前提科普:
深拷贝/浅拷贝
有指针的情况下,浅拷贝只是增加了一个指针指向已经存在的内存,而深拷贝就是增加一个指针并且申请一个新的内存,使这个增加的指针指向这个新的内存。
加载因子
加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.
反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.
冲突的机会越大,则查找的成本越高.反之,查找的成本越小.因而,查找时间就越小.
因此,必须在 "冲突的机会"与"空间利用率"之间寻找一种平衡与折衷. 这种平衡与折衷本质上是数据结构中有名的"时-空"矛盾的平衡与折衷.
一、继承层次图
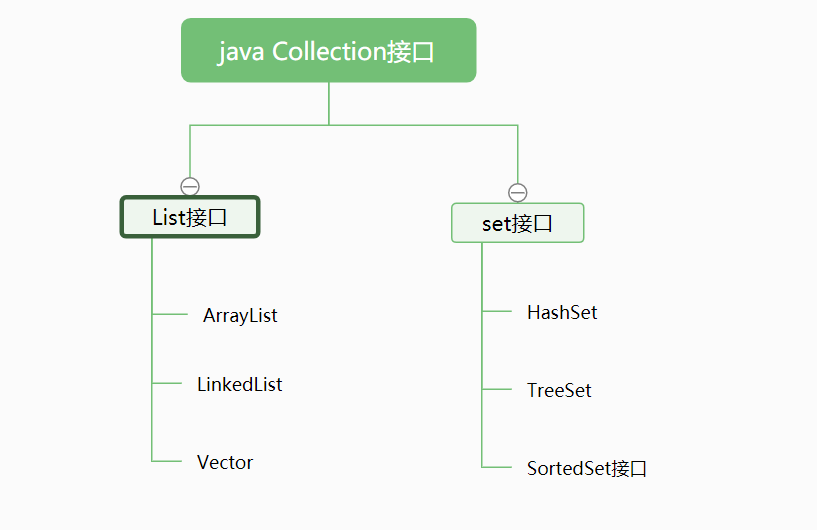
二、List 使用方法说明
List 元素有序 可重复 允许null
1 ArrayList 方法说明(线程不安全)
1.1 方法
1 // 构造器 2 4 构造一个具有指定初始容量的空列表。 5 public ArrayList(int initialCapacity) 6 7 构造一个初始容量为 10 的空列表。 8 public ArrayList() 9 10 构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。 11 public ArrayList(Collection<? extends E> c) 12 13 14 //添加 15 16 将指定的元素添加到此列表的尾部。 17 public boolean add(E e) 18 19 将指定的元素插入此列表中的指定位置。向右移动当前位于该位置的元素(如果有)以及所有后续元素(将其索引加 1)。 20 public void add(int index, E element) 21 22 按照指定 collection 的迭代器所返回的元素顺序,将该 collection 中的所有元素添加到此列表的尾部。 23 public boolean addAll(Collection<? extends E> c) 24 25 从指定的位置开始,将指定 collection 中的所有元素插入到此列表中。向右移动当前位于该位置的元素(如果有)以及所有后续元素(增加其索引)。 26 public boolean addAll(int index, Collection<? extends E> c) 27 28 29 //删除
30 移除此列表中指定位置上的元素。向左移动所有后续元素(将其索引减 1)。 31 public E remove(int index) 32 33 移除此列表中首次出现的指定元素(如果存在)。 34 public boolean remove(Object o) 35 36 移除此列表中的所有元素。此调用返回后,列表将为空。 37 public void clear() 38 39 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。 40 public boolean removeAll(Collection<?> c) 41 42 仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。 43 public boolean retainAll(Collection<?> c) 44 45 //修改 46 47 public E set(int index, E element) 48 49 50 //查询 51 52 返回此列表中指定位置上的元素。 53 public E get(int index) 54 55 返回此列表中的元素数。 56 public int size() 57 58 返回此列表中首次出现的指定元素的索引,或如果此列表不包含元素,则返回 -1。 59 public int indexOf(Object o) 60 61 返回此列表中最后一次出现的指定元素的索引,或如果此列表不包含索引,则返回 -1。 62 public int lastIndexOf(Object o) 63 64 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。 65 public List<E> subList(int fromIndex, int toIndex) 66 67 //判断 68 69 如果此列表中没有元素,则返回 true 70 public boolean isEmpty() 71 72 如果此列表中包含指定的元素,则返回 true。 73 public boolean contains(Object o) 74 75 //迭代器 76 public ListIterator<E> listIterator(int index) 77 public ListIterator<E> listIterator() 78 public Iterator<E> iterator() 79 80 //转换成数组 81 public Object[] toArray() 82 83 @SuppressWarnings("unchecked") 84 public <T> T[] toArray(T[] a) 85 86 87 88 //其它 89 将此 ArrayList 实例的容量调整为列表的当前大小。应用程序可以使用此操作来最小化 ArrayList 实例的存储量。 90 public void trimToSize() 91 92 如有必要,增加此 ArrayList 实例的容量,以确保它至少能够容纳最小容量参数所指定的元素数。 93 public void ensureCapacity(int minCapacity)
94 返回此 ArrayList 实例的浅表副本。(不复制这些元素本身。) 95 public Object clone() 96
1.2 底层数据结构==数组
2 LinkedList 方法说明(线程不安全)
2.1 方法
//构造器***************
构造一个空列表。
public LinkedList()
构造一个包含指定 collection 中的元素的列表,这些元素按其 collection 的迭代器返回的顺序排列。
public LinkedList(Collection<? extends E> c)
//增加****************
添加元素到表头:----------------------
public void addFirst(E e)
public void push(E e)
添加元素到表尾:----------------------
public void addLast(E e)
public boolean add(E e)
