之前的爬虫用的都是java,这次想利用python来爬取网页信息。
首先进入豆瓣中:https://movie.douban.com/
右击检查,选择network中xhr属性,点击爱情分类的电影

看到这里对应的request url的响应网页,复制https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start=0&limit=20
查看对应request header:
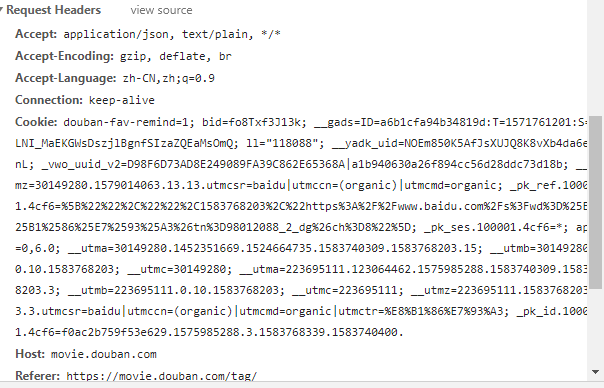
将对应的信息复制之后,设置为json格式的header以便python发送请求
接着将代码写入对应的python中,html是自己定义的一个模块

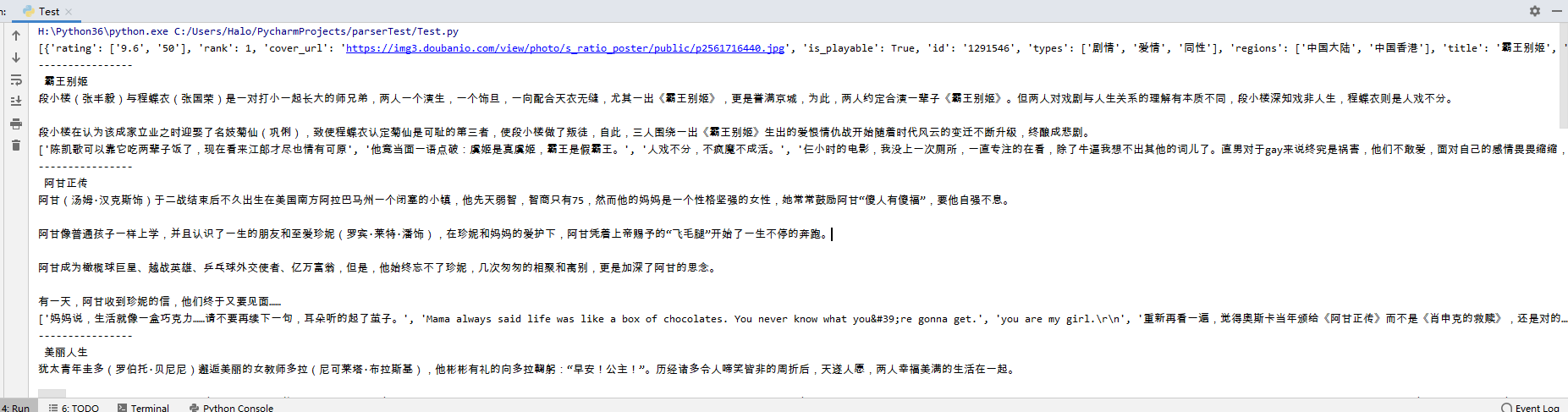
执行之后输入json结果
发现有错误
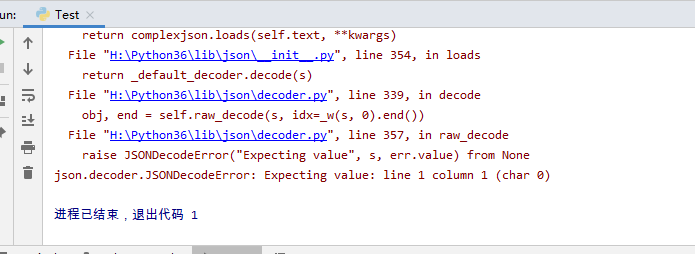
检查片头得返回的结果采用了压缩格式

将对应的header中的参数删除了之后再次执行
显示出对应爬取的json的信息

可以看到信息已经成功显示。
我们将信息放到对应的标准化的在线解析json的网站看正不正确

可以看到爬出来的数据的豆瓣电影中爱情的电影一致
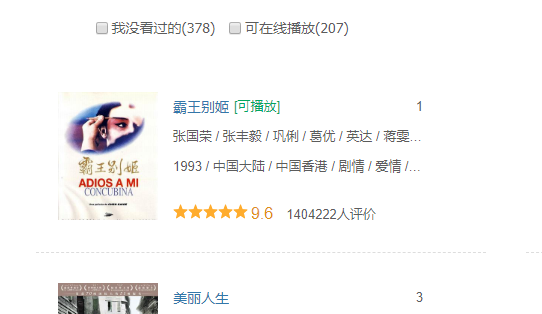
接着对网页中的对应链接进行提取
可以看到对应电影网页的url网址在json中的url中

对url中的信息进行遍历,查看是否能正确输出信息
输出的信息如下
信息正确遍历
接着进入霸王别姬的网页,对里面影评的消息进行分析。
可以发现霸王别姬的简介在这个区域范围里面

这里采用正则表达式对里面的信息进行爬取
则用(?<=<span property="v:summary" class>)[sS]*?(?=</span>)
同样用上述步骤

设置正则表达式的匹配串:
(?<=<span class="short">)[sS]*?(?=</span>)
则综上之后爬虫的代码是:

然后我们看到直接对网页进行爬取的结果
爬取的结果如下所示: