Rest风格说明
3.1 Rest风格说明

| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有的数据 |
关于索引的操作
- 创建一个索引!
PUT /索引名/~类型名~/文档id
{请求体}
类型名以后到8版本就没有了
PUT /test1/type1/1
{
"name":"haima",
"age":2
}
创建成功
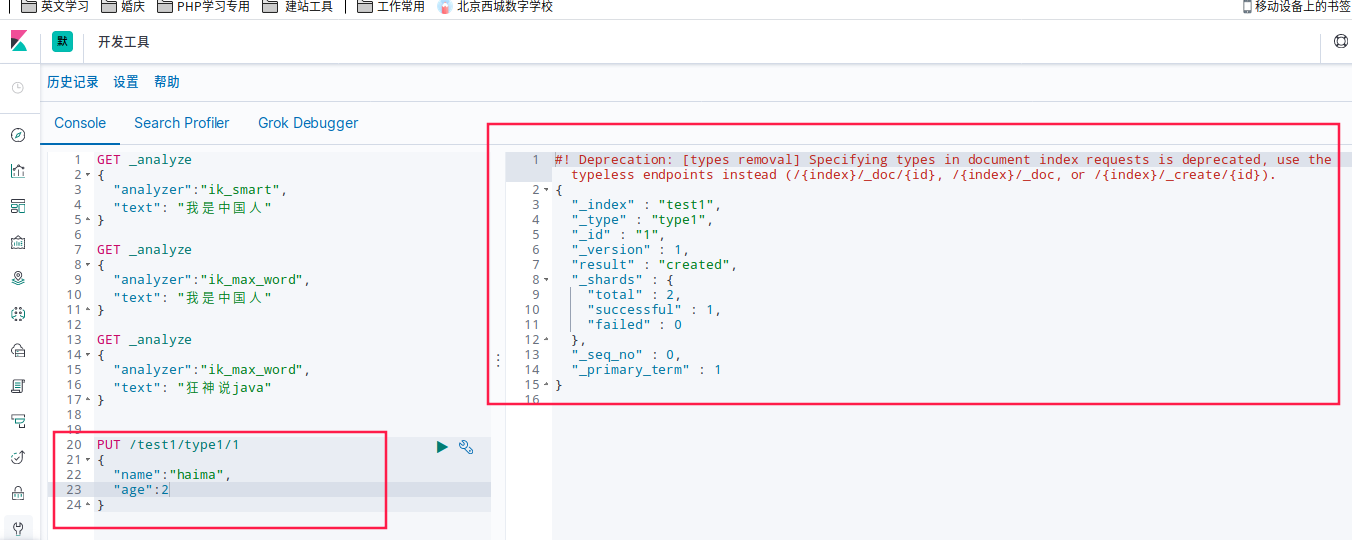
在head里可能看到test索引已经创建成功了
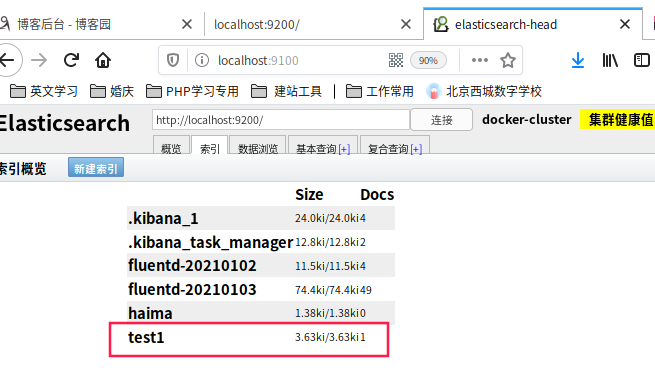
- 查看数据
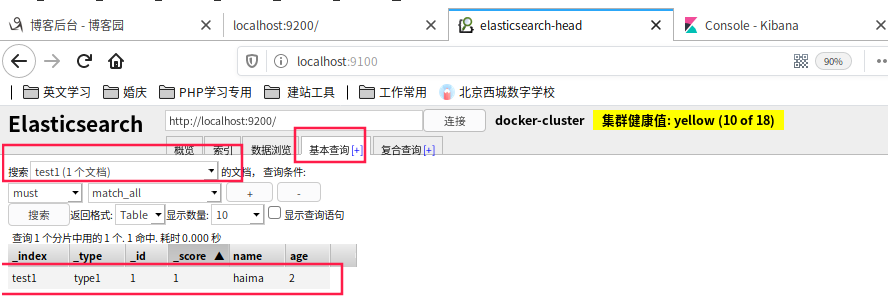
完成了自动增加了索引,数据也成功的添加了,这就是我说大家在初期可以把它当做数据库学习的原因!
