1. 工作原理(定义)
快速排序(Quicksort)是对冒泡排序的一种改进。(分治法策略)
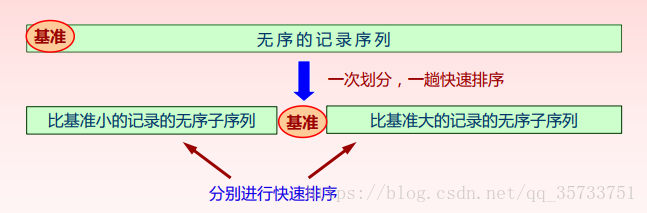
2. 算法步骤
实现方法两种方法:挖坑法和指针交换法
基准的选择三种方法:1.选择最左边记录 2.随机选择 3.选择平均值
2.1 挖坑法
- 设置两个变量i、j,排序开始的时候:i=0,j=N-1;
- 以第一个数组元素作为关键数据,赋值给key,即key=A[0];
- 从j开始向前搜索,即由后开始向前搜索(j--),找到第一个小于key的值A[j],将A[j]和A[i]的值交换;
- 从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于key的A[i],将A[i]和A[j]的值交换;
- 重复第3、4步,直到i=j;
【3,4步中,没找到符合条件的值,即3中A[j]不小于key,4中A[i]不大于key的时候改变j、i的值,使得j=j-1,i=i+1,直至找到为止。找到符合条件的值,进行交换的时候i, j指针位置不变。另外,i==j这一过程一定正好是i+或j-完成的时候,此时令循环结束】。 pivot

2.2 指针交换法

2.3 基准的选择
- 选择最左边记录 : 给定的待排序列是一个随机,无序的序列,那么这种选择策略是可以接受的。但如果这个序列是一个正序或逆序的,还是以选择最左边记录作为基准的策略的话,这将会产生一个非常极端,糟糕的情况
- 随机选择
- 选择平均值
3. 动画演示
4. 性能分析
基准的选择对于快速排序算法来说是非常重要的,虽然选择任何一个元素作为基准都可以完成排序,但是好的基准的选择能最大发挥快速排序算法的性能,而不好的基准选择则会让快速排序的性能大打折扣,甚至变成”慢速”排序。因此在选择基准上,最好的情况就是尽量选择能均匀划分子序列的基准(即尽量使子序列相等)。
1. 时间复杂度
快速排序的时间性能取决于快速排序递归的深度,递归过程中,子序列越平衡,则性能越好
(1)最优情况下时,递归过程形成的递归树是一课平衡树,快速排序算法的时间复杂度为O(nlogn)。
(2)最坏情况下时,递归过程形成的递归树是一课斜树,快速排序算法的时间复杂度为O(n2)。
(3)平均情况下,时间复杂度为O(nlogn)。
2. 空间复杂度
就空间复杂度来说,主要是递归造成的栈空间的使用。
(1)最好情况,递归树的深度为log2n,其空间复杂度也就为O(logn)。
(2)最坏情况,需要进行n‐1递归调用,其空间复杂度为O(n)。
(3)平均情况,空间复杂度也为O(logn)。
3. 算法稳定性
快速排序在排序过程中,由于基准数的比较和交换是跳跃进行的,因此,快速排序是一种不稳定的排序算法。
4. 初始顺序状态
- 比较次数:
- 移动次数:
- 复杂度:
- 排序趟数:
5. 归位
能归位,每一趟排序有一个元素归位。
6. 优点
6. 改进算法
在有序或者接近有序的时候上面的方法效率会非常低(摘录自百度百科)
- 三数取中法:在待排序序列的第一个元素,中间元素和最后一个元素中取大小位于中间的那个元素。
-
根据分区大小调整算法:在递归子问题的时候在区间内的数据比较少的时候我们可以不再划分区间,直接用直接插入排序或者堆排序等算法效率会更高,因为接着划分又要创建栈桢,没有必要。在递归排序子分区的时候,总是选择优先排序那个最小的分区。这个选择能够更加有效的利用存储空间从而从整体上加速算法的执行。
-
不同的分区方案考虑:相同元素很多的情况下,将分区分为三块而不是原来的两块:一块是小于中轴值的所有元素,一块是等于中轴值的所有元素,另一块是大于中轴值的所有元素。另一种简单的改进方法是,当分区完成后,如果发现最左和最右两个元素值相等的话就避免递归调用而采用其他的排序算法来完成。
-
并行的快速排序:由于快速排序算法是采用分治技术来进行实现的,这就使得它很容易能够在多台处理机上并行处理。
在大多数情况下,创建一个线程所需要的时间要远远大于两个元素比较和交换的时间,因此,快速排序的并行算法不可能为每个分区都创建一个新的线程。一般来说,会在实现代码中设定一个阀值,如果分区的元素数目多于该阀值的话,就创建一个新的线程来处理这个分区的排序,否则的话就进行递归调用来排序。
对于这一并行快速排序算法也有其改进。该算法的主要问题在于,分区的这一步骤总是要在子序列并行处理之前完成,这就限制了整个算法的并行程度。解决方法就是将分区这一步骤也并行处理。改进后的并行快速排序算法使用2n个指针来并行处理分区这一步骤,从而增加算法的并行程度。
7. 具体代码
