
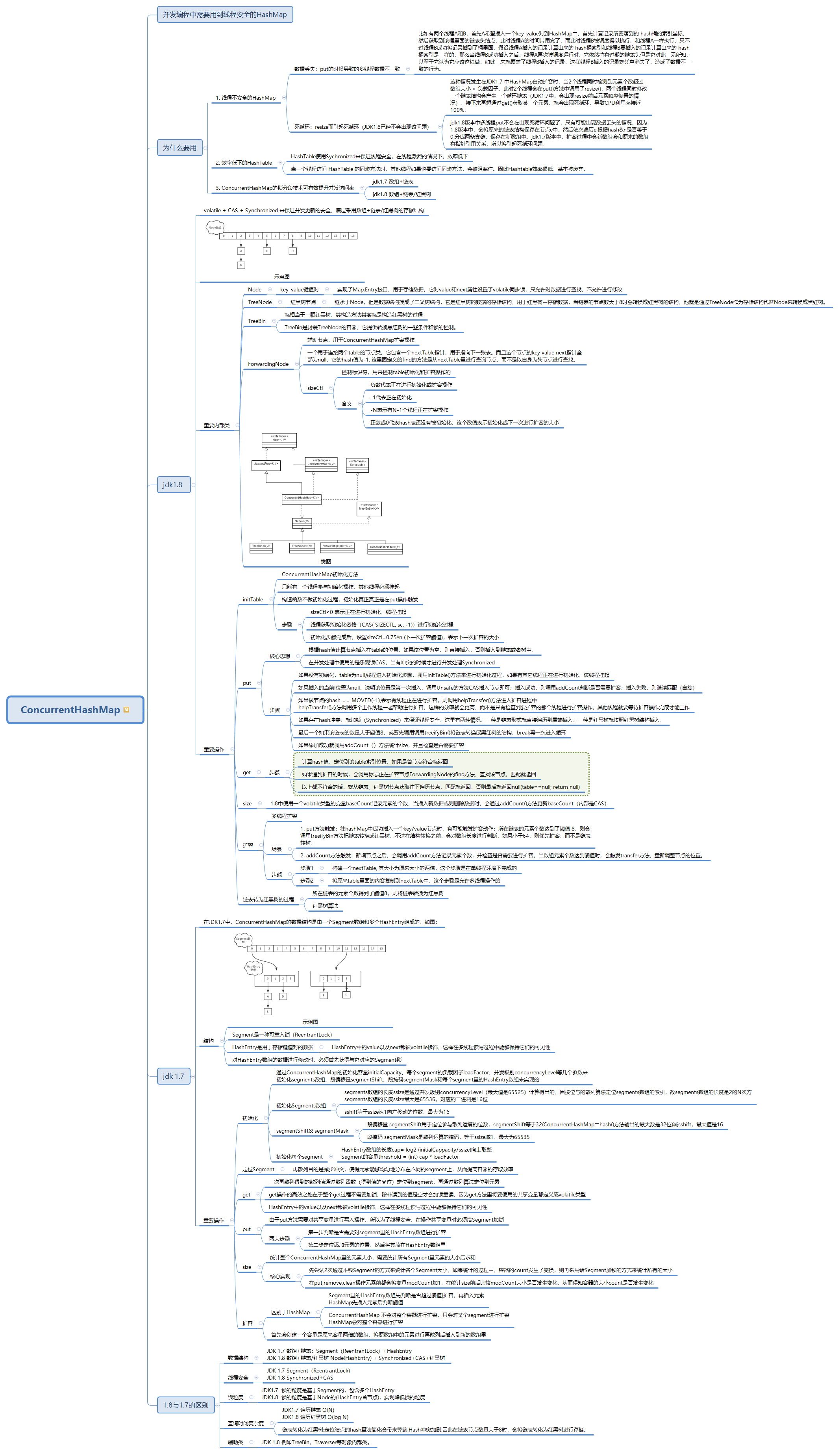
1. ConcurrentHashMap
2. ConcurrentLinkedQueue
3. ConcurrentSkipListMap
4. ConcurrentSkipListSet
5. txt


1 java 并发容器 2 ConcurrentHashMap 3 并发编程中需要用到线程安全的HashMap 4 为什么要用 5 1. 线程不安全的HashMap 6 数据丢失:put的时候导致的多线程数据不一致 7 比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。 8 死循环:resize而引起死循环(JDK1.8已经不会出现该问题) 9 这种情况发生在JDK1.7 中HashMap自动扩容时,当2个线程同时检测到元素个数超过 数组大小 × 负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过get()获取某一个元素,就会出现死循环,导致CPU利用率接近100%。 10 jdk1.8版本中多线程put不会在出现死循环问题了,只有可能出现数据丢失的情况,因为1.8版本中,会将原来的链表结构保存在节点e中,然后依次遍历e,根据hash&n是否等于0,分成两条支链,保存在新数组中。jdk1.7版本中,扩容过程中会新数组会和原来的数组有指针引用关系,所以将引起死循环问题。 11 2. 效率低下的HashTable 12 HashTable使用Sychronized来保证线程安全,在线程激烈的情况下,效率低下 13 当一个线程访问 HashTable 的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。因此Hashtable效率很低,基本被废弃。 14 3. ConcurrentHashMap的锁分段技术可有效提升并发访问率 15 jdk1.7 数组+链表 16 jdk1.8 数组+链表/红黑树 17 jdk1.8 18 volatile + CAS + Synchronized 来保证并发更新的安全,底层采用数组+链表/红黑树的存储结构 19 示意图 20 重要内部类 21 Node 22 key-value键值对 23 实现了Map.Entry接口,用于存储数据。它对value和next属性设置了volatile同步锁,只允许对数据进行查找,不允许进行修改 24 TreeNode 25 红黑树节点 26 继承于Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构,他就是通过TreeNode作为存储结构代替Node来转换成黑红树。 27 TreeBin 28 就相当于一颗红黑树,其构造方法其实就是构造红黑树的过程 29 TreeBin是封装TreeNode的容器,它提供转换黑红树的一些条件和锁的控制。 30 ForwardingNode 31 辅助节点,用于ConcurrentHashMap扩容操作 32 一个用于连接两个table的节点类。它包含一个nextTable指针,用于指向下一张表。而且这个节点的key value next指针全部为null,它的hash值为-1. 这里面定义的find的方法是从nextTable里进行查询节点,而不是以自身为头节点进行查找。 33 sizeCtl 34 控制标识符,用来控制table初始化和扩容操作的 35 含义 36 负数代表正在进行初始化或扩容操作 37 -1代表正在初始化 38 -N表示有N-1个线程正在扩容操作 39 正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小 40 类图 41 重要操作 42 initTable 43 ConcurrentHashMap初始化方法 44 只能有一个线程参与初始化操作,其他线程必须挂起 45 构造函数不做初始化过程,初始化真正真正是在put操作触发 46 步骤 47 sizeCtl<0 表示正在进行初始化,线程挂起 48 线程获取初始化资格(CAS( SIZECTL, sc, -1))进行初始化过程 49 初始化步骤完成后,设置sizeCtl=0.75*n (下一次扩容阈值),表示下一次扩容的大小 50 put 51 核心思想 52 根据hash值计算节点插入在table的位置,如果该位置为空,则直接插入,否则插入到链表或者树中。 53 在并发处理中使用的是乐观锁CAS,当有冲突的时候才进行并发处理Synchronized 54 步骤 55 如果没有初始化,table为null,线程进入初始化步骤,调用initTable()方法来进行初始化过程,如果有其它线程正在进行初始化,该线程挂起 56 如果插入的当前I位置为null,说明该位置是第一次插入,调用Unsafe的方法CAS插入节点即可;插入成功,则调用addCount判断是否需要扩容;插入失败,则继续匹配(自旋) 57 如果该节点的hash == MOVED(-1),表示有线程正在进行扩容,则调用helpTransfer()方法进入扩容进程中 58 helpTransfer()方法调用多个工作线程一起帮助进行扩容,这样的效率就会更高,而不是只有检查到要扩容的那个线程进行扩容操作,其他线程就要等待扩容操作完成才能工作 59 如果存在hash冲突,就加锁(Synchronized)来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入, 60 最后一个如果该链表的数量大于阈值8,就要先调用调用treeifyBin()将链表转换成黑红树的结构,break再一次进入循环 61 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容 62 get 63 步骤 64 计算hash值,定位到该table索引位置,如果是首节点符合就返回 65 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回 66 以上都不符合的话,就从链表、红黑树节点获取往下遍历节点,匹配就返回,否则最后就返回null(table==null; return null) 67 size 68 1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount(内部是CAS) 69 扩容 70 多线程扩容 71 场景 72 1. put方法触发:往hashMap中成功插入一个key/value节点时,有可能触发扩容动作:所在链表的元素个数达到了阈值 8,则会调用treeifyBin方法把链表转换成红黑树,不过在结构转换之前,会对数组长度进行判断,如果小于64,则优先扩容,而不是链表转树。 73 2. addCount方法触发:新增节点之后,会调用addCount方法记录元素个数,并检查是否需要进行扩容,当数组元素个数达到阈值时,会触发transfer方法,重新调整节点的位置。 74 步骤 75 步骤1 76 构建一个nextTable, 其大小为原来大小的两倍,这个步骤是在单线程环境下完成的 77 步骤2 78 将原来table里面的内容复制到nextTable中,这个步骤是允许多线程操作的 79 链表转为红黑树的过程 80 所在链表的元素个数得到了阈值8,则将链表转换为红黑树 81 红黑树算法 82 jdk 1.7 83 在JDK1.7中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成的,如图: 84 结构 85 示例图 86 Segment是一种可重入锁(ReentrantLock) 87 HashEntry是用于存储键值对的数据 88 HashEntry中的value以及next都被volatile修饰,这样在多线程读写过程中能够保持它们的可见性 89 对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁 90 重要操作 91 初始化 92 通过ConcurrentHashMap的初始化容量initialCapacity、每个segment的负载因子loadFactor、并发级别concurrencyLevel等几个参数来 93 初始化segments数组、段偏移量segmentShift、段掩码segmentMask和每个segment里的HashEntry数组来实现的 94 初始化Segments数组 95 segments数组的长度ssize是通过并发级别concurrencyLevel(最大值是65525)计算得出的,因按位与的散列算法定位segments数组的索引,故segments数组的长度是2的N次方 96 segments数组的长度ssize最大是65536,对应的二进制是16位 97 sshift等于ssize从1向左移动的位数,最大为16 98 segmentShift& segmentMask 99 段偏移量 segmentShift用于定位参与散列运算的位数,segmentShift等于32(ConcurrentHashMap中hash()方法输出的最大数是32位)减sshift,最大值是16 100 段掩码 segmentMask是散列运算的掩码,等于ssize减1,最大为65535 101 初始化每个segment 102 HashEntry数组的长度cap= log2 (initialCappacity/ssize)向上取整 103 Segment的容量threshold = (int) cap * loadFactor 104 定位Segment 105 再散列目的是减少冲突,使得元素能够均匀地分布在不同的segment上,从而提高容器的存取效率 106 get 107 一次再散列得到的散列值通过散列函数(得到值的高位)定位到segment,再通过散列算法定位到元素 108 get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读,因为get方法里将要使用的共享变量都定义成volatile类型 109 HashEntry中的value以及next都被volatile修饰,这样在多线程读写过程中能够保持它们的可见性 110 put 111 由于put方法需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须给Segment加锁 112 两大步骤 113 第一步判断是否需要对segment里的HashEntry数组进行扩容 114 第二步定位添加元素的位置,然后将其放在HashEntry数组里 115 size 116 统计整个ConcurrentHashMap里的元素大小,需要统计所有Segment里元素的大小后求和 117 核心实现 118 先尝试2次通过不锁Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变换,则再采用给Segment加锁的方式来统计所有的大小 119 在put,remove,clean操作元素前都会将变量modCount加1,在统计size前后比较modCount大小是否发生变化,从而得知容器的大小count是否发生变化 120 扩容 121 区别于HashMap 122 Segment里的HashEntry数组先判断是否超过阈值|扩容,再插入元素 123 HashMap先插入元素后判断阈值 124 ConcurrentHashMap 不会对整个容器进行扩容,只会对某个segment进行扩容 125 HashMap会对整个容器进行扩容 126 首先会创建一个容量是原来容量两倍的数组,将原数组中的元素进行再散列后插入到新的数组里 127 1.8与1.7的区别 128 数据结构 129 JDK 1.7 数组+链表:Segment(ReentrantLock)+HashEntry 130 JDK 1.8 数组+链表/红黑树 Node(HashEntry) + Synchronized+CAS+红黑树 131 线程安全 132 JDK 1.7 Segment(ReentrantLock) 133 JDK 1.8 Synchronized+CAS 134 锁粒度 135 JDK1.7 锁的粒度是基于Segment的,包含多个HashEntry 136 JDK1.8 锁的粒度是基于Node的(HashEntry首节点),实现降低锁的粒度 137 查询时间复杂度 138 JDK1.7 遍历链表 O(N) 139 JDK1.8 遍历红黑树 O(log N) 140 链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。 