0. 核心
前端-指标
响应时间:用户从客户端发出请求,并得到响应,以及展示出来的整个过程的时间。
加载速度:通俗的理解为页面内容显示的快慢。(改善:1. 减少HTTP重复请求;2.使用CDN;3. 减少下载的资源,压缩,缓存等方法;)
电量:APP的耗电量(屏幕、GPS、唤醒机制、CPU、连网等的使用)。
流量:APP所消耗的流量(资源太多, 图片太大, 重复请求, 日志上传, 埋点数据)
Crash的原因一般有:空指针、内存泄漏、数组越界、调用了高版本的API。
ANR(Application Note Responding):主线程(即UI线程)在超时间内对用户输入时间没有处理完毕时出现,用户需要选择等待或者强制关闭来杀死进程。
FPS(Frames Per Second):动画帧频,1秒钟时间里传输的图片的量,越高越流畅,帧率达到60FPS以上,人眼主观就感受不到差别了。所以一般以60FPS作为衡量标准,即要求每一帧刷新的时间小于16ms,这样才能保证滑动中平滑的流畅度。
服务端-业务指标:
请求响应时间(TTLB):对一个请求做出响应所需要的时间。
吞吐量throughput:网络传输的数据量(处理客户的请求数)
吞吐率:每秒请求数,每秒页面数,用来识别性能瓶颈。
事务响应时间(TPS):每秒事务数;tpm是每分钟的事务数。
点击率(HPS):每秒点击次数
并发用户数:在同一时刻与服务器进行交互(指向服务器发出请求)的在线用户数。
在线用户数:指某段时间内,用户访问系统的用户数。
注册用户数:软件中已经注册的用户,这些用户是系统的潜在用户,随时都有可能上线。
最佳并发用户数:当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待
最大并发用户数:系统的负载一直持续,有些用户在处理而有的用户在自己最大的等待时间内等待的时候
系统的平均负载:在特定的时间内,系统正在处理的用户数和等待处理的用户数的总和
峰值:指的是系统的最大能承受的用户数的极值
业务成功率:多用户对某一业务发起操作的成功率。
错误率:一段时间内出错的请求在总请求数中的占比。
CAPS:每秒建立呼叫数量(Call Attempts Per Second)。
PV:页面浏览量(Page View),或点击量。
qps是指每秒内查询次数,比如执行了select操作,相应的qps会增加。
不同的应用系统tps,qps是没有可对比性的。
服务端-资源指标:
CPU:vmstat 使用率(us,sy,id)、运行队列(r,b)和上下文切换(sc)
内存:vmstat 可用内存(free),swap占用(swpd),页面交换(si,so)
Disk I/O:iostat 使用率(util),IOPS(磁盘每秒能IO次数, r/s,w/s)和数据吞吐量(rkB/s,wkB/s)
Network I/O: 网络吞吐量(iptraf)
1. 性能测试
前提:开始的前提是被测系统的正常业务流程通过,即集成测试通过后。
