一、基础使用
- 常用命令
keys,expire(过期),ttl(查看生存时间),set,select,dbsize,flushdb(删除当前库),flushall(删除所有), get,append,strlen,setnx(不存在了加),incr(增1),decr,incrby(增n) mset(同时设置多个,同时成功,同时失败) getrange k1 0 4(获取k1 0-4位的字符), setrange(设置指定位以后的值), setex k1 10 sad 设置k1值是sad 10秒过期, getset一边查一边赋值 HyperLogLog 计数器 (pfadd 和 pfcount) scan 0 match key99* count 1000 scan 参数提供了三个参数,第一个是 cursor 整数值,第二个是 key 的正则模式,第三个是遍历的 limit hint。 第一次遍历时,cursor 值为 0,然后将返回结果中第一个整数值作为下一次遍历的 cursor。一直遍历到返回的 cursor 值为 0 时结束。 这个 limit 不是限定返回结果的数量,而是限定服务器单次遍历的字典槽位数量(约等于)
- 远程连接
redis-cli -h 127.0.0.1 -p 6379 -a "mypass" config get *,config set requirepass "123456" auth + 密码
- 数据结构
-
- List
lpush/rpush 从左/右插入值 lpop/rpop 从左/右吐值 rpoplpush k1 k2 lrange k1 0 -1取所有 lindex k1 0 取第0个 linsert k1 before 4 A 在4前面插入A lrem k1 2 A 删除两个A)
- Set
sadd 只插入不存在的无序,不重复 smembers k1 取所有 sismember k1 v1 是否存在v1 scard k1 获取长度 srem k1 ...删除 spop k1 随机吐出一个值 srandmember k1 n 随机取出n个值, sinter,sunion,sdiff 交集并集差集)
- Hash
hset hbc:1010 name cjy,
hget,hmset,hexists,
hkeys 获取所有field,
hvals 获取所有values, hincrby增量,
hsetnx hbc:1010 age 25 不存在时设置值, ) - Zset
zadd k1 100 a 插入评分为100的a zrange k1 0 -1 查看所有 zrangebyscore k1 100 200 在评分范围的查找 zrevrangebyscore k1 200 100倒序 zincrby k1 1000 a 给值a的评分增加1000 zcount k1 100 200 在评分范围的数量 zrevrange k1 0 9 withscores显示前10名从大到小
- List
二、程序使用
- stringRedisTemplate
redisTemplate.opsForValue(); //操作字符串 redisTemplate.opsForHash(); //操作hash redisTemplate.opsForList(); //操作list redisTemplate.opsForSet(); //操作set redisTemplate.opsForZSet(); //操作有序set
- 常用操作
stringRedisTemplate.opsForValue().set("test", "100",60*10,TimeUnit.SECONDS);//向redis里存入数据和设置缓存时间 stringRedisTemplate.boundValueOps("test").increment(-1);//val做-1操作 stringRedisTemplate.opsForValue().get("test")//根据key获取缓存中的val stringRedisTemplate.boundValueOps("test").increment(1);//val +1 stringRedisTemplate.getExpire("test")//根据key获取过期时间 stringRedisTemplate.getExpire("test",TimeUnit.SECONDS)//根据key获取过期时间并换算成指定单位 stringRedisTemplate.delete("test");//根据key删除缓存 stringRedisTemplate.hasKey("546545");//检查key是否存在,返回boolean值 stringRedisTemplate.opsForSet().add("red_123", "1","2","3");//向指定key中存放set集合 stringRedisTemplate.expire("red_123",1000 , TimeUnit.MILLISECONDS);//设置过期时间 stringRedisTemplate.opsForSet().isMember("red_123", "1")//根据key查看集合中是否存在指定数据 stringRedisTemplate.opsForSet().members("red_123");//根据key获取set集合 - StringRedisTemplate与RedisTemplate区别点
StringRedisTemplate继承RedisTemplate 数据是不共通的。 RedisTemplate使用的是JdkSerializationRedisSerializer 存入数据会将数据先序列化成字节数组然后在存入Redis数据库。 StringRedisTemplate使用的是StringRedisSerializer
三、原理&深入
- RDB vs AOF
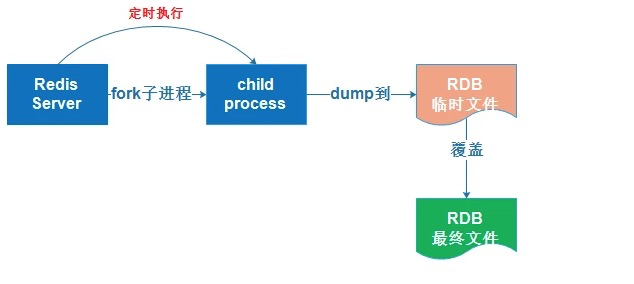
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
RDB的优势和劣势:
RDB存在哪些优势呢? 1). 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。 2). 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。 3). 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。 4). 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。 RDB又存在哪些劣势呢? 1). 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。 2). 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。

AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
AOF的优势和劣势:
AOF的优势有哪些呢? 1). 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。 2). 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。 3). 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。 4). AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。 AOF的劣势有哪些呢? 1). 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。 2). 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
-
持久化配置
-
- RDB持久化配置
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息: save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。 save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。 save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
- AOF持久化配置
在Redis的配置文件中存在三种同步方式,它们分别是: appendfsync always #每次有数据修改发生时都会写入AOF文件。 appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。 appendfsync no #从不同步。高效但是数据不会被持久化。
- RDB持久化配置
3. 哨兵模式
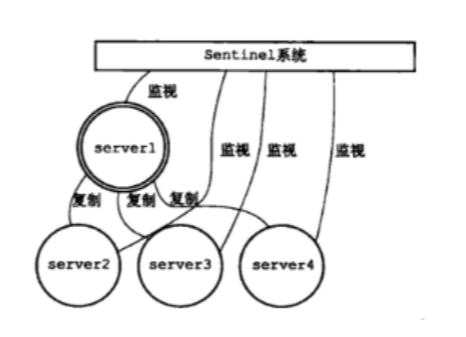
1. 哨兵模式,就类似于zookeeper的选举模式一样,5个服务器需要一个管理的主机,他们需要选举出来,这就是哨兵模式 2. 集群分片 比如 5主5从,也就是说 数据过来之后会均匀的分配到5台服务器上面,5台服务器上面的数据是不同的,但是每个服务器都有一个从服务器,上面的数据跟这一台主服务器的数据是一样的; 也就是说,对于这5对服务器总体来说,这就是集群分片模式,而对于这5对服务器的每一对,都是一个主从模式
四、问题解决方案
- 缓存
-
- 缓存穿透
key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。 比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
解决方案:
布隆过滤器 : key hash到一个bitmap中,每次key判断在bitmap是否存在 空值也做缓存,缓存时间短
- 缓存击穿
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来, 这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:
mutex key: public String get(key) { String value = redis.get(key); if (value == null) { //代表缓存值过期 //设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功 value = db.get(key); redis.set(key, value, expire_secs); redis.del(key_mutex); } else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可 sleep(50); get(key); //重试 } } else { return value; } } - 缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
解决方案:
三种方案:使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一种被称为“二级缓存”的解决方法。 事前解决方案 * 保证缓存层服务高可用性 事中解决方案: * 对缓存访问进行 资源隔离(熔断)、Fail Silent 降级 * ehcache本地缓存 * 对源服务访问进行 限流、资源隔离(熔断)、Stubbed 降级。 事后解决方案 * Redis数据备份和恢复 * 快速缓存预热
- 缓存穿透
2. redis事务
-
-
multi/exec/discard。multi 指示事务的开始,exec 指示事务的执行,discard 指示事务的丢弃。
-