名和密码”,仍然可以在environment指令中使用,但会导致稍微不同的变量被设置。
environment {
SAUCE_ACCESS = credentials('sauce-lab-dev')
}这将实际设置3个环境变量:
SAUCE_ACCESS 含 <username>:<password>
SAUCE_ACCESS_USR 包含用户名
SAUCE_ACCESS_PSW 包含密码credentials仅适用于声明性Pipeline。对于使用脚本Pipeline的用户,请参阅该withCredentials步骤的文档。到目前为止,我们关心的是创建一个配置并执行我们期望的方式的Pipeline。在接下来的两个部分中,我们将介绍连续交付的另一个重要方面:表面反馈和信息。
Jenkins 记录测试结果和工件
虽然测试是良好的连续交付流程的关键部分,但大多数人不想筛选数千行控制台输出,以查找有关测试失败的信息。为了使这更容易,Jenkins可以记录和汇总测试结果,只要您的测试运行器可以输出测试结果文件。Jenkins通常捆绑在一起junit,但是如果您的测试运行器无法输出JUnit风格的XML报告,则还会有其他插件,可以处理任何广泛使用的测试报告格式。
要收集我们的测试结果和工件,我们将使用该post部分。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Test') {
steps {
sh './gradlew check'
}
}
}
post {
always {
junit 'build/reports/**/*.xml'
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
try{
stage('Test') {
sh './gradlew check'
}
finally {
junit 'build/reports/**/*.xml'
}
}这将永远抓住测试结果,让Jenkins跟踪他们,计算趋势并对其进行报告。测试失败的Pipeline将被标记为“不稳定”,在Web UI中用黄色表示。这与“FAILED”状态不同,用红色表示。
当有测试失败时,从Jenkins抓住建造的文物进行本地分析和调查往往是有用的。Jenkins内置的支持存储“工件”,在Pipeline执行过程中生成的文件,实际上是这样。
这很容易通过archive步骤和文件集合表达式完成,如下面的示例所示:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Build') {
steps {
sh './gradlew build'
}
}
stage('Test') {
steps {
sh './gradlew check'
}
}
}
post {
always {
archive 'build/libs/**/*.jar'
junit 'build/reports/**/*.xml'
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
try{
stage('Test') {
sh './gradlew check'
}
finally {
archiveArtifacts artifacts: 'build/libs/**/*.jar', fingerprint: true
junit 'build/reports/**/*.xml'
}
}记录Jenkins中的测试和工件对于快速轻松地向团队的各个成员发布信息非常有用。在下一节中,我们将讨论如何告诉团队成员什么在我们的Pipeline已经发生的事情。
Jenkins 清理和通知
由于post Pipeline的部分保证在Pipeline执行结束时运行,因此我们可以添加一些通知或其他步骤来执行定稿,通知或其他Pipeline末端任务。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('No-op') {
steps {
sh 'ls'
}
}
}
post {
always {
echo 'One way or another, I have finished'
deleteDir() /* clean up our workspace */
}
success {
echo 'I succeeeded!'
}
unstable {
echo 'I am unstable :/'
}
failure {
echo 'I failed :('
}
changed {
echo 'Things were different before...'
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
try {
stage('No-op') {
sh 'ls'
}
}
}
catch (exc) {
echo 'I failed'
}
finally {
if (currentBuild.result == 'UNSTABLE') {
echo 'I am unstable :/'
} else {
echo 'One way or another, I have finished'
}
}有很多方法可以发送通知,下面是一些演示如何将有关Pipeline的通知发送到电子邮件,Hipchat房间或Slack频道的片段。
post {
failure {
mail to: 'team@example.com',
subject: "Failed Pipeline: ${currentBuild.fullDisplayName}",
body: "Something is wrong with ${env.BUILD_URL}"
}
}Hipchat
post {
failure {
hipchatSend message: "Attention @here ${env.JOB_NAME} #${env.BUILD_NUMBER} has failed.",
color: 'RED'
}
}Slack
post {
success {
slackSend channel: '#ops-room',
color: 'good',
message: "The pipeline ${currentBuild.fullDisplayName} completed successfully."
}
}现在,当事情出现故障,不稳定或甚至成功时,我们可以通过令人兴奋的部分完成我们的持续交付流程:shipping!好了现在让我们来看看下一节:Jenkins部署
Jenkins 部署
最基本的连续交付流程将至少具有三个阶段,这些阶段应在以下内容中定义Jenkinsfile:构建,测试和部署。
对于本节,我们将主要关注部署阶段,但应该注意的是,稳定的构建和测试阶段是任何部署活动的重要前身。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building'
}
}
stage('Test') {
steps {
echo 'Testing'
}
}
stage('Deploy') {
steps {
echo 'Deploying'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
stage('Build') {
echo 'Building'
}
stage('Test') {
echo 'Testing'
}
stage('Deploy') {
echo 'Deploying'
}
}阶段作为部署环境
一个常见的模式是扩展级别以捕获额外的部署环境,如“分段”或“生产”,如下面的代码段所示。
stage('Deploy - Staging') {
steps {
sh './deploy staging'
sh './run-smoke-tests'
}
}
stage('Deploy - Production') {
steps {
sh './deploy production'
}
}在这个例子中,我们假设我们的./run-smoke-tests脚本运行的任何“烟雾测试” 都足以将释放资格或验证到生产环境。自动将代码自动部署到生产的这种Pipeline可以被认为是“持续部署”的实现。虽然这是一个崇高的理想,但对许多人来说,连续部署可能不实际的原因很好,但仍然可以享受持续交付的好处。 Jenkins Pipeline很容易支撑两者。
要求人力投入进行
通常在阶段之间,特别是环境阶段之间,您可能需要人为的输入才能继续。例如,判断应用程序是否处于“促进”到生产环境的状态。这可以通过input步骤完成。在下面的示例中,“真实检查”阶段实际上阻止输入,如果没有人确认进度,则不会继续进行。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
/* "Build" and "Test" stages omitted */
stage('Deploy - Staging') {
steps {
sh './deploy staging'
sh './run-smoke-tests'
}
}
stage('Sanity check') {
steps {
input "Does the staging environment look ok?"
}
}
stage('Deploy - Production') {
steps {
sh './deploy production'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
/* "Build" and "Test" stages omitted */
stage('Deploy - Staging') {
sh './deploy staging'
sh './run-smoke-tests'
}
stage('Sanity check') {
input "Does the staging environment look ok?"
}
stage('Deploy - Production') {
sh './deploy production'
}
}结论
这个导读旨在向您介绍使用Jenkins和Jenkins Pipeline的基础知识。因为它是非常可扩展的,Jenkins可以进行修改和配置,以处理几乎任何方面的自动化。要了解更多关于Jenkins可以做什么的信息,请查看用户手册或 Jenkins博客,了解最新的活动,教程和更新。
Jenkins入门
本章适用于不熟悉Jenkins或没有Jenkins最新版本经验的新用户。
本章将引导您在用于学习目的的系统上安装Jenkins实例,并了解基本的Jenkins概念。它将提供简单的分步教程,介绍如何执行一些常见任务。每个部分的目的是按顺序完成,每一个建筑都是从上一节的知识。当你完成后,你应该有足够的经验与Jenkins的核心,继续探索自己。
如果您已经熟悉Jenkins基础知识,并希望深入了解如何使用特定功能,请参阅 使用Jenkins。
如果您是Jenkins管理员,并想了解更多关于管理Jenkins节点和实例的信息,请参阅 管理Jenkins。
如果您是系统管理员,并且想了解如何备份,还原,维护Jenkins服务器和节点,请参阅 操作Jenkins。
Jenkins安装
概述
本节是入门指南的一部分。它提供了许多平台上基本的Jenkins配置的说明。但不涵盖安装Jenkins的全部注意事项或选项。
预安装
这些仅仅是入门,有关因素的全面讨论,请参见硬件建议讨论 。
系统要求
最小推荐配置:
- Java 8(JRE或JDK)
- 256MB可用内存
- 1GB +可用磁盘空间
推荐配置小团队:
- Java 8
- 1GB +免费内存
- 50GB +可用磁盘空间
实验,分期或生产?
根据您的预期用例,Jenkins的配置将会有很大的不同。本节专门针对初步使用和实验。
独立还是Servlet?
Jenkins可以使用自己的内置Web服务器(Jetty)在自己的进程中独立运行。它也可以作为现有框架中的一个servlet运行,如Tomcat或Glassfish应用程序服务器。本节专门针对独立的安装和执行。
安装
Unix / Linux
在基于Debian的发行版,如Ubuntu,您可以通过安装Jenkins apt。最近的版本在一个apt存储库中可用。旧的但稳定的LTS版本在这个apt存储库。
wget -q -O - https://pkg.jenkins.io/debian/jenkins.io.key | sudo apt-key add -
sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list'
sudo apt-get update
sudo apt-get install jenkins
此包安装将:
- 将Jenkins设置为启动时启动的守护程序。查看/etc/init.d/jenkins更多详情。
- 创建一个jenkins用户来运行这个服务。
- 直接控制台日志输出到文件/var/log/jenkins/jenkins.log。如果您正在对Jenkins进行故障排除,请检查此文件
- 填充/etc/default/jenkins启动的配置参数,例如JENKINS_HOME
- 将Jenkins设置为侦听端口8080.使用浏览器访问此端口以开始配置。
如果你的/etc/init.d/jenkins文件无法启动Jenkins,编辑/etc/default/jenkins,以取代线 ----HTTP_PORT=8080----用----HTTP_PORT=8081---- 在这里,“8081”被选为但你可以把可用的其他端口OpenIndiana Hipster
在运行OpenIndiana Hipster的系统中, Jenkins可以使用图像打包系统(IPS)安装在本地或全局区域中 。
免责声明:该平台尚未由Jenkins团队正式支持,您自己承担风险。OpenIndiana Hipster团队维护本节中描述的包装和整合,将通用工具捆绑jenkins.war 在该操作环境中。对于将每周最新打包的版本作为独立(Jetty)服务器运行的常见情况,只需执行:
pkg install jenkins
svcadm enable jenkins独立服务的常见包装集成将:
- 创建一个jenkins用户来运行服务并拥有目录结构/var/lib/jenkins。
- 拉OpenJDK8等执行Jenkins所需的jenkins-core-weekly软件包,包括最新的软件包jenkins.war。长期支持(LTS)Jenkins发行版目前不支持基于OpenZFS的系统,因此目前不提供打包。
- 将Jenkins设置为SMF服务实例(svc:/network/http:jenkins),然后可以使用svcadm上面显示的命令启用Jenkins 。
- 设置Jenkins在8080端口上听。
- 配置由SMF管理的日志输出/var/svc/log/network-http:jenkins.log。
一旦Jenkins运行,请咨询log(/var/svc/log/network-http:jenkins.log)来检索Jenkins初始设置生成的管理员密码,通常会在那里找到/var/lib/jenkins/home/secrets/initialAdminPassword。然后导航到 localhost:8080以完成Jenkins实例的配置。
要更改服务的属性,例如JENKINS_HOME Jetty Web服务器使用的环境变量或端口号,请使用该svccfg实用程序:
svccfg -s svc:/network/http:jenkins editprop
svcadm refresh svc:/network/http:jenkins您还可以参考/lib/svc/manifest/network/jenkins-standalone.xml有关SMF服务的当前支持的可调参数的更多详细信息和注释。请注意,jenkins由包装创建的用户帐户是特权的,允许绑定到1024以下的端口号。
可以查询给定版本的OpenIndiana的Jenkins相关软件包的当前状态:
pkg info -r '*jenkins*'可以通过更新整个操作环境pkg update,或专门为Jenkins核心软件执行升级,方法如下:
pkg update jenkins-core-weekly更新软件包的过程将重新启动当前运行的Jenkins进程。如果需要,请确保在更新之前准备关闭并完成所有正在运行的程序。Solaris, OmniOS, SmartOS和其他
一般来说,应该足以安装Java8和下载的 jenkins.war,并运行它作为一个独立的进程或应用服务器,比如Apache Tomcat。
一些注意事项使用:
- Headless JVM和字体:对于OpenJDK构建在最小化的脚本系统上,运行Headless JVM可能会出现问题,因为Jenkins需要一些字体来渲染某些页面。
- ZFS相关的JVM崩溃:当Jenkins在被检测到的系统上运行时SunOS,它会尝试使用捆绑的加载集成高级ZFS功能libzfs.jar,将来自Java的调用映射到libzfs.so主机操作系统提供的本地例程。不幸的是,该库是为了在操作系统中构建和捆绑的二进制实用程序,同时与它一起制作,并不是作为一个稳定界面显示给消费者的。作为Solaris遗留的分支,包括ZFS以及随后的OpenZFS计划的发展,许多不同的二进制功能签名由不同的主机操作系统提供 - 当Jenkins libzfs.jar调用错误的签名时,整个JVM进程崩溃。jenkins.war自从每周发布2.55(至今尚未在任何LTS中)以来,提出并整合了一个解决方案。使管理员能够配置哪些功能签名应该用于已知具有不同变体的每个功能,将其应用于其应用程序服务器初始化选项,然后运行和更新通用而不需要进一步的解决方法。有关更多详细信息,请参阅 libzfs4j Git存储库,包括尝试使用脚本并“锁定”您特定分发所需的配置(特别是如果您的内核更新带来新的不兼容libzfs.so)。
另请注意,OpenZFS计划的分支可能会在各种BSD,Linux和macOS发行版上提供ZFS。一旦Jenkins支持检测ZFS功能,而不是依赖于SunOS检查,则应考虑上述与Jenkins集成ZFS的注意事项。
MACOS
要从网站安装,使用一个包:
- 下载最新的软件包
- 打开包装并按照说明进行操作
jenkins也可以使用brew进行安装:
- 安装最新版本
brew install jenkins
- 安装LTS版本
brew install jenkins
Windows
要从网站安装,请使用安装程序:
- 下载最新的软件包
- 打开包装并按照说明进行操作
Docker
您必须在您的机器上正确安装Docker。有关详细信息,请参阅Docker安装指南。
首先,从Docker存储库中取出官方的jenkins图像。
docker pull jenkins/jenkins接下来,使用此映像运行容器并将数据目录从容器映射到主机; 例如在下面的示例中/var/jenkins_home,容器jenkins/从主机上的当前路径映射到目录。jenkins8080接口也显示在主机49001。
docker run -d -p 49001:8080 -v $PWD/jenkins:/var/jenkins_home -t jenkins/jenkins安装后(安装向导)
为Jenkins创建管理员用户和密码
Jenkins最初配置为在首次启动时安全。无需使用用户名和密码即可访问Jenkins,并且开放端口有限。在Jenkins的初始运行期间,生成安全令牌并将其打印在控制台日志中:
************************************************** *********** 需要Jenkins初始设置。需要安全令牌才能继续。 请使用以下安全令牌继续安装: 41d2b60b0e4cb5bf2025d33b21cb ************************************************** ***********
以上每个平台的安装说明包括可以找到此日志输出的默认位置。首次打开Jenkins UI时,必须在“安装向导”中输入此令牌。如果您跳过安装向导中的用户创建步骤,此令牌也将作为用户管理员的默认密码。
初始插件安装
安装向导还将安装此Jenkins服务器的初始插件。推荐的可用插件是基于最常见的用例。您可以在安装向导期间自由添加更多内容,然后再根据需要进行安装。
Jenkins词汇表
通用规则
- Agent
- Agent通常是一个机器或容器,它连接到Jenkins主机,并在主控器指导时执行任务。
- Artifact
-
在Build或Pipeline 运行期间生成的不可变文件,该文件归档到Jenkins Master上以供用户随后检索。
- Build
-
项目 单次执行的结果
- Cloud
-
提供动态代理 配置和分配的系统配置,例如由Azure VM Agents 或 Amazon EC2插件提供的配置和分配 。
- Core
-
主要的Jenkins应用程序(
jenkins.war)提供了 可以构建Plugins的基本Web UI,配置和基础。 - Downstream
-
配置Pipeline或项目时被触发作为一个单独的Pipeline或项目的执行的一部分。
- Executor
-
用于执行由节点上的Pipeline或 项目定义的工作的插槽。节点可以具有零个或多个配置的执行器,其对应于在该节点上能够执行多少并发项目或Pipeline。
- Fingerprint
-
考虑全局唯一性的哈希追踪跨多个Pipeline或项目的工件或其他实体 的使用 。
- Folder
-
类似于文件系统上的文件夹的Pipeline和/或 项目 的组织容器。
- Item
-
Web UI中的实体对应于:Folder, Pipeline, or Project.
- Job
-
一个不推荐的术语,与项目同义。
- Label
-
用于分组代理的用户定义的文本,通常具有类似的功能或功能。例如
linux对于基于Linux的代理或docker适用于支持Docker的代理。 - Master
-
存储配置,加载插件以及为Jenkins呈现各种用户界面的中央协调过程。
- Node
-
作为Jenkins环境的一部分并能够执行Pipeline或项目的机器。无论是the Master还是Agents都被认为是Nodes。
- Project
-
用户配置的Jenkins应该执行的工作描述,如构建软件等。
- Pipeline
-
用户定义的连续输送Pipeline模型,以便更多阅读本手册中的“ Pipeline”一章。
- Plugin
-
与Jenkins Core分开提供的Jenkins功能扩展。
- Publisher
-
完成发布报告,发送通知等的所有配置步骤后的 构建的 一部分。
- Stage
-
stage是Pipeline的一部分,用于定义整个Pipeline的概念上不同的子集,例如:“构建”,“测试”和“部署”,许多插件用于可视化或呈现Jenkins Pipeline状态/进度。 - Step
-
单一任务从根本上讲,指的是Jenkins 在Pipeline或项目中做了什么。
- Trigger
-
触发新Pipeline运行或构建的标准。
- Update Center
-
托管插件和插件元数据的库存,以便在Jenkins内部进行插件安装。
- Upstream
-
配置的Pipeline或项目,其触发单独的Pipeline或项目作为其执行的一部分。
- Workspace
-
Noede文件系统上的一次性目录, 可以由Pipeline或项目完成工作。在Build或 Pipeline运行完成后,工作区通常会保留原样,除非在Jenkins Master上已经设置了特定的Workspace清理策略。
Jenkins 使用
本章将介绍如何使用Jenkins作为非管理员用户。它将涵盖适用于所有使用Jenkins的人每天使用的主题。这包括基本主题,例如选择,运行和监控现有作业,以及如何查找和查看作业结果。将继续讨论有关设计和创建项目的一些主题。
本章适合所有技能水平的的Jenkins用户使用。这些部分以特征为中心的方式组织,以便经验丰富的用户更容易搜索和参考。同时,为了帮助初学者,我们尝试从章节中更简单地逐步更复杂的特征区域中的章节。此外,每个部分中的主题将从基础到高级进行,专家级考虑和角落在最后或本章后面的单独部分。
如果您还不熟悉Jenkins的基本术语和功能,请参考 Jenkins入门。
如果您已经熟悉Jenkins基础知识,并希望深入了解如何使用各种功能,请参阅 使用Jenkins。
如果您是系统管理员,并且想了解如何备份,还原,维护Jenkins服务器和节点,请参阅 操作Jenkins。
贡献者:本章作为“ Jenkins入门 ” 的延续,但格式将略有不同 - 请参阅上述说明。我们需要在为有经验的用户提供功能参考之间进行平衡,并为初学者提供持续的学习。有些章节应该写成并标记为只能从“入门”或本章的前一部分中获取知识。Jenkins管理
Jenkins 管理安全
从Jenkins 2.0开始,默认情况下启用了许多安全选项,以确保Jenkins环境保持安全,除非管理员明确禁用某些保护。
本节将介绍Jenkins管理员可用的各种安全选项,解释所提供的保护措施,并对其中某些功能进行权衡。
启用安全性
选中“ 启用安全性”复选框后,自Jenkins 2.0起是默认启用安全性复选框,用户可以使用用户名和密码登录,以执行匿名用户不可用的操作。哪些操作要求用户登录取决于所选择的授权策略及其配置; 默认情况下,匿名用户没有权限,并且登录的用户具有完全的控制权。对于任何非本地(测试)Jenkins环境,应始终启用此复选框。
Web UI的“启用安全性”部分允许Jenkins管理员启用,配置或禁用适用于整个Jenkins环境的关键安全功能。
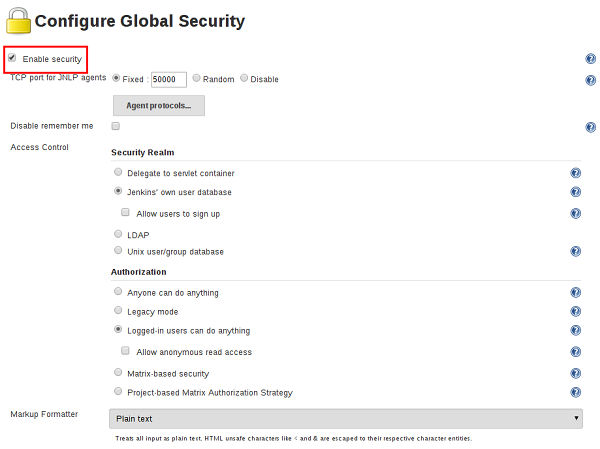
NLP TCP端口
Jenkins使用TCP端口与通过JNLP协议启动的代理(如基于Windows的代理)进行通信。截至Jenkins 2.0,默认情况下此端口被禁用。
对于希望使用基于JNLP的代理的管理员,两个端口选项是:
- 随机:JNLP端口是随机选择的,以避免Jenkins主机发生冲突 。随机JNLP端口的缺点是在Jenkins主引导期间选择它们,这使得难以管理允许JNLP流量的防火墙规则。
- 固定:JNPP端口由Jenkins管理员选择,并且在Jenkins主控器的重新启动之间是一致的。这使得管理防火墙规则更容易,允许基于JNLP的代理连接到主服务器。
访问控制
访问控制是保护Jenkins环境免受未经授权的使用的主要机制。在Jenkins中配置访问控制需要两个方面的配置:
- 一个安全域,其通知Jenkins环境如何以及在哪里获取用户(或标识)的信息。也被称为“认证”。
- 授权配置,通知Jenkins环境,哪些用户和/或组在多大程度上可以访问Jenkins的哪些方面。
使用安全领域和授权配置,可以在Jenkins中配置非常轻松或非常刚性的身份验证和授权方案。
此外,一些插件(如 基于角色的授权策略) 插件可以扩展Jenkins的访问控制功能,以支持更细微的身份验证和授权方案。
安全领域
默认情况下Jenkins包括对几个不同安全领域的支持:
委托给servlet容器
用于委托身份验证运行Jenkins主服务器的servlet容器,如 Jetty。如果使用此选项,请参阅servlet容器的身份验证文档。
Jenkins自己的用户数据库
使用Jenkins自己的内置用户数据存储进行身份验证,而不是委派给外部系统。默认情况下,这将启用新的Jenkins 2.0或更高版本的安装,适用于较小的环境。
LDAP
将所有身份验证委托给配置的LDAP服务器,包括用户和组。对于已经配置了外部身份提供程序(如LDAP)的组织中的较大安装,此选项更为常见。这也支持Active Directory安装。
此功能由可能未安装在您的实例上的LDAP插件提供。Unix用户/组数据库
将认证委托给Jenkins主服务器上的底层Unix操作系统级用户数据库。此模式还允许重新使用Unix组进行授权。例如,Jenkins可以配置为“ developers群组中的所有人都具有管理员访问权限”。为了支持此功能,Jenkins依赖于 PAM ,可能需要在Jenkins环境外配置。
插件可以提供额外的安全领域,这对于将Jenkins纳入现有身份系统可能是有用的,例如:
授权
安全领域或认证表明谁可以访问Jenkins环境。另一个谜题是授权,这表明他们可以在Jenkins环境中访问什么。默认情况下,Jenkins支持几个不同的授权选项:
所有人都可以控制Jenkins
每个人都可以完全控制Jenkins,包括尚未登录的匿名用户。请勿将本设置用于本地测试Jenkins管理以外的任何其他设置。
传统模式
与Jenkins<1.164完全一样。也就是说,如果用户具有“admin”角色,他们将被授予对系统的完全控制权,否则(包括匿名用户)将仅具有读访问权限。不要将本设置用于本地测试Jenkins
管理以外的任何设置。
登录用户可以做任何事情
在这种模式下,每个登录的用户都可以完全控制Jenkins。根据高级选项,匿名用户可以读取Jenkins的访问权限,也可以不访问。此模式有助于强制用户在执行操作之前登录,以便有用户操作的审计跟踪。
基于矩阵的安全性
该授权方案可以精确控制哪些用户和组能够在Jenkins环境中执行哪些操作(请参见下面的屏幕截图)。
基于项目的矩阵授权策略
此授权方案是基于Matrix的安全性的扩展,允许在项目配置屏幕中单独为每个项目定义附加的访问控制列表(ACL)。这允许授予特定用户或组访问指定的项目,而不是Jenkins环境中的所有项目。使用基于项目的矩阵授权定义的ACL是加法的,使得在“配置全局安全性”屏幕中定义的访问权限将与项目特定的ACL组合。
基于矩阵的安全性和基于项目的矩阵授权策略由Matrix授权策略插件提供,可能不会安装在您的Jenkins上。对于大多数Jenkins环境,基于Matrix的安全性提供最大的安全性和灵活性,因此建议将其作为“生产”环境的起点。
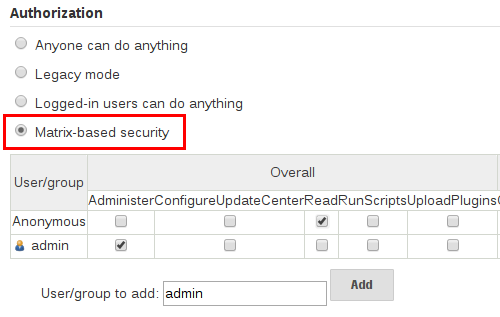
图1.基于矩阵的安全性
上面显示的表可以变得相当宽泛,因为每一列都表示由Jenkins核心或插件提供的权限。将鼠标悬停在权限上将显示有关权限的更多信息。
表中的每一行表示用户或组(也称为“角色”)。这包括名为“匿名”和“认证”的特殊条目。“匿名”条目表示授予访问Jenkins环境的所有未认证用户的权限。而“已认证”可用于向访问环境的所有经过身份验证的用户授予权限。
矩阵中授予的权限是加法的。例如,如果用户“kohsuke”在“开发人员”和“管理员”组中,则授予“kohsuke”的权限将是授予“kohsuke”,“开发人员”,“管理员” ,“认证”和“匿名”。
标记格式器
Jenkins允许用户输入许多不同的配置字段和文本区域,这可能会导致用户无意或恶意地插入不安全的HTML和/或JavaScript。
默认情况下,“ 标记格式化程序”配置设置为“ 纯文本”,将会转义不安全的字符,例如<和&其各自的字符实体。
使用安全的HTML标记格式化程序允许用户和管理员将有用的和信息的HTML片段注入到项目描述和其他地方。
跨站点请求伪造
跨站点请求伪造(或CSRF / XSRF)是一种漏洞,它允许未经授权的第三方通过模仿另一个经过身份验证的用户对Web应用程序执行请求。在Jenkins环境的上下文中,CSRF攻击可能允许恶意actor删除项目,更改构建或修改Jenkins的系统配置。为了防范此类漏洞,默认情况下,CSRF保护已启用,所有Jenkins版本自2.0以来。