操作:通过测试工具模拟多种正常、峰值及异常负载条件来对系统的各项性能指标进行测试。
目的:验证软件系统是否能够达到用户提出的性能指标,发现系统中存在的性能瓶颈并加以优化。
分类:4大类
- 基准测试:单用户,发单次请求,产出基准性能数据。
- 负载测试:多用户,用户数渐增,持续同时发同一业务请求,产出最大TPS。
- 压力测试:多用户,资源使用饱和,持续同时发同一业务请求,产出系统瓶颈或使用极限。
- 混合场景测试:多用户,资源使用不饱和,持续同时发不同业务请求,验证系统稳定性。
在对互联网服务进行服务端性能测试时,主要关注两方面的性能指标:
1. 业务指标:如吞吐量(QPS、TPS)、点击率(HPS)、响应时间(RT)、并发数、业务成功率等
2. 资源指标:如CPU、内存、Disk I/O、Network I/O等资源的消耗情况
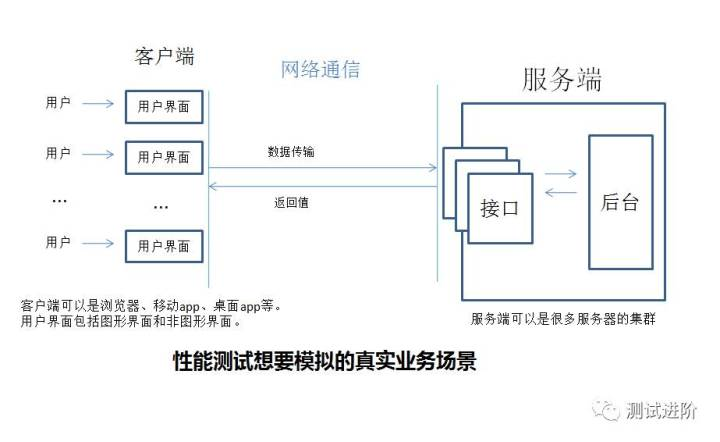
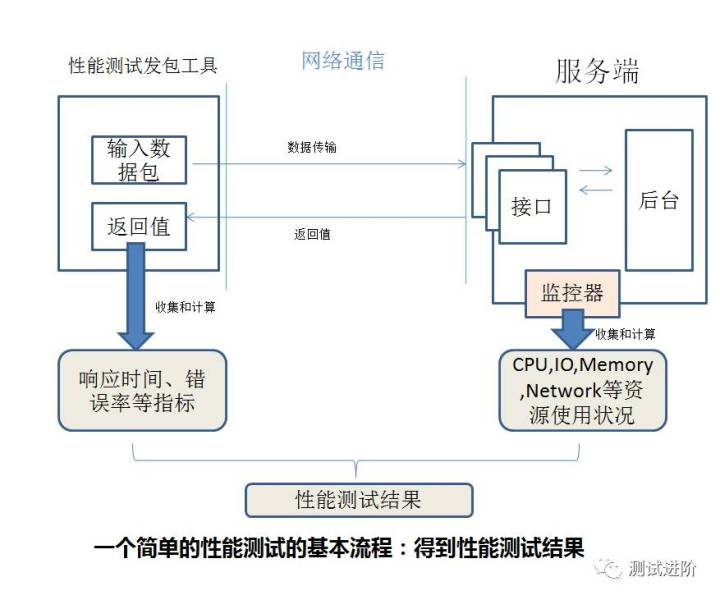

2. 服务端-业务指标
2.1 请求响应时间(TTLB)
请求响应时间:对一个请求做出响应所需要的时间。响应时间是一个往返的过程,包括了客户端请求和服务器响应的时间。可以模拟用户的真实感受。
响应通常会称为“TTLB”,即"time to last byte",意思是从发起一个请求开始,到客户端接收到最后一个字节的响应所耗费的时间,响应时间的单位一般为“秒”或者“毫秒”。
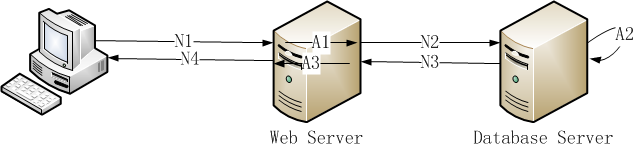
网络传输时间:N1+N2+N3+N4
应用服务器处理时间:A1+A3
数据库服务器处理时间:A2
响应时间=网络响应时间+应用程序响应时间=(N1+N2+N3+N4)+(A1+A2+A3)
/** 标准可参考国外的3/5/10原则: (1)在3秒钟之内,页面给予用户响应并有所显示,可认为是“Very nice很不错的”; (2)在3~5秒钟内,页面给予用户响应并有所显示,可认为是“Not bad好的”; (3)在5~10秒钟内,页面给予用户响应并有所显示,可认为是“Accept reluctantly勉强接受的”; (4)超过10秒就让人有点不耐烦了,用户很可能不会继续等待下去,可认为是“Bye Bye再见”; */
还有一个是标准是2/5/8原则
平均响应时间:所有请求花费的平均时间,平均响应时间指针对某个业务的访问统计所有的响应时间,然后求平均。
如:如果有100个请求,其中 98 个耗时为 1ms,其他两个为 100ms
平均响应时间: (98 * 1 + 2 * 100) / 100.0 = 2.98ms,但是,2.98ms并不能反映服务器的整体效率,因为98个请求耗时才1ms,引申出百分位数
百分位数:以响应时间为例,指的是 99% 的请求响应时间,都处在这个值以下,更能体现整体效率。
2.2 事务响应时间(TPS)
TPS(Transaction Per Second)每秒事务数,每秒钟系统能够处理的交易或者事务的数量.它是衡量系统处理能力的重要指标.
事务:可以看作是一个动作或是一系列动作的集合,可能由一系列请求组成,例如登录,从登录开始到登录结束为一个事务。
计算机术语中,事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
在性能测试脚本设计中,事务的设置至少应该遵守原子性,即不可分割性。
常用的场景
1、事务=单个请求
2、事务=思考时间+单个请求
3、事务=多个相关联的请求
/**
如果事务中增加思考时间,运行结果统计的事务响应时间是包括思考时间的,所有场景的设计,脚本的设置,对测试结果是有影响的,具体需要根据需求进行设计。 Think Time,从业务角度来看,这个时间指用户进行操作时每个请求之间的时间间隔,而在做新能测试时,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。
Think Time作用
A、降低当前运行时压力,缓解对应用服务器所造成的压力;
B、模拟真实生产用户操作,考察对服务器所造成的影响。
0. 吞吐量公式
F = VU * R / T
其中F为吞吐量,
VU表示虚拟用户个数,
R表示每个虚拟用户发出的请求数,
T表示性能测试所用的时间
其中的R又可以用时间T和用户思考时间TS来计算:R = T / TS 1. 平均的并发用户数C,计算公式
C = nL / T
n:平均每天访问用户数(login session)
L:一天内用户从登录到退出的平均时间(login session的平均时间)
T:用户每天使用系统大概多长时间,考察时间长度(一天内多长时间有用户使用系统)
2. 计算思考时间的一般步骤: A、首先计算出系统的并发用户数 C = nL / T
F = R × C B、统计出系统平均的吞吐量 F = VU * R / T
R × C = VU * R / T C、统计出平均每个用户发出的请求数量 R = u * C * T / VU D、根据公式计算出思考时间 TS = T / R*/
TPS:衡量系统处理事务或交易的能力,即服务器对客户请求的能力,每秒处理的事务数,一般在LoadRunner上使用,设置事务,然后统计单位时间内系统可以成功完成多少个定义的事务。
平均事务响应时间满足了性能需求不一定表示系统的性能已经满足了绝大多数用户的要求,因而提出了90%事务响应时间。
90%事务响应时间指在一个时间切面上针对某个事务统计所有的响应时间,然后对这些响应时间进行排序,然后取其中90%的时间中最大的值(排序后的最后一个值)。
从计算平均响应时间的那些请求里去掉最慢的10%之后重新计算平均响应时间。
显然,使用90%平均响应时间,因为去掉了出错超时的那些请求,使得得到的数据更加接近真实值。
具体可以参考《LoadRunner 没有告诉你的》之一——描述性统计与性能结果分析
如果某一次测出的TPS非常小,怎么办?