public class QuickSort { /** * 快排递归 * @param arr 待排序的数组 * @param left 数组的左边界(例如,从起始位置开始排序,则l=0) * @param right 数组的右边界(例如,排序截至到数组末尾,则right=arr.length-1) */ public static void quickSort(int[] arr, int left, int right) { if (left< right) { int index = getPartitionIndex2(arr, left, right);/* 获取分区索引 */ quickSort(arr, left, index-1); /* 递归调用 */ quickSort(arr, index+1, right); /* 递归调用 */ } } //快速排序--挖坑法 获取分区索引的 public static int getPartitionIndex1(int[] arr, int left, int right) { int low,high,pivot; low = left; high = right; dealPivot(arr, left, right);//三数中值 pivot = arr[left]; //最左基准 while (low < high) { while(low < high && arr[high] > pivot) high--; // 从右向左找第一个小于pivot的数 if(low < high) arr[low++] = arr[high]; while(low < high && arr[low] < pivot) low++; // 从左向右找第一个大于pivot的数 if(low < high) arr[high--] = arr[low]; } arr[low] = pivot; return low; } //快速排序--指针交换法 获取分区索引的 public static int getPartitionIndex2(int[] arr, int left, int right) { int low,high,pivot; low = left; high = right; dealPivot(arr, left, right);//三数中值 pivot = arr[left];//最左基准 while (low < high) { while(low < high && arr[high] > pivot) high--; // 从右向左找第一个小于pivot的数 while(low < high && arr[low] <= pivot) low++; // 从左向右找第一个大于等于pivot的数 if(low < high) swap(arr, low, high); } // 此时right和left值是相同的,将基准元素与重合位置元素交换 arr[left] = arr[low]; arr[low] = pivot; return low; } //三数取中法,也就是取左端、中间、右端三个数,然后进行排序,将中间数作为枢纽值。将中间数放在了left位置上 public static void dealPivot(int[] arr, int left, int right) { int mid = (left + right) / 2; if (arr[left] > arr[mid]) {//左端小于中间 swap(arr, left, mid); } if (arr[left] > arr[right]) {//左端小于右边 swap(arr, left, right); } if (arr[right] < arr[mid]) {//右边大于中间 swap(arr, right, mid); } swap(arr, left, mid);//左边《中间《右边 将中间的值换到左边 } // 交换数组中的两个数 public static void swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } public static void main(String[] args){ int[] arr = { 49, 38, 65, 97, 76, 13, 27, 50 }; quickSort(arr,0,arr.length-1); System.out.println("排好序的数组:"); for (int e : arr) System.out.print(e+" "); } }