141 辅助类 142 JDK 1.8 例如TreeBin,Traverser等对象内部类。 143 ConcurrentLinkedQueue 144 并发编程中需要用到线程安全的队列 145 1. 使用阻塞算法 146 1个锁(入队和出队用同一把锁)和2个锁(入队和出队用不同的锁) 147 阻塞队列 148 2. 使用非阻塞算法 149 CAS 150 ConcurrentLinkedQueue 151 结构 152 由head和tail节点组成,每个节点Node由节点元素item和指向下一个节点next的引用组成,他们四个都是volatile 153 默认情况下head节点存储的元素为空,tail节点等于head节点 154 基于链接节点的无边界的线程安全队列,采用FIFO原则对元素进行排序,内部采用CAS算法实现 155 重要操作 156 入队 offer() 157 入队列就是将入队节点添加到队列的尾部 158 3大步骤 159 1. 定位尾节点 160 tail节点不总是尾节点,通过tail节点来找到尾节点,尾节点可能是tail节点,也可能是tail节点的next节点 161 2. 设置入队节点为尾节点 162 使用CAS算法将入队节点设置成当前队列尾节点的下一个节点 163 3. 更新tail节点 164 如果tail节点的next不为空,则将入队节点设置成tail节点 165 如果tail节点的next节点为空,则将入队节点设置成tail节点的next节点 166 HOPS 167 tail节点不总是尾节点,提高入队的效率 168 减少CAS更新tail节点的次数能提高入队的效率,使用hops常量来控制并减少tail节点的更新频率,并不是每次节点入队后都将tail节点更新为尾节点,而是当tail节点和尾节点的距离大于等于常量HOPS的值(默认等于1)时才更新tail节点, 169 tail和尾节点的距离越长,使用CAS更新tail节点的次数就会少,但是距离越长带来的负面影响就是每次入队时定位尾节点的时间就越长,但这样仍然能提高入队的效率 170 因为本质上它通过增加对volatile变量的读操作来减少对volatile变量的写操作,而对volatile变量的写操作开销要远大于读操作,多以入队的效率会有所提升 171 注意:入队方法永远返回true,所哟不要通过返回值判断入队是否成功 172 出队 poll() 173 出队列就是从队列里返回一个节点元素,并清空该节点对元素的引用 174 HOPS 175 并不是每次出队时都更新head节点 176 当head节点里有元素时,直接弹出head节点里的元素,并不会更新head节点。 177 只有head节点里面没有元素时,出队操作才会更新head节点 178 这种做法通过hops变量来减少使用CAS更新head节点的消耗,从而提高出队效率 179 不变性 180 在入队的最后一个元素的next为null 181 队列中所有未删除的节点的item都不能为null且都能从head节点遍历到 182 对于要删除的节点,不是直接将其设置为null而是先将其item域设置为null(迭代器会跳过item为null的节点) 183 允许head和tail更新滞后。head、tail不总是指向第一个元素和最后一个元素 184 head的不变性和可变性 185 不变性 186 所有未删除的节点都可以通过head节点遍历到 187 head不能为null 188 head节点的next不能指向自身 189 可变性 190 head的item可能为null,也可能不为null 191 允许tail滞后head,也就是说调用succc()方法,从head不可达tail 192 tail的不变性和可变性 193 不变性 194 tail不能为null 195 可变性 196 tail的item可能为null,也可能不为null 197 tail节点的next域可以指向自身 198 允许tail滞后head,也就是说调用succc()方法,从head不可达tail 199 精妙之处:利用CAS来完成数据操作,同时允许队列的不一致性,弱一致性表现淋漓尽致。 