1. Java List
1. Java List重要观点
- Java List接口是Java Collections Framework的成员。
- List允许您添加重复元素。
- List允许您拥有'null'元素。
- List接口在Java 8中有许多默认方法,例如replaceAll,sort和spliterator。
- 列表索引从0开始,就像数组一样。
- List支持泛型(类型的参数化),我们应尽可能使用它。将Generics与List一起使用将在运行时避免ClassCastException。
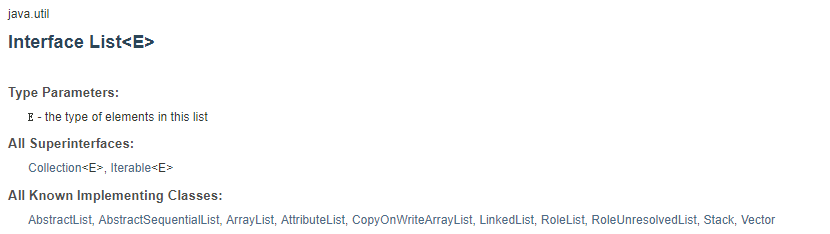
2. Java列表类图
Java List接口扩展了Collection接口。Collection接口 externs Iterable接口。
一些最常用的List实现类是ArrayList,LinkedList,Vector,Stack,CopyOnWriteArrayList。
AbstractList提供了List接口的骨干实现,以减少实现List的工作量。
3. Java List方法
- int size():获取列表中元素的数量。
- boolean isEmpty():检查列表是否为空。
- boolean contains(Object o):如果此列表包含指定的元素,则返回true。
- Iterator <E> iterator():以适当的顺序返回此列表中元素的迭代器。
- Object [] toArray():以适当的顺序返回包含此列表中所有元素的数组
- boolean add(E e):将指定的元素追加到此列表的末尾。
- boolean remove(Object o):从此列表中删除指定元素的第一个匹配项。
- boolean retainAll(Collection <?> c):仅保留此列表中包含在指定集合中的元素。
- void clear():从列表中删除所有元素。
- E get(int index):返回列表中指定位置的元素。
- E set(int index,E element):用指定的元素替换列表中指定位置的元素。
- ListIterator <E> listIterator():返回列表中元素的列表迭代器。
- List <E> subList(int fromIndex,int toIndex):返回指定fromIndex(包含)和toIndex(不包括)之间的此列表部分的视图。返回的列表由此列表支持,因此返回列表中的非结构更改将反映在此列表中,反之亦然。
在Java 8中添加到List的一些默认方法是;
- default void replaceAll(UnaryOperator <E>运算符):将此列表的每个元素替换为将运算符应用于该元素的结果。
- default void sort(Comparator <super E> c):根据指定的Comparator引发的顺序对此列表进行排序。
- default Spliterator <E> spliterator():在此列表中的元素上创建Spliterator。
2. ArrayList
1. ArrayList 结构图
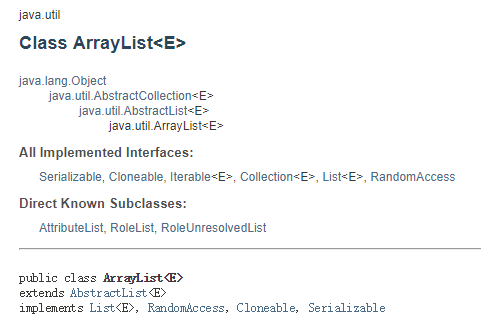
ArrayList基于数组实现,是一个动态的数组链表。但是它和Java中的数组又不一样,它的容量可以自动增长,类似于C语言中动态申请内存,动态增长内存!
ArrayList继承了AbstractList,实现了RandomAccess、Cloneable和Serializable接口!