public boolean addAll(Collection<? extends E> c)
将指定元素添加到此列表的末尾(最后一个元素)。
public boolean offer(E e)
在此列表末尾插入指定的元素。
public boolean offerLast(E e)
-----------------------------
public boolean addAll(int index, Collection<? extends E> c)
public void add(int index, E element)
//删除*******************
移除此列表的第一个元素:-------------------
public E removeFirst()//列表为空,报错
public E remove() //列表为空,报错
public E pop() //列表为空,报错
public E pollFirst()//列表为空,则返回 null
public E poll() //列表为空,返回null
删除此列表的最后一个元素:-----------------
public E removeLast() //列表为null,报错
public E pollLast()//列表为空,则返回 null
---------------------------
public boolean remove(Object o) //不存在不抱错
public void clear() //列表为空不报错
public E remove(int index) //不存在索引报错
//修改*********************
public E set(int index, E element) //表为空报错,索引不存在报错
//查询*********************
//返回此列表的第一个元素。--------------------
public E getFirst() //表为空 报错
public E peek() //列表为空,则返回 null
public E peekFirst() //列表为空,则返回 null
public E element() //列表为空,则报错
//返回此列表的最后一个元素---------------------
public E getLast() //列表为空,报错
public E peekLast() //列表为空,则返回 null
public int size()
public E get(int index)
public int indexOf(Object o) //不存在-1
public int lastIndexOf(Object o)//不存在 -1
//判断**********************
public boolean (Object o) //如果是引用对象,也只是看这个对象的值。地址不管
---------------------------
在此列表的开头插入指定的元素。
public boolean offerFirst(E e)
从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表时)。如果列表不包含该元素,则不作更改。//不存在,返回false
public boolean removeFirstOccurrence(Object o)
从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表时)。如果列表不包含该元素,则不作更改。//不存在,返回false
public boolean removeLastOccurrence(Object o)
//迭代器***********************
//链表为空,迭代器不抱错
public ListIterator<E> listIterator(int index)
返回以逆向顺序在此双端队列的元素上进行迭代的迭代器。元素将按从最后一个(尾部)到第一个(头部)的顺序返回。
public Iterator<E> descendingIterator()
//转换************************
public Object[] toArray()
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) //如果参数长度大于列表 那么用null填充,如果小于,按照列表全部输出。
//其它***********************
public Object clone()//浅拷贝 单实际应用 肯定会对它进行重新赋值 所以深浅意义不大
2.2 底层数据结构==链表
3 Vector 方法说明(线程安全)
Vector 类可以实现可增长的对象数组。Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作。
向量的大小大于其容量时,容量自动增加的量。如果容量的增量小于等于零,则每次需要增大容量时,向量的容量将增大一倍。增大后的容量是之前的2倍。
3.1 方法
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
//构造器 **********************
/**
* 使用指定的初始容量和容量增量构造一个空的向量。
*/
public Vector(int initialCapacity, int capacityIncrement)
/**
* 使用指定的初始容量和等于零的容量增量构造一个空向量。
*/
public Vector(int initialCapacity)
/**
* 构造一个空向量,使其内部数据数组的大小为 10,其标准容量增量为零。
*/
public Vector()
/**
* 构造一个包含指定 collection 中的元素的向量,这些元素按其 collection 的迭代器返回元素的顺序排列。
*/
public Vector(Collection<? extends E> c)
//增加*************************
/**
* 将指定对象作为此向量中的组件插入到指定的 index 处。 索引超出范围报错
*/
public synchronized void insertElementAt(E obj, int index)
/**
* 将指定的组件添加到此向量的末尾,将其大小增加 1。如果向量的大小比容量大,则增大其容量。
*/
public synchronized void addElement(E obj)
public synchronized boolean add(E e)
public void add(int index, E element)
public synchronized boolean addAll(Collection<? extends E> c)
public synchronized boolean addAll(int index, Collection<? extends E> c)
//删除*************************
/**
* 删除指定索引处的组件。此向量中的每个索引大于等于指定 index 的组件都将下移,使其索引值变成比以前小 1 的值。此向量的大小将减 1。
* //索引超出范围,报错
*/
public synchronized void removeElementAt(int index)
/**
* 从此向量中移除变量的第一个(索引最小的)匹配项。 不存在返回false
*/
public synchronized boolean removeElement(Object obj)
/**
* 从此向量中移除全部组件,并将其大小设置为零。
*/
public synchronized void removeAllElements()
//移除此向量中指定元素的第一个匹配项,如果向量不包含该元素,则元素保持不变。 不存在 返回false
public boolean remove(Object o)
public synchronized E remove(int index)
public void clear()
public synchronized boolean removeAll(Collection<?> c)
public synchronized boolean retainAll(Collection<?> c)
protected synchronized void removeRange(int fromIndex, int toIndex)
//修改*************************
/**
*将此向量指定 index 处的组件设置为指定的对象。丢弃该位置以前的组件。 //索引超出范围报错
*/
public synchronized void setElementAt(E obj, int index)
public synchronized E set(int index, E element)
//查询*************************
/**
* 返回此向量的当前容量
*/
public synchronized int capacity()
/**
* 返回此向量中的组件数。
*/
public synchronized int size()
/**
* 返回此向量的组件的枚举。返回的 Enumeration 对象将生成此向量中的所有项。生成的第一项为索引 0 处的项,然后是索引 1 处的项,依此类推。
*/
public Enumeration<E> elements()
public int indexOf(Object o)
/**
* 返回此向量中第一次出现的指定元素的索引,从 index 处正向搜索,如果未找到该元素,则返回 -1。
*/
public synchronized int indexOf(Object o, int index)
public synchronized int lastIndexOf(Object o)
/**
* 返回此向量中最后一次出现的指定元素的索引,从 index 处逆向搜索,如果未找到该元素,则返回 -1
*/
public synchronized int lastIndexOf(Object o, int index)
/**
* 返回指定索引处的组件。
*/
public synchronized E elementAt(int index)
/**
* 获取第一个元素
*/
public synchronized E firstElement()
/**
* 获取最后一个元素
*/
public synchronized E lastElement()
public synchronized E get(int index)
public synchronized int hashCode()
//返回此 List 的部分视图,元素范围为从 fromIndex(包括)到 toIndex(不包括)。
public synchronized List<E> subList(int fromIndex, int toIndex)
//判断*************************
public synchronized boolean isEmpty()
public boolean contains(Object o)
public synchronized boolean containsAll(Collection<?> c)
//比较指定对象与此向量的相等性。当且仅当指定的对象也是一个 List、两个 List 大小相同,并且其中所有对应的元素对都 相等 时才返回 true。???????
public synchronized boolean equals(Object o)
//迭代器***********************
public synchronized ListIterator<E> listIterator(int index)
public synchronized ListIterator<E> listIterator()
public synchronized Iterator<E> iterator()
//转换成数组*******************
/**
* 将此向量的组件复制到指定的数组中。此向量中索引 k 处的项将复制到 anArray 的组件 k 中。
* 如果给定的数组为 null 报错
* 如果指定数组不够大,不能够保存此向量中的所有组件 报错
* 如果此向量的组件不属于可在指定数组中存储的运行时类型
*/
public synchronized void copyInto(Object[] anArray)
public synchronized Object[] toArray()
//数组长度大了,用null填充 ,小了,则返回新数组
public synchronized <T> T[] toArray(T[] a)
//其它*************************
/**
*对此向量的容量进行微调,使其等于向量的当前大小。
*如果此向量的容量大于其当前大小,则通过将其内部数据数组(保存在字段 elementData 中)替换为一个较小的数组,从而将容量更改为等于当前大小。
* 应用程序可以使用此操作最小化向量的存储。
*/
public synchronized void trimToSize()
/**
* 增加此向量的容量(如有必要),以确保其至少能够保存最小容量参数指定的组件数。//????