可能的原因
1)服务器处理能力本如此
2)负载机的用户数没发出去,如给10个用户,只发了3个用户。如果是这种情况,可以用siege试一下
3)如果这时的CPU和内存占用也很小,可能是网卡满了
2.3 吞吐量(率)
衡量网络性能的重要指标
从业务角度看,吞吐量可以用:请求数/秒、页面数/秒、访问人数/天、页面访问量/天、or 处理业务数/小时等单位来衡量。
从网络角度看,吞吐量可以用:字节/秒来衡量
/** 对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力 以不同方式表达的吞吐量可以说明不同层次的问题,例如, 1. 以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈; 2. 已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。 当没有遇到性能瓶颈的时候,吞吐量与虚拟用户数之间存在一定的联系,可以采用以下公式计算:F=VU * R / T 其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间 */
吞吐率与很多因素有关,服务器的硬件配置,网络的宽带及拓扑结构,软件的技术架构等。
2.4 并发用户数
并发用户数:主要是针对服务器而言,在同一时刻与服务器进行交互(指向服务器发出请求)的在线用户数。
在线用户数:指某段时间内,用户访问系统的用户数,如多个用户在浏览网页,但没有对同时对服务器进行数据请求,需要与并发用户数区分开。
注册用户数:软件中已经注册的用户,这些用户是系统的潜在用户,随时都有可能上线。这个指标的意义在于让测试工程师了解系统数据中的数据总量和系统最大可能有多少用户同时在线。
平均的并发用户数C,计算公式C=nL/T
n:平均每天访问用户数(login session)
L:一天内用户从登录到退出的平均时间(login session的平均时间)
T:用户每天使用系统大概多长时间,考察时间长度(一天内多长时间有用户使用系统)
峰值C1,即并发用户峰值,计算公式C1=C+3*根号C,该公式遵循泊松分布理论。
/** 注:理解最佳并发用户数和最大并发用户数 看了《LoadRunner没有告诉你的》之理发店模式,对最佳并发用户数和最大的并发用户数的理解小小整理了一下。 所谓的理发店模式,简单地阐述一下, 一个理发店有3个理发师,当同时来理发店的客户有3个的时候,那么理发师的资源能够有效地利用,这时3个用户数即为最佳的并发用户数; 当理发店来了9个客户的时候,3个客户理发,而6个用户在等待,3个客户的等待时间为1个小时,另外的3个客户的等待时间为2小时,客户的最大忍受时间为3小时包括理发的1个小时,所以6个客户的等待时间都在客户的可以承受范围内,故9个客户是该理发店的最大并发用户数。 */
具体的随着并发用户数的增加,响应时间R,吞吐量X,资源利用U 情况如下图所示:

- Light Load(较轻压力)
- 最佳用户数(资源利用最高)
- Heavy Load(较重压力,系统可以持续工作,但用户等待时间较长,满意度会下降)
- 最大并发用户数
- Buckle Zone(用户无法忍受而放弃请求)
最佳并发用户数:当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待
最大并发用户数:系统的负载一直持续,有些用户在处理而有的用户在自己最大的等待时间内等待的时候
系统的平均负载:在特定的时间内,系统正在处理的用户数和等待处理的用户数的总和
峰值:指的是系统的最大能承受的用户数的极值
我们需要保证的是(反过来理解更容易):
