selenium是可以模拟浏览器操作。
有些爬虫是异步加载的,通过爬取网页源码是得不到需要的内容。所以可以模拟浏览器去登陆该网站进行爬取操作。
需要安装selenium通过pip install xxx安装,如果你使用的Anaconda3,可以使用conda install xxx这些都是可以
值得一提的是,需要下载chromdriver,就是chrome浏览器的驱动。百度搜索下载,下载之前看你的chrome的版本是几,应该下载比你浏览器的版本更高的驱动版本。
比如:我的chrome是74,那么你可以下载74以后的,75等。
然后把chromedriver放在python安装程序主目录下,
也就是说,你的python.exe在哪个目录,你把chromedriver放在那就可以了。
import time from selenium import webdriver from selenium.webdriver.common.by import By """ 使用selenium进行模拟登陆 1.初始化ChromDriver 2.打开163登陆页面 3.找到用户名的输入框,输入用户名 4.找到密码框,输入密码 5.提交用户信息 """ name = 'xxxxxxxx' passwd = 'xxxxxx' driver = webdriver.Chrome() driver.get('https://mail.163.com/') # 将窗口调整最大 driver.maximize_window() # 休息5s time.sleep(5) current_window_1 = driver.current_window_handle print(current_window_1) button = driver.find_element_by_id('lbNormal') button.click() driver.switch_to.frame(driver.find_element_by_xpath("//iframe[starts-with(@id, 