*/
public synchronized void ensureCapacity(int minCapacity)
/**
* 设置此向量的大小。如果新大小大于当前大小,则会在向量的末尾添加相应数量的 null 项。
* 如果新大小小于当前大小,则丢弃索引 newSize 处及其之后的所有项。 //如果有数据是不是 数据也不要了????
*/
public synchronized void setSize(int newSize)
//返回向量的一个副本。副本中将包含一个对内部数据数组副本的引用,而非对此 Vector 对象的原始内部数据数组的引用。?????
public synchronized Object clone()
}
3.2 底层数据结构==数组
三、Set 使用方法说明
元素不可重复
1 HashSet 方法说明(线程不安全)
无序,不可重复,允许 null
没有修改方法,没有转换成数组的方法,也无法获取某一个元素,估计只能迭代了
1 .1 方法
.
package java.util; public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { //构造器 5个******************* /** * 构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。 */ public HashSet() /** * 构造一个包含指定 collection 中的元素的新 set。使用默认的加载因子 0.75 和足以包含指定 collection 中所有元素的初始容量来创建 HashMap。 */ public HashSet(Collection<? extends E> c) /** * 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。 */ public HashSet(int initialCapacity, float loadFactor) /** * 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。 */ public HashSet(int initialCapacity) //增加********************* /** * 如果已经存在(重复)的,返回false */ public boolean add(E e) /** * 如果不存在???? */ public boolean remove(Object o) //删除********************* public void clear() //查询********************* /** * 元素数量(其容量)(允许null) * 有的集合 元素数量=容量 元素数量!=容量 */ public int size() //判断********************* public boolean isEmpty() public boolean contains(Object o) //迭代器******************* /** * 返回对此 set 中元素进行迭代的迭代器。返回元素的顺序并不是特定的。 */ public Iterator<E> iterator() //其它********************* /** * 浅复制 */ public Object clone() }
1.2 底层数据结构
2 LinkedHashSet 方法说明(线程不安全)
2.1 方法
不能重复,迭代有顺序,允许null,就是为了弥补hashset迭代无序。加入重复的元素,不会报错,会替换原来的
package java.util; public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable { //构造器***************
/** * 构造一个带有指定初始容量和加载因子的新空链接哈希 set。 */ public LinkedHashSet(int initialCapacity, float loadFactor) /** * 构造一个带指定初始容量和默认加载因子 (0.75) 的新空链接哈希 set。 */ public LinkedHashSet(int initialCapacity) /** * 构造一个带默认初始容量 (16) 和加载因子 (0.75) 的新空链接哈希 set。 */ public LinkedHashSet() /** * 构造一个与指定 collection 中的元素相同的新链接哈希 set。 参数为空,报错 */ public LinkedHashSet(Collection<? extends E> c)
//迭代器************************8 /** *???? */ @Override public Spliterator<E> spliterator() }
2.2 底层数据结构
3 TreeSet 方法说明(线程不安全)
不能重复,有序(得自己实现),
3.1 方法
package java.util;
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
//构造器******************
/**
* 构造一个新的空 set,该 set 根据其元素的自然顺序进行排序。插入该 set 的所有元素都必须实现 Comparable 接口。
*/
public TreeSet()
/**
* 构造一个新的空 TreeSet,它根据指定比较器进行排序。
*/
public TreeSet(Comparator<? super E> comparator)
/**
* 构造一个包含指定 collection 元素的新 TreeSet,
* 它按照其元素的 自然顺序进行排序。插入该 set 的所有元素都必须实现 Comparable 接口。
*/
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
//增加*************************
/**
* 重复返回false
*/
public boolean add(E e)
/**
* 参数为空???
*/
public boolean addAll(Collection<? extends E> c)
//删除*************************
/**
* 如果是空怎么办?