启用该选项后,Jenkins将会在可能更改Jenkins环境中的数据的任何请求上检查CSRF令牌或“crumb”。这包括任何表单提交和对远程API的调用,包括使用“基本”身份验证的表单。
这是强烈建议这个选项不要被启用,包括私人,完全可信的网络运行情况。
注意事项
CSRF保护可能会对 Jenkins更高级的使用带来挑战,例如:
- 某些Jenkins功能(如远程API)在启用此选项时更难使用。
- 通过配置不正确的反向代理访问Jenkins可能会导致CSRF HTTP头被从请求中删除,导致受保护的操作失败。
- 未经使用CSRF保护测试的过时插件可能无法正常工作。
有关CSRF漏洞的更多信息,请参见 OWASP网站。
代理/主访问控制
在概念上,Jenkins的管理员和代理人可以被认为是一个凝聚力的系统,恰好在多个离散的过程和机器上执行。这允许代理向主进程请求可用的信息,例如文件的内容等。
对于Jenkins管理员可能启用由其他团队或组织提供的代理的较大或成熟的Jenkins环境,平面代理/主信任模型不足。
引入了代理/主访问控制系统,允许Jenkins管理员在Jenkins主服务器和连接的代理程序之间添加更精细的访问控制定义。

从Jenkins 2.0开始,该子系统默认启用。
自定义访问
对于可能希望允许从代理到Jenkins主机的某些访问模式的高级用户,Jenkins允许管理员从内置访问控制规则创建特定的豁免。

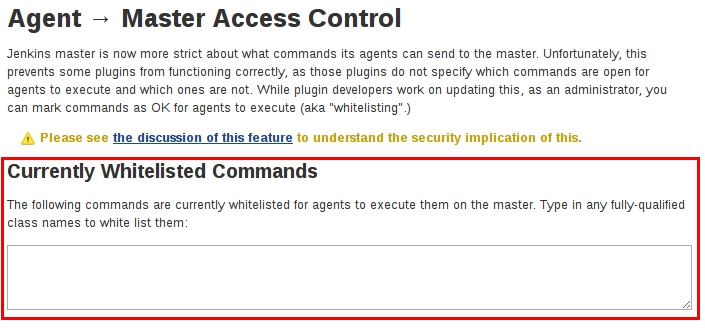
通过遵循上面突出显示的链接,管理员可以编辑命令和文件访问代理/主访问控制规则。
命令
Jenkins及其插件中的“命令”通过其完全限定的类名来标识。大多数这些命令旨在通过主机的请求在代理上执行,但是其中一些命令旨在通过代理的请求在主机上执行。
尚未更新的此子系统的插件可能不会对每个命令所属的类别进行分类,以便当代理请求主机执行不明确允许的命令时,Jenkins将错误地注意并拒绝执行该命令。
在这种情况下,Jenkins管理员可能会将某些命令列入白名单 ,以便在主服务器上执行。
高级
管理员也可以通过.conf 在目录中创建具有扩展名的文件来对类进行白名单JENKINS_HOME/secrets/whitelisted-callables.d/。这些.conf文件的内容应该在单独的行上列出命令名称。
该目录中的所有.conf文件的内容将被Jenkins读取并合并,default.conf在目录中创建一个列出所有已知安全命令的文件。该default.conf文件将每次Jenkins启动时重新编写。
Jenkins还管理一个文件gui.conf,在whitelisted-callables.d 目录中,通过Web UI添加的命令被写入。为了禁用管理员从Web UI更改列入白名单的命令的能力,请gui.conf在目录中放置一个空文件,并更改其权限,以便操作系统用户Jenkins运行时不能写入。
文件访问规则
文件访问规则用于验证从代理向主设备提交的文件访问请求。每个文件访问规则是一个三元组,它必须包含以下每个元素:
- allow/ deny:如果以下两个参数与正在考虑的当前请求匹配,则allow条目将允许执行请求,并且deny条目将拒绝该请求被拒绝,而不管稍后的规则如何。
- 操作:请求的操作的类型。存在以下6个值。操作也可以通过逗号分隔值组合。all表示所有列出的操作的值被允许或拒绝。
- read:读取文件内容或列出目录条目
- write:写文件内容
- mkdirs:创建一个新的目录
- create:在现有目录中创建一个文件
- delete:删除文件或目录
- stat:读取文件/目录的元数据,例如时间戳,长度,文件访问模式。
3.文件路径:指定与此规则匹配的文件路径的正则表达式。除了基本的正则表达式语法之外,它还支持以下令牌:
- <JENKINS_HOME>可以用作前缀来匹配主 JENKINS_HOME目录。
- <BUILDDIR>可以用作前缀来匹配构建记录目录,比如/var/lib/jenkins/job/foo/builds/2014-10-17_12-34-56。
- <BUILDID>匹配时间戳格式的构建ID,如 2014-10-17_12-34-56。
这些规则是按照顺序排列的,并被应用于规则上。例如,以下规则允许访问JENKINS_HOME 除secrets文件夹之外的所有文件:
# To avoid hassle of escaping every '\' on Windows, you can use / even on Windows.
deny all <JENKINS_HOME>/secrets/.*
allow all <JENKINS_HOME>/.*规则非常重要!以下规则被错误地写入,因为第二条规则永远不会匹配,并允许所有代理访问下列所有文件和文件夹JENKINS_HOME:
allow all <JENKINS_HOME>/.*
deny all <JENKINS_HOME>/secrets/.*高级
管理员还可以通过.conf.在目录中创建扩展名的文件来添加文件访问规则 JENKINS_HOME/secrets/filepath-filters.d/。Jenkins本身30-default.conf在此目录中的引导时生成文件,其中包含默认值,被认为是Jenkins项目的兼容性和安全性之间的最佳平衡。为了禁用这些内置的默认值,请替换30-default.conf为操作系统用户Jenkins不能写入的空文件。
在每次启动时,Jenkins将以 字母顺序读取目录中的所有.conf文件filepath-filters.d,因此,以表示其加载顺序的方式命名文件是一种好习惯。
Jenkins还管理50-gui.conf,在filepath-filters/目录中,其中通过网络用户界面添加文件访问规则写入。为了禁止管理员从Web UI更改文件访问规则的能力,请将空50-gui.conf文件放在目录中,并更改其权限,以便操作系统用户Jenkins运行时不能写入。
禁用
虽然不推荐使用,但如果Jenkins环境中的所有代理程序都可以被认为与主机信任的程度相当“受信任”,则可能会禁用代理/主访问控制功能。
此外,Jenkins环境中的所有用户都应具有对所有已配置项目的访问级别。
管理员可以通过取消选中“ 配置全局安全性”页面上的框来禁用Web UI中的代理/主访问控制。或者,管理员可以使用内容JENKINS_HOME/secrets命名 并重新启动Jenkins 来创建一个文件。slave-to-master-security-kill-switchtrue
大多数Jenkins环境随着时间的推移需要他们的信任模型随着环境的增长而发展。请考虑安排定期的“检查”以查看是否应重新启用所有已禁用的安全设置。Jenkins 管理工具
Jenkins 管理插件
管理插件
插件是增强Jenkins环境功能以满足组织或用户特定需求的主要手段。有超过一千种不同的插件 ,可以安装在Jenkins主机上,并集成各种构建工具,云提供商,分析工具等等。
可以从更新中心自动下载插件及其依赖关系 。更新中心是由Jenkins项目运营的一项服务,该项目提供了由Jenkins社区的各种成员开发和维护的开源插件的清单。
本节将介绍从Jenkins Web UI中管理插件的基础知识到主文件系统的更改。
安装插件
Jenkins提供了几种不同的方法来在主机上安装插件:
- 在Web UI中使用“插件管理器”。
- 使用Jenkins CLI install-plugin命令。
每种方法将导致插件由Jenkins加载,但可能需要不同级别的访问权限和权衡才能使用。
这两种方法要求Jenkins管理员能够从更新中心下载元数据,无论是由Jenkins项目运行的主更新中心 ,还是自定义更新中心。
插件被打包为自包含的.hpi文件,它们具有插件需要成功运行的所有必需的代码,图像和其他资源。
来自Web UI
安装插件的最简单和最常见的方法是通过 管理Jenkins > 管理插件视图,可供Jenkins环境的管理员使用。
在“ 可用”选项卡下,可以搜索并考虑可从配置的“更新中心”下载的插件:

大多数插件可以通过检查插件旁边的框立即安装和使用,然后单击安装而不重新启动。
如果可用插件列表为空,则主机可能配置不正确或尚未从更新中心下载插件元数据。单击立即检查按钮将强制Jenkins尝试联系其配置的更新中心。使用Jenkins CLI
管理员也可以使用Jenkins CLI来提供安装插件的命令。管理Jenkins环境的脚本或配置管理代码可能需要在Web UI中安装插件,而无需直接的用户交互。Jenkins CLI允许命令行用户或自动化工具下载插件及其依赖项。
java -jar jenkins-cli.jar -s http://localhost:8080/ install-plugin SOURCE ... [-deploy] [-name VAL] [-restart]
Installs a plugin either from a file, an URL, or from update center.
SOURCE : If this points to a local file, that file will be installed. If
this is an URL, Jenkins downloads the URL and installs that as a
plugin.Otherwise the name is assumed to be the short name of the
plugin in the existing update center (like "findbugs"),and the
plugin will be installed from the update center.
-deploy : Deploy plugins right away without postponing them until the reboot.
-name VAL : If specified, the plugin will be installed as this short name
(whereas normally the name is inferred from the source name
automatically).
-restart : Restart Jenkins upon successful installation.高级安装
更新中心仅允许安装最新发布的插件版本。在需要旧版本插件的情况下,Jenkins管理员可以下载较旧的.hpi存档,并手动将其安装在Jenkins主机上。
来自 Web UI
假设.hpi已下载文件,登录的Jenkins管理员可以从Web UI中上载该文件:
- 浏览到Web界面中的“ 管理Jenkins > 管理插件”页面。
- 单击高级选项卡。
- 选择“ 上传插件”部分.hpi下的文件。
- 上传插件文件。
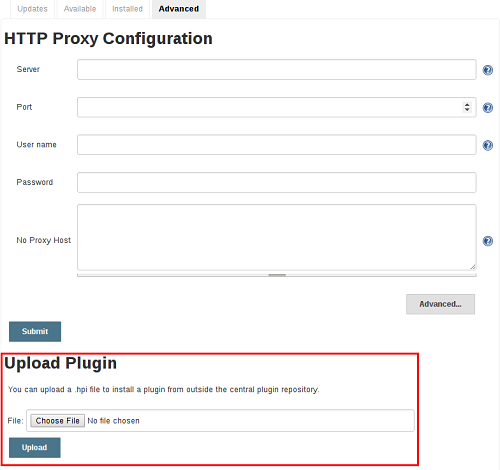
一旦插件文件被上传,必须手动重新启动Jenkins主机,从而更改生效。
在管理员上
假设.hpi系统管理员已经明确下载了一个文件,管理员可以手动将.hpi文件放在文件系统的特定位置。
将下载的.hpi`文件复制到JENKINS_HOME/pluginsJenkins主目录中(例如,Debian系统JENKINS_HOME一般 /var/lib/jenkins)。
在插件加载并在Jenkins环境中可用之前,主人将需要重新启动。
更新站点中的插件目录的名称并不总是与插件的显示名称相同。搜索 plugins.jenkins.io 以获取所需的插件将提供相应的.hpi文件链接。
更新插件
更新列在“ 管理插件”页面的“ 更新”选项卡中,可以通过选中所需插件更新的复选框并单击“ 立即下载并重新启动”按钮后进行安装。
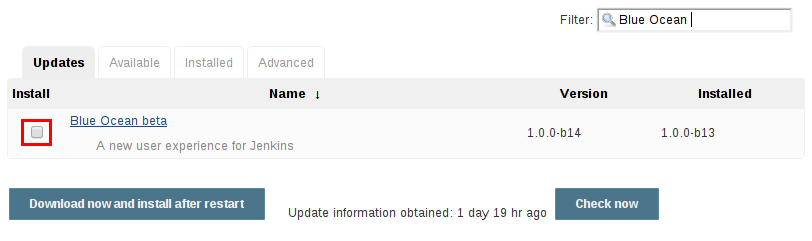
默认情况下,Jenkins管理将每24小时检查一次更新中心的更新。要手动触发检查更新,只需点击更新选项卡上的立即检查按钮。
删除一个插件
当插件不再在Jenkins环境中使用时,从Jenkins主机中删除插件是谨慎的。这提供了许多好处,例如在启动或运行时减少内存开销,减少Web UI中的配置选项,以及消除与新插件更新的未来冲突的潜力。
卸载插件
卸载插件的最简单的方法是导航到“ 管理插件”页面上的“ 已安装”选项卡。从那里,Jenkins将自动确定哪些插件安全卸载,那些不依赖于其他插件的插件,并提供一个这样做的按钮。
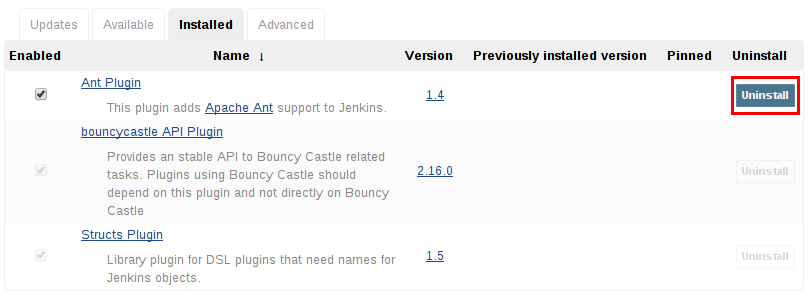
也可以通过.hpi从JENKINS_HOME/plugins主机上的目录中删除相应的文件来卸载插件。该插件将继续运行,直到主机重新启动。
如果某个插件.hpi文件已被删除但其他插件需要,则Jenkins主机可能无法正确启动。卸载插件并不会删除插件可能已经创建的配置。如果存在引用插件创建的数据的现有作业/节点/视图/构建/ etc配置,则Jenkins将在引导期间警告某些配置无法完全加载,并忽略无法识别的数据。
由于配置将被保留,直到它们被覆盖,重新安装插件将导致这些配置值重新出现。
删除旧数据
Jenkins提供了通过卸载的插件清除配置的设施。导航到管理Jenkins,然后单击管理旧数据以查看和删除旧数据。
禁用插件
禁用插件是退出插件的较软的方式。Jenkins将继续认识到该插件已安装,但它不会启动该插件,并且此插件不会提供任何扩展。
Jenkins管理员可以通过取消选中“ 管理插件”页面的“ 已安装”选项卡上的框(见下文)来禁用插件 。
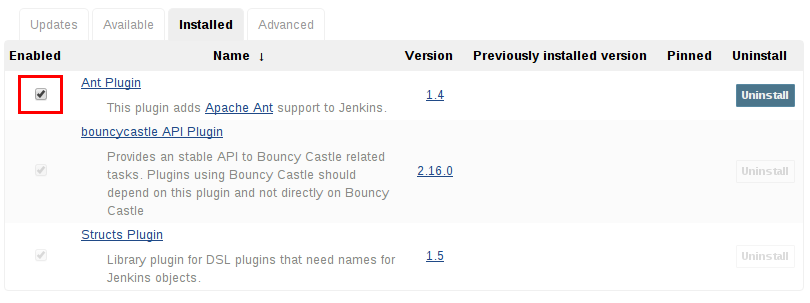
统管理员也可以通过在Jenkins主机上创建文件来禁用插件,例如:JENKINS_HOME/plugins/PLUGIN_NAME.hpi.disabled。
由禁用的插件创建的配置就像插件被卸载一样,只要它们在引导时引起警告,但是会被忽略。
固定插件
固定插件功能已在Jenkins 2.0中删除。版本晚于Jenkins 2.0不会捆绑插件,而是提供一个向导来安装最有用的插件。
固定插件的概念适用于与Jenkins 1.x捆绑的插件,例如 Matrix授权插件。
默认情况下,每当Jenkins升级时,其捆绑的插件将覆盖当前安装的插件版本JENKINS_HOME。
但是,当手动更新捆绑的插件时,Jenkins会将该插件标记为特定版本。在文件系统上,Jenkins创建一个空文件,JENKINS_HOME/plugins/PLUGIN_NAME.hpi.pinned 用于指示固定。
Jenkins启动期间,固定插件永远不会被捆绑插件覆盖。(较新版本的Jenkins会警告您,如果固定插件 比当前捆绑的旧版本更旧)。
将捆绑插件更新到Update Center提供的版本是安全的。这通常是获取最新功能和修复程序所必需的。捆绑版本偶尔更新,但不一致。
插件管理器允许明确地取消固定插件。该 JENKINS_HOME/plugins/PLUGIN_NAME.hpi.pinned文件也可以手动创建/删除以控制钉扎行为。如果该pinned文件存在,Jenkins将使用用户指定的任何插件版本。如果文件不存在,Jenkins将在启动时将插件恢复为默认版本。
Jenkins CLI
Jenkins有一个内置的命令行界面,允许用户和管理员从脚本或shell环境访问Jenkins。这对于日常任务的脚本编写,批量更新,故障排除等都是很方便的。
命令行界面可以通过SSH或Jenkins CLI客户端进行访问,这是Jenkins .jar发布的一个文件。
不建议使用与Jenkins 2.53及更早版本Jenkins 2.5.3及更早版本配合使用的CLI客户端,因为安全原因:虽然目前还存在未知的漏洞,但是有几个已经被报告和修补过,而Jenkins Remoting协议使用本身就容易受到远程代码执行错误的影响,甚至是“预认证”漏洞(由能够物理访问Jenkins网络的匿名用户)。
Jenkins 2.54和更新版本的Jenkins LTS 2.46.2和更新版本的客户端在其默认(-http)或-ssh模式下被认为是安全的,正如使用标准ssh命令一样通过SSH使用CLI
在新的Jenkins安装中,默认情况下禁用SSH服务。管理员可以选择设置特定端口,或者请求Jenkins在“ 配置全局安全性”页面中选择一个随机端口。为了确定随机分配的SSH端口,请检查Jenkins URL上返回的标头,例如:
% curl -Lv https://JENKINS_URL/login 2>&1 | grep 'X-SSH-Endpoint'
< X-SSH-Endpoint: localhost:53801
%使用随机SSH端口(53801在本示例中)和身份验证 配置,任何现代SSH客户端都可以安全地执行CLI命令。
认证
用于与Jenkins主机进行身份验证的用户必须具有访问 CLI 的 Overall/Read权限。根据执行的命令,用户可能需要额外的权限。
认证依赖于基于SSH的公钥/私钥认证。要为适当的用户添加SSH公钥,请导航 https://JENKINS_URL/user/USERNAME/configure并将SSH公钥粘贴到相应的文本区域中。
共同命令
Jenkins有许多内置的CLI命令,可以在每个Jenkins环境中找到,例如build或list-jobs。插件还可以提供CLI命令; 为了确定给定Jenkins环境中可用的命令的完整列表,请执行CLI help命令:
% ssh -l kohsuke -p 53801 localhost help以下命令列表并不全面,但它是Jenkins CLI使用的有用起点。
建立
CLI命令中最常用和最有用的命令之一是build允许用户触发他们有权限的任何作业或pipeline。
最基本的调用将简单地触发作业或pipeline并退出,但是使用附加选项,用户也可以传递参数,轮询SCM,甚至跟随触发构建或pipeline运行的控制台输出。
% ssh -l kohsuke -p 53801 localhost help build
java -jar jenkins-cli.jar build JOB [-c] [-f] [-p] [-r N] [-s] [-v] [-w]
Starts a build, and optionally waits for a completion. Aside from general
scripting use, this command can be used to invoke another job from within a
build of one job. With the -s option, this command changes the exit code based
on the outcome of the build (exit code 0 indicates a success) and interrupting
the command will interrupt the job. With the -f option, this command changes
the exit code based on the outcome of the build (exit code 0 indicates a
success) however, unlike -s, interrupting the command will not interrupt the
job (exit code 125 indicates the command was interrupted). With the -c option,
a build will only run if there has been an SCM change.
JOB : Name of the job to build
-c : Check for SCM changes before starting the build, and if there's no
change, exit without doing a build
-f : Follow the build progress. Like -s only interrupts are not passed
through to the build.
-p : Specify the build parameters in the key=value format.
-s : Wait until the completion/abortion of the command. Interrupts are passed
through to the build.
-v : Prints out the console output of the build. Use with -s
-w : Wait until the start of the command
% ssh -l kohsuke -p 53801 localhost build build-all-software -f -v
Started build-all-software #1
Started from command line by admin
Building in workspace /tmp/jenkins/workspace/build-all-software
[build-all-software] $ /bin/sh -xe /tmp/hudson1100603797526301795.sh
+ echo hello world
hello world
Finished: SUCCESS
Completed build-all-software #1 : SUCCESS
%console
同样有用的是console命令,它检索指定生成或pipeline运行的控制台输出。当没有提供编号时,该 console命令将输出最后完成的版本的控制台输出。
% ssh -l kohsuke -p 53801 localhost help console
java -jar jenkins-cli.jar console JOB [BUILD] [-f] [-n N]
Produces the console output of a specific build to stdout, as if you are doing 'cat build.log'
JOB : Name of the job
BUILD : Build number or permalink to point to the build. Defaults to the last
build
-f : If the build is in progress, stay around and append console output as
it comes, like 'tail -f'
-n N : Display the last N lines
% ssh -l kohsuke -p 53801 localhost console build-all-software
Started from command line by kohsuke
Building in workspace /tmp/jenkins/workspace/build-all-software
[build-all-software] $ /bin/sh -xe /tmp/hudson1100603797526301795.sh
+ echo hello world
yes
Finished: SUCCESS
%who-am-i
该who-am-i命令有助于列出用户可用的当前用户的凭据和权限。当调试缺少CLI命令时,由于缺少某些权限,这将非常有用。
% ssh -l kohsuke -p 53801 localhost help who-am-i
java -jar jenkins-cli.jar who-am-i
Reports your credential and permissions.
% ssh -l kohsuke -p 53801 localhost who-am-i
Authenticated as: kohsuke
Authorities:
authenticated
%使用CLI客户端
尽管基于SSH的CLI速度快,涵盖了大部分需求,但可能会出现与Jenkins分发的CLI客户端更适合的情况。例如,CLI客户端的默认传输是HTTP,这意味着在防火墙中不需要打开额外的端口供其使用。
下载客户端
该CLI客户端可以直接从Jenkins管理在URL下载 /jnlpJars/jenkins-cli.jar,在效果 https://JENKINS_URL/jnlpJars/jenkins-cli.jar
虽然CLI .jar可以针对不同版本的Jenkins使用,但如果在使用过程中出现任何兼容性问题,请.jar 从Jenkins管理重新下载最新的文件。
使用客户端
调用客户端的一般语法如下:
java -jar jenkins-cli.jar [-s JENKINS_URL] [global options...] command [command options...] [arguments...]客户端连接模式
有三种基本模式,其中可以使用本2.54+ / 2.46.2+客户端,通过全局选项可选择的: -http; -ssh; 和-remoting。
HTTP连接模式
这是2.54和2.46.2的默认模式,尽管-http为了清楚起见,您可以明确地传递选项。
认证最好有一个-auth选项,它需要一个username:apitoken参数。获取您的API令牌/me/configure:
java -jar jenkins-cli.jar [-s JENKINS_URL] -auth kohsuke:abc1234ffe4a command ...(也接受实际的密码,但不鼓励)。
您还可以在参数之前@从文件加载相同的内容:
java -jar jenkins-cli.jar [-s JENKINS_URL] -auth @/home/kohsuke/.jenkins-cli command ...通常,不需要特殊的系统配置来启用基于HTTP的CLI连接。如果您在HTTP(S)反向代理之后运行Jenkins,请确保它不缓冲请求或响应体。
SSH连接模式
验证是通过SSH密钥对。您还必须选择Jenkins用户ID:
java -jar jenkins-cli.jar [-s JENKINS_URL] -ssh -user kohsuke command ...在这种模式下,客户端的行为基本上就像一个本机ssh命令。
默认情况下,客户端将尝试连接到同一主机上的SSH端口JENKINS_URL。如果Jenkins位于HTTP反向代理之后,这通常不起作用,因此运行Jenkins与系统属性-Dorg.jenkinsci.main.modules.sshd.SSHD.hostName=ACTUALHOST 来定义SSH端点的主机名或IP地址。
远程连接模式
这是从2.54 / pre-2.46.2之前的Jenkins服务器(在引入该-remoting选项之前)下载的客户端支持的唯一模式。由于安全性和性能原因,它的使用已被弃用。也就是说,某些命令或命令模式只能在Remoting模式下运行,这通常是因为命令功能涉及在客户机上运行服务器提供的代码。
在2.54+和2.46.2的新安装中,服务器端禁用此模式。如果您必须使用它并接受风险,则可能会在配置全局安全性中启用。
验证最好通过SSH密钥对。一个login命令和--username/ --password命令(注意:不是全球性)选项也可用; 这些是不鼓励的,因为它们无法使用基于非密码的安全领域,如果匿名用户缺少整体或作业读取访问权限,某些命令参数将无法正确解析,并且将保存用于脚本的人为选择的密码视为不安全。
请注意,有两种可用于此模式的传输:通过HTTP或专用TCP套接字。如果TCP端口启用并且可以工作,客户端将使用此传输。如果TCP端口被禁用,或者这样的端口被通告但不接受连接(例如因为您使用带有防火墙的HTTP反向代理),客户端将自动回退到效率较低的HTTP传输。
基于远程客户端的常见问题
运行CLI客户端时可能会遇到一些常见的问题。
操作超时
如果您在服务器上使用防火墙,请检查是否打开HTTP端口或TCP端口。您可以在Jenkins配置中配置其值。默认设置为使用随机端口。
% java -jar jenkins-cli.jar -s JENKINS_URL help
Exception in thread "main" java.net.ConnectException: Operation timed out
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.PlainSocketImpl.doConnect(PlainSocketImpl.java:351)
at java.net.PlainSocketImpl.connectToAddress(PlainSocketImpl.java:213)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:200)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:432)
at java.net.Socket.connect(Socket.java:529)
at java.net.Socket.connect(Socket.java:478)
at java.net.Socket.<init>(Socket.java:375)
at java.net.Socket.<init>(Socket.java:189)
at hudson.cli.CLI.<init>(CLI.java:97)
at hudson.cli.CLI.<init>(CLI.java:82)
at hudson.cli.CLI._main(CLI.java:250)
at hudson.cli.CLI.main(CLI.java:199)没有X-Jenkins-CLI2端口
转到管理Jenkins > 配置全局安全性,并在JNLP代理的TCP端口下选择“固定”或“随机” 。
java.io.IOException: No X-Jenkins-CLI2-Port among [X-Jenkins, null, Server, X-Content-Type-Options, Connection,
X-You-Are-In-Group, X-Hudson, X-Permission-Implied-By, Date, X-Jenkins-Session, X-You-Are-Authenticated-As,
X-Required-Permission, Set-Cookie, Expires, Content-Length, Content-Type]
at hudson.cli.CLI.getCliTcpPort(CLI.java:284)
at hudson.cli.CLI.<init>(CLI.java:128)
at hudson.cli.CLIConnectionFactory.connect(CLIConnectionFactory.java:72)
at hudson.cli.CLI._main(CLI.java:473)
at hudson.cli.CLI.main(CLI.java:384)
Suppressed: java.io.IOException: Server returned HTTP response code: 403 for URL: http://citest.gce.px/cli
at sun.net.www.protocol.http.HttpURLConnection.getInputStream0(HttpURLConnection.java:1840)
at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1441)
at hudson.cli.FullDuplexHttpStream.<init>(FullDuplexHttpStream.java:78)
at hudson.cli.CLI.connectViaHttp(CLI.java:152)
at hudson.cli.CLI.<init>(CLI.java:132)
... 3 moreJenkins 进程内脚本批准
Jenkins和许多插件允许用户在Jenkins中执行Groovy脚本。这些脚本功能由以下提供:
为了保护Jenkins不会执行恶意脚本,这些插件在Groovy Sandbox中执行用户提供的脚本,可以限制可访问的内部API。然后,管理员可以使用脚本安全性插件提供的“进程内脚本批准”页面来管理在Jenkins环境中应该允许哪些不安全的方法(如果有的话)。
开始
该脚本安全插件被自动安装后安装设置向导,虽然最初没有额外的脚本或操作批准使用。
这个插件的旧版本可能不安全使用。请查看脚本安全性插件页面 中列出的安全警告,以确保脚本安全性插件是最新的。进程内脚本的安全性由两种不同的机制提供: Groovy Sandbox
Groovy Sandbox
和 Script Approval。第一个Groovy Sandbox默认启用Jenkins Pipeline,允许用户提供的Scripted和Declarative Pipeline执行,而无需事先管理员干预。第二个“脚本批准”允许管理员批准或拒绝未分组的脚本,或允许Sandbox脚本执行其他方法。
在大多数情况下,Groovy Sandbox和 Script Security内建的已批准方法签名列表的组合将足够。强烈建议,如果绝对必要,管理员只会偏离这些默认值。
Groovy Sandbox
为了减少管理员的手动干预,默认情况下,大多数脚本将在Groovy Sandbox中运行,包括所有 Jenkins Pipeline。Sandbox只允许Groovy的一些方法被认为足够安全,以便在未经事先批准的情况下执行“不受信任”访问。使用Groovy Sandbox的脚本都受到相同的限制,因此由管理员编写的Pipeline将受到非管理用户授权的限制。
当脚本尝试使用Sandbox未经授权的功能或方法时,脚本将立即停止,如下所示,Jenkins Pipeline
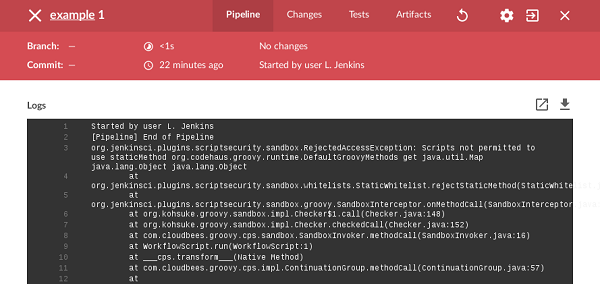
图1.未经授权的方法签名在运行时通过Blue Ocean被拒绝
在管理员通过“ 进程内脚本批准”页面批准方法签名之前,上述Pipeline将不会执行 。
除了添加批准的方法签名,用户还可以完全禁用Groovy Sandbox,如下所示。禁用Groovy Sandbox要求整个脚本必须经过管理员审核并手动批准。
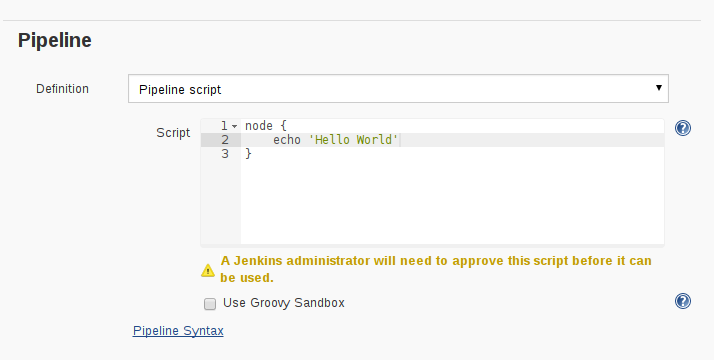
图2.禁用Pipeline的Groovy Sandbox
脚本批准
由管理员手动批准整个脚本或方法签名,为管理员提供了额外的灵活性,以支持更高级的进程内脚本编写。当Groovy Sandbox被禁用或者调用了内置列表以外的方法时,Script Security插件将检查经过管理员管理的已批准脚本和方法列表。
对于希望在Groovy Sandbox之外执行的脚本,管理员必须在“ 进程内脚本批准”页面中批准整个脚本:
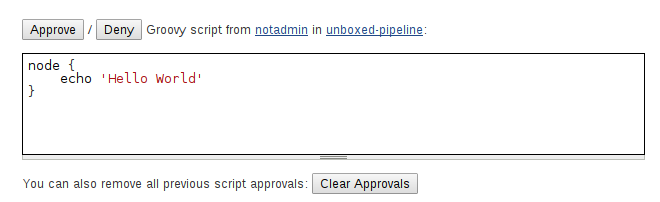
图3.批准一个unsandboxed Script Pipeline
对于使用Groovy Sandbox但是希望执行当前未经批准的方法签名的脚本也将被Jenkins停止,并且要求管理员在脚本被允许执行之前批准特定的方法签名:
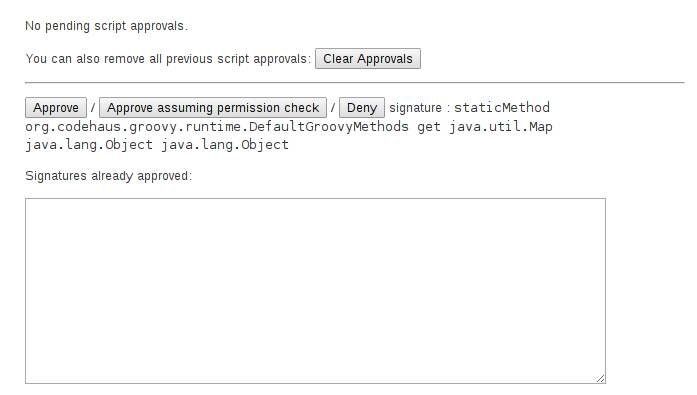
图4.批准新的方法签名
批准假设权限检查
脚本批准提供三个选项:批准,拒绝和“批准假设权限检查”。虽然前两者的目的是不言而喻的,但第三个要求需要对内部数据脚本能够访问的内容以及Jenkins函数中的权限如何进行一些额外的了解。
考虑访问该方法的脚本,该脚本 hudson.model.AbstractItem.getParent()本身是无害的,并返回一个包含当前正在执行的流水线或作业的文件夹或根目录的对象。在该方法调用,执行hudson.model.ItemGroup.getItems()(将列出文件夹或根项目中的项目)之后,需要该Job/Read权限。
这可能意味着批准hudson.model.ItemGroup.getItems()方法签名将允许脚本绕过内置权限检查。
相反,通常更需要单击“ 批准”假设权限检查,这将导致脚本批准引擎允许方法签名,假设运行该脚本的用户具有执行该方法的Job/Read权限,例如此示例中的权限。
Pipeline 介绍
本章将介绍Jenkins Pipeline的所有方面,从运行Pipeline到写入Pipeline代码,甚至扩展Pipeline本身。
本章旨在让所有技能级别的Jenkins用户使用,但初学者可能需要参考“ 使用Jenkins ”的一些部分来了解本章涵盖的一些主题。
如果您还不熟悉Jenkins的基本术语和功能,请参考 Jenkins介绍。
什么是Pipeline?
Jenkins Pipeline是一套插件,支持将连续输送Pipeline实施和整合到Jenkins。Pipeline提供了一组可扩展的工具,用于通过PipelineDSL为代码创建简单到复杂的传送Pipeline。
通常,此“Pipeline代码”将被写入 Jenkinsfile项目的源代码控制存储库,例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any  stages {
stage('Build') {
stages {
stage('Build') {  steps {
steps {  sh 'make'
sh 'make'  }
}
stage('Test'){
steps {
sh 'make check'
junit 'reports/**/*.xml'
}
}
stage('Test'){
steps {
sh 'make check'
junit 'reports/**/*.xml'  }
}
stage('Deploy') {
steps {
sh 'make publish'
}
}
}
}
}
}
stage('Deploy') {
steps {
sh 'make publish'
}
}
}
}
agent 表示Jenkins应该为Pipeline的这一部分分配一个执行者和工作区。