- 那么name这个字段用不用指定类型呢。毕竟我们关系型数据库是需要指定类型的啊
- 字符串类型
text,keyword - 数值类型
long,integer,short,byte,double,float,half_float,scaled_float - 日期类型
date - 布尔值类型
boolean - 二进制类型
binary - 等等
更多详情看下面的文章
官网地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
es 数据类型:
https://blog.csdn.net/liuxiao723846/article/details/109099508
- 指定字段的类型
建 索引规则 和 字段的类型,不填入数据内容
请求
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type":"text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
返回成功
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test2"
}
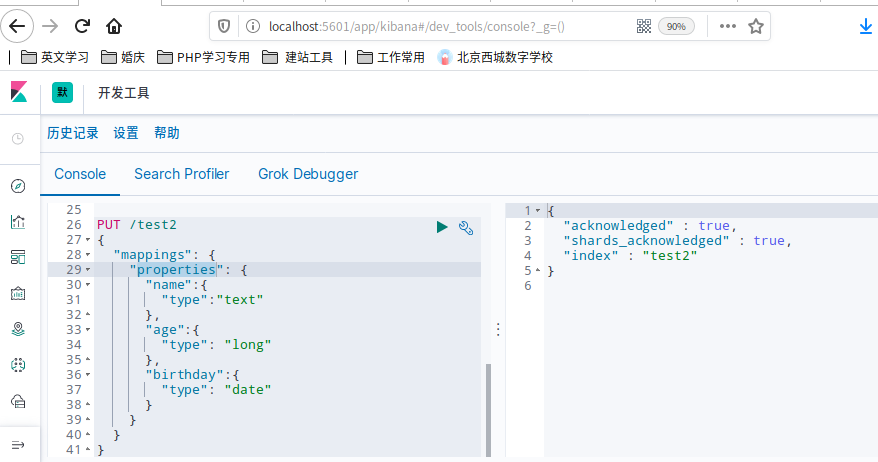
看以看到已经成功建立test2索引,但是没有写入数据
获取test2索引的命令
获取这个规则!可以通过GET请求获取具体的信息