*/
public boolean remove(Object o)
public void clear()
/**
* 移除第一个(最低)元素;如果此 set 为空,则返回 null。
*/
public E pollFirst()
/**
* 移除最后一个(最高)元素;如果此 set 为空,则返回 null。
*/
public E pollLast()
//修改*************************
//查询*************************
/**
* 返回 set 中的元素数(set 的容量)。
*/
public int size()
/**
* 返回小于给定元素的最大元素;不存在,返回 null。
*/
public E lower(E e)
/**
* 返回大于给定元素的最小元素;不存在,则返回 null。
*/
public E higher(E e) {
return m.higherKey(e);
}
/**
* 返回小于等于给定元素的最大元素;不存在,返回 null。
*/
public E floor(E e) {
return m.floorKey(e);
}
/**
* 返回大于等于给定元素的最小元素;不存在,返回 null。
*/
public E ceiling(E e)
/**
* 返回第一个(最低)元素。
*/
public E first()
/**
* 返回最后一个(最高)元素。
*/
public E last()
//判断*************************
public boolean isEmpty() {
return m.isEmpty();
}
public boolean contains(Object o) {
return m.containsKey(o);
}
//转换*************************
/**
* 构造一个与指定有序 set 具有相同映射关系和相同排序的新 TreeSet。
*/
public TreeSet(SortedSet<E> s)
------------------------------------------
/**
* 返回部分视图,其元素从 fromElement(包括)到 toElement(不包括)。
*/
public SortedSet<E> subSet(E fromElement, E toElement)
/**
* 返回部分视图,开始到toElement(不包括)
*/
public SortedSet<E> headSet(E toElement)
/**
* 返回部分视图,fromElement(包括)到结尾
*/
public SortedSet<E> tailSet(E fromElement)
-------------------------------
/**
* 返回部分视图,其元素范围从 fromElement 到 toElement。
*/
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive)
/**
* 返回部分视图,开始到toElement(true,包括)。
*/
public NavigableSet<E> headSet(E toElement, boolean inclusive)
/**
* 返回部分视图,fromElement(true,包括)到结尾。
*/
public NavigableSet<E> tailSet(E fromElement, boolean inclusive)
/**
* 返回此 set 中所包含元素的逆序视图。
*/
public NavigableSet<E> descendingSet()
//迭代器***********************
/**
* 返回在此 set 中的元素上按升序进行迭代的迭代器。
*/
public Iterator<E> iterator()
/**
* 返回在此 set 元素上按降序进行迭代的迭代器。
*/
public Iterator<E> descendingIterator()
/**
* ????
*/
public Spliterator<E> spliterator()
//其它
/**
* 浅复制
*/
public Object clone()
/**
* 返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的 自然顺序,则返回 null。
***/
public Comparator<? super E> comparator() {
return m.comparator();
}
示例代码
自然排序 元素对象所在类实现java.lang.Comparable
public class Teacher implements Comparable{
private int age;
public Teacher(int age) {
this.age=age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//实现 Comparable 接口
public int compareTo(Object o) {
if(o.getClass()==Teacher.class) {
Teacher b=(Teacher)o;
if(o==null){
System.out.println("参数为空,不能进行比较!!!");
}else {
if(this.age<b.getAge()) {
return -1;
}else if(this.age==b.getAge()) {
return 0;
}else {
return 1;
}
}
}else {
System.out.println("类型不符!!!!无法进行比较");
throw new NumberFormatException();
}
return 0;
}
}
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Spliterator;
import java.util.TreeSet;
import org.junit.Test;
import com.haiqin.Teacher;
public class CollectTest {
@Test
public void test2() {
TreeSet treeSet=new TreeSet();
treeSet.add(new Teacher(1));
treeSet.add(new Teacher(3));
treeSet.add(new Teacher(2));
treeSet.add(new Teacher(4));
treeSet.add(new Teacher(4));
Iterator aIterator=treeSet.iterator();
while(aIterator.hasNext()) {
Teacher a=(Teacher)aIterator.next();
System.out.println("输出======="+a.getAge());
}
}
}

定制排序
另外写一个比较器(实现 java.util.Comparator接口),这个比较器专门用来比较对象类型。
package com.haiqin;
public class Teacher{
private int age;
public Teacher() {
}
public Teacher(int age) {
this.age=age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
