经查阅,将资料整理如下:
一、冒泡排序
1、算法简介
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
2、算法原理
(1)比较相邻的元素。如果第一个比第二个大,就交换他们两个。
(2)对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
(3)针对所有的元素重复以上的步骤,除了最后一个。
(4)持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
3、算法分析
(1)时间复杂度

(2)算法稳定性
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,我想你是不会再无聊地把他们俩交换一下的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
4、算法描述

二、二分查找
1、算法简介
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
2、算法要求
(2)必须按关键字大小有序排列
3、算法复杂度
二分查找的基本思想是将n个元素分成大致相等的两部分,取a[n/2]与x做比较,如果x=a[n/2],则找到x,算法中止;如果x<a[n/2],则只要在数组a的左半部分继续搜索x,如果x>a[n/2],则只要在数组a的右半部搜索x.
时间复杂度无非就是while循环的次数!
总共有n个元素,
渐渐跟下去就是n,n/2,n/4,....n/2^k(接下来操作元素的剩余个数),其中k就是循环的次数
由于你n/2^k取整后>=1
即令n/2^k=1
可得k=log2n,(是以2为底,n的对数)
所以时间复杂度可以表示O()=O(logn)
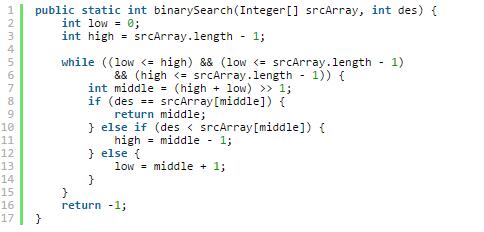
4、代码示例