- 实现了RandomAccess接口,提供了随机访问功能,实际上就是通过下标序号进行快速访问,因此查找效率高。
- 实现了Cloneable接口,即覆盖了函数clone(),实现浅拷贝。
- 实现了Serializable接口,支持序列化,也就意味了ArrayList能够通过序列化传输。
2. ArrayList 重要特点
- 本质实现:Object类型的动态的数组。
- 线程安全:非同步的。
- 列表长度:ArrayList中元素个数用size记录。
- 扩展容量:初始化容量 = 10 ,最大容量不会超过 MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8!【Integer.MAX_VALUE = 0x7fffffff,换算成二进制: 2^31 - 1,十进制就是 :2147483647,二十一亿多。一些虚拟器需要在数组前加个 头标签,所以减去 8 。 当想要分配比 MAX_ARRAY_SIZE 大的个数就会报 OutOfMemoryError。】当ArrayList容量不足以容纳全部元素时,ArrayList会重新设置容量:JDK1.6 int newCapacity = (oldCapacity * 3) /2 + 1; JDK1.8 int newCapacity = oldCapacity + (oldCapacity >> 1); 当容量不够时,调用ensureCapacity(int minCapacity)方法调整列表容量,每次增加元素,都要将原来的元素拷贝到一个新的数组中,使用Arrays.copyOf(elementData, newCapacity)拷贝 ,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用LinkedList。我们可以主动调用 ensureCapcity 来增加 ArrayList 对象的容量,这样就避免添加元素满了时扩容、挨个复制后移等消耗。
- 3种构造方法:1)构造一个默认初始容量为10的空列表; 2) 构造一个指定初始容量的空列表; 3) 构造一个包含指定collection的元素的列表,内部是Arrays.copyOf(elementData, size, Object[].class);。
- 5种存储方法:1)set(int index, E element)、2)add(E e)、3)add(int index, E element)、4)addAll(Collection<? extends E> c)、5)addAll(int index, Collection<? extends E> c) 其中3,4,5调用了 System.arraycopy()。
- 2种删除方法:1) remove(int index) ;2)remove(Object o)
- 转换成数组:toArray()方法内部调用Arrays.copyOf(),toArray(T[] a)方法内部如果是部分转换用Arrays.copyOf(),全部转换用 System.arraycopy()。
- 遍历方法:遍历时 get 的效率要 >= 迭代器。
- Fail-Fast机制:ArrayList 不是同步的,所以在并发访问时,如果在迭代器迭代的同时有其他线程修改了 ArrayList, fail-fast 的迭代器 Iterator/ListIterator 会报 ConcurrentModificationException 错。因此我们在并发环境下需要外部给 ArrayList 加个同步锁,或者直接在初始化时用 Collections.synchronizedList 方法进行包装。也可以使用concurrent并发包下的CopyOnWriteArrayList类。快速失败机制通过记录modCount参数来实现。迭代器的快速失败行为应该仅用于检测 bug。
- 序列化:ArrayList实现java.io.Serializable的方式。当写入到输出流时,先写入“容量”,再依次写入“每一个元素”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。那为什么ArrayList里面的elementData为什么要用transient来修饰?不是因为ArrayList不能序列化和反序列化,是因为elementData里面不是所有的元素都有数据,因为容量的问题,elementData里面有一些元素是空的,这种是没有必要序列化的。ArrayList的序列化和反序列化依赖writeObject和readObject方法来实现。可以避免序列化空的元素。序列化size大小的元素。
- 克隆: ArrayList的本质是维护了一个Object的数组,所以克隆也是通过数组的复制实现的,属于浅复制,调用的是Arrays.copyOf()。如果你想要修改克隆后的集合,那么克隆前的也会被修改。那么就需要使用深复制。通过实现对象类的clone方法。
- ArrayList的实现中大量地调用了Arrays.copyof()和System.arraycopy()方法。
- ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
- 在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,ArrayList中允许元素为null。
- indexOf和lastIndexOf 查找元素,若元素不存在,则返回-1!
- 适合读数据多的场合。
2. LinkedList
1. LinkedList 结构图

LinkedList是基于链表实现的,从源码可以看出是一个双向链表。除了当做链表使用外,它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList不是线程安全的,继承AbstractSequentialList实现List、Deque、Cloneable、Serializable。
- LinkedList继承AbstractSequentialList,AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)这些函数。这些接口都是随机访问List的。
- LinkedList 实现 List 接口,能对它进行队列操作。
- LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
- LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
- LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
2. LinkedList 重要特点
- 本质实现:底层使用一个Node数据结构,有前后两个指针,双向链表实现。
- 线程安全:非同步的。
- 列表长度:LinkedList中元素个数用size记录。
- 列表容量:LinkedList是基于链表实现的,因此不存在容量不足的问题,所以这里没有扩容的方法。
- 内存:需要更多的内存,LinkedList 每个节点中需要多存储前后节点的信息,占用空间更多些(previous element next)。
- 元素允许为null。
- Fail-Fast机制:同ArrayList相同。
- 遍历方法:所有指定位置的操作都是从头开始遍历进行的。LinkedList是基于链表实现的,因此插入删除效率高,查找效率低(虽然有一个加速动作)。源码中先将index与长度size的一半比较,如果index<size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历,从而提高一定的效率(实际上效率还是很低)。Arrays.copyOf() 方法:
- 它适合删除,插入较多的场景。
3. Vector
1. Vector 结构图

Vector 类可以实现可增长的对象数组。与数组一样,它包含可以使用整数索引进行访问的组件。但是,Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作。Vector 是同步的,可用于多线程。
- Vector 继承了AbstractList,实现了List;所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能。
- Vector实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
- Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。
- Vector 实现Serializable接口,支持序列化。
2. Vector 重要特点
- 本质实现:可增长的对象数组。
- 线程安全:同步的,很多方法都加入了synchronized同步语句,来保证线程安全。
- 列表长度:elementCount表示实际元素的数量。(Vector 通过 capacity (容量) 和 capacityIncrement (增长数量) 来尽量少的占用空间)
- 列表容量:Vector初始化容量是10,扩容默认2倍。capacityIncrement 容量增长系数(向量的大小大于其容量时,容量自动增加的量),ensureCapacity(int minCapacity)调用ensureCapacityHelper(int minCapacity)如果此向量的当前容量小于
minCapacity,则通过将其内部数据数组(保存在字段elementData中)替换为一个较大的数组来增加其容量。新数据数组的大小将为原来的大小加上capacityIncrement,如果容量的增量小于等于零,则每次需要增大容量时,向量的容量将增大一倍(编程原来的两倍),不过,如果此大小仍然小于minCapacity,则新容量将为minCapacity。 - Fail-Fast机制:Vector 的 iterator 和 listIterator 方法所返回的迭代器是快速失败的:如果在迭代器创建后的任意时间从结构上修改了向量(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
- Vector 的 elements 方法返回的 Enumeration 不是 快速失败的。
- Vector 主要用在事先不知道数组的大小,或者只是需要一个可以改变大小的数组的情况。
- 最好在插入大量元素前增加 vector 容量,那样可以减少重新申请内存的次数。
3. Array vs Vector
共同点:
- 都是基于数组
- 都支持随机访问
- 默认容量都是 10
- 都有扩容机制
区别:
- Vector 出生的比较早,JDK 1.0 就出生了,ArrayList JDK 1.2 才出来
- Vector 比 ArrayList 多一种迭代器 Enumeration
- Vector 是线程安全的,ArrayList 不是
- Vector 默认扩容 2 倍,ArrayList 是 1.5
如果没有线程安全的需求,一般推荐使用 ArrayList,而不是 Vector,因为每次都要获取锁,效率太低。
4. Stack
1. Stack 结构图

Stack 类表示后进先出(LIFO)的对象堆栈。它通过五个操作对类 Vector 进行了扩展 ,允许将向量视为堆栈。它提供了通常的 push 和 pop 操作,以及取堆栈顶点的 peek 方法、测试堆栈是否为空的 empty 方法、在堆栈中查找项并确定到堆栈顶距离的 search 方法。
因为它继承自Vector,那么它的实现原理是以数组实现堆栈的。如果要以链表方式实现堆栈可以使用LinkedList!(因为)
2. Stack 重要特点
- Stack是栈。它的特性是:先进后出(FILO, First In Last Out)。
- Stack实际上也是通过数组去实现的。实际调用的实现方法都是Vector中的方法!
- push时(即,将元素推入栈中),是通过将元素追加的数组的末尾中。
- peek时(即,取出栈顶元素,不执行删除),是返回数组末尾的元素。
- pop时(即,取出栈顶元素,并将该元素从栈中删除),是取出数组末尾的元素,然后将该元素从数组中删除。
- 栈最大的长度取决于vector里面数组能有多长。这里vector里面最大能取到Integer.MAX_VALUE。
5.CopyOnWriteArrayList(JUC)
1. CopyOnWriteArrayList 结构图
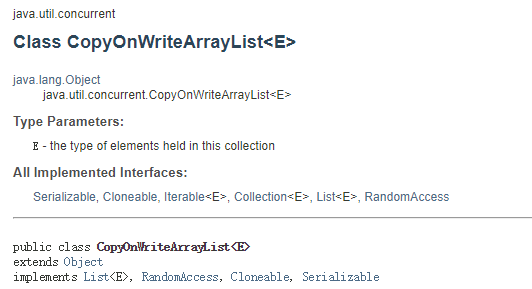
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。添加的时候是需要加锁的.
2. CopyOnWriteArrayList重要特点
- 增删改都需要获得锁,并且锁只有一把,而读操作不需要获得锁,支持并发。(而Vector读也需要加锁,性能差)
- 读的时候不需要加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的CopyOnWriteArrayList。
- 应用:CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景。
- 缺点:即内存占用问题(写时复制机制->GC->应用响应时间长)和数据一致性问题(只能保证数据的最终一致性,不能保证数据的实时一致性)。
- CopyOnWriteArrayList 是一个线程安全的 ArrayList,通过内部的 volatile 数组和显式锁 ReentrantLock 来实现线程安全。
-
CopyOnWriteArrayList 实现非常简单。内部使用了一个 volatile 数组(array)来存储数据,保证了多线程环境下的可见性。在更新数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给 array。正由于这个原因,涉及到数据更新的操作效率很低。
抄录网址
- https://blog.csdn.net/u010648555/column/info/14681(Java集合系列专栏)
- https://blog.csdn.net/ns_code/article/category/2362915(Java集合源码剖析)
- http://www.cnblogs.com/skywang12345/p/3323085.html( Java 集合系列)
- http://ifeve.com/talk-concurrency/(聊聊并发系列)
- Java List集合深入学习
- java集合系列——List集合之ArrayList介绍(二)
- 深入Java集合学习系列:ArrayList的实现原理
- java集合入门和深入学习,看这篇就差不多了
- ArrayList 源码分析 -- 扩容问题及序列化问题
- 【Java集合源码剖析】ArrayList源码剖析
- ArrayList的elementData为什么要用transient修饰
- java ArrayList的序列化分析
- 何巧妙的使用ArrayList的Clone方法
- Java 集合深入理解(11):LinkedList
- java集合系列——List集合之LinkedList介绍(三)
- 【Java集合源码剖析】LinkedList源码剖析
- LinkedList API
- 聊聊并发-Java中的Copy-On-Write容器