公司有个项目,是使用kettle从oracle上统计,再将结果跟oracle中目标表进行对比更新。接手后,走了一些弯路,中间各种尝试都不尽如人意,也学了kettle的一些组件的用法。正好趁着机会记录 一下。
一、背景:
需求其实很简单,在源oracle中,有大批量的表,是使用定时调度从其他不同的数据库(oracle,mysql,sybase,dameng,sqlserver)中将 “表信息”,“字段信息”,“注释信息”等元数据表,拉取过来,分别做好编号存储。
而kettle要实现的功能:
① 则是从这些源数据表中,将表名、字段名、字段注释、字段长度、字段类型等信息关联出来。
② 并与之前已经做好的一张结果表做关联更新。
③ 将“元数据有变更”的表的四元素(type,length,primary,comment)信息进行update。
④ 如果该字段已经没有了被删除了,则有专用字段标记为"1"。
⑤ 如果是新来的字段,则insert插入目标表。
二、历程:
1. 一开始,机敏的同事使用了一个SQL脚本,用了oracle中的 merge using() matched ....用法,——如果查询结果与目标结果的 table_name和 column_name关联上,则直接将四元素update到目标表中;若没关联上,则直接insert到目标表中。
2. 问题初现: 初步的逻辑相当于:只要关联上,就必须update,这样来说,没有任何变化的字段,也要update一次,造成大量的update其实是可以避免的。而且已删除字段的标记也未实现。
3. 趟雷:
① 最开始,使用kettle的组件来实现SQL中的逻辑,就不贴图了,太长了,而且运行起来的效率低的可怕,后被pass。
② 后来尝试,将SQL优化:
建立临时表;
join的数据的列裁剪;
都用了一遍,但是毫无卵用....效率仍然低(在真实生产环境上直接都跑不动了)
③ 后来尝试了一个新的用法: kettle中有个组件叫“合并记录”:  。 这个小老弟看着不起眼,其实很厉害——它可以将两组数据流进行比对,一个原始的,一个“新来的”,用新来的流与原始的流做比对,并在新产生的流中做标记,标记出哪些是没变的,哪些是新加的(new),哪些是删除了的(deleted),哪些是改变了的(changed)。
。 这个小老弟看着不起眼,其实很厉害——它可以将两组数据流进行比对,一个原始的,一个“新来的”,用新来的流与原始的流做比对,并在新产生的流中做标记,标记出哪些是没变的,哪些是新加的(new),哪些是删除了的(deleted),哪些是改变了的(changed)。
当时一看,这不就是为这需求量身打造的组件,直接用起来!
改造逻辑:
查询的SQL保留,但是再从目标表查询出全量数据,将这两个流做比对,用“合并记录”的组件将各种情况的记录都标记出来,在后续的流程中可以使用组件来筛选和进行后续的操作。
改造完成后的图如下:
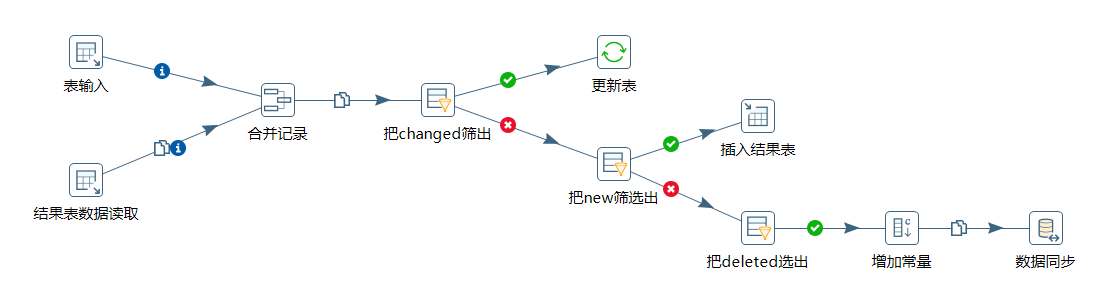
这样,就将“需要更新”的,“需要插入的”,需要“标记为删除的”分别筛选出来,单独进行更细或者插入的操作了。
然而,还是出现了新的问题,在“更新”和”同步“ 之后,速度仍然慢。
保存出问题了,中间写的没有了,现在精简的补充一下:
解决方案:
建立索引——> 目标表(table_name,column_name)。
update的速度——>大幅度提升。
三、总结:
① 对于不通的方式,最多2天,不要再深入研究,问题一定不是在整个方向上。
② 解决问题要有逻辑性,哪怕在纸上写出来,将问题一个个的罗列,解决,梳理,能对问题有个明确的方向。
③ 多上cnblog看看大神的数据库笔记。。。