'x-URS-iframe')]")) email = driver.find_element_by_name('email') #email = driver.find_element_by_xpath('//input[@name="email"]') email.send_keys(name) password = driver.find_element_by_name('password') #password = driver.find_element_by_xpath("//input[@name='password']") password.send_keys(passwd) submit = driver.find_element_by_id("dologin") submit.click() time.sleep(10) print(driver.page_source) driver.quit()
问题:
在使用过程中,始终iframe这个元素,提示driver.find_element_by_name找不到。
然后通过chrome的开发者工具,找了iframe.如下图:
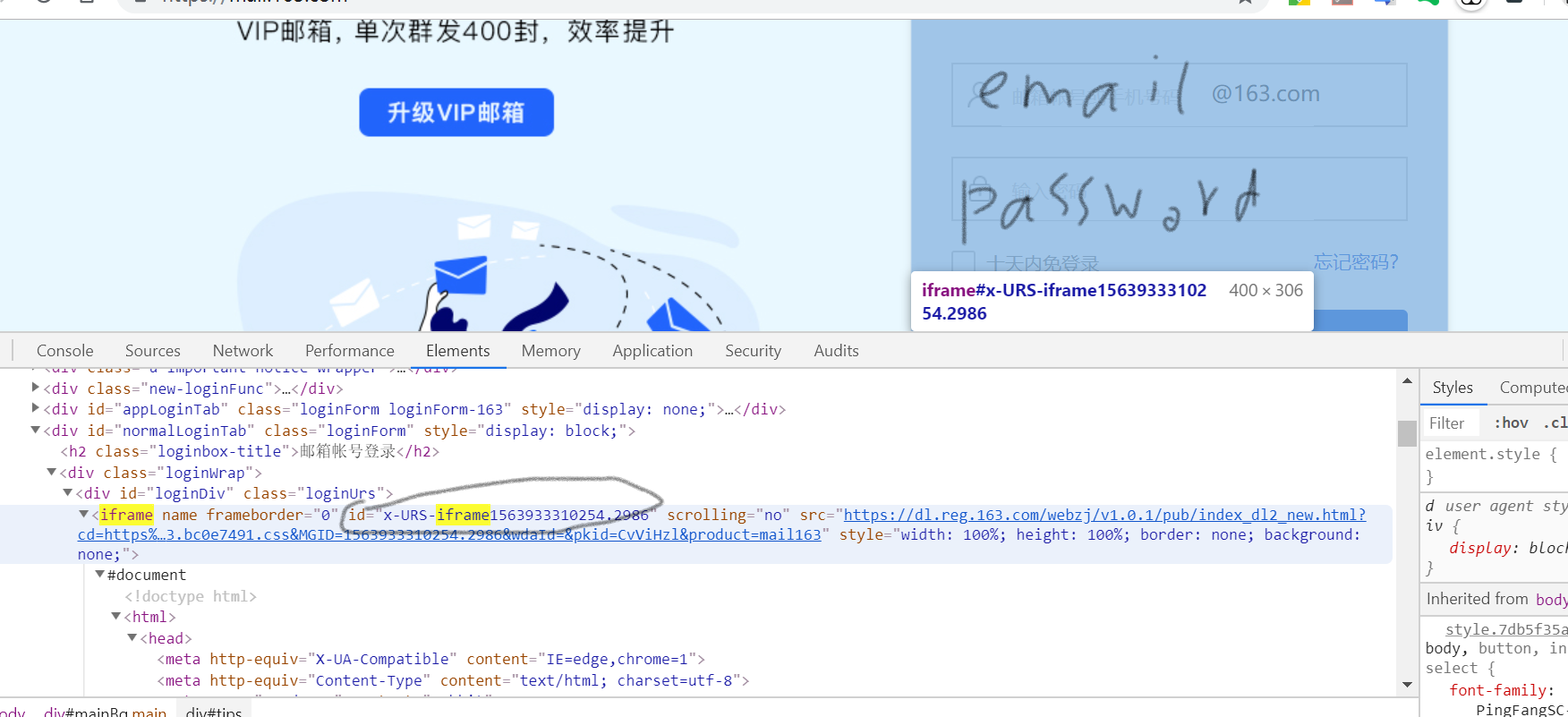
邮箱输入框和密码输入框在iframe中。但是这个iframe id="x-URS-iframe156xxxxxx"后面的数字是一个时间戳。是唯一的,而且name竟然也是设置为“”,
所以通过driver.find_element_by_name通过属性获取或者driver.find_element_by_id通过id获取都是提示找不到。
那该怎么办???
driver.find_element_by_xpath("//iframe[starts-with(@id, 'x-URS-iframe')]")
通过使用xpath获取,并且是ids属性是“x-URS-iframe”开头的,就可以动态的获取这个iframe。