// //实现 Comparable 接口
// public int compareTo(Object o) {
// if(o.getClass()==Teacher.class) {
// Teacher b=(Teacher)o;
// if(o==null){
// System.out.println("参数为空,不能进行比较!!!");
// }else {
// if(this.age<b.getAge()) {
// return -1;
// }else if(this.age==b.getAge()) {
// return 0;
// }else {
// return 1;
// }
// }
// }else {
// System.out.println("类型不符!!!!无法进行比较");
//
// }
// return 0;
// }
}
package com.haiqin;
import java.util.Comparator;
public class MyComparator implements Comparator{
//实现比较方法
public int compare(Object o1, Object o2) {
if(o1 instanceof Teacher &o2 instanceof Teacher) {
if(o1==null||o2==null) {
throw new NumberFormatException();
//System.out.println("类型不符!");
}
Teacher a=(Teacher)o1;
Teacher b=(Teacher)o2;
if(a.getAge()<b.getAge()) {
return -1;
}else if(a.getAge()==b.getAge()){
return 0;
}else {
return 1;
}
}else {
System.out.println("类型不符!");
return 88;
}
}
}
package com.haiqin.HelloSpring;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Spliterator;
import java.util.TreeSet;
import org.junit.Test;
import com.haiqin.MyComparator;
import com.haiqin.Teacher;
public class CollectTest {
@Test
public void test2() {
TreeSet treeSet=new TreeSet(new MyComparator());
treeSet.add(new Teacher(1));
treeSet.add(new Teacher(3));
treeSet.add(new Teacher());
Iterator aIterator=treeSet.iterator();
while(aIterator.hasNext()) {
Teacher a=(Teacher)aIterator.next();
System.out.println("输出======="+a.getAge());
}
}
}

3.2 底层数据结构
3 SortedSet接口 方法说明
treeSet实现了这个接口
3.1 方法
package java.util;
public interface SortedSet<E> extends Set<E> {
/**
* 返回比较器;如果是自然顺序,返回 null。
*/
Comparator<? super E> comparator();
/**
* 返回部分视图,从 fromElement(包括)到 toElement(不包括)。
*/
SortedSet<E> subSet(E fromElement, E toElement);
/**
* 返回部分视图,[0,toElement)。
*
*/
SortedSet<E> headSet(E toElement);
/**
* 返回部分视图,[fromElement,结束]。
*/
SortedSet<E> tailSet(E fromElement);
/**
* 返回第一个元素。
*/
E first();
/**
* 返回最后一个元素。
*/
E last();
/**
* 迭代器
*/
@Override
default Spliterator<E> spliterator()
}
3.2 底层数据结构
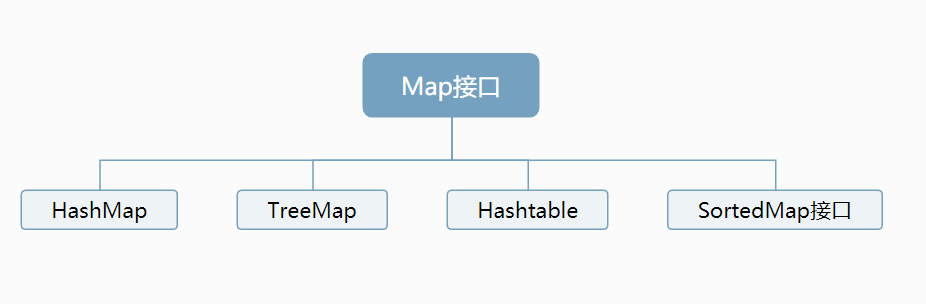
四、Map 使用方法使用
键值对,键不可重复,不能为空。值随意。
1 HashMap 方法说明(线程不安全)
键,值 都可为null ,无序
1.1 方法
package java.util;
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//构造器
/***
* 构造一个带指定初始容量和加载因子的空 HashMap。
**/
public HashMap(int initialCapacity, float loadFactor)
/**
* 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
*/
public HashMap(int initialCapacity)
/**
* 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
*/
public HashMap()
/**
* 构造一个映射关系与指定 Map 相同的新 HashMap。
*/
public HashMap(Map<? extends K, ? extends V> m)
//增加
/**
* 如果已存在,替换
*/
public V put(K key, V value)
/**
* 已存在,替换
*/
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
//删除
/**
* 不存在,返回null
*/
public V remove(Object key)
public void clear()
//查询
public int size()
public Set<K> keySet()
public Collection<V> values()
/**
* 返回此映射所包含的映射关系的 Set 视图。
*/
public Set<Map.Entry<K,V>> entrySet()
/**
* 返回指定键所映射的值 不存在返回null
*/
public V get(Object key)
//判断
public boolean isEmpty()
public boolean containsKey(Object key)
public boolean containsValue(Object value)
//其它
public Object clone()
package com.haiqin.HelloSpring;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.Spliterator;
import java.util.TreeSet;
import org.junit.Test;
import com.haiqin.MyComparator;
import com.haiqin.Teacher;