200 ConcurrentSkipListMap 201 java里面的3 个 key-value数据结构 202 HashMap 203 Hash表:插入、查找最快,为O(1);如使用链表实现则可实现无锁;数据有序化需要显式的排序操作 204 TreeMap 205 红黑树:插入、查找为O(logn),但常数项较小;无锁实现的复杂性很高,一般需要加锁;数据天然有序 206 SkipList 207 Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。 208 Skip List(跳跃表)是一种支持快速查找的数据结构,插入、查找和删除操作都仅仅只需要O(log n)对数级别的时间复杂度 209 SkipList让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,通过“空间换时间”的一个算法,在每个节点中增加了向前的指针,在插入、删除、查找时可以忽略一些不可能涉及到的结点,从而提高了效率。 210 特性 211 由很多层结构组成,level是通过一定的概率随机产生的 212 每一层都是一个有序的链表,默认是升序,也可以根据创建映射时所提供的Comparator进行排序,具体取决于使用的构造方法 213 最底层(Level1)的链表包含所有元素 214 如果一个元素出现在Level i 的链表中,则它在Level I 之下的链表也都会出 215 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下一层的元素 216 查找、删除、添加 217 实现 218 ConcurrentSkipListMap其内部采用SkipLis数据结构实现。 219 内部类 220 Node 221 Node表示最底层的单链表有序节点 222 key-value和一个指向下一个节点的next。 223 Index 224 Index表示为基于Node的索引层 225 Index提供了一个基于Node节点的索引Node,一个指向下一个Index的right,一个指向下层的down节点。 226 HeadIndex 227 HeadIndex用来维护索引层次 228 重要操作 229 put 230 首先通过findPredecessor()方法找到前辈节点Node 231 根据返回的前辈节点以及key-value,新建Node节点,同时通过CAS设置next 232 设置节点Node,再设置索引节点。采取抛硬币方式决定层次,如果所决定的层次大于现存的最大层次,则新增一层,然后新建一个Item链表。 233 最后,将新建的Item链表插入到SkipList结构中。 234 get 235 首先调用findPredecessor()方法找到前辈节点,然后顺着right一直往右找即可 236 remove 237 调用findPredecessor()方法找到前辈节点,然后通过右移,然后比较,找到后利用CAS把value替换为null 238 然后判断该节点是不是这层唯一的index,如果是的话,调用tryReduceLevel()方法把这层干掉,完成删除。 239 size 240 ConcurrentSkipListMap的size()操作和ConcurrentHashMap不同,它并没有维护一个全局变量来统计元素的个数,所以每次调用该方法的时候都需要去遍历。 241 调用findFirst()方法找到第一个Node,然后利用node的next去统计。最后返回统计数据,最多能返回Integer.MAX_VALUE。注意这里在线程并发下是安全的。 242 ConcurrentSkipListMap是通过HeadIndex维护索引层次,通过Index从最上层开始往下层查找,一步一步缩小查询范围,最后到达最底层Node时,就只需要比较很小一部分数据了。 243 ConcurrentSkipListSet 244 内部采用ConcurrentSkipListMap实现