请求
GET test2
返回数据
{
"test2" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"birthday" : {
"type" : "date"
},
"name" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1609688493459",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "lm-IkU7QTsifdLdxyXgwgw",
"version" : {
"created" : "7030199"
},
"provided_name" : "test2"
}
}
}
}
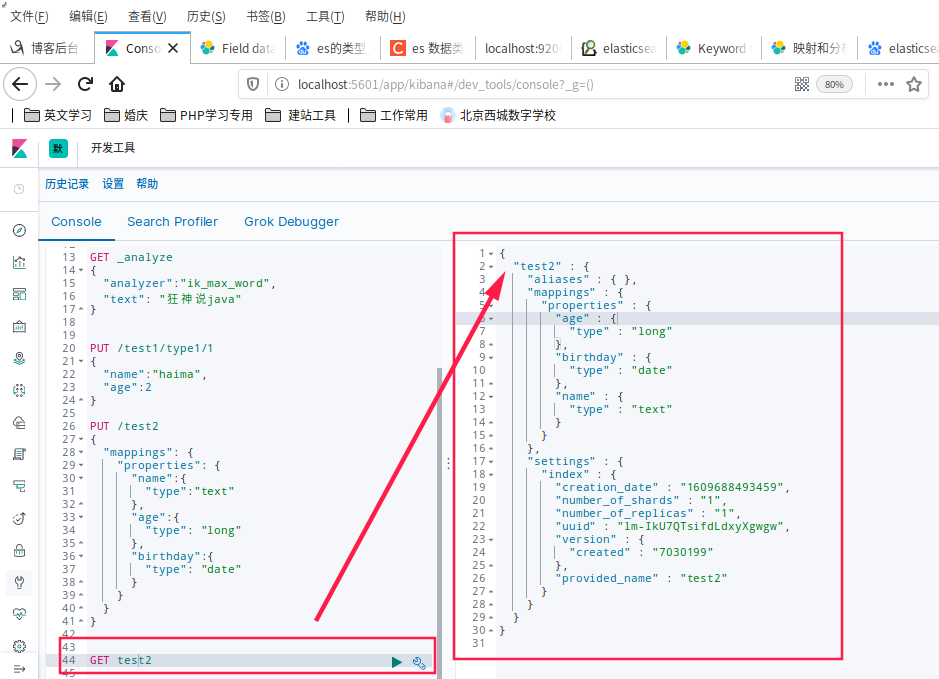
- 查看默认的信息
请求
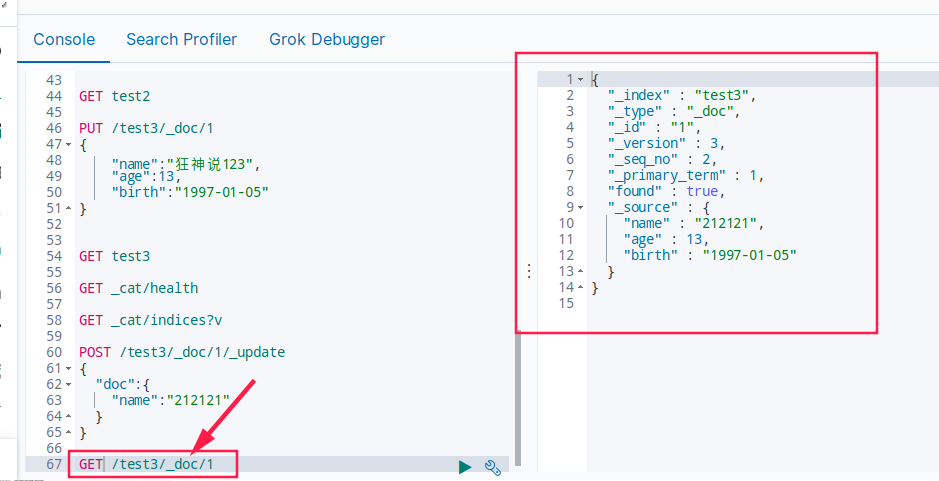
PUT /test3/_doc/1
{
"name":"狂神说",
"age":13,
"birth":"1997-01-05"
}
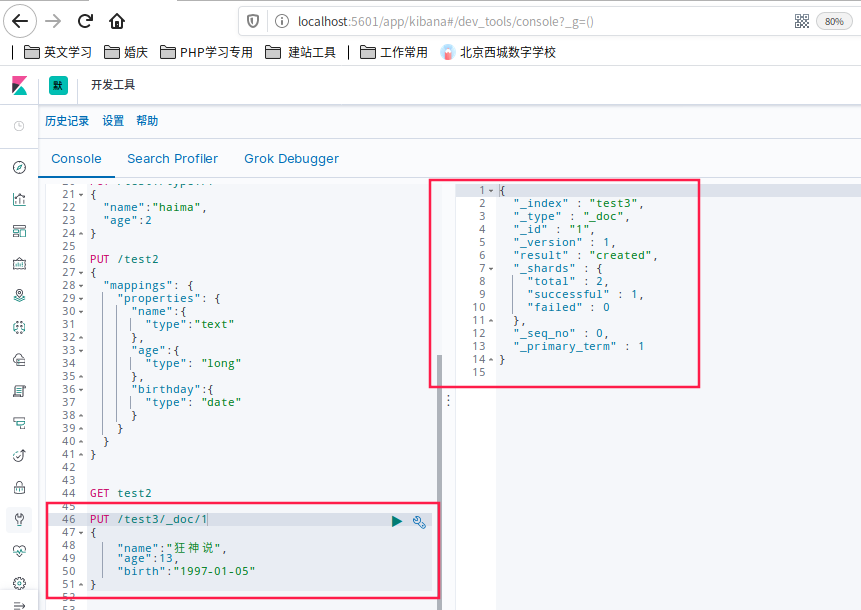
返回数据
{
"_index" : "test3",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