stage 描述了这条Pipeline的一个阶段。

steps 描述了要在其中运行的步骤 stage

sh 执行给定的shell命令

junit是由JUnit插件提供的 用于聚合测试报告的Pipeline步骤。
为什么是Pipeline?
Jenkins从根本上讲是一种支持多种自动化模式的自动化引擎。Pipeline在Jenkins上添加了一套强大的自动化工具,支持从简单的连续集成到全面的连续输送Pipeline的用例。通过建模一系列相关任务,用户可以利用Pipeline 的许多功能:
- 代码:Pipeline以代码的形式实现,通常被检入源代码控制,使团队能够编辑,审查和迭代其传送流程。
- 耐用:Pipeline可以在计划和计划外重新启动Jenkins管理时同时存在。
- Pausable:Pipeline可以选择停止并等待人工输入或批准,然后再继续Pipeline运行。
- 多功能:Pipeline支持复杂的现实世界连续交付要求,包括并行分叉/连接,循环和执行工作的能力。
- 可扩展:Pipeline插件支持其DSL的自定义扩展 以及与其他插件集成的多个选项。
虽然Jenkins一直允许基本形式的自由式工作联合起来执行顺序任务,Pipeline使这个概念成为Jenkins的最好的一个部分。
基于Jenkins的核心可扩展性,Pipeline也可以由Pipeline共享库用户和插件开发人员扩展。
下面的流程图是在Jenkins Pipeline中容易建模的一个连续发货方案的示例:
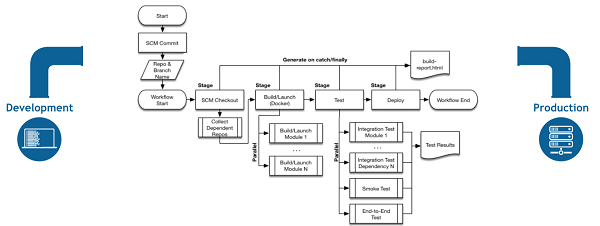
图1.Pipeline流量
Pipeline 条件
Step
单一任务,从基础中告诉了Jenkins应该怎么做。例如,要执行shell命令,请make使用以下sh步骤:sh 'make'。当插件扩展Pipeline DSL时,通常意味着插件已经实现了一个新的步骤。
Node
Pipeline执行中的大部分工作都是在一个或多个声明node步骤的上下文中完成的。将工作限制在Node步骤中有两件事情:
- 通过将项目添加到Jenkins队列来调度要运行的块中包含的步骤。一旦执行器在节点上空闲,步骤就会运行。
- 创建工作区(特定于该特定Pipeline的目录),可以从源代码控制中检出的文件完成工作。
根据您的Jenkins配置,某些工作空间在一段时间不活动后可能无法自动清除。Stage
stage是定义整个Pipeline的概念上不同子集的一个步骤,例如:“Build”,“Test”和“Deploy”,许多插件用于可视化或呈现Jenkins Pipeline状态/进度。
Pipeline 入门
Jenkins Pipeline是一套插件,支持将连续输送Pipeline实施和整合到Jenkins。Pipeline 提供了一组可扩展的工具,用于通过Pipeline DSL为代码创建简单到复杂的传送Pipeline 。
本节介绍Jenkins Pipeline的一些关键概念,并帮助介绍在运行的Jenkins实例中定义和使用Pipelines的基础知识。
先决条件
要使用Jenkins Pipeline,您将需要:
- Jenkins 2.x或更高版本(旧版本回到1.642.3可能会工作,但不推荐)
- Pipeline插件
要了解如何安装和Pipeline插件,请参阅管理插件。
Pipeline 定义
脚本Pipeline是用Groovy写的 。Groovy语法的相关位将在本文档中根据需要进行介绍,因此,当了解Groovy时,不需要使用Pipeline。
可以通过以下任一方式创建基本Pipeline:
- 直接在Jenkins网页界面中输入脚本。
- 通过创建一个Jenkinsfile可以检入项目的源代码管理库。
用任一方法定义Pipeline的语法是一样的,但是Jenkins支持直接进入Web UI的Pipeline,通常认为最佳实践是在Jenkinsfile Jenkins中直接从源代码控制中加载Pipeline。
在Web UI中定义Pipeline
要在Jenkins Web UI中创建基本Pipeline,请按照下列步骤操作:
- 单击Jenkins主页上的New Item。
- 输入Pipeline的名称,选择Pipeline,然后单击确定。
Jenkins使用流水线的名称在磁盘上创建目录。包含空格的管道名称可能会发现不希望路径包含空格的脚本中的错误。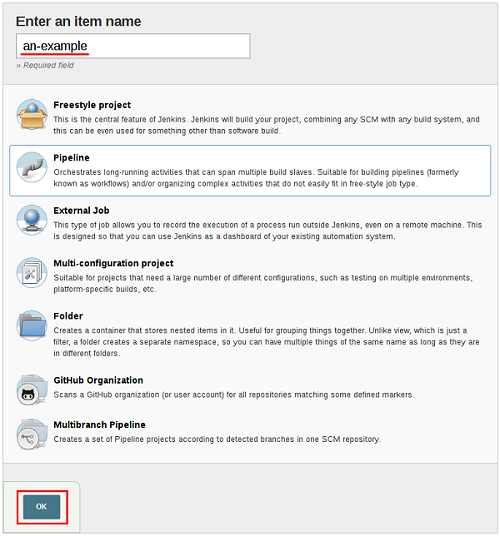
- 在脚本文本区域中,输入Pipeline,然后单击保存。
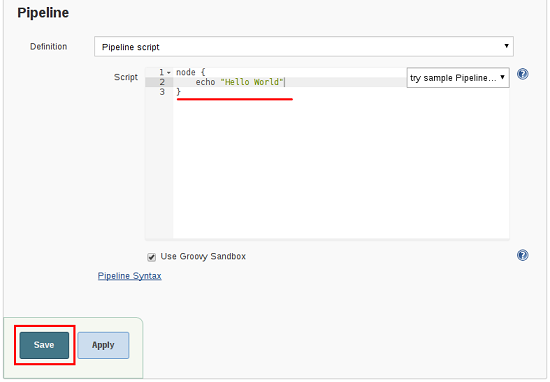
- 单击立即生成以运行Pipeline。

单击“构建历史记录”下的#1,然后单击控制台输出以查看Pipeline的完整输出。

上面的示例显示了在Jenkins Web UI中创建的基本Pipeline的成功运行,使用两个步骤。
Jenkinsfile (Scripted Pipeline)
node {  echo 'Hello World'
echo 'Hello World'  }
} :
:node 在Jenkins环境中分配一个执行器和工作空间。
 :
:echo 在控制台输出中写入简单的字符串
在SCM中定义管道
复杂的Pipeline难以在Pipeline配置页面的文本区域内进行写入和维护。为了使这更容易,Pipeline也可以写在文本编辑器中,并检查源控件,作为Jenkinsfile,Jenkins可以通过Pipeline脚本从SCM选项加载的控件。
为此,在定义Pipeline时,从SCM中选择Pipeline脚本。
选择SCM选项中的Pipeline脚本后,不要在Jenkins UI中输入任何Groovy代码; 您只需指定要从其中检索Pipeline的源代码中的路径。更新指定的存储库时,只要Pipeline配置了SCM轮询触发器,就会触发一个新构建。
文本编辑器,IDE,GitHub等将使用Groovy代码进行语法高亮显示, 第一行Jenkinsfile应该是#!/usr/bin/env groovy Jenkinsfile。内置文档
Pipeline配有内置的文档功能,可以更轻松地创建不同复杂性的Pipeline。根据Jenkins实例中安装的插件自动生成和更新内置文档。
内置文档可以在全局范围内找到: localhost:8080 / pipeline-syntax /,假设您有一个Jenkins实例在本地端口8080上运行。同样的文档也作为管道语法链接到任何配置的Pipeline的侧栏中项目。
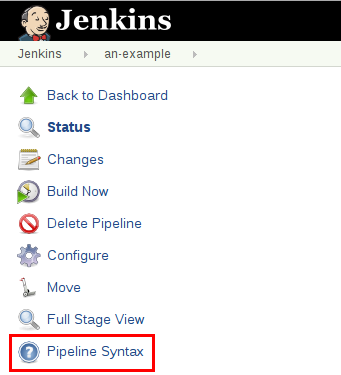
代码段生成器
内置的“Snippet Generator”实用程序有助于为单个步骤创建一些代码,发现插件提供的新步骤,或为特定步骤尝试不同的参数。
Snippet Generator动态填充Jenkins实例可用的步骤列表。可用的步骤数量取决于安装的插件,它明确地暴露了在Pipeline中使用的步骤。
要使用代码段生成器生成步骤代码片段:
- 从配置的流水线或本地主机:8080 / pipeline-syntax导航到Pipeline语法链接(上面引用)。
- 在“ 样品步骤”下拉菜单中选择所需的步骤
- 使用“ 样品步骤”下拉列表下方的动态填充区域配置所选步骤。
- 单击生成Pipeline脚本以创建一个可以复制并粘贴到Pipeline中的Pipeline代码段。
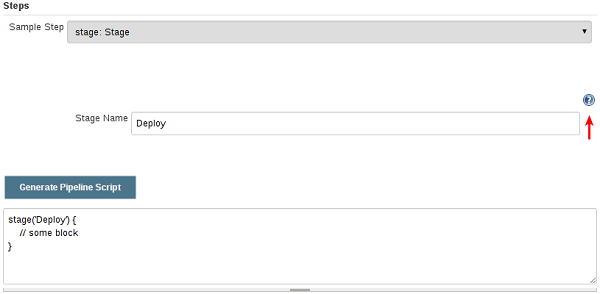
要访问有关所选步骤的其他信息和/或文档,请单击帮助图标(由上图中的红色箭头指示)。
全局变量引用
除了代码片段生成器之外,Pipeline还提供了一个内置的“ 全局变量引用”。像Snippet Generator一样,它也是由插件动态填充的。与代码段生成器不同的是,全局变量引用仅包含Pipeline提供的变量的文档,这些变量可用于Pipeline。
在Pipeline中默认提供的变量是:
- ENV
-
脚本化Pipeline可访问的环境变量,例如:
env.PATH或env.BUILD_ID。请参阅内置的全局变量参考 ,以获取管道中可用的完整和最新的环境变量列表。 - PARAMS
-
将为Pipeline定义的所有参数公开为只读 地图,例如:
params.MY_PARAM_NAME。 - currentBuild
-
可用于发现有关当前正在执行的Pipeline信息,与如属性
currentBuild.result,currentBuild.displayName等等请教内置的全局变量引用 了一个完整的,而且是最新的,可用的属性列表currentBuild。
进一步阅读
本节只是划伤了Jenkins Pipeline可以做的工作,但应该为您提供足够的基础,开始尝试使用测试Jenkins实例。
在下一节中,Jenkinsfile将会更多的管道步骤与实现成功的,真实的Jenkins Pipeline的模式一起讨论。
其他资源
- Pipeline步骤参考,包含分布在Jenkins更新中心的插件提供的所有步骤。
- Pipeline示例,一个社区策划的可复制Pipeline示例的集合。
Jenkinsfile使用
本节基于“ Jenkins入门”中介绍的信息,并介绍更有用的步骤,常见模式,并演示一些非平凡的Jenkinsfile示例。
创建一个Jenkinsfile被检入源代码控制,提供了一些直接的好处:
- Pipeline上的代码审查/迭代
- Pipeline的审计跟踪
- Pipeline的唯一真实来源,可以由项目的多个成员查看和编辑。
Pipeline支持两种语法:Declarative(在Pipeline 2.5中引入)和Scripted Pipeline。两者都支持建立连续输送Pipeline。两者都可以用于在Web UI或者a中定义一个流水线Jenkinsfile,尽管通常被认为是Jenkinsfile将文件创建并检查到源代码控制库中的最佳做法。
创建Jenkins文件
如“ 入门” 部分所述,a Jenkinsfile是一个包含Jenkins Pipeline定义的文本文件,并被检入源代码控制。考虑以下Pipeline,实施基本的三阶段连续输送Pipeline。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building..'
}
}
stage('Test') {
steps {
echo 'Testing..'
}
}
stage('Deploy') {
steps {
echo 'Deploying....'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
stage('Build') {
echo 'Building....'
}
stage('Test') {
echo 'Building....'
}
stage('Deploy') {
echo 'Deploying....'
}
}并非所有的Pipeline都将具有相同的三个阶段,但是对于大多数项目来说,这是一个很好的起点。以下部分将演示在Jenkins的测试安装中创建和执行简单的Jenkins。
假设已经有一个项目的源代码管理库,并且已经在Jenkins中按照这些说明定义了一个Jenkins 。
使用文本编辑器,理想的是支持Groovy语法突出显示的文本编辑器, Jenkinsfile在项目的根目录中创建一个新的。
上述声明性Pipeline示例包含实现连续传送Pipeline的最小必要结构。需要的代理指令指示Jenkins为Pipeline分配一个执行器和工作区。没有agent指令,不仅声明Pipeline无效,所以不能做任何工作!默认情况下,该agent伪指令确保源存储库已被检出并可用于后续阶段的步骤
该阶段的指令,和步骤的指令也需要一个有效的声明Pipeline,因为他们指示Jenkins如何执行并在哪个阶段应该执行。
要使用Scripted Pipeline进行更高级的使用,上面的示例node是为Pipeline分配执行程序和工作空间的关键第一步。在本质上,没有node Pipeline不能做任何工作!从内部node,业务的第一个顺序是检查此项目的源代码。由于Jenkinsfile直接从源代码控制中抽取,所以Pipeline提供了一种快速简便的方式来访问源代码的正确版本Jenkinsfile (Scripted Pipeline)
node {
checkout scm  /* .. snip .. */
}
/* .. snip .. */
} :该
:该checkout步骤将检出从源控制代码; scm是一个特殊变量,指示checkout步骤克隆触发此Pipeline运行的特定修订。
建立
对于许多项目,Pipeline“工作”的开始就是“建设”阶段。通常,Pipeline的这个阶段将是源代码组装,编译或打包的地方。的Jenkinsfile是不为现有的构建工具,如GNU/Make,Maven, Gradle,等的替代品,而是可以被看作是一个胶层结合项目的开发生命周期的多个阶段(建设,测试,部署等)一起。
Jenkins有一些插件,用于调用几乎任何一般使用的构建工具,但是这个例子将只是make从shell步骤(sh)调用。该sh步骤假定系统是基于Unix / Linux的,因为bat可以使用基于Windows的系统。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'make'  archiveArtifacts artifacts: '**/target/*.jar', fingerprint: true
archiveArtifacts artifacts: '**/target/*.jar', fingerprint: true  }
}
}
}
}
}
}
} :该
:该sh步骤调用该make命令,只有在命令返回零退出代码时才会继续。任何非零退出代码将失败Pipeline。
 :
:archiveArtifacts捕获与include pattern(**/target/*.jar)匹配的文件,并将它们保存到Jenkins主文件以供以后检索。
存档工件不能替代使用诸如Artifactory或Nexus之类的外部工件存储库,只能用于基本报告和文件归档。测试
运行自动化测试是任何成功的连续传送过程的重要组成部分。因此,Jenkins有许多插件提供的测试记录,报告和可视化设备 。在基本层面上,当有测试失败时,让Jenkins在Web UI中记录报告和可视化的故障是有用的。下面的示例使用junit由JUnit插件提供的步骤。
在下面的示例中,如果测试失败,则Pipeline被标记为“不稳定”,如Web UI中的黄色球。根据记录的测试报告,Jenkins还可以提供历史趋势分析和可视化。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Test') {
steps {
/* `make check` returns non-zero on test failures,
* using `true` to allow the Pipeline to continue nonetheless
*/
sh 'make check || true'  junit '**/target/*.xml'
junit '**/target/*.xml'  }
}
}
}
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
/* .. snip .. */
stage('Test') {
/* `make check` returns non-zero on test failures,
* using `true` to allow the Pipeline to continue nonetheless
*/
sh 'make check || true'
junit '**/target/*.xml'
}
/* .. snip .. */
} :使用内联shell conditional(
:使用内联shell conditional(sh 'make || true')确保该 sh步骤始终看到零退出代码,从而使该junit步骤有机会捕获和处理测试报告。下面的“ 处理故障”部分将详细介绍其他方法。
 :
:junit捕获并关联与包含pattern(**/target/*.xml)匹配的JUnit XML文件
部署
部署可能意味着各种步骤,具体取决于项目或组织的要求,并且可能是从构建的工件发送到Artifactory服务器,将代码推送到生产系统的任何步骤。
在Pipeline示例的这个阶段,“构建”和“测试”阶段都已成功执行。实际上,“部署”阶段只能在上一阶段成功完成,否则Pipeline将早退。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Deploy') {
when {
expression {
currentBuild.result == null || currentBuild.result == 'SUCCESS'
}
}
steps {
sh 'make publish'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
/* .. snip .. */
stage('Deploy') {
if (currentBuild.result == null || currentBuild.result == 'SUCCESS') {
sh 'make publish'
}
}
/* .. snip .. */
}:访问该currentBuild.result变量允许Pipeline确定是否有任何测试失败。在这种情况下,值将是 UNSTABLE。
假设一切都在Jenkins Pipeline示例中成功执行,每个成功的Pipeline运行都会将存档的关联构建工件,报告的测试结果和完整的控制台输出全部放在Jenkins中。
脚本Pipeline可以包括条件测试(如上所示),循环,try / catch / finally块甚至函数。下一节将详细介绍这种高级脚本Pipeline语法。
管道高级语法
字符串插值
Jenkins Pipeline使用与Groovy相同的规则 进行字符串插值。Groovy的字符串插值支持可能会让很多新来的语言感到困惑。虽然Groovy支持使用单引号或双引号声明一个字符串,例如:
def singlyQuoted = 'Hello'
def doublyQuoted = "World"只有后一个字符串将支持基于dollar-sign($)的字符串插值,例如:
def username = 'Jenkins'
echo 'Hello Mr. ${username}'
echo "I said, Hello Mr. ${username}"会导致:
Hello Mr. ${username}
I said, Hello Mr. Jenkins了解如何使用字符串插值对于使用一些管道更高级的功能至关重要。
工作环境
Jenkins Pipeline通过全局变量公开环境变量,该变量env可从任何地方获得Jenkinsfile。假设Jenkins主机正在运行,在本地主机:8080 / pipeline-syntax / globals#env中记录了可从Jenkins Pipeline中访问的环境变量的完整列表 localhost:8080,其中包括:
- BUILD_ID
-
当前版本ID,与Jenkins版本1.597+中创建的构建相同,为BUILD_NUMBER
- JOB_NAME
-
此构建项目的名称,如“foo”或“foo / bar”。
- JENKINS_URL
-
完整的Jenkins网址,例如example.com:port/jenkins/(注意:只有在“系统配置”中设置了Jenkins网址时才可用)
参考或使用这些环境变量可以像访问Groovy Map中的任何键一样完成 ,例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example') {
steps {
echo "Running ${env.BUILD_ID} on ${env.JENKINS_URL}"
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
echo "Running ${env.BUILD_ID} on ${env.JENKINS_URL}"
}设置环境变量
根据是否使用Declarative或Scripted Pipeline,在Jenkins Pipeline中设置环境变量是不同的。
声明式Pipeline支持环境指令,而Scripted Pipeline的用户必须使用该withEnv步骤。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
environment {
CC = 'clang'
}
stages {
stage('Example') {
environment {  DEBUG_FLAGS = '-g'
}
steps {
sh 'printenv'
}
}
}
}
DEBUG_FLAGS = '-g'
}
steps {
sh 'printenv'
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
/* .. snip .. */
withEnv(["PATH+MAVEN=${tool 'M3'}/bin"]) {
sh 'mvn -B verify'
}
}:environment顶级pipeline块中使用的指令将适用于Pipeline中的所有步骤。
 :在一个
:在一个environment意图中定义的一个指令stage将仅将给定的环境变量应用于该过程中的步骤stage。
参数
声明式Pipeline支持开箱即用的参数,允许Pipeline在运行时通过parameters指令接受用户指定的参数。使用脚本Pipeline配置参数是通过properties步骤完成的,可以在代码段生成器中找到。
如果您使用“使用构建参数”选项来配置Pipeline以接受参数,那么这些参数可作为params 变量的成员访问。
假设一个名为“Greeting”的String参数已经在配置中 Jenkinsfile,它可以通过${params.Greeting}以下方式访问该参数:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
parameters {
string(name: 'Greeting', defaultValue: 'Hello', description: 'How should I greet the world?')
}
stages {
stage('Example') {
steps {
echo "${params.Greeting} World!"
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
properties([parameters([string(defaultValue: 'Hello', description: 'How should I greet the world?', name: 'Greeting')])])
node {
echo "${params.Greeting} World!"
}故障处理
声明性Pipeline默认支持robust失败处理经由其post section,其允许声明许多不同的“post conditions”,例如:always,unstable,success,failure,和 changed。“ Pipeline语法”部分提供了有关如何使用各种帖子条件的更多详细信息。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Test') {
steps {
sh 'make check'
}
}
}
post {
always {
junit '**/target/*.xml'
}
failure {
mail to: team@example.com, subject: 'The Pipeline failed :('
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
node {
/* .. snip .. */
stage('Test') {
try {
sh 'make check'
}
finally {
junit '**/target/*.xml'
}
}
/* .. snip .. */
}但是脚本Pipeline依赖于Groovy的内置try/ catch/ finally该Pipeline的执行过程中处理故障的语义。
在上面的测试示例中,该sh步骤被修改为从不返回非零退出代码(sh 'make check || true')。这种方法虽然有效,但是意味着以下阶段需要检查currentBuild.result以确定是否有测试失败。
处理这种情况的另一种方法是保留Pipeline故障的早期退出行为,同时仍然junit有机会捕获测试报告,是使用一系列try/ finally块:
使用多个代理
在所有以前的例子中,只使用了一个代理。这意味着Jenkins将分配一个可用的执行器,无论它是如何标记或配置的。这不仅可以行为被覆盖,但Pipeline允许从内利用Jenkins环境中的多个代理商相同 Jenkinsfile,可为更高级的使用情况,如执行有帮助建立跨多个平台/测试。
在下面的示例中,“构建”阶段将在一个代理上执行,并且构建的结果将在“测试”阶段中分别标记为“linux”和“windows”的两个后续代理程序中重用。
Jenkinsfile (Declarative Pipeline)
pipeline {
agent none
stages {
stage('Build') {
agent any
steps {
checkout scm
sh 'make'
stash includes: '**/target/*.jar', name: 'app'  }
}
stage('Test on Linux') {
agent {
}
}
stage('Test on Linux') {
agent {  label 'linux'
}
steps {
unstash 'app'
label 'linux'
}
steps {
unstash 'app'  sh 'make check'
}
post {
always {
junit '**/target/*.xml'
}
}
}
stage('Test on Windows') {
agent {
label 'windows'
}
steps {
unstash 'app'
bat 'make check'
sh 'make check'
}
post {
always {
junit '**/target/*.xml'
}
}
}
stage('Test on Windows') {
agent {
label 'windows'
}
steps {
unstash 'app'
bat 'make check'  }
post {
always {
junit '**/target/*.xml'
}
}
}
}
}
}
post {
always {
junit '**/target/*.xml'
}
}
}
}
}Toggle Scripted Pipeline (Advanced)
Jenkinsfile (Scripted Pipeline)
stage('Build') {
node {
checkout scm
sh 'make'
stash includes: '**/target/*.jar', name: 'app'
}
}
stage('Test') {
node('linux') {
checkout scm
try {
unstash 'app'
sh 'make check'
}
finally {
junit '**/target/*.xml'
}
}
node('windows') {
checkout scm
try {
unstash 'app'
bat 'make check'
}
finally {
junit '**/target/*.xml'
}
}
} :该
:该stash步骤允许捕获与包含模式(**/target/*.jar)匹配的文件,以在同一管道中重用。一旦Pipeline完成执行,垃圾文件将从Jenkins主站中删除。
 :
:agent/中的参数node允许任何有效的Jenkins标签表达式。有关详细信息,请参阅Pipeline语法部分。
 :
:unstash 将从Jenkins主机中检索名为“藏书”的管道当前工作空间。
 : 该
: 该bat脚本允许在基于Windows的平台上执行批处理脚本.
可选步骤参数
Pipeline遵循Groovy语言约定,允许在方法参数中省略括号。
许多Pipeline步骤还使用命名参数语法作为使用Groovy创建Map的简写,它使用语法[key1: value1, key2: value2]。发表如下功能等同的语句:
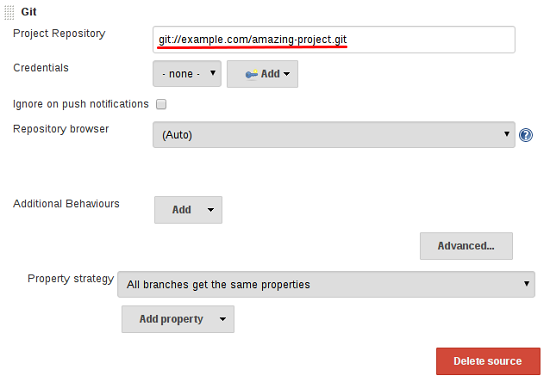
git url: 'git://example.com/amazing-project.git', branch: 'master'
git([url: 'git://example.com/amazing-project.git', branch: 'master'])为方便起见,当仅调用一个参数(或只有一个必需参数)时,可能会省略参数名称,例如:
sh 'echo hello' /* short form */
sh([script: 'echo hello']) /* long form */高级脚本管道
脚本Pipeline是 基于Groovy 的领域专用语言,大多数Groovy语法可以在脚本Pipeline中使用而无需修改。
同时执行
上面的例子在线性系列中的两个不同平台上运行测试。在实践中,如果make check 执行需要30分钟完成,“测试”阶段现在需要60分钟才能完成!
幸运的是,Pipeline具有内置功能,用于并行执行Scripted Pipeline的部分,在适当命名的parallel步骤中实现。
重构上述示例以使用parallel步骤:
Jenkinsfile (Scripted Pipeline)
stage('Build') {
/* .. snip .. */
}
stage('Test') {
parallel linux: {
node('linux') {
checkout scm
try {
unstash 'app'
sh 'make check'
}
finally {
junit '**/target/*.xml'
}
}
},
windows: {
node('windows') {
/* .. snip .. */
}
}
}而不是在“linux”和“windows”标签的节点上执行测试,它们现在将在Jenkins环境中存在必需容量的情况下并行执行。
Pipeline 分支与Pull请求
在上一节一个Jenkinsfile可能被签入源代码控制实施。本节将介绍多支Pipeline的概念, 该Jenkinsfile基础是在Jenkins提供更多动态和自动功能的基础上建立的。
创建多分支Pipeline
多分支Pipeline项目类型使您可以实现不同Jenkinsfiles在同一个项目的不同分支。在Multibranch Pipeline项目中,Jenkins自动发现,Pipeline和执行包含Jenkinsfile源代码控制的分支Pipeline。
这不需要手动Pipeline创建和管理。
创建多分支Pipeline:
- 单击Jenkins主页上的New Item。
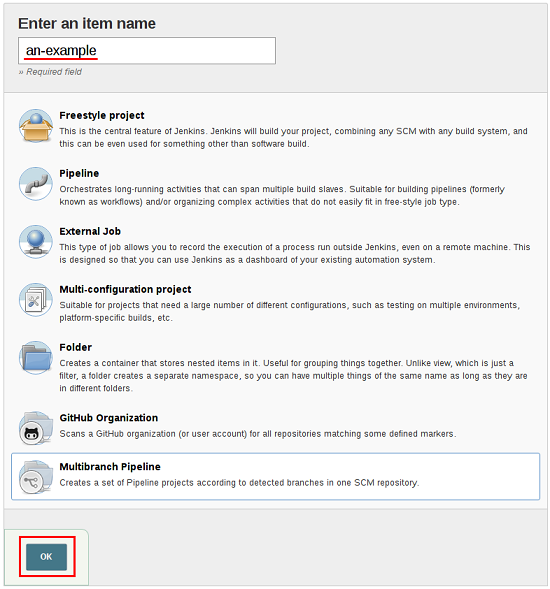
- 输入Pipeline的名称,选择多Multibranch Pipeline,然后单击确定
Jenkins使用Pipeline的名称在磁盘上创建目录。包含空格的Pipeline名称可能会发现不希望路径包含空格的脚本中的错误。
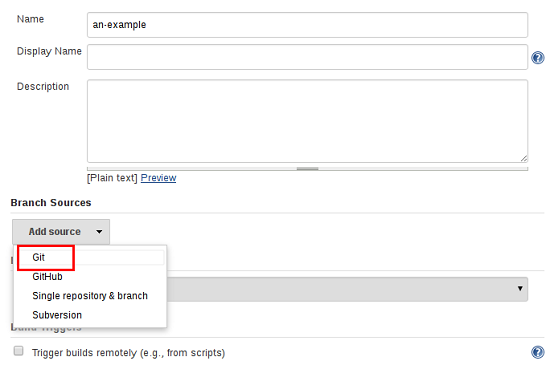
- 添加分支源(例如,Git)并输入存储库的位置。
- 保存多分支Pipeline项目。
一旦保存,Jenkins自动扫描指定的存储库,并为其中包含了库中的每个分支合适的项目 Jenkinsfile。
默认情况下,Jenkins不会自动重新索引存储库以进行分支添加或删除(除非使用组织文件夹),因此配置多分支Pipeline在配置中定期重新建立索引通常很有用:

附加环境变量
Multibranch Pipeline公开了通过env全局变量构建的分支的附加信息,例如:
- BRANCH_NAME
-
例如,该Pipeline正在执行的分支的名称
master。 - CHANGE_ID
-
对应于某种改变请求的标识符,例如拉请求号
其他环境变量列在“ 全局变量引用”中。
支持Pull请求
通过“GitHub”或“Bitbucket”分支源,多分支Pipeline可用于验证拉/更改请求。该功能分别由 GitHub分支源 和 Bitbucket分支源 插件提供。有关如何使用这些插件的更多信息,请参阅他们的文档。
Using Organization Folders
组织文件夹使Jenkins监视整个GitHub组织或Bitbucket团队/项目,并自动创建包含分支和拉请求的存储库的新的多支路Pipeline Jenkinsfile。
目前,此功能仅适用于GitHub和Bitbucket,具有由 GitHub组织文件夹 和 Bitbucket Branch Source 插件提供的功能。
Pipeline 扩展共享库
由于Pipeline在一个组织中越来越多的项目被采用,普遍的模式很可能会出现。通常,在各种项目之间共享Pipeline的部分是有用的,以减少冗余并保持代码“DRY” 。
Pipeline支持创建“共享库”,可以在外部源代码控制存储库中定义并加载到现有的Pipeline中。
定义共享库
共享库使用名称,源代码检索方法(如SCM)以及可选的默认版本进行定义。该名称应该是一个简短的标识符,因为它将在脚本中使用。
该版本可以被该SCM所了解; 例如,分支,标签和提交hashes都为Git工作。您还可以声明脚本是否需要显式请求该库(详见下文),或默认情况下是否存在。此外,如果您在Jenkins配置中指定版本,则可以阻止脚本选择不同的版本。
指定SCM的最佳方法是使用已经特别更新的SCM插件,以支持新的API来检出任意命名版本(现代SCM选项)。在撰写本文时,最新版本的Git和Subversion插件支持此模式; 其他人应该遵循。
如果您的SCM插件尚未集成,则可以选择Legacy SCM并选择所提供的任何内容。在这种情况下,您需要${library.yourLibName.version}在SCM的配置中包含 某处,以便在结帐时插件将扩展此变量以选择所需的版本。例如,对于Subversion,您可以将Repository URL设置为https://svnserver/project/${library.yourLibName.version},然后使用诸如trunkor branches/dev或之类的版本tags/1.0
目录结构
共享库存储库的目录结构如下所示:
(root)
+- src # Groovy source files
| +- org
| +- foo
| +- Bar.groovy # for org.foo.Bar class
+- vars
| +- foo.groovy # for global 'foo' variable
| +- foo.txt # help for 'foo' variable
+- resources # resource files (external libraries only)
| +- org
| +- foo
| +- bar.json # static helper data for org.foo.Bar该src目录应该像标准的Java源目录结构。执行Pipeline时,该目录将添加到类路径中。
该vars目录托管定义可从Pipeline访问的全局变量的脚本。通常,每个*.groovy文件的基本名称应该是Groovy(〜Java)标识符camelCased。匹配*.txt(如果存在)可以包含通过系统配置的标记格式化程序处理的文档(所以可能真的是HTML,Markdown等,尽管txt需要扩展)。
这些目录中的Groovy源文件与Scripted Pipeline中的“CPS转换”相同。
甲resources目录允许libraryResource从外部库中使用步骤来加载相关联的非Groovy文件。目前内部库不支持此功能。
保留根目录下的其他目录,以备将来进行增强
全球共享库
根据用例,有几个可以定义共享库的地方。管理Jenkins»配置系统»全局Pipeline库 可以配置所需的许多库。