问题来了,为什么要获取iframe。
因为看代码有一个
driver.switch_to.frame()
切换界面,因为通过开发者工具可以看到,输入密码和用户名都是在iframe下,如果不切换到这个iframe.那么始终是找不到。
还有一个问题就是,
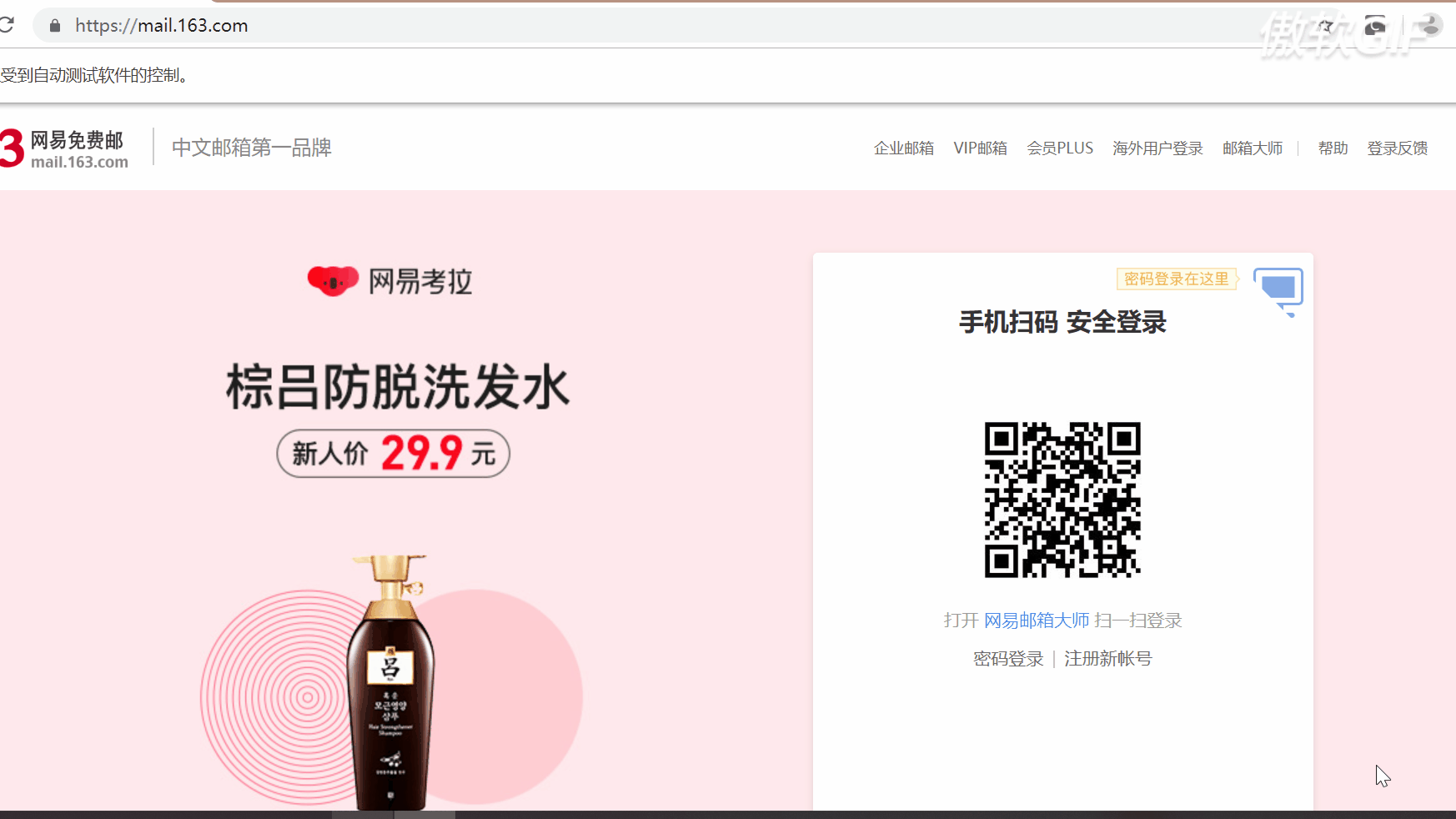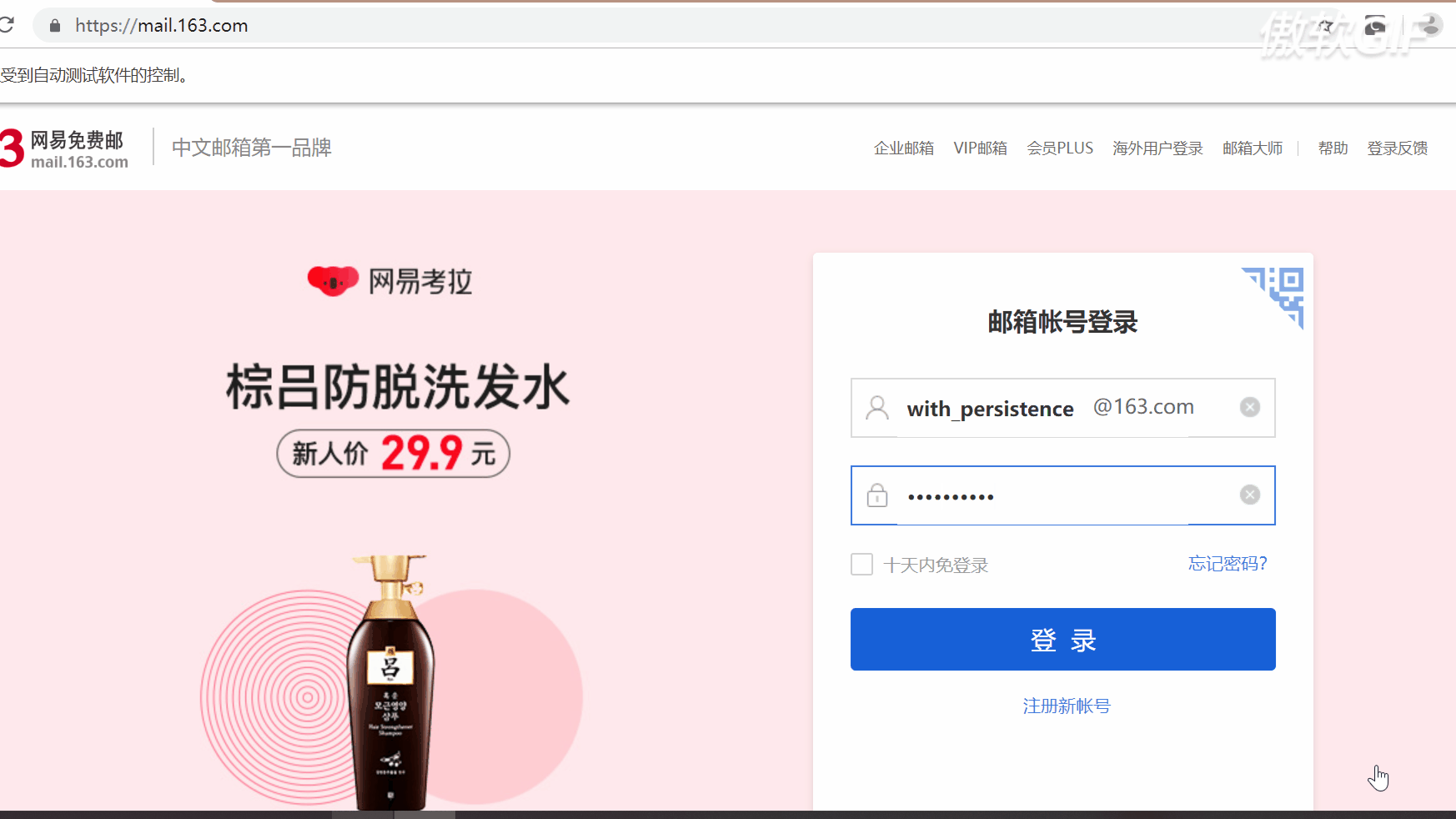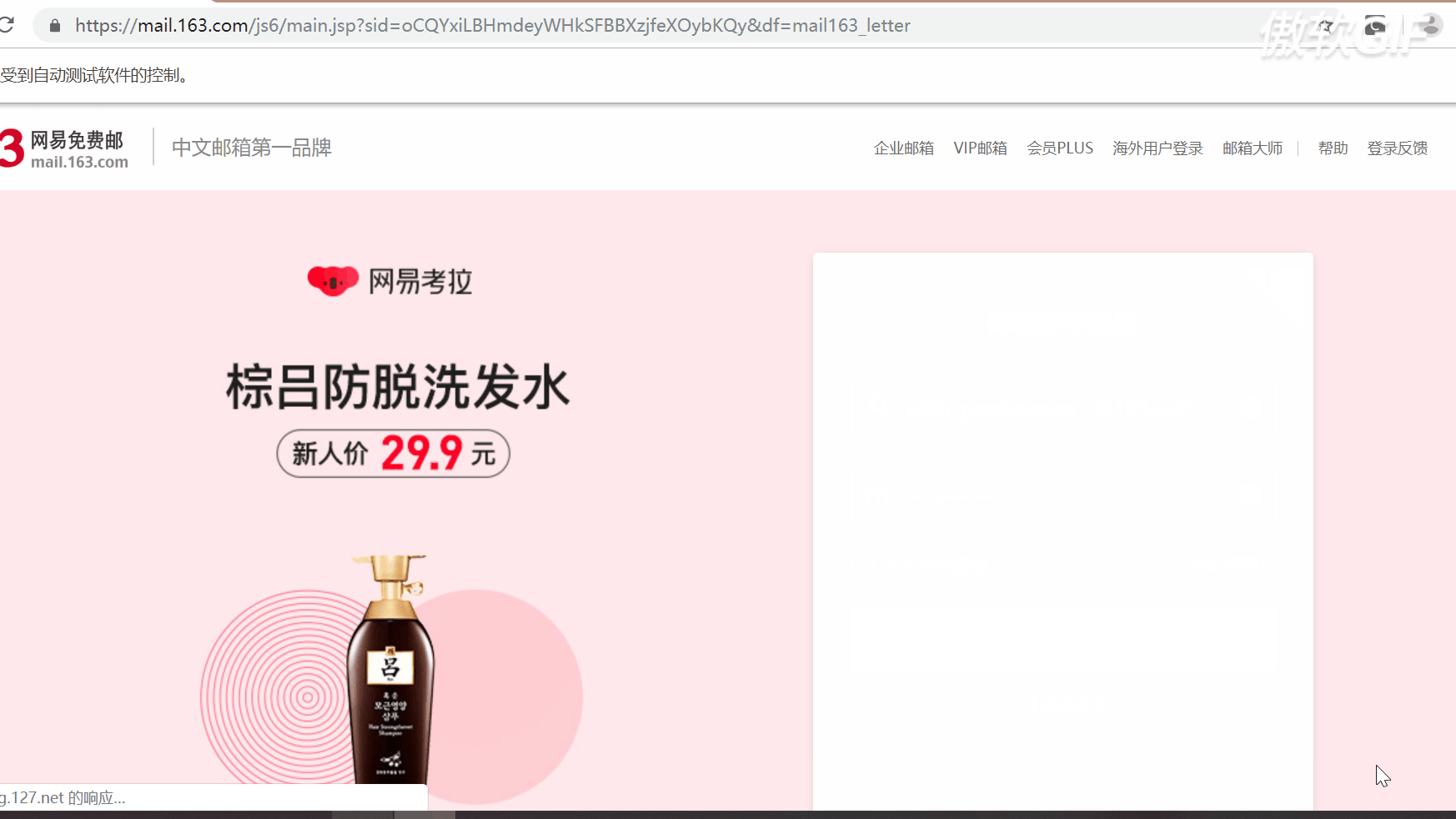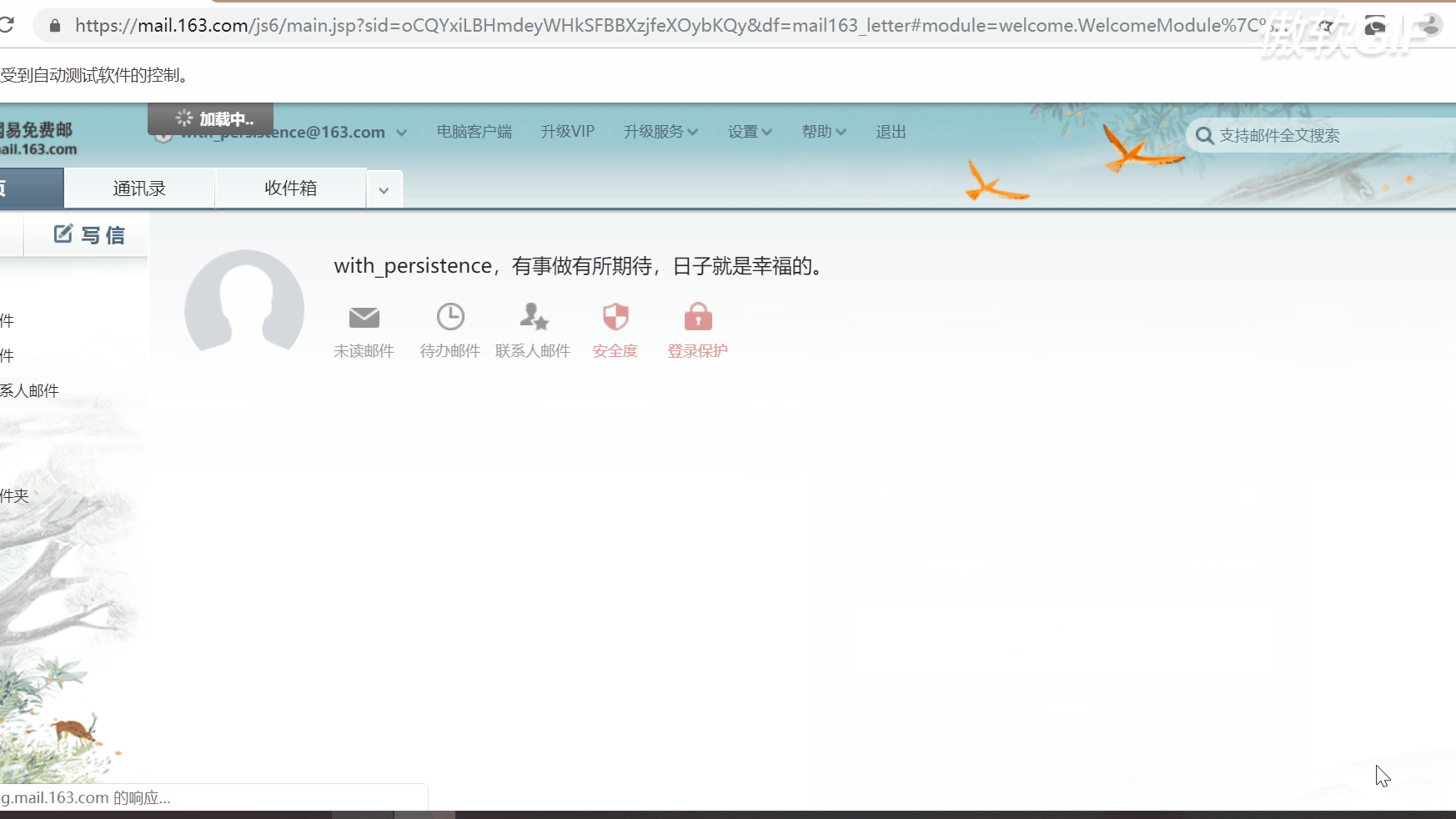
通过浏览器登陆163,开始显示的是一个扫描QRcode二维码进入邮箱。我们想要的是输入邮箱和密码的界面。
所以代码中:
button = driver.find_element_by_id('lbNormal')
button.click()
这个就是获取切换的界面的按钮,点击切换到输入界面。
以下是模拟,仅供参考