之前写了一篇判断Chromedriver是否最新并自动下载的文章,这次尝试实现了IEDriverServer的自动更新。
火狐的geckodriver 是在github,暂时还没想到怎么实现。
这次与上一篇的不同,主要在于页面接口返回的是XML,所以使用了lxml进行解析。同时使用了之前自己写的一个比较版本号大小的函数。
2019.03.17更新:
原本是使用的xml.etree.ElementTree进行解析,但是使用xpath获取元素列表的时候,发现每个节点都需要使用xml的namespace作为前缀,但是ElementTree模块貌似没有获取namespace的方法,搜索好久之后,发现lxml模块有个方法可以获取(lxml.tree.nsmap[None]),所以改用了lxml模块。
简单说下思路:
1、获取版本号(解析xml,并通过xpath获取)
xpath为:’.//{name_space}CommonPrefixes/{name_space}Prefix’
因为该xml有namespace,所以每个节点都需要加前缀,比较麻烦,所以将namespace提取出来作为变量

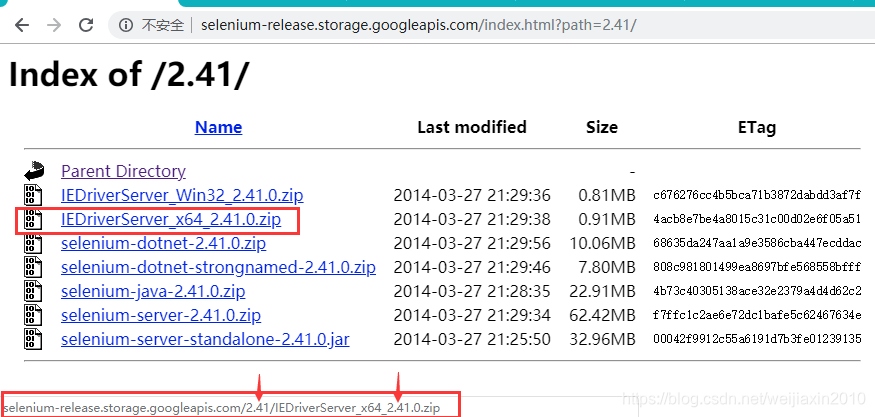
2、拼接下载地址
如图,获取到最新的版本号后,下载地址里面只需要相应修改2个地方就可以了
代码如下:
#!/usr/bin/env python
# coding=UTF-8
'''
@Description: 用于将IEDriverServer更新为最新版本
@Author: wjx
@LastEditors: Please set LastEditors
@Date: 2019-03-15 10:56:34
@LastEditTime: 2019-03-17 00:52:33
依据网页上最新版本的命名规则获取最新的文件,所以如果网站命名规则改变的话,可能会获取到旧版
如果获取的版本不是最新,请手动到网站(http://selenium-release.storage.googleapis.com/index.html/)获取
'''
import requests
import re
import os
import zipfile
from lxml import etree
IEDRIVERSERVER_URL = 'http://selenium-release.storage.googleapis.com/'
IEDRIVERSERVER_API = f'{IEDRIVERSERVER_URL}?delimiter=/&prefix=' # 下载地址
PATH = ".\drivers\"
def get_latest_version(url):
'''查询最新的IEDriverServer版本'''
rep = requests.get(url)
tree = etree.fromstring(rep.content) # 接口返回的是XML文件,需要进行解析
name_space = '{' + tree.nsmap[None] + '}' # 获取XML的namespace
latest_version = '0'
for tag in tree.findall(f'.//{name_space}CommonPrefixes/{name_space}Prefix'): # 通过xpath定位,每个节点都有namespace
version = tag.text[:-1]
if version.replace('.', '').isdigit():
latest_version = compare(latest_version, version) or latest_version # 如果返回为None,说明相等,则直接拿上次的结果
return latest_version
def download_driver(download_url):
'''下载文件'''
file = requests.get(download_url)
with open(f"{PATH}IEDriverServer.zip", 'wb') as zip_file: # 保存文件到脚本所在目录
zip_file.write(file.content)
print('下载成功')
def get_version():
'''查询指定位置的IEDriverServer版本'''
# path = os.getcwd() # 获取当前工作路径
outstd2 = os.popen(f'{PATH}IEDriverServer.exe --version').read()
return outstd2.split(' ')[1]
def unzip_driver():
'''解压IEDriverServer压缩包到指定目录'''
f = zipfile.ZipFile(f"{PATH}IEDriverServer.zip", 'r')
for file in f.namelist():
f.extract(file, PATH)
def compare(a: str, b: str):
'''比较两个版本的大小,需要按.分割后比较各个部分的大小'''
lena = len(a.split('.')) # 获取版本字符串的组成部分
lenb = len(b.split('.'))
a2 = a + '.0' * (lenb-lena) # b比a长的时候补全a
b2 = b + '.0' * (lena-lenb)
for i in range(max(lena, lenb)): # 对每个部分进行比较,需要转化为整数进行比较
if int(a2.split('.')[i]) > int(b2.split('.')[i]):
return a
elif int(a2.split('.')[i]) < int(b2.split('.')[i]):
return b
else: # 比较到最后都相等,则返回None用于判断相等的情况
if i == max(lena, lenb)-1:
return None
if __name__ == "__main__":
latest_version = get_latest_version(IEDRIVERSERVER_API)
print('最新的IEDriverServer版本为:', latest_version)
version = get_version()
print('当前系统内的IEDriverServer版本为:', version)
if compare(version, latest_version): # 如果有返回值,说明不相等
print('当前系统内的IEDriverServer不是最新的,需要进行更新')
download_url = IEDRIVERSERVER_URL + latest_version + '/IEDriverServer_x64_' + latest_version + '.0.zip' # 拼接下载链接
print('文件下载路径:', download_url)
download_driver(download_url)
unzip_driver()
print('更新后的IEDriverServer版本为:', get_version())
else:
print('当前系统内的IEDriverServer已经是最新的')
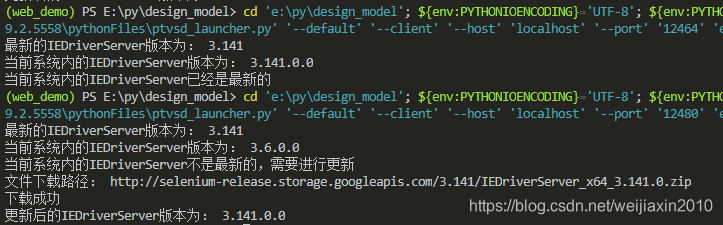
效果如下:
PS:还有个小问题,就是拼接的版本不一定是该路径下最新的,如:
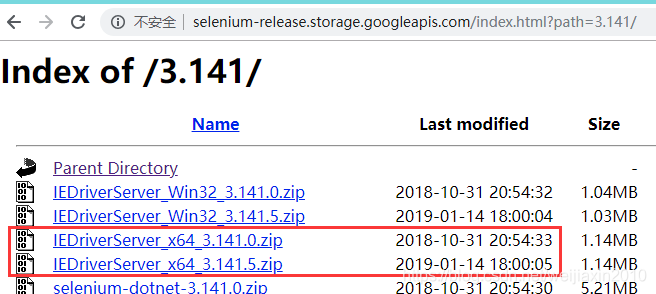
后面再考虑从这个页面再次解析出日期最新的版本的下载链接好了,但是貌似会导致最终下载的版本和原本确定的最新版本又有一点不一致……