由于这些库将全局可用,系统中的任何Pipeline都可以利用这些库中实现的功能。
这些库被认为是“受信任的”:他们可以在Java,Groovy,Jenkins内部API,Jenkins插件或第三方库中运行任何方法。这允许您定义将各个不安全的API封装在更高级别的包装器中的库,以便从任何Pipeline使用。请注意,任何能够将提交到该SCM存储库的人都可以无限制地访问Jenkins。您需要总体/ RunScripts权限来配置这些库(通常这将授予Jenkins管理员)。
文件夹级共享库
创建的任何文件夹可以具有与其关联的共享库。此机制允许将特定库范围限定为文件夹或子文件夹内的所有Pipeline。
基于文件夹的库不被认为是“受信任的”:它们像Groovy sandbox 一样运行,就像典型的Pipeline一样。
自动共享库
其他插件可能会添加在运行中定义库的方法。例如, GitHub分支源插件提供了一个“GitHub组织文件夹”项,它允许脚本使用不受信任的库,例如github.com/someorg/somerepo没有任何其他配置。在这种情况下,指定的GitHub存储库将从master 分支中使用匿名检出进行加载。
使用库
标记为加载的共享库隐式允许Pipeline立即使用由任何此类库定义的类或全局变量。要访问其他共享库,Jenkinsfile需要使用@Library注释,指定库的名称:
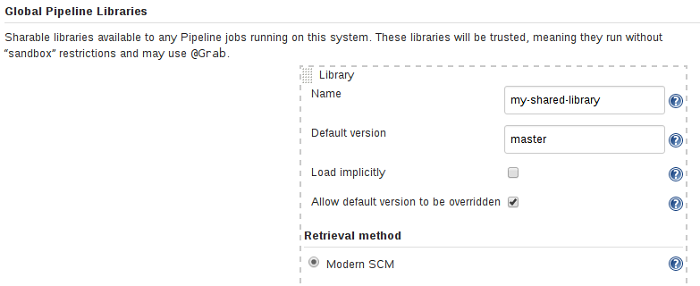
@Library('my-shared-library') _
/* Using a version specifier, such as branch, tag, etc */
@Library('my-shared-library@1.0') _
/* Accessing multiple libraries with one statement */
@Library(['my-shared-library', 'otherlib@abc1234']) _注释可以在脚本中的任何地方,Groovy允许注释。当引用类库(包含src/目录)时,通常会在import语句上注释:
@Library('somelib')
import com.mycorp.pipeline.somelib.UsefulClass对于仅定义全局变量(vars/)的共享库或 Jenkinsfile仅需要全局变量的 共享库,注释 模式@Library('my-shared-library') _可能有助于保持代码简洁。实质上,import该符号不是注释不必要的语句_。
不推荐import使用全局变量/函数,因为这将强制编译器解释字段和方法,static 即使它们是实例。在这种情况下,Groovy编译器可能会产生混乱的错误消息。在编译脚本之前,在开始执行之前解析和加载库。这允许Groovy编译器了解在静态类型检查中使用的符号的含义,并允许它们在脚本中的类型声明中使用,例如:
@Library('somelib')
import com.mycorp.pipeline.somelib.Helper
int useSomeLib(Helper helper) {
helper.prepare()
return helper.count()
}
echo useSomeLib(new Helper('some text'))然而,全局变量在运行时解决。
动态加载库
从2.7版Pipeline:共享Groovy库插件,有一个新的选项,用于在脚本中加载(非隐式)库:一个在构建期间的任何时间动态library加载库的步骤。
如果您只对使用全局变量/函数感兴趣(从vars/目录中),语法非常简单:
library 'my-shared-library'此后,脚本中可以访问该库中的任何全局变量。
从src/目录中使用类也是可能的,但是比较棘手。而在@Library编译之前,注释准备脚本的“classpath”,在library遇到步骤时,脚本已经被编译。因此,您不能import或以其他方式“静态地”引用库中的类型。
但是,您可以动态地使用库类(无类型检查),从library步骤的返回值通过完全限定名称访问它们。 static可以使用类似Java的语法来调用方法:
library('my-shared-library').com.mycorp.pipeline.Utils.someStaticMethod()您还可以访问static字段,并调用构造函数,就像它们是指定的static方法一样new:
def useSomeLib(helper) { // dynamic: cannot declare as Helper
helper.prepare()
return helper.count()
}
def lib = library('my-shared-library').com.mycorp.pipeline // preselect the package
echo useSomeLib(lib.Helper.new(lib.Constants.SOME_TEXT))库版本
例如,当勾选“加载隐式”时,或者如果Pipeline仅以名称引用库,则使用配置的共享库的“默认版本” @Library('my-shared-library') _。如果“默认版本” 没有定义,Pipeline必须指定一个版本,例如 @Library('my-shared-library@master') _。
如果在共享库的配置中启用了“允许默认版本被覆盖”,则@Library注释也可以覆盖为库定义的默认版本。这样还可以在必要时从不同的版本加载带有“负载加载”的库。
使用该library步骤时,您还可以指定一个版本:
library 'my-shared-library@master'由于这是一个常规步骤,所以该版本可以 与注释一样计算而不是常量; 例如:
library "my-shared-library@$BRANCH_NAME"将使用与多分支相同的SCM分支来加载库Jenkinsfile。另一个例子,你可以通过参数选择一个库:
properties([parameters([string(name: 'LIB_VERSION', defaultValue: 'master')])])
library "my-shared-library@${params.LIB_VERSION}"请注意,该library步骤可能不会用于覆盖隐式加载库的版本。它在脚本启动时已经加载,给定名称的库可能不会被加载两次。
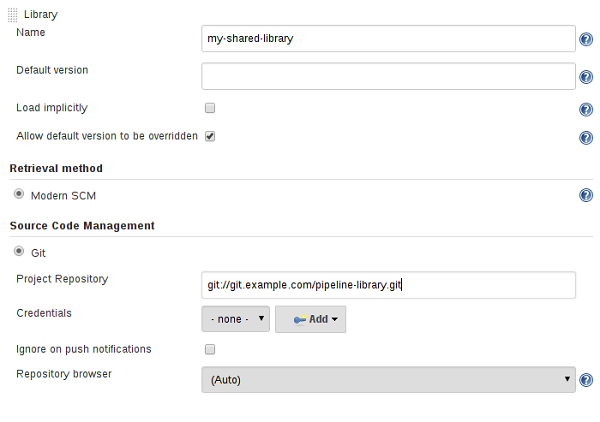
检索方法
指定SCM的最佳方法是使用已经特别更新的SCM插件,以支持新的API来检出任意命名版本(现代SCM选项)。在撰写本文时,Git和Subversion插件的最新版本支持此模式。
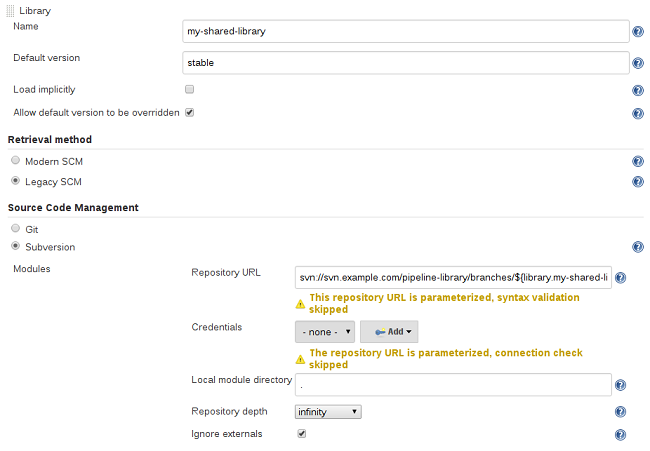
传统SCM
尚未更新以支持共享库所需的较新功能的SCM插件仍可通过Legacy SCM选项使用。在这种情况下,包括${library.yourlibrarynamehere.version}可以为该特定SCM插件配置branch / tag / ref的任何位置。这可以确保在检索库的源代码期间,SCM插件将扩展此变量以检出库的相应版本。
动态检索
如果您仅@在library步骤中指定库名称(可选地,随后使用版本),Jenkins将查找该名称的预配置库。(或者在github.com/owner/repo自动库的情况下,它将加载。)
但是您也可以动态地指定检索方法,在这种情况下,不需要在Jenkins中预定义库。这是一个例子:
library identifier: 'custom-lib@master', retriever: modernSCM(
[$class: 'GitSCMSource',
remote: 'git@git.mycorp.com:my-jenkins-utils.git',
credentialsId: 'my-private-key'])为了您的SCM的精确语法,最好参考流水线语法。
请注意,在这些情况下必须指定库版本。
Writing libraries
在基层,任何有效的 Groovy代码 都可以使用。不同的数据结构,实用方法等,如:
// src/org/foo/Point.groovy
package org.foo;
// point in 3D space
class Point {
float x,y,z;
}访问步骤
库类不能直接调用诸如shor的步骤git。然而,它们可以实现除封闭类之外的方法,这些方法又调用Pipeline步骤,例如:
// src/org/foo/Zot.groovy
package org.foo;
def checkOutFrom(repo) {
git url: "git@github.com:jenkinsci/${repo}"
}然后可以从脚本Pipeline中调用它:
def z = new org.foo.Zot()
z.checkOutFrom(repo)这种做法有局限性; 例如,它阻止了超类的声明。
或者,一组steps可以显式传递给库类,构造函数或只是一种方法:
package org.foo
class Utilities implements Serializable {
def steps
Utilities(steps) {this.steps = steps}
def mvn(args) {
steps.sh "${steps.tool 'Maven'}/bin/mvn -o ${args}"
}
}当在类上保存状态时,如上面所述,类必须实现 Serializable接口。这样可确保使用该类的Pipeline,如下面的示例所示,可以在Jenkins中正确挂起并恢复。
@Library('utils') import org.foo.Utilities
def utils = new Utilities(steps)
node {
utils.mvn 'clean package'
}如果库需要访问全局变量,例如env,那些应该以类似的方式显式传递给库类或方法。
而不是将许多变量从脚本Pipeline传递到库中,
package org.foo
class Utilities {
static def mvn(script, args) {
script.sh "${script.tool 'Maven'}/bin/mvn -s ${script.env.HOME}/jenkins.xml -o ${args}"
}
}上面的示例显示了脚本被传递到一个static方法,从脚本Pipeline调用如下:
@Library('utils') import static org.foo.Utilities.*
node {
mvn this, 'clean package'
}定义全局变量
在内部,vars目录中的脚本作为单例按需实例化。这允许在单个.groovy文件中定义多个方法或属性,这些文件彼此交互,例如:
// vars/acme.groovy
def setName(value) {
name = value
}
def getName() {
name
}
def caution(message) {
echo "Hello, ${name}! CAUTION: ${message}"
}在上面,name不是指一个字段(即使你把它写成this.name!),而是一个根据需要创建的条目Script.binding。要清楚你要存储什么类型的什么数据,你可以改为提供一个明确的类声明(类名称应符合的文件名前缀,如果只能调用Pipeline的步骤steps或this传递给类或方法,与src上述课程一样):
// vars/acme.groovy
class acme implements Serializable {
private String name
def setName(value) {
name = value
}
def getName() {
name
}
def caution(message) {
echo "Hello, ${name}! CAUTION: ${message}"
}
}然后,Pipeline可以调用将在acme对象上定义的这些方法 :
acme.name = 'Alice'
echo acme.name /* prints: 'Alice' */
acme.caution 'The queen is angry!' /* prints: 'Hello, Alice. CAUTION: The queen is angry!' */温习提示:在Jenkins加载并使用该库作为成功的Pipeline运行的一部分后,共享库中定义的变量将仅显示在“ 全局变量参考”(在“ Pipeline语法”下)。
定义步骤
共享库还可以定义与内置步骤类似的全局变量,例如sh或git。共享库中定义的全局变量必须使用所有小写或“camelCase”命名,以便由Pipeline正确加载。
例如,要定义sayHello,vars/sayHello.groovy 应该创建文件,并应该实现一个call方法。该call方法允许以类似于以下步骤的方式调用全局变量:
// vars/sayHello.groovy
def call(String name = 'human') {
// Any valid steps can be called from this code, just like in other
// Scripted Pipeline
echo "Hello, ${name}."
}然后,Pipeline将能够引用并调用此变量:
sayHello 'Joe'
sayHello() /* invoke with default arguments */如果调用一个块,该call方法将收到一个 Closure。应明确界定类型,以澄清步骤的意图,例如:
// vars/windows.groovy
def call(Closure body) {
node('windows') {
body()
}
}然后,Pipeline可以像接受一个块的任何内置步骤一样使用此变量:
windows {
bat "cmd /?"
}定义更结构化的DSL
如果您有大量类似的Pipeline,则全局变量机制提供了一个方便的工具来构建更高级别的DSL来捕获相似性。例如,所有的插件Jenkins构建和以同样的方式进行测试,所以我们可以写一个名为步 buildPlugin:
// vars/buildPlugin.groovy
def call(body) {
// evaluate the body block, and collect configuration into the object
def config = [:]
body.resolveStrategy = Closure.DELEGATE_FIRST
body.delegate = config
body()
// now build, based on the configuration provided
node {
git url: "https://github.com/jenkinsci/${config.name}-plugin.git"
sh "mvn install"
mail to: "...", subject: "${config.name} plugin build", body: "..."
}
}假设脚本已被加载为 全局共享库或 文件夹级共享库 ,结果Jenkinsfile将会更加简单:
Jenkinsfile (Scripted Pipeline)
buildPlugin {
name = 'git'
}使用第三方库
通过使用注释,可以使用通常位于Maven Central中的第三方Java库 从受信任的库代码中使用@Grab。 有关详细信息,请参阅 Grape文档,但简单地说:
@Grab('org.apache.commons:commons-math3:3.4.1')
import org.apache.commons.math3.primes.Primes
void parallelize(int count) {
if (!Primes.isPrime(count)) {
error "${count} was not prime"
}
// …
}第三方库默认缓存~/.groovy/grapes/在Jenkins主机上。
资源加载
外部库可以resources/使用libraryResource步骤从目录中加载附件文件。参数是一个相对路径名,类似于Java资源加载:
def request = libraryResource 'com/mycorp/pipeline/somelib/request.json'该文件作为字符串加载,适合传递给某些API或使用保存到工作空间writeFile。
建议使用独特的包装结构,以便您不会意外与另一个库冲突。
预测库更改
如果您使用不受信任的库发现构建中的错误,只需单击Replay链接即可尝试编辑其一个或多个源文件,并查看生成的构建是否按预期方式运行。一旦您对结果感到满意,请从构建状态页面执行diff链接,并将diff应用于库存储库并提交。
(即使库要求的版本是分支,而不是像标签一样的固定版本,重播的构建将使用与原始版本完全相同的修订版本:库源将不会被重新签出。)
受信任的库不支持重放。Replay中目前不支持修改资源文件。
Pipeline 开发工具
Jenkins Pipeline包含内置文档和 Snippet Generator,它们是开发Pipeline时的关键资源。它们提供了针对当前安装的Jenkins版本和相关插件定制的详细帮助和信息。在本节中,我们将讨论可能有助于开发Jenkins Pipeline的其他工具和资源。
Blue Ocean编辑器
在 Blue Ocean Pipeline编辑器提供了一个WYSIWYG的方式来创建声明Pipeline。编辑器提供了Pipeline中所有阶段,平行分支和步骤的结构视图。编辑器会根据Pipeline更改进行验证,消除许多错误,甚至被提交。在幕后,它仍然生成声明性的Pipeline代码。
命令行Pipeline Linter
Jenkins可以在实际运行之前从命令行验证或“ lint ”声明式Pipeline。这可以使用Jenkins CLI命令或使用适当的参数进行HTTP POST请求来完成。我们建议使用 SSH接口 运行linter。有关如何正确配置Jenkins以进行安全命令行访问的详细信息,请参阅Jenkins CLI文档。
通过CLI通过SSH进行Linting
# ssh (Jenkins CLI)
# JENKINS_SSHD_PORT=[sshd port on master]
# JENKINS_HOSTNAME=[Jenkins master hostname]
ssh -p $JENKINS_SSHD_PORT $JENKINS_HOSTNAME declarative-linter < Jenkinsfile通过HTTP POST使用 curl
# curl (REST API)
# Assuming "anonymous read access" has been enabled on your Jenkins instance.
# JENKINS_URL=[root URL of Jenkins master]
# JENKINS_CRUMB is needed if your Jenkins master has CRSF protection enabled as it should
JENKINS_CRUMB=`curl "$JENKINS_URL/crumbIssuer/api/xml?xpath=concat(//crumbRequestField,\":\",//crumb)"`
curl -X POST -H $JENKINS_CRUMB -F "jenkinsfile=<Jenkinsfile" $JENKINS_URL/pipeline-model-converter/validate例子
以下是Pipeline Linter的两个实例。第一个例子显示了linter在通过无效的输出时Jenkinsfile,缺少agent声明的一部分。
Jenkinsfile
pipeline {
agent
stages {
stage ('Initialize') {
steps {
echo 'Placeholder.'
}
}
}
}Linter输出无效的Jenkins文件
# pass a Jenkinsfile that does not contain an "agent" section
ssh -p 8675 localhost declarative-linter < ./Jenkinsfile
Errors encountered validating Jenkinsfile:
WorkflowScript: 2: Not a valid section definition: "agent". Some extra configuration is required. @ line 2, column 3.
agent
^
WorkflowScript: 1: Missing required section "agent" @ line 1, column 1.
pipeline }
^在第二个例子中,Jenkinsfile已经被更新为包含缺少any的agent。linter现在报告Pipeline是有效的。
Jenkinsfile
pipeline {
agent any
stages {
stage ('Initialize') {
steps {
echo 'Placeholder.'
}
}
}
}Linter输出有效的Jenkins文件
ssh -p 8675 localhost declarative-linter < ./Jenkinsfile
Jenkinsfile successfully validated.“Replay”Pipeline运行与修改
通常,Pipeline将在经典的Jenkins Web UI中定义,或者通过提交到Jenkinsfile源代码控件来定义。不幸的是,这两种方法都不适用于Pipeline的快速迭代或原型设计。“重播”功能可以快速修改和执行现有流水线,而无需更改Pipeline配置或创建新的提交。
用法
要使用“重播”功能:
1、在构建历史记录中选择先前完成的运行。
2、点击左侧菜单中的“重播”