(1)最佳并发用户数需大于系统的平均负载。如果系统的平均负载大于最佳并发用户数,则用户的满意度会下降,所以我们需要保证系统的平均负载小于或者等于最佳并发用户数
(2)系统的最大并发用户数要大于系统需要承受的峰值负载。只有最大并发用户数的大于系统所能承受的峰值负载,才不会造成等待空间资源的浪费,导致系统的效率低下
/** 补充: 并发一般分为2种情况。 1.严格意义上的并发,即所有的用户在同一时刻做同一件事情或者操作,这种操作一般指做同一类型的业务。比如在信用卡审批业务中,一定数目的拥护在同一时刻对已经完成的审批业务进行提交;还有一种特例,即所有用户进行完全一样的操作,例如在信用卡审批业务中,所有的用户可以一起申请业务,或者修改同一条记录。 2.广义范围的并发。这种并发与前一种并发的区别是,尽管多个用户对系统发出了请求或者进行了操作,但是这些请求或者操作可以是相同的,也可以是不同的。对整个系统而言,仍然是有很多用户同时对系统进行操作,因此也属于并发的范畴。 可以看出,后一种并发是包含前一种并发的。而且后一种并发更接近用户的实际使用情况,因此对于大多数的系统,只有数量很少的用户进行“严格意义上的并发”。对于WEB性能测试而言,这2种并发情况一般都需要进行测试,通常做法是先进行严格意义上的并发测试。严格意义上的用户并发一般发生在使用比较频繁的模块中,尽管发生的概率不是很大,但是一旦发生性能问题,后果很可能是致命的。严格意义上的并发测试往往和功能测试关联起来,因为并发功能遇到异常通常都是程序问题,这种测试也是健壮性和稳定性测试的一部分。 用户并发数量:关于用户并发的数量,有2种常见的错误观点。 一种错误观点是把并发用户数量理解为使用系统的全部用户的数量,理由是这些用户可能同时使用系统; 还有一种比较接近正确的观点是把在线用户数量理解为并发用户数量。 实际上在线用户也不一定会和其他用户发生并发,例如正在浏览网页的用户,对服务器没有任何影响,但是,在线用户数量是计算并发用户数量的主要依据之一。 */
Ramp-up time是规定所有用户在时间段内把请求发送完。
2.5 点击率(HPS)
每秒点击次数Hits Per Second,是指在一秒钟的时间内用户对Web页面的链接、提交按钮等点击总和。它一般和TPS成正比关系,是B/S系统中非常重要的性能指标之一。
点击数:指Web Server收到的HTTP请求数。
点击率:单位时间每秒用户向Web Server提交的HTTP请求数。
区分鼠标点击数:如请求一个网页,网页含有3张图片,向Web Server请求的点击数:1+3=4,而鼠标的一次点击就可以访问网页,点击数只有1次
2.6 业务成功率
2.7 错误率
一段时间内出错的请求在总请求数中的占比。
对于错误率的容忍程度,取决于不同的系统需求。那么一般错误又分情况:
1有返回值的错误,这里又要分是HTTP请求之类的错误,还是业务上的错误。这些可能出现错误的值需要在测试脚本里做校验,或者说断言。
2 没有返回值的错误,或者说就是超时。
有些请求会超时,那么不但会导致错误率的出现还会影响平均响应时间。
2.8 CAPS
每秒建立呼叫数量(Call Attempts Per Second)。
CAPS乘以3600就是BHCA(忙时呼叫量)了。 BHCA(Busy Hour Call Attempts)是忙时呼叫量的缩写,
主要测试内容为:在一小时之内,系统能建立通话连接的绝对数量值。
测试结果是一个极端能力的反映,它反映了设备的软件和硬件的综合性能。BHCA值最后体现为CAPS(每秒建立呼叫数量)。
2.9 PV