获取test3索引

如果自己不设置文档字段类型,那么es会自动给默认类型
获取健康值
GET _cat/health
获取所有的信息
GET _cat/indices?v
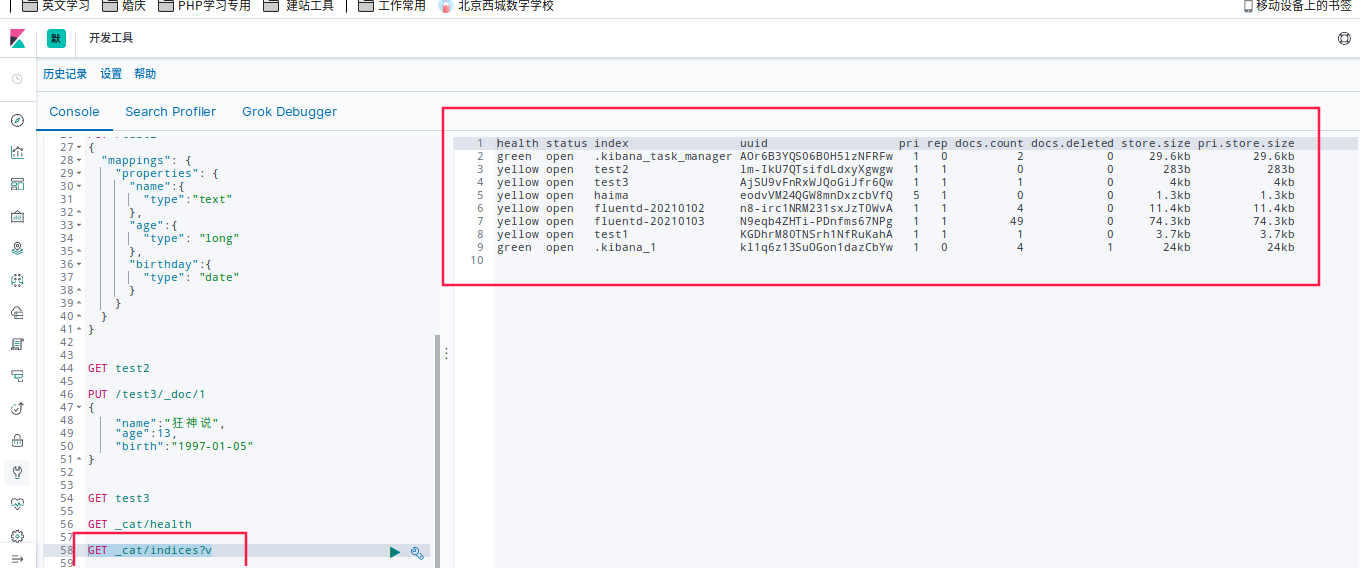
还有很多 可以自动展示 都试试
修改索引
- 修改我们可以还是用原来的PUT的命令,根据id来修改
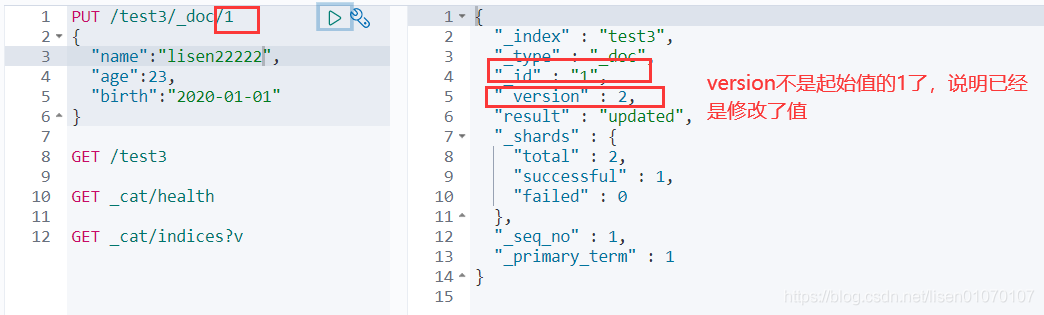
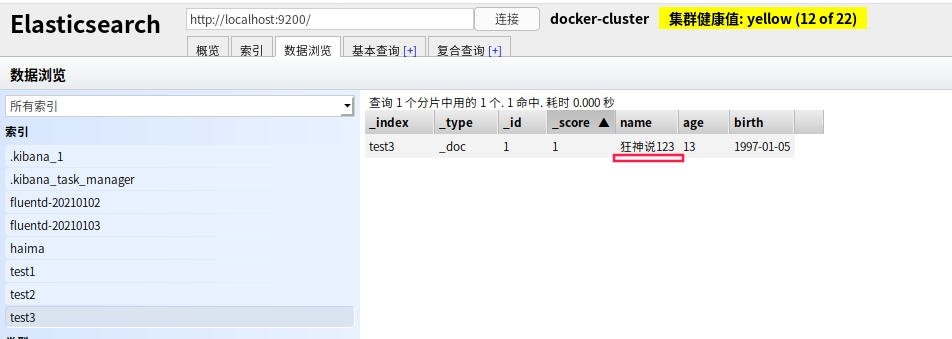
但是如果没有填写的字段 会重置为空了 ,相当于java接口传对象修改,如果只是传id的某些字段,那其他没传的值都为空了。
- 还有一种update方法 这种不设置某些值 数据不会丢失
POST /test3/_doc/1/_update
{
"doc":{
"name":"212121"
}
}
GET /test3/_doc/1
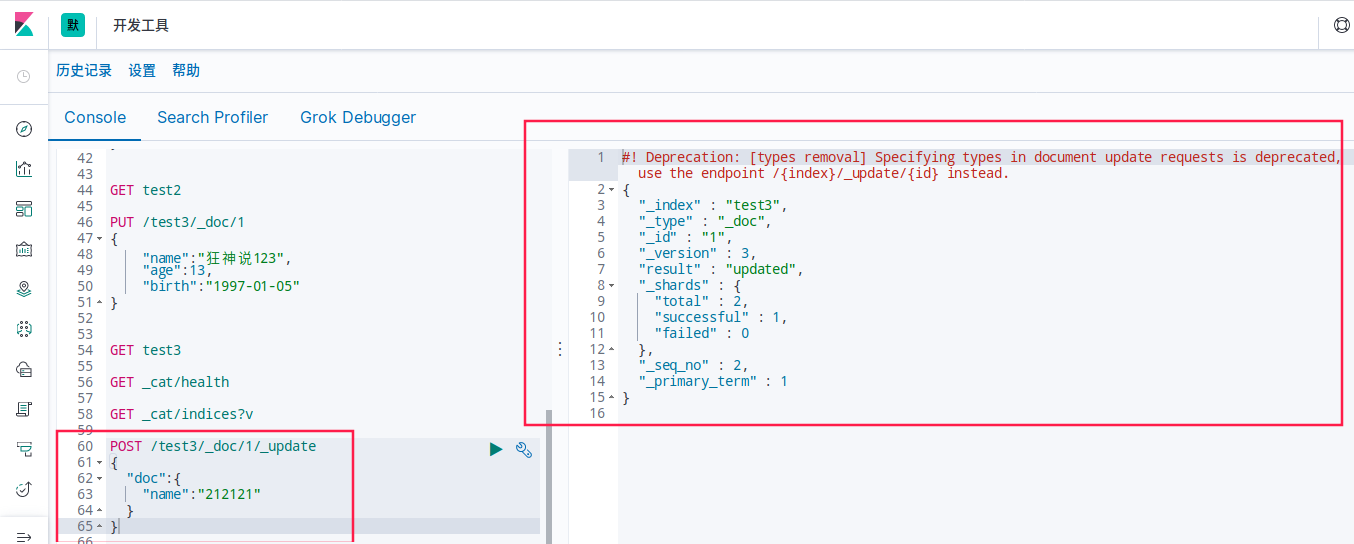
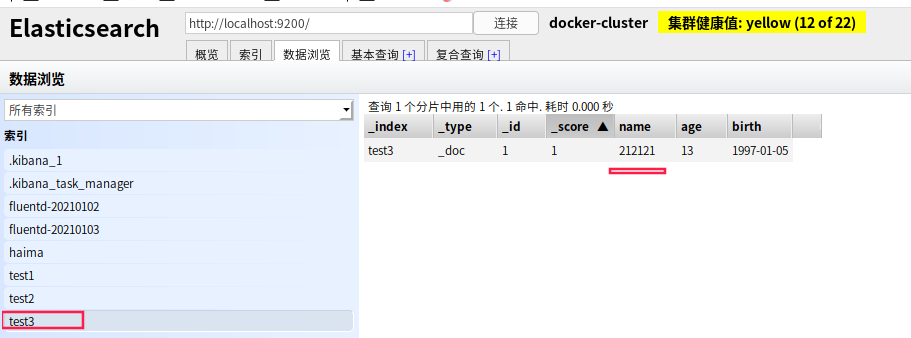
带doc修改 查询也是带doc的(document)
//下面两种都是会将不修改的值清空的
POST /test3/_doc/1
{
"name":"212121"
}
POST /test3/_doc/1
{
"doc":{
"name":"212121"