3、进行修改并单击“运行”。在这个例子中,我们将“ruby-2.3”更改为“ruby-2.4”。
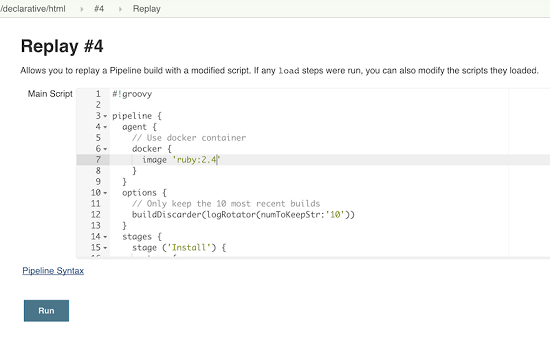
4、检查更改的结果
一旦您对更改感到满意,您可以使用Replay再次查看它们,将其复制回Pipeline作业Jenkinsfile,然后使用您通常的工程流程提交。
特征
- 可以在同一运行中多次调用 - 允许轻松并行测试不同的更改。
- 也可以在仍在进行中的Pipeline运行中调用 - 只要Pipeline包含语法正确的Groovy并且能够启动,它可以被Replayed。
- 参考的共享库代码也可以修改 - 如果Pipeline运行引用 共享库,共享库中的代码也将作为Replay页面的一部分显示和修改。
限制
- 无法重播语法错误的Pipeline运行 - 这意味着无法查看代码,无法检索其中所做的任何更改。当使用Replay进行更多重要的修改时,在将其更改保存到Jenkins之外的文件或编辑器之前,请先运行它们。
- 重播的Pipeline行为可能与其他方法开始的运行有所不同 - 对于不属于多分支流水线的Pipeline,对于原始运行和Replayed运行,提交信息可能不同。见JENKINS-36453
Pipeline单元测试框架
Pipeline单元测试框架是Jenkins项目不支持的第三方工具。该Pipeline单元测试框架 可以让你的单元测试Pipeline和共享库完全运行之前。它提供了一个模拟的执行环境,真正的Pipeline的步骤是模仿对象,模仿对象
是可以使用检查期望的方式取代的。虽然新的和粗糙的边缘,但有希望。该项目的README包含示例和使用说明。
Pipeline 语法
本节基于“ 入门指南”中介绍的信息,并应作为参考。有关如何在实际示例中使用Pipeline语法的更多信息,请参阅 本章的Jenkinsfile部分。从Pipeline插件2.5版开始,Pipeline支持两种离散语法,详细说明如下。对于每个的利弊,请参阅语法比较(下文中)。
如“ 入门指南 ”所述,Pipeline最基本的部分是“步骤”。基本上,步骤告诉Jenkins 要做什么,并且作为Declarative和Scripted Pipeline语法的基本构建块。
有关可用步骤的概述,请参阅 Pipeline步骤参考(下文中) ,其中包含Pipeline内置的完整列表以及插件提供的步骤。
声明Pipeline
声明性Pipeline是Jenkins Pipeline 的一个相对较新的补充, 它在Pipeline子系统之上提出了一种更为简化和有意义的语法。
所有有效的声明性Pipeline必须包含在一个pipeline块内,例如:
pipeline {
/* insert Declarative Pipeline here */
}声明性Pipeline中有效的基本语句和表达式遵循与Groovy语法相同的规则 ,但有以下例外:
- Pipeline的顶层必须是块,具体来说是:pipeline { }
- 没有分号作为语句分隔符。每个声明必须在自己的一行
- 块只能包含章节, 指令,步骤或赋值语句。
- 属性引用语句被视为无参数方法调用。所以例如,输入被视为input()
Sections
声明性Pipeline中的部分通常包含一个或多个指令或步骤。
agent
该agent部分指定整个Pipeline或特定阶段将在Jenkins环境中执行的位置,具体取决于该agent 部分的放置位置。该部分必须在pipeline块内的顶层定义 ,但阶段级使用是可选的。
|
需要 |
是 |
|---|---|
|
参数 |
如下面所描述的 |
|
允许 |
在顶级 |
参数
为了支持作者可能有的各种各样的pipeline用例, agent 部分支持一些不同类型的参数。这些参数应用在`pipeline`块的顶层, 或 stage 指令内部。
在任何可用的代理上执行Pipeline或stage。例如:agent any
当在pipeline块的顶层应用时,将不会为整个Pipeline运行分配全局代理,并且每个stage部分将需要包含其自己的agent部分。例如:agent none
使用提供的标签在Jenkins环境中可用的代理上执行Pipeline或阶段性执行。例如:agent { label 'my-defined-label' }
agent { node { label 'labelName' } }行为相同 agent { label 'labelName' },但node允许其他选项(如customWorkspace)。
执行Pipeline,或阶段执行,用给定的容器将被动态地供应一个节点预先配置成接受基于Docker-based Pipelines,或匹配的任选定义的节点上 label的参数。 docker还可以接受一个args可能包含直接传递给docker run调用的参数的参数。例如:agent { docker 'maven:3-alpine' }或
agent {
docker {
image 'maven:3-alpine'
label 'my-defined-label'
args '-v /tmp:/tmp'
}
}- dockerfile
-
使用从
Dockerfile源存储库中包含的容器构建容器来执行Pipeline或阶段性执行 。为了使用此选项,Jenkinsfile必须从多分支Pipeline或“Pipeline从SCM”加载。通常这是Dockerfile源库的根源:agent { dockerfile true }。如果Dockerfile在另一个目录中建立,请使用以下dir选项:agent { dockerfile { dir 'someSubDir' } }。您可以docker build ...使用该additionalBuildArgs选项将其他参数传递给命令,如agent { dockerfile { additionalBuildArgs '--build-arg foo=bar' } }。
常用选项
这些是可以应用两个或多个agent实现的几个选项。除非明确说明,否则不需要。
- 标签
-
一个字符串。运行Pipeline或个人的标签
stage。此选项对于
node,docker和dockerfile,并且是必需的node。 - customWorkspace
-
一个字符串。运行Pipeline或个人
stage这agent是这个自定义的工作空间内的应用,而不是默认的。它可以是相对路径,在这种情况下,自定义工作区将位于节点上的工作空间根目录下,也可以是绝对路径。例如:
agent {
node {
label 'my-defined-label'
customWorkspace '/some/other/path'
}
}-
此选项是有效的
node,docker和dockerfile。 - reuseNode
-
一个布尔值,默认为false。如果为true,则在同一工作空间中,而不是完全在新节点上运行Pipeline顶层指定的节点上的容器。
此选项适用于
docker和dockerfile,并且仅在agent个人使用时才有效果stage。
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent { docker 'maven:3-alpine' }  stages {
stage('Example Build') {
steps {
sh 'mvn -B clean verify'
}
}
}
}
stages {
stage('Example Build') {
steps {
sh 'mvn -B clean verify'
}
}
}
} :在给定名称和tag(
:在给定名称和tag(maven:3-alpine)的新创建的容器中执行此Pipeline中定义的所有步骤。
Stage-level agent 部分
Jenkinsfile (Declarative Pipeline)
pipeline {
agent none
stages {
stage('Example Build') {
agent { docker 'maven:3-alpine' }  steps {
echo 'Hello, Maven'
sh 'mvn --version'
}
}
stage('Example Test') {
agent { docker 'openjdk:8-jre' }
steps {
echo 'Hello, Maven'
sh 'mvn --version'
}
}
stage('Example Test') {
agent { docker 'openjdk:8-jre' }  steps {
echo 'Hello, JDK'
sh 'java -version'
}
}
}
}
steps {
echo 'Hello, JDK'
sh 'java -version'
}
}
}
}:agent none在Pipeline顶层定义确保执行者不会被不必要地分配。使用agent none也强制每个stage部分包含自己的agent部分
 :使用此图像在新创建的容器中执行此阶段中的步骤
:使用此图像在新创建的容器中执行此阶段中的步骤
 :在新创建的容器中使用前一个阶段的不同图像执行此阶段中的步骤
:在新创建的容器中使用前一个阶段的不同图像执行此阶段中的步骤
post
该post部分定义将在Pipeline运行或阶段结束时运行的操作。一些条件后 的块的内支持post:部分 always,changed,failure,success,unstable,和aborted。这些块允许在Pipeline运行或阶段结束时执行步骤,具体取决于Pipeline的状态。
|
需要 |
没有 |
|---|---|
|
参数 |
没有 |
|
允许 |
在顶级 |
条件
always-
运行,无论Pipeline运行的完成状态如何。
changed-
只有当前Pipeline运行的状态与先前完成的Pipeline的状态不同时,才能运行。
failure-
仅当当前Pipeline处于“失败”状态时才运行,通常在Web UI中用红色指示表示。
success-
仅当当前Pipeline具有“成功”状态时才运行,通常在具有蓝色或绿色指示的Web UI中表示。
unstable-
只有当前Pipeline具有“不稳定”状态,通常由测试失败,代码违例等引起,才能运行。通常在具有黄色指示的Web UI中表示。
aborted-
只有当前Pipeline处于“中止”状态时,才会运行,通常是由于Pipeline被手动中止。通常在具有灰色指示的Web UI中表示。
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
post {  always {
always {  echo 'I will always say Hello again!'
}
}
}
echo 'I will always say Hello again!'
}
}
} :通常,该
:通常,该post部分应放在Pipeline末端
 :后条件块包含的步骤相同的步骤部分
:后条件块包含的步骤相同的步骤部分
steps
包含一个或多个阶段指令的序列,该stages部分是Pipeline描述的大部分“工作”的位置。建议stages至少包含至少一个阶段指令,用于连续交付过程的每个离散部分,如构建,测试和部署。
|
需要 |
是 |
|---|---|
|
参数 |
没有 |
|
允许 |
只有一次,在 |
例如
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages { stage('Example') {
steps {
echo 'Hello World'
}
}
}
}
stage('Example') {
steps {
echo 'Hello World'
}
}
}
} :的
:的stages部分将典型地遵循指令,例如agent, options等
脚步
该steps部分定义了 在给定指令中执行的一系列一个或多个步骤stage。
|
需要 |
是 |
|---|---|
|
参数 |
没有 |
|
允许 |
在每个 |
例如
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example') {
steps {  echo 'Hello World'
}
}
}
}
echo 'Hello World'
}
}
}
}:该steps部分必须包含一个或多个步骤
指令
环境
该environment指令指定一系列键值对,这些对值将被定义为所有步骤的环境变量或阶段特定步骤,具体取决于environment指令位于Pipeline中的位置。
该指令支持一种特殊的帮助方法credentials(),可以通过其在Jenkins环境中的标识符来访问预定义的凭据。对于类型为“Secret Text”的凭据,该 credentials()方法将确保指定的环境变量包含Secret Text内容。对于“标准用户名和密码”类型的凭证,指定的环境变量将被设置为, username:password并且将自动定义两个附加的环境变量:MYVARNAME_USR和MYVARNAME_PSW相应的。
|
需要 |
没有 |
|---|---|
|
参数 |
没有 |
|
允许 |
在 |
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
environment {
CC = 'clang'
}
stages {
stage('Example') {
environment {  AN_ACCESS_KEY = credentials('my-prefined-secret-text')
AN_ACCESS_KEY = credentials('my-prefined-secret-text')  }
steps {
sh 'printenv'
}
}
}
}
}
steps {
sh 'printenv'
}
}
}
}:environment顶级pipeline块中使用的指令将适用于Pipeline中的所有步骤
 :在一个
:在一个environment意图中定义的一个指令stage将仅将给定的环境变量应用于该过程中的步骤stage
 :该
:该environment块具有一个帮助方法credentials(),可用于在Jenkins环境中通过其标识符访问预定义的凭据
选项
该options指令允许在Pipeline本身内配置Pipeline专用选项。Pipeline提供了许多这些选项,例如buildDiscarder,但它们也可能由插件提供,例如 timestamps。
|
需要 |
没有 |
|---|---|
|
参数 |
没有 |
|
允许 |
只有一次,在 |
可用选项
- buildDiscarder
-
持久化工件和控制台输出,用于最近Pipeline运行的具体数量。例如:
options { buildDiscarder(logRotator(numToKeepStr: '1')) } - disableConcurrentBuilds
-
不允许并行执行Pipeline。可用于防止同时访问共享资源等。例如:
options { disableConcurrentBuilds() } - skipDefaultCheckout
-
在
agent指令中默认跳过来自源代码控制的代码。例如:options { skipDefaultCheckout() } - skipStagesAfterUnstable
-
一旦构建状态进入了“不稳定”状态,就跳过阶段。例如:
options { skipStagesAfterUnstable() } - timeout
-
设置Pipeline运行的超时时间,之后Jenkins应该中止Pipeline。例如:
options { timeout(time: 1, unit: 'HOURS') } - retry
-
失败后,重试整个Pipeline指定的次数。例如:
options { retry(3) } - timestamps
-
预处理由Pipeline生成的所有控制台输出运行时间与发射线的时间。例如:
options { timestamps() }
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
options {
timeout(time: 1, unit: 'HOURS')  }
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}
}
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
} :指定一个小时的全局执行超时,之后Jenkins将中止Pipeline运行。
:指定一个小时的全局执行超时,之后Jenkins将中止Pipeline运行。
完整的INFRA-1503完整列表可供选择 参数
该parameters指令提供用户在触发Pipeline时应提供的参数列表。这些用户指定的参数的值通过该params对象可用于Pipeline步骤,具体用法见示例。
|
需要 |
没有 |
|---|---|
|
参数 |
没有 |
|
允许 |
只有一次,在 |
可用参数
string
-
字符串类型的参数,例如:
parameters { string(name: 'DEPLOY_ENV', defaultValue: 'staging', description: '') } - booleanParam
-
一个布尔参数,例如:
parameters { booleanParam(name: 'DEBUG_BUILD', defaultValue: true, description: '') }
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
}
stages {
stage('Example') {
steps {
echo "Hello ${params.PERSON}"
}
}
}
}INFRA-1503的完整列表可供参考 。
触发器
该triggers指令定义了Pipeline应重新触发的自动化方式。对于与源代码集成的Pipeline,如GitHub或BitBucket,triggers可能不需要基于webhook的集成可能已经存在。目前只有两个可用的触发器是cron和pollSCM。
|
需要 |
没有 |
|---|---|
|
参数 |
没有 |
|
允许 |
只有一次,在 |
- cron
-
接受一个cron风格的字符串来定义Pipeline应重新触发的常规间隔,例如:
triggers { cron('H 4/* 0 0 1-5') } - pollSCM
-
接受一个cron风格的字符串来定义Jenkins应该检查新的源更改的常规间隔。如果存在新的更改,则Pipeline将被重新触发。例如:
triggers { pollSCM('H 4/* 0 0 1-5') }
该pollSCM触发器仅在Jenkins 2.22或更高版本可用例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
triggers {
cron('H 4/* 0 0 1-5')
}
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}stage
该stage指令在该stages部分中,应包含步骤部分,可选agent部分或其他特定于阶段的指令。实际上,Pipeline完成的所有实际工作都将包含在一个或多个stage指令中。
|
需要 |
最后一个 |
|---|---|
|
参数 |
一个强制参数,一个用于舞台名称的字符串。 |
|
允许 |
在 |
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}工具
定义自动安装和放置工具的部分PATH。如果agent none指定,这将被忽略。
|
需要 |
没有 |
|---|---|
|
参数 |
没有 |
|
允许 |
在 |
支持的工具
- maven
- jdk
- gradle
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
tools {
maven 'apache-maven-3.0.1'  }
stages {
stage('Example') {
steps {
sh 'mvn --version'
}
}
}
}
}
stages {
stage('Example') {
steps {
sh 'mvn --version'
}
}
}
} :工具名称必须在Jenkins 管理Jenkins → 全局工具配置中预配置。
:工具名称必须在Jenkins 管理Jenkins → 全局工具配置中预配置。
when
该when指令允许Pipeline根据给定的条件确定是否执行该阶段。该when指令必须至少包含一个条件。如果when指令包含多个条件,则所有子条件必须为舞台执行返回true。这与子条件嵌套在一个allOf条件中相同(见下面的例子)。
更复杂的条件结构可使用嵌套条件建:not,allOf或anyOf。嵌套条件可以嵌套到任意深度。
|
需要 |
没有 |
|---|---|
|
参数 |
没有 |
|
允许 |
在 |
内置条件
- branch
-
当正在构建的分支与给出的分支模式匹配时执行stage,例如:
when { branch 'master' }。请注意,这仅适用于多分支Pipeline。 - environment
-
当指定的环境变量设置为给定值时执行stage,例如:
when { environment name: 'DEPLOY_TO', value: 'production' } - expression
-
当指定的Groovy表达式求值为true时执行stage,例如:
when { expression { return params.DEBUG_BUILD } } - not
-
当嵌套条件为false时执行stage。必须包含一个条件。例如:
when { not { branch 'master' } } - allOf
-
当所有嵌套条件都为真时,执行stage。必须至少包含一个条件。例如:
when { allOf { branch 'master'; environment name: 'DEPLOY_TO', value: 'production' } } - anyOf
-
当至少一个嵌套条件为真时执行stage。必须至少包含一个条件。例如:
when { anyOf { branch 'master'; branch 'staging' } }
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
branch 'production'
}
steps {
echo 'Deploying'
}
}
}
}Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
branch 'production'
environment name: 'DEPLOY_TO', value: 'production'
}
steps {
echo 'Deploying'
}
}
}
}Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
allOf {
branch 'production'
environment name: 'DEPLOY_TO', value: 'production'
}
}
steps {
echo 'Deploying'
}
}
}
}Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
branch 'production'
anyOf {
environment name: 'DEPLOY_TO', value: 'production'
environment name: 'DEPLOY_TO', value: 'staging'
}
}
steps {
echo 'Deploying'
}
}
}
}Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
expression { BRANCH_NAME ==~ /(production|staging)/ }
anyOf {
environment name: 'DEPLOY_TO', value: 'production'
environment name: 'DEPLOY_TO', value: 'staging'
}
}
steps {
echo 'Deploying'
}
}
}
}Steps
声明性Pipeline可以使用“ Pipeline步骤”引用中记录的所有可用步骤 ,其中包含一个完整的步骤列表,并附加以下列出的步骤,仅在声明性PipelinePipeline Pipeline 中支持。
script
该script步骤需要一个script Pipeline,并在声明性Pipeline中执行。对于大多数用例,script声明Pipeline中的步骤不是必须的,但它可以提供一个有用的“escape hatch”。script不平凡的大小和/或复杂性的块应该转移到共享库中。
例如:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
script {
def browsers = ['chrome', 'firefox']
for (int i = 0; i < browsers.size(); ++i) {
echo "Testing the ${browsers[i]} browser"
}
}
}
}
}
}Scripted Pipeline
Scripted Pipeline,如声明式Pipeline,构建在底层Pipeline子系统之上。不像声明,Scripted Pipeline有效地是一个通用的DSL构建与Groovy。由Groovy语言提供的大多数功能都提供给Scripted Pipeline的用户,这意味着它可以是一个非常富有表现力和灵活性的工具,可以通过这些工具来创建连续的传送Pipeline。
Flow Control
Scripted Pipeline从顶部顺序执行,与Jenkinsfile Groovy或其他语言中的大多数传统Scripted一样。因此,提供流量控制取决于Groovy表达式,例如 if/else条件,例如:
Jenkinsfile (Scripted Pipeline)
node {
stage('Example') {
if (env.BRANCH_NAME == 'master') {
echo 'I only execute on the master branch'
} else {
echo 'I execute elsewhere'
}
}
}可以管理Scripted Pipeline流控制的另一种方式是使用Groovy的异常处理支持。当步骤由于任何原因而导致异常时。处理错误行为必须使用try/catch/finallyGroovy 中的块,例如:
Jenkinsfile (Scripted Pipeline)
node {
stage('Example') {
try {
sh 'exit 1'
}
catch (exc) {
echo 'Something failed, I should sound the klaxons!'
throw
}
}
}Steps
如“ 入门指南 ”所述,Pipeline最基本的部分是“步骤”。从根本上说,步骤告诉Jenkins 要做什么,并且作为Declarative和Scripted Pipeline语法的基本构建块。
Scripted Pipeline并没有介绍这是专门针对它的语法的任何步骤; Pipeline步骤参考 ,其中包含Pipeline和插件提供的完整步骤列表。
与简单的Groovy的区别
为了提供耐久性,这意味着运行Pipeline可以在重新启动Jenkins主站后保留,Scripted Pipeline必须将数据序列化回主站。由于这个设计要求,一些Groovy成语如collection.each { item -> /* perform operation */ }没有完全支持。有关 更多信息,请参见 JENKINS-27421和 JENKINS-26481。
语法比较
当Jenkins Pipeline首次创建时,Groovy被选为基础。Jenkins长期运用嵌入式Groovy引擎,为管理员和用户提供高级脚本功能。此外,Jenkins Pipeline的实施者发现Groovy是建立现在称为“Scripted Pipeline”DSL的坚实基础。
由于它是一个功能齐全的编程环境,Scripted Pipeline为Jenkins用户提供了极大的灵活性和可扩展性。Groovy学习曲线通常不适用于给定团队的所有成员,因此,创建声明性Pipeline是为了创作Jenkins Pipeline提供一个更简单和更有见解的语法。
两者基本上是下面相同的Pipeline 子系统。它们都是“Pipeline代码”的持久实现。他们都能够使用Pipeline内置的插件或插件提供的步骤。两者都可以利用共享库
不同之处在于语法和灵活性。声明性限制了用户具有更严格和预定义结构的可用性,使其成为更简单连续输送Pipeline的理想选择。脚本化提供了极少的限制,因为Groovy本身只能对结构和语法进行限制,而不是任何Pipeline专用系统,使其成为电力用户和具有更复杂要求的用户的理想选择。顾名思义,Declarative Pipeline鼓励声明式编程模型。 尽管Scripted Pipeline遵循更命令性的编程模型。
BlueOcean介绍
本章将介绍Blue Ocean的各个方面,从仪表板到各个Pipeline运行的查看分支和结果,使用可视编辑器修改Pipeline作为代码。
本章适用于所有技能水平的Jenkins用户,但初学者可能需要参考“ 使用Jenkins ”的一些部分来了解本章涵盖的一些主题。
如果您还不熟悉Jenkins术语和功能,请参考 Jenkins入门。
什么是BlueOcean?
BlueOcean重新考虑了Jenkins的用户体验。BlueOcean由Jenkins Pipeline设计,但仍然兼容自由式工作,减少了团队成员的混乱,增加了清晰度。
- 连续交付(CD)Pipeline的复杂可视化,允许快速和直观地了解Pipeline的状态。
- Pipeline编辑器通过引导用户直观和可视化的过程创建Pipeline,使创建Pipeline平易近人。
- 个性化,以适应团队每个成员的角色需求。
- 需要干预和/或出现问题时确定精度。BlueOcean显示了Pipeline需要注意的地方,便于异常处理和提高生产率。
- 用于分支和拉取请求的本地集成可以在GitHub和Bitbucket中与其他人进行代码协作时最大限度提高开发人员的生产力。
要开始使用BlueOcean,请参阅BlueOcean入门。
FAQ
为什么存在BlueOcean?
世界已经从纯粹功能的开发人员工具转移到开发人员工具,成为“开发人员体验”的一部分。也就是说,它不再是一个单一的工具,而是开发人员在一天中使用的许多工具,以及它们如何协同工作,以实现对开发人员有益的工作流程 - 这是开发人员体验。
像Heroku,Atlassian和Github这样的开发人员工具公司已经提出了一些被认为是开发人员的经验的酒吧,开发人员越来越期待卓越的设计。近年来,开发人员正在变得越来越快地被吸引到不仅可以实现功能的工具,而且被设计为无缝地融入其工作流程中,并且是使用的乐趣。这种转变代表了Jenkins需要提升的设计和用户体验标准。
创建和可视化连续输送Pipeline对于许多Jenkins用户来说是有价值的,这在社区为满足他们的需求而创建的5+个插件中得到证明。对我们来说,这意味着需要重新审视Jenkins目前如何表达这些概念,并考虑将输送Pipeline作为Jenkins用户体验的中心主题。
这不仅仅是持续的交付概念,而且是开发人员每天使用的工具--Github,Bitbucket,Slack,HipChat,Puppet或Docker。它不仅仅是Jenkins,而是围绕着Jenkins跨越多种工具的开发人员工作流程。
新团队没有时间学习组装自己的Jenkins经验 - 他们希望通过更快地运送更好的软件来改善他们的上市时间。组装理想的Jenkins经验是我们可以一起工作,作为Jenkins用户和贡献者界定的社区。随着时间的推移,开发人员对良好用户体验的期望将会改变,Blue Ocean的使命将使Jenkins项目得以回应。
Jenkins社区已经将汗水和泪水浇灌到现有的最具技术能力和可扩展性的软件自动化工具中。今天没有任何改变Jenkins开发人员经验的事情,只是邀请别人 - 封闭的来源 - 来做这件事。
名字起源
BlueOcean名称来自 蓝海战略 ,而不是在有争议的空间中看待战略问题,而是考虑更大的无争议的空间中的问题。为了更简单的说,考虑冰球传奇韦恩格雷茨基的这个报价:“滑冰到冰球将在哪里,而不是在那里”。
BlueOcean支持自由式工作吗?
Blue Ocean旨在为Pipeline提供丰富的体验,并与您在系统中配置的任何自由式作业兼容。但是,它们将无法从为Pipeline建立的任何功能中受益 - 例如,Pipeline可视化。
由于BlueOcean设计是可扩展的,社区将来有可能将其扩展到其他工作类型。
这对于经典的Jenkins UI来说意味着什么?
其意图是,随着BlueOcean成熟,用户回到现有UI的原因将越来越少。
例如,在第一个版本中,我们将主要针对Pipeline作业。您可能可以在Blue Ocean中看到现有的非Pipeline作业,但可能无法从新UI中配置它们一段时间。这意味着用户必须跳回到经典的用户界面来配置非Pipeline作业。
这可能会有更多的例子,这就是为什么经典的用户界面在长期来看仍然是重要的。
这对我的插件意味着什么?
可扩展性是Jenkins的一个非常核心的概念,所以能够延伸BlueOceanUI是很重要的。基于一些研究,我们制定了一种方式,允许<ExtensionPoint name=..>在BlueOcean的标记中使用,为插件贡献UI(插件可以拥有自己的BlueOcean扩展点,就像今天在Jenkins一样) 。BlueOcean本身(至今为止)使用这些扩展点实现。扩展程序通常由插件提供,只要他们希望为BlueOcean经验做出贡献,他们将有一些额外的JavaScript来提供扩展。
目前正在使用哪些技术?
BlueOcean作为Jenkins插件本身构建。然而,有一个关键的区别。它为http请求提供了自己的端点,并通过不同的路径提供html / javascript,而没有现有的Jenkins UI标记/脚本。React.js和ES6用于提供Blue Ocean的JavaScript组件。受到这个优秀的开源项目(反应插件)的启发,建立了一个<ExtensionPoint>模式,允许扩展来自任何Jenkins插件(仅使用Javascript),如果它们无法加载,则会发生故障。
在哪里可以找到源代码?
源代码可以在Github上找到:
BlueOcean入门
本节将介绍如何开始使用BlueOcean。它将包括安装和配置BlueOcean插件的说明,以及如何切换和切换BlueOceanUI。
安装
BlueOcean可以安装在现有的Jenkins环境中,也可以使用Docker进行运行 。
要开始在现有的Jenkins环境中使用Blue Ocean插件,它必须运行Jenkins 2.7.x或更高版本:
- 登录到您的Jenkins服务器
- 单击边栏中的管理Jenkins然后管理插件
- 选择可用的选项卡,并使用搜索栏查找BlueOcean
- 单击“安装”列中的复选框
- 单击安装而不重新启动或立即下载并重新启动后安装
有关如何安装和Pipeline插件的深入描述,请参阅“ Pipeline插件”部分。
大多数Blue Ocean在安装后不需要额外的配置。现有管道和作业将继续照常运行。但是,Blue Ocean将首次创建或添加Pipeline,将要求访问您的存储库(Git或GitHub)的权限,以便根据这些存储库创建Pipeline。
与Docker
Jenkins项目每次发布Blue Ocean的新版本时,都会发布一个内置BlueOcean的Docker容器。该jenkinsci/blueocean 图像基于当前的Jenkins长期支持 (LTS)版本,并且已经准备就绪。
预先安装一个新的Jenkins:BlueOcean
- 确保Docker已安装。
- 跑 docker run -p 8888:8080 jenkinsci/blueocean:latest
- 浏览到本地主机:8888 /蓝色
可以使用与Jenkins项目发布的其他图像相同的配置选项来配置Blue Ocean容器 。
开始BlueOcean
一旦Jenkins环境安装了Blue Ocean,用户可以通过点击Jenkins网络用户界面的导航栏中的Open Blue Ocean开始使用Blue Ocean 。或者,用户可以直接浏览BlueOcean/blue,例如Jenkins环境的 URL http://JENKINS_URL/blue。
如果Pipeline已经存在于当前的Jenkins实例上,则会显示 Blue Ocean Dashboard。
如果这是一个新的Jenkins实例,BlueOcean将展示一个盒子,以“ Create a new pipeline”。
导航栏
BlueOcean在大多数BlueOcean的顶部使用一个通用的导航栏。它包括五个按钮:
- Jenkins - 导航到仪表板(重新加载,如果已经查看)
- Pipeline - 导航到仪表板(如果已经查看,则不执行任何操作)
- 管理 - 管理此Jenkins实例(使用Classic UI)
- 切换到“经典”UI - 切换到“经典” Jenkins UI
- 注销 - 注销当前用户,返回到Jenkins登录页面
使用标准导航栏的视图将在其下方添加另一个与该视图相关的选项。一些视图用一个特别适合该视图的通用导航栏来代替。
切换到“Classic”UI
BlueOcean可能不支持某些用户需要的遗留或管理功能。对于那些希望退出BlueOcean的用户来说,“退出”图标位于BlueOcean大部分页面的顶部。点击退出图标将导航到BlueOcean中当前页面的“经典”页面中最相关的页面。

BlueOcean中的一些链接,如管理,也将导航到经典的网页界面,当没有BlueOcean的时候。在这些情况下,BlueOcean将根据需要自动将用户带入经典的网页界面。
BlueOcean 创建Pipeline
BlueOcean可以轻松地在Jenkins创建Pipeline。Pipeline可以从现有的“Jenkinsfile”或由Blue Ocean Pipeline Editor创建的新Jenkinsfile文件创建 。Pipeline创建工作流程通过清晰,易于理解的步骤指导用户完成此过程。
启动Pipeline创建
在BlueOcean界面的顶部,是一个“ New Pipeline ”按钮,启动Pipeline创建工作流程。
在新的Jenkins实例中,没有作业或Pipeline,仪表板为空,Blue Ocean还将显示“Creat a new Pipeline”的消息框。
为Git存储库创建Pipeline
要从Git存储库创建Pipeline,首先选择“Git”作为源代码控制系统。
然后输入Git Repository的URL,并可选择选择要使用的凭据。如果下拉列表中没有显示所需的凭据,则可以使用“添加”按钮添加。
完成后,点击“创建Pipeline”。BlueOcean将查看所选存储库的所有分支,并将为包含a的每个分支启动Pipeline运行Jenkinsfile。
为GitHub存储库创建Pipeline
要从GitHub创建Pipeline,首先选择“GitHub”作为源代码控制系统。
提供一个GitHub访问令牌
如果这是当前登录用户首次运行Pipeline创建,Blue Ocean将要求 GitHub访问令牌 允许Blue Ocean访问您的组织和存储库。
如果您尚未创建访问令牌,请单击提供的链接,Blue Ocean将导航到 GitHub上的右侧页面,自动选择所需的相应权限。
选择一个GitHub帐户或组织
Github上的所有存储库都由所有者,帐户或组织分组。创建Pipeline时,Blue Ocean会反映该结构,要求用户选择拥有存储库的帐户或组织,从中添加Pipeline。
从这里,BlueOcean 提供两种风格的Pipeline创作,即 "single Pipeline" or "discover all Pipelines”。
来自单个存储库的新Pipeline
选择“新Pipeline ”允许用户为单个存储库选择并创建Pipeline 。
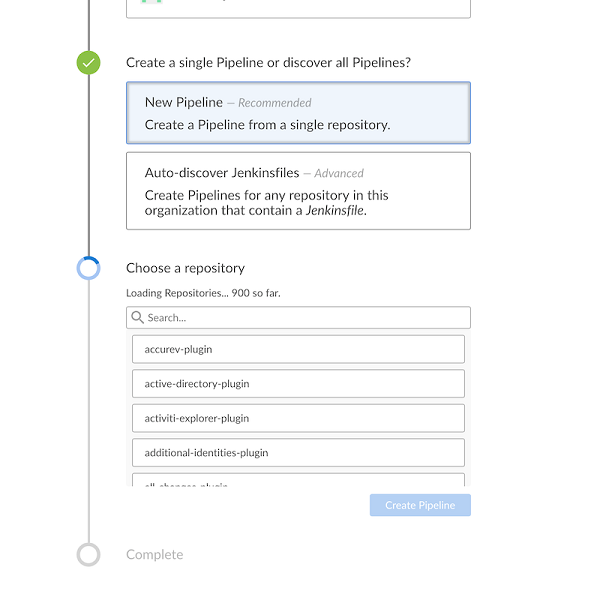
选择存储库后,Blue Ocean将扫描该存储库中的所有分支,并为根文件夹中包含“Jenkinsfile”的每个分支创建一个Pipeline。然后BlueOcean将在此过程中运行为每个分支创建的Pipeline。
如果所选存储库中没有分支机构有“Jenkins文件”,Blue Ocean将提供该存储库的“创建新Pipeline”,使用户到 BlueOcean Pipeline编辑器创建Jenkinsfile一个新的Pipeline并添加新的Pipeline。
自动发现Pipeline
选择“自动发现Pipeline”扫描属于所选所有者的所有存储库,并将为根文件夹中包含“Jenkinsfile”的每个分支创建一个Pipeline。