页面浏览量(Page View),或点击量。同一个人浏览你网站同一个页面,不重复计算pv量。pv就是一个访问者打开了你网站的几个页面。pv的计算:当一个访问者访问的时候,记录他所访问的页面和对应的IP,然后确定这个IP今天访问了这个页面没有。如果你的网站到了24点,单纯IP有60万条的话,每个访问者平均访问了3个页面,那么pv表的记录就要有180万条。
3.服务端-资源指标
指的是对不同的系统资源的使用程度,例如服务器的CPU利用率,磁盘利用率等.
资源利用率是分析系统性能指标进而改善性能的主要依据,因此是WEB性能测试工作的重点.
资源利用率主要针对WEB服务器,操作系统,数据库服务器,网络等,是测试和分析瓶颈的主要参考.
在实际测试中,通常会持续收集这些数据,如使用nmon,JMeter的PerfMon插件,以及zabbix等专门的系统监控工具
3.1 CPU
CPU的三个重要概念是我们需要关注的:使用率、运行队列和上下文切换
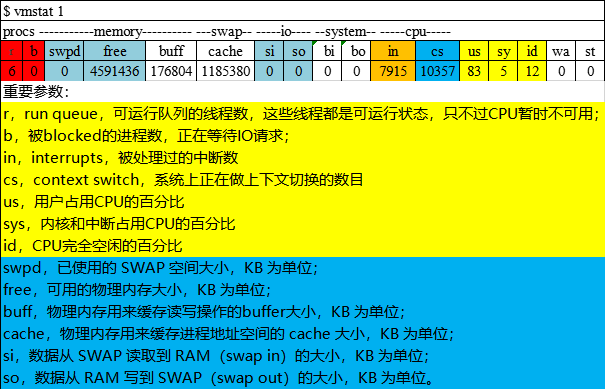
1. CPU使用率(CPU Utilization Percentages):有进程处于Running状态的时间/总时间。
/** 在vmstat主要通过us、sys和id三列数据来体现:
· us:用户占用CPU的百分比(消耗过高的原因可能是1.代码问题;2.GC消耗) · sy:系统(内核和中断)占用CPU的百分比(消耗高的原因上下文切换频繁。上下文切换发生的情况有:中断处理,多任务处理,用户状态改变。) · id:CPU空闲的百分比 性能测试指标中,CPU使用率通常用us + sy来计算,其可接受上限通常在70%~80%。
另外需要注意的是,在测试过程中,如果sy的值长期大于25%,应该关注in(系统中断)和cs(上下文切换)的数值,并根据被测应用的实现逻辑来分析是否合理。 */
2. 运行队列进程数(Processes on run queue):Running状态 + Waiting状态的进程数。
/**
展示了正在运行和等待CPU资源的任务数,可以看作CPU的工作清单,是判断CPU资源是否成为瓶颈的重要依据 vmstat通过r的值来体现: · r: 可运行进程数,包括正在运行(Running)和已就绪等待运行(Waiting)的。 如果r的值等于系统CPU总核数,则说明CPU已经满负荷。
在负载测试中,其可接受上限通常不超过CPU核数的2倍。 */
3. 上下文切换(Context Switches):简单来说,context指CPU寄存器和程序计数器在某时间点的内容,(进程)上下文切换即kernel挂起一个进程并将该进程此时的状态存储到内存,然后从内存中恢复下一个要执行的进程原来的状态到寄存器,从其上次暂停的执行代码开始继续执行至频繁的上下文切换将导致sy值增长。
/** vmstat通过cs的值来体现: · cs:每秒上下文切换次数。 */
4. 平均负载Load Average:在一段时间内的平均负载,系统工具top、uptime等提供1分钟、5分钟和15分钟的平均负载值。
/** 在UNIX系统中,Load是对系统工作量的度量。Load取值有两种情况,多数UNIX系统取运行队列的值(vmstat输出的r,Running), 而Linux系统取运行队列的值 + 处于task_uninterruptible状态的进程数(vmstat输出的b,Blocked),所以会出现CPU使用率不高但Load值很高的情况。
[hbase@ecs-097 ~]$ top
top - 19:23:28 up 18:05, 3 users, load average: 0.80, 0.60, 0.53
上面示例中的0.80即是1分钟内的Load average,以此类推。
当我们需要了解当前系统负载情况时,可以先查看Load average的值,
如果系统持续处于高负载(如15分钟平均负载大于CPU总核数的两倍),