}
}
删除索引
DELETE /test1
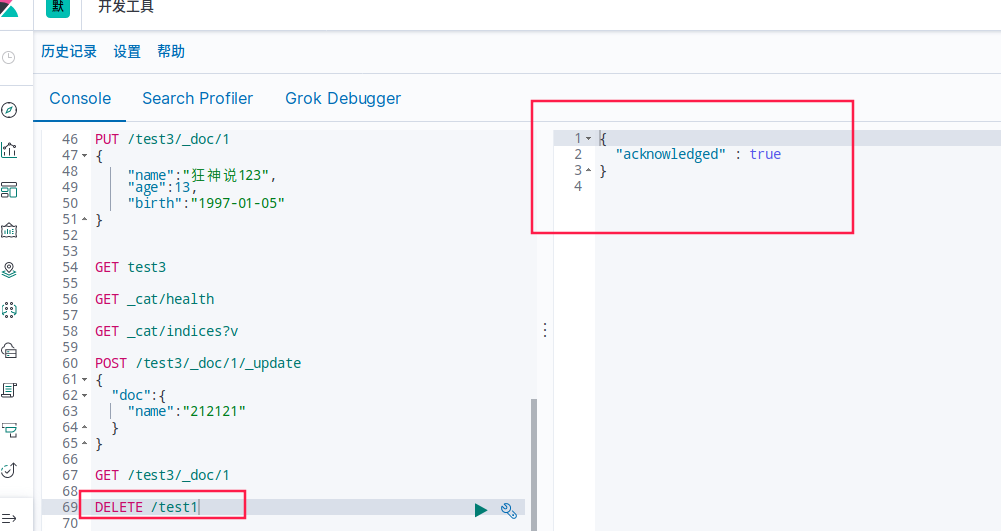
通过DELETE命令实现删除,根据你的请求来判断是删除索引还是删除文档记录
使用RESTFUL的风格是我们ES推荐大家使用的!
3.3 关于文档的基本操作
- 添加数据PUT
PUT /haima/user/1
{
"name":"狂神说123",
"age":13,
"desc":"我是描述",
"tags":["技术宅","温暖","直男"]
}
返回数据
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead.
{
"_index" : "haima",
"_type" : "user",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 7,
"found" : true,
"_source" : {
"name" : "狂神说123",
"age" : 13,
"desc" : "我是描述",
"tags" : [
"技术宅",
"温暖",
"直男"
]
}
}
- 查询
最简单的搜索是GET
GET /haima/user/1
返回数据
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead.
{
"_index" : "haima",