public class CollectTest {
@Test
public void test2() {
HashMap hashMap=new HashMap<String, String>();
hashMap.put("0", 0);
hashMap.put("1", 1);
hashMap.put("2", 2);
hashMap.put("", "");
hashMap.put(null,null);
Set aSet=hashMap.entrySet();
Iterator aIterator=aSet.iterator();
while(aIterator.hasNext()) {
System.out.println("输出======="+aIterator.next());
}
// 输出=======0=0
// 输出========
// 输出=======null=null
// 输出=======1=1
// 输出=======2=2
}
}
1.2 底层数据结构
2 LinkedHashMap(线程不安全)
键,值都可为空,键迭代有序。
该哈希映射的迭代顺序就是最后访问其条目的顺序,从近期访问最少到近期访问最多的顺序(访问顺序)。
2.1 方法
package java.util; public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> { //构造器 //插入顺序 public LinkedHashMap(int initialCapacity, float loadFactor) //插入顺序 public LinkedHashMap(int initialCapacity) //插入顺序 public LinkedHashMap() //插入顺序 public LinkedHashMap(Map<? extends K, ? extends V> m) /** * 访问顺序,为 true;插入顺序,则为 false */ public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; } //删除 public void clear() /** *如果此映射移除其最旧的条目,则返回 true。 缓存的时候用,保证保存不会存储溢出 */ protected boolean removeEldestEntry(Map.Entry<K,V> eldest) //查询 public V get(Object key) /** * Map集合中有这个key时,就使用这个key值,如果没有就使用默认值defaultValue(当作key值) */ public V getOrDefault(Object key, V defaultValue) public Set<K> keySet() public Collection<V> values() public Set<Map.Entry<K,V>> entrySet() //判断 public boolean containsValue(Object value) }
2.2 底层数据结构
3 TreeMap 方法说明
3.1 方法
package java.util;
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
//构造器
//自然顺序
public TreeMap()
public TreeMap(Comparator<? super K> comparator)
public TreeMap(Map<? extends K, ? extends V> m)
public TreeMap(SortedMap<K, ? extends V> m)
//增加
//如果存在,替换
public void putAll(Map<? extends K, ? extends V> map)
//如果存在,替换
public V put(K key, V value)
//删除
public V remove(Object key)
public void clear()
/**
* 移除并返回与此映射中的最小键关联的键-值映射关系;如果不存在,返回null。
*/
public Map.Entry<K,V> pollFirstEntry()
public Map.Entry<K,V> pollLastEntry()
//修改
public boolean replace(K key, V oldValue, V newValue)
@Override
public V replace(K key, V value)
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function)
//查询
public int size()
public V get(Object key)
//返回一个与此映射中的最小键关联的键-值映射关系,如果为空,返回null
public K firstKey()
public K lastKey()
/**
*
*/
public Map.Entry<K,V> firstEntry()
public Map.Entry<K,V> lastEntry()
/**
* 返回一个键-值映射关系,它与严格小于给定键的最大键关联;如果不存在这样的键,则返回 null。
*/
public Map.Entry<K,V> lowerEntry(K key)
/**
*返回严格小于给定键的最大键;如果不存在这样的键,则返回 null。
*/
public K lowerKey(K key)
/**
* 返回一个键-值映射关系,它与小于等于给定键的最大键关联;如果不存在这样的键,则返回 null。
*/
public Map.Entry<K,V> floorEntry(K key)
/**
* 返回小于等于给定键的最大键;如果不存在这样的键,则返回 null。
*/
public K floorKey(K key)
/**
* 返回一个键-值映射关系,它与大于等于给定键的最小键关联;如果不存在这样的键,则返回 null。
*/
public Map.Entry<K,V> ceilingEntry(K key)
/**
* 返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。
*/
public K ceilingKey(K key)
/**
* 返回一个键-值映射关系,它与严格大于给定键的最小键关联;如果不存在这样的键,则返回 null。
*/
public Map.Entry<K,V> higherEntry(K key)
/**
* 返回严格大于给定键的最小键;如果不存在这样的键,则返回 null。
*/
public K higherKey(K key)
public Set<K> keySet()
public Collection<V> values()
/**
* 返回此映射中所包含键的 NavigableSet 视图。set 的迭代器按升序返回键。
*/
public NavigableSet<K> navigableKeySet()
/**
*
*/
public NavigableSet<K> descendingKeySet()
/**
* 返回此映射中包含的映射关系的 Set 视图。
*/
public Set<Map.Entry<K,V>> entrySet()
/**
* 返回此映射中所包含映射关系的逆序视图。
*/
public NavigableMap<K, V> descendingMap()
