1、Side-Aware Boundary Localization for More Precise Object Detection
为了有效解决目标检测中精确定位的问题,来自港中文、南洋理工、浙大、中科大和商汤的研究人员们提出了一种基于边线的边框定位方法(Side-Aware Boundary Localization, SABL)。
这种方法基于目标周围上下文特征来确定包围框的四条边线,通过为每条边线进行特征分桶(bucketing)抽取,经过基于分类的粗定位和基于回归的精确定位两个步骤,实现了更为精确的目标检测定位。通过将目标检测框架的bbox回归分支替换为SABL,实现了两到三个点的AP提升。
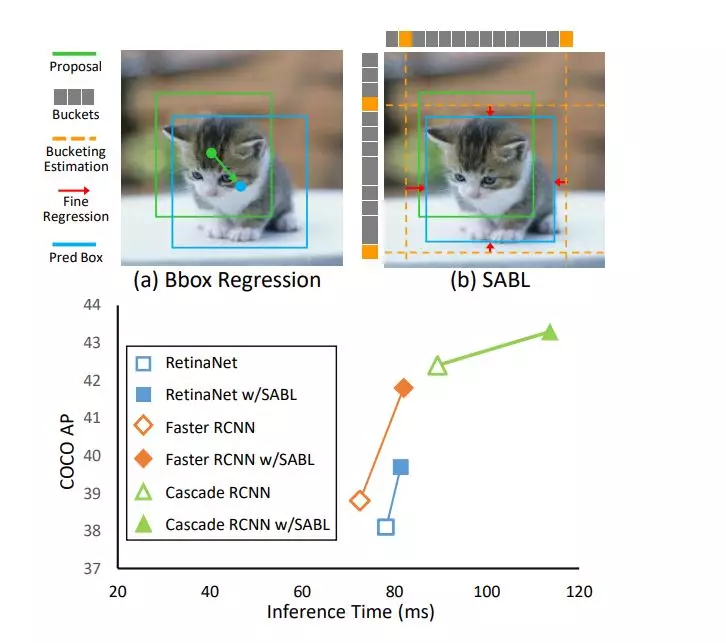
基于边线感知的边框定位
大多数基于bbox的目标检测方法都集中于训练如何将边框精确地回归到目标上,基于RoI的区域特征模型将通过回归分支预测出目标基于锚框的中心偏移量以及长宽尺寸变化。虽然基于这种设计的检测方法在目标检测任务中取得了巨大的成功,但对于与锚框位置方差过大的目标来说,精确预测其位置还面临着一系困难,这同时也降低了目标检测模型的性能。
为了在不引入过多计算开销的情况下解决此类目标的精确定位问题,实现轻量化高性能的检测模型变得尤为重要。
受到图像标注过程的启发,研究人员发现人类在对目标进行标注时,分别匹配标注目标的每一条边线比直接移动和调整bbox更为容易和准确。基于这样的观察和想法,科研人员提出了**边缘感知的边框定位方法(SABL)**来实现目标检测,为目标检测提供了除bbox外更为准确的定位方法。
来自: https://www.techbeat.net/articles/MTU5MDY2MjE0NTY0OC0xNTYtMzEyNDU=
2、细粒度情感分析,忘记记录论文的名字,从中学到了细粒度的概念,粗粒度可以从文本中学习到积极/消极情绪;细粒度是先分出文本中的对象,例如服务、菜价、口味分别是积极/消极的。如果应用到检测,是不是可以。。。没想好怎么说。
3、将门的视频,看到两篇商汤的CVPR 论文,POD和Revisiting head,稍笔记一下。
POD:同一个dataset,先用faster r-cnn 检测,相当预训练,再用soft-softmax 【roipooling后改的】训练。不知道是不是这样,再看论文吧,dilation factor 是学习的,resnet50 每个stage的factor选择策略?(前面的层里,若接近1,例如1.09,因为1.09-10< threshold=0.1,就discard;后面的几乎都保留)(i-box和j-box 如果IOU>0.85, 即为共生,共生数/总数=?)(实验的设计)
Revisiting:解耦方式设计encoding和head部分。(Pc,Pr 有先验,因为分类是置信度,对回归的框,因为框有固定形状--有限制,所以预测偏移量时,对分类无限,但对回归有约束-成矩形)(data的分布,在roipooling 后,domain会集中在分类-较回归容易,不太懂,看原文)(TSD对one-stage也有效)(mc和mr推动了Pc,Pr -?)(实验设计,融合的影响)
4、小尺度不好(先分析原因,调研后分类,再看解决)(采样不均衡、平衡sampling)(anchor数量不平衡-在anchor产生【不同scale,面积不同,但一般是比例吧,影响还大吗】和匹配时,如回归解耦?)(计算量、次数等不平衡)(参数?)
还是不太懂,再看论文吧
5、anchor-based 学习:(https://zhuanlan.zhihu.com/p/91261916,还有一篇数据增强的文章)
Anchor有什么作用【查ambiguous sample】
- 正负样本界定。设定双IoU阈值来定义pos, neg和 ingore三种样本,从而进行训练。
- 在Faster RCNN时代,anchor在处理multi-scale的基础上,同时很大程度解决了ambiguous sample问题。如下图所示,两个物体靠的很近,它们的中心点在8/16倍下采样feature map上,很容易对准到同1个pixel,若不考虑多个anchor,大概率丢失掉其中一个gt。但是为每个点考虑不同scale和aspect ratio的anchor便可以很好的解决这个问题。

- 有了FPN过后,为不同level的feature考虑不同大小的anchor,那么通过anchor与GT的匹配便可以做到将不同scale的物体assign到不同level的feature map上。此外,这种assign又进一步缓解了ambiguous sample问题。
6、Label Assignment in Object Detection 整理