1、码云地址
2、PSP表格
| PSP2.1 | 个人开发流程 | 预估耗费时间(分钟) | 实际耗费时间(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 5 |
| · Estimate | 明确需求和其他相关因素,估计每个阶段的时间成本 | 5 | 0 |
| Development | 开发 | 200 | 210 |
| · Analysis | 需求分析 (包括学习新技术) | 10 | 15 |
| · Design Spec | 生成设计文档 | 15 | 10 |
| · Design Review | 设计复审 | 10 | 10 |
| · Coding Standard | 代码规范 | 0 | 0 |
| · Design | 具体设计 | 20 | 25 |
| · Coding | 具体编码 | 90 | 80 |
| · Code Review | 代码复审 | 10 | 5 |
| · Test | 测试(自我测试,修改代码,提交修改) | 20 | 50 |
| Reporting | 报告 | 10 | 10 |
| · | 测试报告 | 10 | 5 |
| · | 计算工作量 | 5 | 5 |
| · | 并提出过程改进计划 | 0 | 0 |
3、解体思路描述:
整体思路:
读取文件,把文本内容转换为字符串,将字符串作为参数传入到方法中,去然后在去做字符数、有效行数的统计。然后在将此字符串在进行截取,把它转为以空格为分隔符的字符串,做单词总数和词频的统计。
各功能思路:
- 统计文件的字符数:将文本转换为字符数组,然后遍历数组,判断是否为合法字符,设置统计变量,然后返回字符数。
- 统计有效行数:将字符串作为参数传入,用String.split()方法以回车换行符为正则表达式截取,遍历字符串数组,将长度大于0的记为有效行数,返回有效行数。
- 截取有效单词:先文本字符串作为参数传入,转为字符数组。创建StringBuffer对象,遍历数组,判断字符是否为英文字符或空格,若是用StringBuffer拼接,否则则拼接上一个空格符。得到一个一个以空格为分隔符的字符串,在以空格截取字符串,转为字符串数组,遍历数组,判断是否满足前四个字母为英文的单词。若是则再用StringBuffer拼接,否则跳过。最后返回一个以有效单词组成,以空格为分隔符的字符串。
- 统计单词总数:将有效单词字符串作为参数传入,用String.spilt()方法分割,返回字符串数组长度,及有效单词总数。
- 统计单词出现频率:用String.spilt()方法分割,遍历数组。使用map来统计词频,先判断Map中是否存在相同单词,如果不存在,则存入Map并将value置为1,若存在,则将其value值加1。最后返回map。
- 词频排序:使用比较器排序。
4、设计实现过程
1.类设计:
- FileRead类:读取文件。
- Word类:实现功能
- Test类:程序入口,测试。
2.FileRead类:
- fileRead方法:按行读取文件,拼接各行数据,返回文本字符串。
3.Word类:
- getCharCount()方法:统计字符数
- getLineCount()方法:统计有效行数
- getWord()方法:截取有效单词,为统计单词出现次数、单词总数服务
- getWordCount()方法:统计单词总数
- getWordFrequency()方法:统计单词出现频率
- sort()方法:对词频排序
5、代码说明
1、getCharCount()方法(统计字符数)
public int getCharCount(String text) {
char[] c = text.toCharArray();
int count = 0;
for (char cTemp : c) {
if ((cTemp >= 32 && cTemp <= 126) || cTemp == '
' || cTemp == '
' || cTemp == ' ') {
count++; // 判断合法字符
}
}
return count;
}
2、public int getLineCount()方法(统计有效行数)
public int getLineCount(String text) {
String[] len = text.split("
"); //以回车为分隔符
int count = 0;
for (String str : len) {
if (str.length() > 0) { //有效行
count++;
}
}
return count;
}
3、public String getWord()方法(截取合法单词)
public String getWord(String text) {
char[] c = text.toCharArray();
StringBuffer str = new StringBuffer();
for (int i = 0; i < c.length; i++) {
if ((c[i] >= 48 && c[i] <= 57) || (c[i] >= 65 && c[i] <= 90) || (c[i] >= 97 && c[i] <= 122) || c[i] == 32) {
str.append(c[i]); // 截取以字母数字组成的单词
} else {
if (i == 0) {
continue;
}
str.append(" "); // 单词间的分隔符
}
}
String textTemp = str.toString();
str.setLength(0);
String[] word = textTemp.split(" +");
for (String s : word) {
if (s.length() < 4) {
continue;
} else {
for (int i = 0; i < 4; i++) { // 判断前四个字母是英文字母
boolean flag = false;
if (!(s.charAt(i) >= 'A' && s.charAt(i) <= 'Z' || s.charAt(i) >= 'a' && s.charAt(i) <= 'z')) {
break;
}
if (i == 3) {
str.append(s + " ");
}
}
}
}
textTemp = str.toString();
System.out.println(textTemp);
return textTemp; // 返回单词字符串,以空格为分隔符
}
4、getWordCount()方法(统计单词总数)
public int getWordCount(String text) {
if(text.length() == 0) {
return 0;
}
String[] word = text.split(" +");
return word.length;
}
5、getWordFrequency()(统计单词出现频率)
public Map getWordFrequency(String text) {
Map<String, Integer> map = new HashMap<>();
String[] strTemp = text.split(" +");
for (String s : strTemp) {
if (!map.containsKey(s)) { //单词首次出现,存入map,置值为1
map.put(s, 1);
else {
map.put(s, (map.get(s) + 1)); //单词已存在,值加1
}
}
return map;
}
6、sort()方法(排序)
public List sort(Map map) {
List<Map.Entry<String, Integer>> arraylist = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(arraylist, new Comparator<Map.Entry<String, Integer>>() { //重写比较器
public int compare(Map.Entry<String, Integer> obj1, Map.Entry<String, Integer> obj2) {
return ((Integer) obj2.getValue()).compareTo((Integer) obj1.getValue());
}
});
return arraylist;
}
6、单元测试
设计了4个测试点:
-
测试文件内容为空
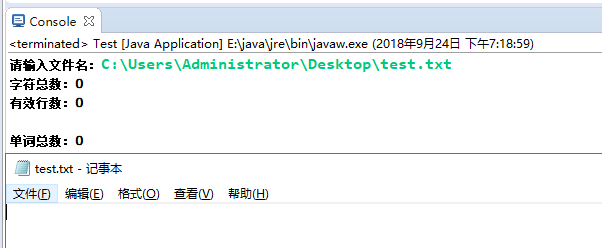
-
测试单词都是不合法
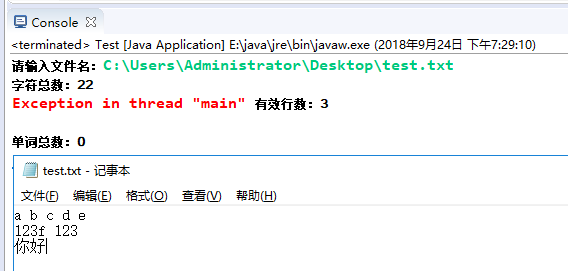
-
测试单词都为合法
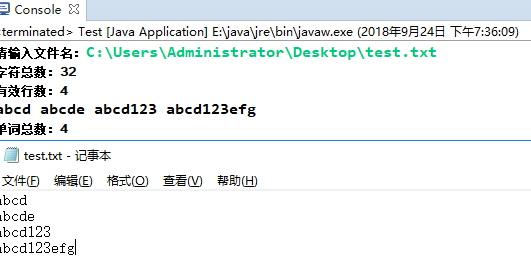
-
测试文本中含合法、不合法单词
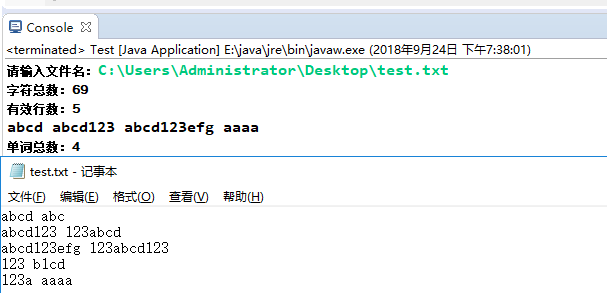
7、实验心得
这次实验小项目让自己感到专业知识的欠缺,倍感折磨,但却收益良多。对java的重温,认识到了在开发前作好规划的重要性,一定不能是想到一点写一点。在单元测试方面确实有很大的欠缺,一窍不通,还是习惯做断点测试。对此我将不断的去学习,争取下次做得更好。