则查看vmstat的r值和b值来确认是CPU负荷重还是等待I/O的进程太多。
*/
CPU良好状态指标:
-
- CPU利用率:User Time <= 70%,System Time <= 35%,User Time + System Time <= 70%。
- 上下文切换:与CPU利用率相关联,如果CPU利用率状态良好,大量的上下文切换也是可以接受的。
- 可运行队列:每个处理器的可运行队列<=3个线程。
3.2 内存
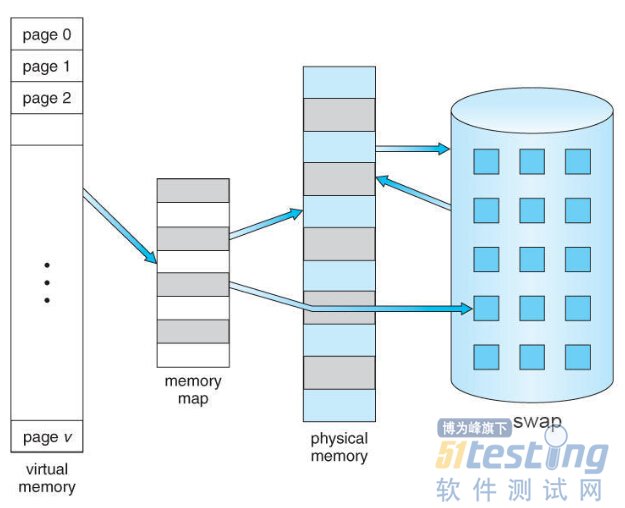
/** 内存包括物理内存和虚拟内存 物理内存和硬盘上的一块空间(SWAP)组合起来作为虚拟内存(Virtual Memory)为进程的运行提供一个连续的内存空间,
好处:进程可用的内存变大了,
缺点:SWAP的读写速度远低于物理内存,并且物理内存和swap之间的数据交换会增加系统负担。 虚拟内存被分成页(x86系统默认页大小为4k),内核读写虚拟内存以页为单位,当物理内存空间不足时,内存调度会将物理内存上不常使用的内存页数据存储到磁盘的SWAP空间,物理内存与swap空间之间的数据交换过程称为页面交换(Paging)。 */
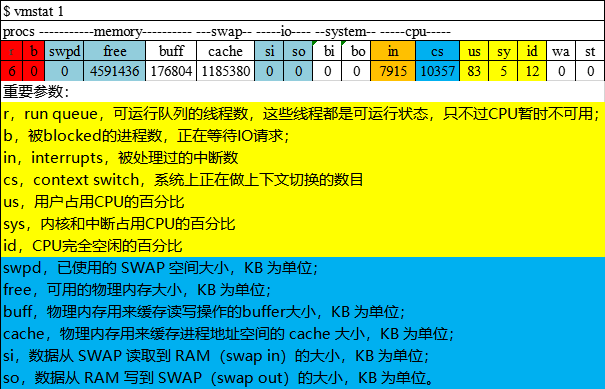
/** vmstat输出free的值,可用内存过小将影响整个系统的运行效率 对于稳定运行的系统,free可接受的范围通常应该大于物理内存的20%,即内存占用应该小于物理内存的80%。 在压力测试时,系统内存资源的情况应该用可用内存结合页面交换情况来判断,如果可用内存很少,但页面交换也很少,此时可以认为内存资源还对系统性能构成严重影响。 */
2. SWAP空间占用:
/** 可以从vmstat的swpd来获取当前SWAP空间的使用情况, 应该和页面交换结合来分析,比如当swpd不为0,但si,so持续保持为0时,内存资源并没有成为系统的瓶颈。 */
3. 页面交换(Paging):页面交换包括从SWAP交换到内存和从内存交换到SWAP,如果系统出现频繁的页面交换,需要引起注意。
/** 可以从vmstat的si和so获取: · si:每秒从SWAP读取到内存的数据大小 · so:每秒从内存写入到SWAP的数据大小 */
Memory良好状态指标
- swap in (si) == 0,swap out (so) == 0
- 应用程序可用内存/系统物理内存 <= 70%
3.3 Disk I/O

/**
磁盘通常是系统中最慢的一环,
一是其自身速度慢,即使是SSD(固态硬盘),其读写速度与内存都还存在数量级的差距,
二是其离CPU最远。另外需要说明的是磁盘IO分为随机IO和顺序IO两种类型,在性能测试中应该先了解被测系统是偏向哪种类型。
随机IO:随机读写数据,读写请求多,每次读写的数据量较小,其IO速度更依赖于磁盘每秒能IO次数(IOPS)。
顺序IO:顺序请求大量数据,读写请求个数相对较少,每次读写的数据量较大,顺序IO更重视每次IO的数据吞吐量(每秒数据量)。
*/
良好状态指标
iowait % < 20%
提高命中率的一个简单方式就是增大文件缓存区面积,缓存区越大预存的页面就越多,命中率也越高。Linux 内核希望能尽可能产生次缺页中断(从文件缓存区读),并且能尽可能避免主缺页中断(从硬盘读),这样随着次缺页中断的增多,文件缓存区也逐步增大,直到系统只有少量可用物理内存的时候 Linux 才开始释放一些不用的页。
磁盘I/O高居不下,通过什么来查看占用I/O的进程?iotop,监视磁盘I/O使用状况的top类工具。
3.4 Network I/O