当这些存储库中已有Jenkinsfile条目时,此选项对于在组织中的所有存储库添加Pipeline是有用的。不包含Jenkinsfile条目的存储库将被忽略。要Jenkinsfile在没有单个存储库中创建新的存储库,请改用“ "New Pipeline”选项。
BlueOcean仪表板
BlueOcean仪表板显示了Jenkins实例上所有Pipeline的概述。仪表板是打开BlueOcean时显示的默认视图。
它由顶部的导航栏,收藏夹列表和Pipeline列表组成。
导航栏
仪表板包括顶部的标准导航栏,下面有一个本地导航栏。本地导航栏仅包含一个按钮:
- new Pipeline - 打开Pipeline创建工作流
最爱
“收藏夹”列表显示在常规Pipeline列表上方。“收藏夹”列表显示 有关分支机构的最新“运行”或包含对当前用户重要的项目的拉取请求的状态和其他关键详细信息。BlueOcean自动将分支或拉动请求添加到此列表中,当它们包含具有由当前用户创作的更改的运行时。用户还可以通过点击此列表中的实心星“★”手动从收藏夹中删除项目。
单击收藏夹列表中的项目将显示该分支或拉请求中的最新运行的 Pipeline运行详细信息。
Pipelines
“Piplines”列表显示了这个Jenkins实例中每个Pipeline的总体状态,包括Pipeline的健康状况,分支数量以及通过或失败的拉动请求,以及一个星星(实体“★”或大纲“☆” ),指示此Pipeline的默认分支是否已手动添加到此用户的收藏夹。点击星号会切换该流水线的默认分支是否显示在该用户的“收藏夹”列表中。
单击Pipeline列表中的项目将显示该 Pipeline的Pipeline活动视图。
健康图标
BlueOcean代表使用天气图标的Pipeline或Pipeline分支的总体健康状况,这取决于最近通过的建筑物的数量。仪表板上的健康图标表示整体Pipeline健康。活动视图的“ 分支”选项卡中的健康图标 表示每个分支的健康状况。
| 图标 | 健康 |
|---|---|
|
|
晴朗,超过80%的跑步 |
|
|
部分晴朗,61%至80%的跑步通过 |
|
|
多云,41%至60%的跑步 |
|
|
下雨,21%至40%的跑步 |
|
|
风暴,少于21%的跑步 |
Pipeline运行状态
BlueOcean代表运行状态,使用一整套图标。
| 图标 | 状态 |
|---|---|
|
|
进行中 |
|
|
通过 |
|
|
不稳定 |
|
|
失败 |
|
|
中止 |





BlueOcean活动视图
BlueOcean活动视图显示与一条Pipeline相关的所有活动。
导航栏
活动视图包括顶部的标准导航栏,下面有一个本地导航栏。本地导航栏包括:
- Pipeline名称 - 单击此处将显示 默认活动选项卡
- 收藏夹切换 - 单击“收藏夹”符号(星形轮廓“☆”)将向该用户的仪表板“收藏夹”列表中显示的收藏夹列表中添加一个分支 。
- 选项卡 (活动,分支,拉请求) - 单击其中一个将显示活动视图的该选项卡。
Activity
活动视图的默认选项卡“Activity”选项卡显示最近完成或正在进行的运行的列表。列表中的每一行显示运行状态,ID号,提交信息,持续时间以及运行完成的状态。单击运行将显示该运行的Pipeline运行详细信息 。“进行中”运行可以通过点击“停止”符号(圆圈中的正方形“◼”)从此列表中止。可以通过单击“重新运行”符号(逆时针箭头“↺”)重新运行已完成的运行。通过点击列表头中的“分支”下拉菜单,可以通过分支或拉动请求过滤列表。
此列表不允许编辑或标记为收藏夹。这些操作可以从“ branches ”选项卡进行。
分支
“Branches”选项卡显示当前Pipeline中已完成或正在运行的所有分支的列表。列表中的每一行对应于源控件中的一个分支,基于最近的运行,最近运行的状态,ID号,提交信息,持续时间以及运行完成时 显示分支的总体运行状况。

单击此列表中的分支将显示该分支 的最新完成或正在进行的运行的“ Pipeline运行详细信息 ”。“进行中”运行可以通过点击“停止”符号(圆圈中的正方形“◼”)从该列表中止。通过点击“播放”符号(圆圈内的三角形“▶”)可以再次运行最近运行完成的拉动请求。单击“编辑”符号(类似于铅笔“✎”)将打开 Pipeline编辑器在Pipeline上。单击“收藏夹”符号(星形轮廓“☆”)将分支添加到该用户的仪表板“收藏夹”列表中显示的收藏夹列表中。最喜欢的分支将显示一颗坚实的明星“★”
下拉请求
“Pull Requests”选项卡显示当前Pipeline的已完成或正在运行的所有拉请求的列表。(有些源代码控制系统称之为“合并请求”,其他源代码不支持它们。)列表中的每一行都对应于源代码控制中的提取请求,显示最近的运行状态,ID号,提交信息,持续时间,运行完成时间。
BlueOcean显示从分支分开提取请求,但否则“拉取请求”列表的行为与“分支”列表类似。点击此列表中的拉动请求,将显示该拉动请求 的最近完成或正在进行的运行的“ Pipeline运行详细信息 ”。“进行中”运行可以通过点击“停止”符号(圆圈中的正方形“◼”)从该列表中止。通过点击“播放”符号(圆圈内的三角形“▶”)可以再次运行最近运行完成的拉动请求。拉请求不显示“Heath Icons” ,无法编辑或标记为收藏夹。
默认情况下,当Pull Request关闭时,Jenkins将从Jenkins中删除Pipeline(将在以后进行清理),然后运行该Jelkins将无法访问该请求。可以通过更改底层多支路Pipeline作业的配置来更改。Pipeline运行详细信息视图
BlueOcean Pipeline运行详细信息视图显示与单个Pipeline运行相关的信息,并允许用户编辑或重播该运行。以下是“运行详细信息”视图部分的详细概述。
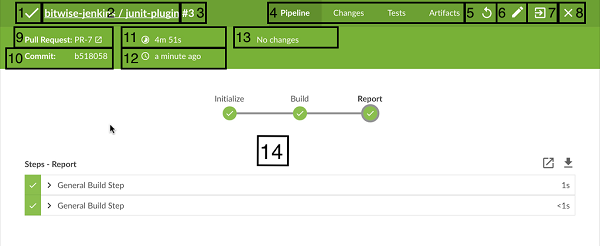
- 运行状态 - 此图标以及顶部菜单栏的背景颜色指示此Pipeline运行的状态。
- Pipeline名称 - 此运行Pipeline的名称。
- 运行编号 - 此Pipeline运行的编号。Pipeline的每个分支(和拉请求)唯一的ID号。
- 选项卡选择器 - 查看此运行的详细选项卡。默认为“ Pipeline ”。
- 重新运行Pipeline - 再次执行此运行的Pipeline。
- 编辑Pipeline - 在Pipeline编辑器中打开此运行的Pipeline。
- 转到 “经典” - 切换到“经典”UI视图,了解此运行的详细信息。
- 关闭详细信息 - 这将关闭“详细信息”视图,并将用户返回给此Pipeline的“活动”“活动”视图。
- 分支或拉式请求 - 此运行的分支或拉动请求。
- 提交ID - 此运行的提交ID。
- 持续时间 - 此运行的持续时间。
- 完成时间 - 这个运行完成了多久。
- 更改作者 - 具有此运行更改的作者姓名。
- 选项卡视图 - 显示所选选项卡的信息。
Pipeline运行状态
BlueOcean通过更改顶部菜单栏的颜色来更容易地查看当前Pipeline运行状态:蓝色为“正在进行”,绿色为“已通过”,黄色为“不稳定”,红色为“失败“,灰色为”中止“。
特殊例子
BlueOcean针对源控制中的Pipeline进行了优化,但也可以显示其他类型项目的详细信息。BlueOcean为所有支持的项目类型提供相同的选项卡,但这些选项卡可能会显示不同的信息。
Souce Control以外的Pipeline
对于不基于源代码管理的Pipeline,BlueOcean仍显示“提交标识”,“分支”和“更改”,但这些字段留空。在这种情况下,顶部菜单栏不包括“编辑”选项。
Freestyle Projects
对于Freestyle Projects,Blue Ocean仍然提供相同的选项卡,但Pipeline选项卡仅显示控制台日志输出。“Rerun”或“Edit”选项也不会显示在顶部菜单栏中。
Matrix projects
BlueOcean不支持Matrix Projects。查看Matrix项目将重定向到该项目的“Classic UI”视图。
Tabs
“运行详细信息”视图的每个选项卡提供有关运行的特定方面的信息。
Pipeline
这是默认选项卡,并给出了此Pipeline运行流程的总体视图。它显示每个阶段和并行分支,这些阶段的步骤,以及这些步骤的控制台输出。上图概述显示了成功的Pipeline运行。如果运行过程中的特定步骤失败,则该选项卡将自动默认为从失败的步骤显示控制台日志。下图显示了一个失败的运行。
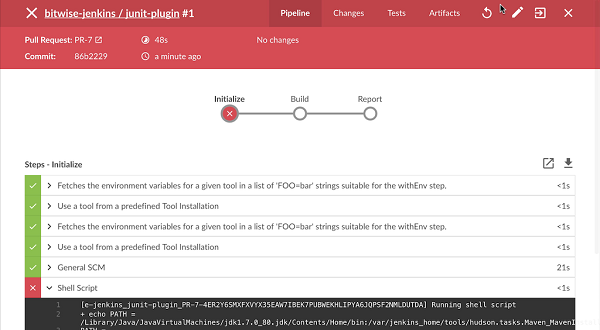
Changes
Tests
“tests”选项卡显示有关此运行的测试结果的信息。如果测试结果发布步骤(例如“发布JUnit测试结果”(junit))步骤,此选项卡将仅包含信息。如果没有记录任何结果,这个表将会说,如果所有测试通过,该选项卡将报告通过测试的总数。在故障的情况下,该选项卡将显示故障中的日志详细信息,如下所示。
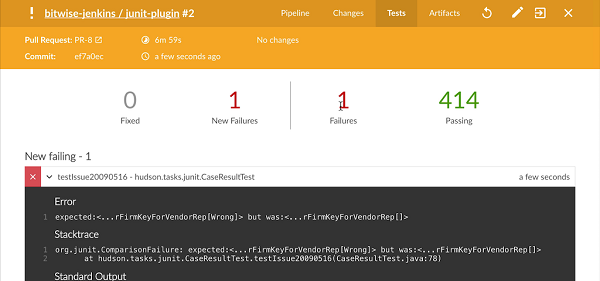
当前一个运行失败并且当前的运行修复了这些故障时,此选项卡将记录固定的文本并显示其日志。

Artifacts
“Artifacts”选项卡显示使用“存档工件”(archive)步骤保存的任何工件的列表。单击列表中的项目将下载它。运行中的完整输出日志可从此列表中下载。
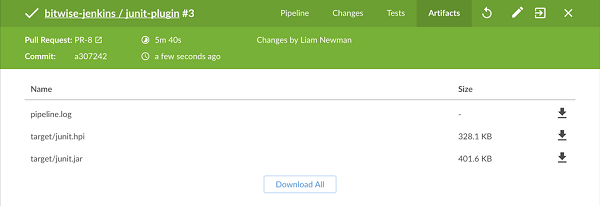
Pipeline编辑
BlueOcean Pipeline编辑器是任何人开始在Jenkins创建Pipeline的最简单的方法。这也是现有Jenkins用户开始采用Pipeline的好方法。
编辑器允许用户创建和编辑声明性Pipeline,添加可以同时运行的阶段和并行化任务,这取决于他们的需要。完成后,编辑器将管道保存为源代码存储库Jenkinsfile。如果Pipeline需要再次更换,Blue Ocean可以轻松地跳回到可视化编辑器中以随时修改Pipeline。
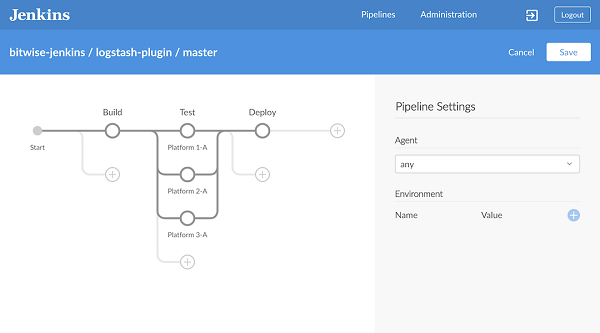
开始编辑
要使用编辑器,用户必须首先 在Blue Ocean中创建Pipeline, 或者已在Jenkins中创建一个或多个现有Pipeline。如果编辑现有Pipeline,则该Pipeline的凭据必须允许将更改推送到目标资源库。
编辑器可以通过以下方式启动:
- 仪表板“New Pipeline”按钮
- 活动视图单次运行
- Pipeline运行详细信息
限制
- 仅基于SCM的声明性Pipeline
- 证书必须具有写入权限
- 与声明式Pipeline没有完全一致
- Pipeline重新排序和注释已删除
导航栏
Pipeline编辑器包括顶部的标准导航栏,下面有一个本地导航栏。本地导航栏包括:
- Pipeline名称 - 这将包括分支依赖或如何
- 取消 - 放弃对Pipeline进行的更改。
- 保存 - 打开保存Pipeline对话框。
Pipeline设置
默认情况下,编辑器的右侧显示“Pipeline Settings”。可以通过单击Stage编辑器 中不是Stage或“Add Stage”按钮x之一的任何位置来访问此工作表
Agent
“代理”部分控制Pipeline将使用什么代理。这与“代理”指令相同。
环境
“环境”部分允许我们为Pipeline设置环境变量。这与“环境”指令相同。
Stage editor
左侧编辑器屏幕包含Stage编辑器,用于创建Pipeline的阶段。
可以通过单击" button to the right of an existing stage. Parallel stages can be added by clicking the "现有Stage下方的“ ”按钮将阶段添加到Pipeline。可以使用Stage配置表中的上下文菜单删除阶段。
Stage编辑器将在设置完毕后显示每个Stage的名称。包含不完整或无效信息的阶段将显示警告符号。Pipeline在编辑时可能会出现验证错误,但在修复错误之前无法保存。
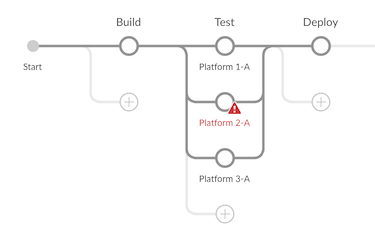
Stage配置
在Stage编辑器中选择Stage将打开右侧的“Stage配置”工作表。在这里,我们可以更改Stage的名称,删除Stage,并向Stage添加步骤。
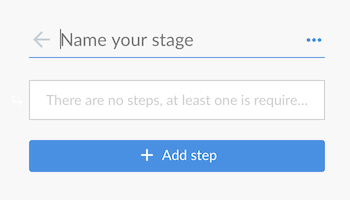
Stage的名称可以设置在Stage配置表的顶部。上下文菜单(右上角三个点)可用于删除当前阶段。单击“添加步骤”将显示可用步骤类型的列表,其顶部有搜索栏。可以使用步骤配置表中的上下文菜单删除步骤。添加步骤或选择现有步骤将打开步骤配置表。
步骤配置
从Stage配置表中选择一个步骤将打开“步骤Stage”页。
此工作表将根据步骤类型而有所不同,包含所需的任何字段或控件。步骤的名称不能更改。上下文菜单(右上方的三个点)可用于删除当前步骤。包含不完整或无效信息的字段将显示警告符号。Pipeline在编辑时可能会出现验证错误,但在修复错误之前无法保存。
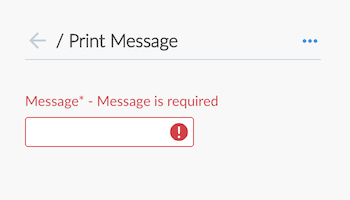
保存Pipeline对话框
为了运行,Pipeline的更改必须保存在源代码控制中。“保存Pipeline”对话框控制对源代码控制的更改的保存。
更改的有用描述可以添加或留空。该对话框还支持保存更改相同的分支或输入新的分支以保存到。点击“保存并运行”将保存对Pipeline的任何更改作为新的提交,将根据这些更改启动新的Pipeline运行,并将导航到此Pipeline的 活动视图。
Securing Jenkins
在Jenkins 1.x的默认配置中,Jenkins不执行任何安全检查。这意味着Jenkins启动流程和访问本地文件的能力可供任何可以访问Jenkins Web UI和更多内容的用户使用。
Securing Jenkins 有两个方面。
- 访问控制,用于确保用户在访问Jenkins并对其活动进行授权时进行身份验证。
- 保护Jenkins 免受外部威胁
访问控制
您应该锁定对Jenkins UI的访问权限,以便用户进行身份验证,并向他们提供适当的权限。此设置主要由两个轴控制:
- 安全领域,它决定了用户及其密码,以及用户所属的组。
- 授权策略,决定谁可以访问什么。
这两个轴是正交的,需要单独配置。例如,您可以选择使用外部LDAP或Active Directory作为安全领域,并且您可以选择“每次登录后的所有人都可以访问”模式进行授权策略。或者您可以选择让Jenkins运行自己的用户数据库,并根据权限/用户矩阵执行访问控制。
- 快速简单的安全性 - 如果你正在运行Jenkins java -jar jenkins.war,只需要一个非常简单的设置
- 标准安全设置 ---讨论了Jenkins运行自己的用户数据库并进行更细粒度的访问控制的最常见的设置
- Apache前端的安全性 - 在Apache后面运行Jenkins,并在Apache中执行访问控制,而不是Jenkins
- 验证脚本客户端 ---如果您需要以编程方式访问启用安全性的Jenkins Web UI,请使用BASIC auth
- 基于矩阵的安全性|基于矩阵的安全性 - 授予和拒绝更细粒度的权限
保护Jenkins的用户免受其他威胁
Jenkins还有其他安全子系统可以保护Jenkins和Jenkins的用户免受间接攻击。
以下主题讨论默认关闭的功能。我们建议您先阅读并对它们采取行动。
- CSRF保护 ---防止对防火墙内运行的Jenkins进行远程攻击
- 建立管理的安全隐患 - 保护Jenkins管理免受恶意构建
- 从属于主访问控制 ---保护Jenkins管理免受恶意构建代理
以下主题讨论默认情况下已启用的其他安全功能。当他们造成问题时,您只需要查看它们。
- 配置内容安全策略 ---保护Jenkins的用户免受恶意构建
- 标记格式 ---保护Jenkins的用户免受Jenkins恶意用户的伤害
Disabling Security
人们可能会意外地建立安全领域/授权,使您无法再重新配置Jenkins。
当这种情况发生时,您可以通过以下步骤解决此问题:
- 停止Jenkins(最简单的方法是窃取servlet容器。)
- 转到$JENKINS_HOME在文件系统中找到config.xml文件。
- 在编辑器中打开此文件。
- 查找<useSecurity>true</useSecurity>此文件中的元素。
- 替换true为false
- 删除元素authorizationStrategy和securityRealm
- 开始Jenkins
- 当Jenkins回来时,它将处于不安全的模式,每个人都可以完全访问系统。
如果这仍然不起作用,请尝试重命名或删除config.xml。