/**
* 返回此映射的部分视图,其键的范围从 fromKey 到 toKey。
*/
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive)
/**
* 返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true) toKey
*/
public NavigableMap<K,V> headMap(K toKey, boolean inclusive)
/**
* 返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true) fromKey。
*/
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive)
/**
* 返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。
*/
public SortedMap<K,V> subMap(K fromKey, K toKey)
/**
* 返回此映射的部分视图,其键值严格小于 toKey。
*/
public SortedMap<K,V> headMap(K toKey)
/**
* 返回此映射的部分视图,其键大于等于 fromKey。
*/
public SortedMap<K,V> tailMap(K fromKey)
//判断
public boolean containsKey(Object key)
public boolean containsValue(Object value)
//转换
//迭代器
Iterator<K> keyIterator()
Iterator<K> descendingKeyIterator()
//其它
public Object clone()
@Override
public void forEach(BiConsumer<? super K, ? super V> action)
}
3.2 底层数据结构
4 HashTable 方法说明
3.1 方法
package java.util; public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable { //构造器 /** * 用指定初始容量和指定加载因子构造一个新的空哈希表。 */ public Hashtable(int initialCapacity, float loadFactor) /** * 用指定初始容量和默认的加载因子 (0.75) 构造一个新的空哈希表。 */ public Hashtable(int initialCapacity) /** * 用默认的初始容量 (11) 和加载因子 (0.75) 构造一个新的空哈希表。 */ public Hashtable() /** * 构造一个与给定的 Map 具有相同映射关系的新哈希表。 */ public Hashtable(Map<? extends K, ? extends V> t) //增加 //如果map里没有这个key 就添加 public synchronized V putIfAbsent(K key, V value) //如果map里没有这个key,那么就按照后面的这个function添加对应的key和value public synchronized V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) //如果map里有这个key,那么就按照后面的这个function添加对应的key和value public synchronized V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) //如果map里有这个key,那么function输入的v就是现在的值,返回的是对应value,如果没有这个key,那么输入的v是null public synchronized V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) //删除 /** * 增加此哈希表的容量并在内部对其进行重组,以便更有效地容纳和访问其元素。当哈希表中的键的数量超出哈希表的容量和加载因子时,自动调用此方法。 */ protected void rehash() public synchronized Object clone() public synchronized V put(K key, V value) public synchronized void putAll(Map<? extends K, ? extends V> t) public synchronized V remove(Object key) public synchronized void clear() @Override public synchronized boolean remove(Object key, Object value) //修改 public synchronized void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) public synchronized boolean replace(K key, V oldValue, V newValue) public synchronized V replace(K key, V value) //查询 public synchronized int size() public synchronized boolean isEmpty() public synchronized Enumeration<K> keys() public synchronized Enumeration<V> elements() public synchronized V get(Object key) public Set<K> keySet() public Set<Map.Entry<K,V>> entrySet() public Collection<V> values() public synchronized int hashCode() public synchronized V getOrDefault(Object key, V defaultValue) //判断 /** * 测试此映射表中是否存在与指定值关联的键。 */ public synchronized boolean contains(Object value) public boolean containsValue(Object value) public synchronized boolean containsKey(Object key) //??????? public synchronized boolean equals(Object o) //迭代器 //转换 //其它 @SuppressWarnings("unchecked") @Override public synchronized void forEach(BiConsumer<? super K, ? super V> action) @Override public synchronized V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) }
3.2 底层数据结构
5 SortedMap接口 方法说明
4.1方法
4.2 底层数据结构
6 Collectons 接口