网络本身是系统中一个非常复杂的部分,但常规的服务端性能测试通常放在一个局域网进行,因为我们首先关注被测系统自身的性能表现,并且需要保证能在较少的成本下发起足够大的压力。
因此对于多数系统的性能测试,我们主要关注网络吞吐量即可,对于稳定运行的系统,需要为被测场景外的业务留出足够的带宽;在压力测试过程中,需要注意瓶颈可能来自于带宽。
1. 在Linuxf服务器,可以使用iptraf来查看本机网络吞吐量,如:
/** [root@ecs-097 ~]# iptraf -d eth0 x Total rates: 67.8 kbits/sec Broadcast packets: 0x x 54.2 packets/sec Broadcast bytes: 0x x x Incoming rates: 19.2 kbits/sec x x 25.4 packets/sec x x IP checksum errors: 0 x x Outgoing rates: 48.7 kbits/sec x x 28.8 packets/sec */
2. 网络带宽:单位时间(一般指的是1秒钟)内能传输的数据量。
服务器网卡一般都是千兆,我们可以确认一下,先用ifconfig来看下当前服务器的网卡,是eth0;另外,lo是本地环路接口。
用ethtool查询网卡信息,下面显示的速度Speed是1000Mb/s,注意,这里是Mb,不是MB。
通过sar命令(sar -n DEV 1)查看网络情况,rxkB/s表示每秒接收的数据量。
也可以使用tcpdump抓包,然后Wireshark分析tcpdump抓包结果
3. 良好状态指标
对于UDP:接收、发送缓冲区不长时间有等待处理的网络包。 watch netstat -su
对于TCP:不会出现因为缓存不足而存在丢包的事,因为网络等其他原因,导致丢了包,协议层也会通过重传机制来保证丢的包到达对方。所以,tcp而言更多的专注重传率。
cat /proc/net/snmp | grep Tcp:
4. 通用指标
通用指标(指Web应用服务器、数据库服务器必需测试项)

5. Web服务器指标
6. 数据库服务器指标

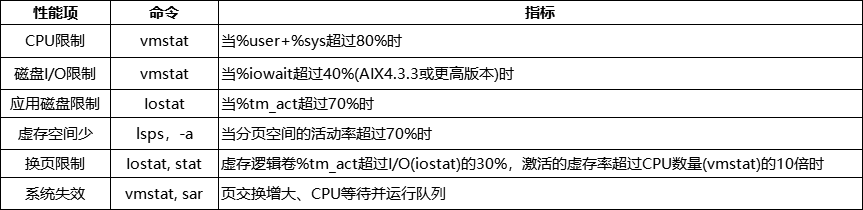
7. 系统的瓶颈定义
8. 网址测试标准
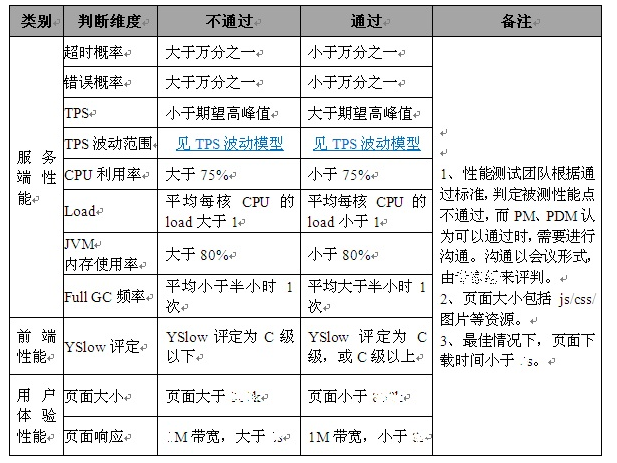
9. 性能测试通过标准
1、所有计划的测试已经完成。
2、所有计划收集的性能数据已经获得。
3、所有性能瓶颈得到改善并达到设计要求。
针对规定的功能模块进行性能测试,分析在最大用户的情况下,事务的90 Percent Time值,是否在2、5、8s以内,服务器的CPU使用率<=75%,内存使用率<=70%,事务的通过率=100%。
10. 经典性能测试场景
tps常常是有限制的,如cpu<80%,内存<60%时的tps
cpu使用率和内存占用率往往是默认的或取经验值

容量测试:一般可设置运行1小时
压力测试:一般可设置10分钟
稳定测试:7*24小时、5*24小时
很不明确的需求:一般测试最大TPS
11. 性能测试用例(框架)

12. 性能调优的本质
- 拿时间换空间
- 拿空间换时间
时间:响应时间
空间:缓存
摘录网址
- 性能测试中服务器关键性能指标浅析(1)
- 性能测试中服务器关键性能指标浅析(2)
- 软件测试网-性能测试
- 泽众软件
- 常见的性能测试指标
- Performance Testing Guidance for Web Applications
- blazemeter:https://www.blazemeter.com/blazemeter/
- web性能测试基本性能指标
- 性能测试指标
- 性能测试基础
- 性能测试的指标