"_type" : "user",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 7,
"found" : true,
"_source" : {
"name" : "狂神说123",
"age" : 13,
"desc" : "我是描述",
"tags" : [
"技术宅",
"温暖",
"直男"
]
}
}
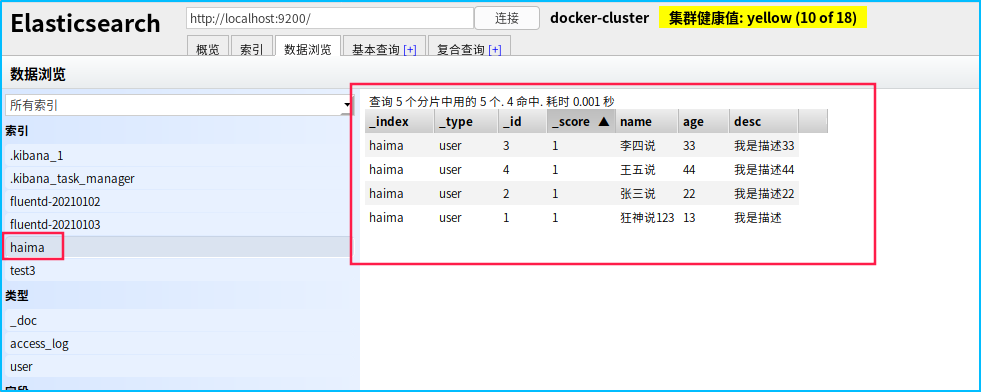
多添加几条数据
PUT /haima/user/2
{
"name":"张三说",
"age":22,
"desc":"我是描述22",
"tags":["技术宅","温暖","直男"]
}
PUT /haima/user/3
{
"name":"李四说",
"age":33,
"desc":"我是描述33",
"tags":["技术宅","温暖","直男"]
}
PUT /haima/user/4
{
"name":"王五说",
"age":44,
"desc":"我是描述44",
"tags":["技术宅","温暖","直男"]
}
- 搜索功能search
GET /haima/user/_search?q=name:李四

这边name是text 所以做了分词的查询 如果是keyword就不会分词搜索了
- 复杂操作搜索select(排序,分页,高亮,模糊查询,精准查询)
//测试只能一个字段查询
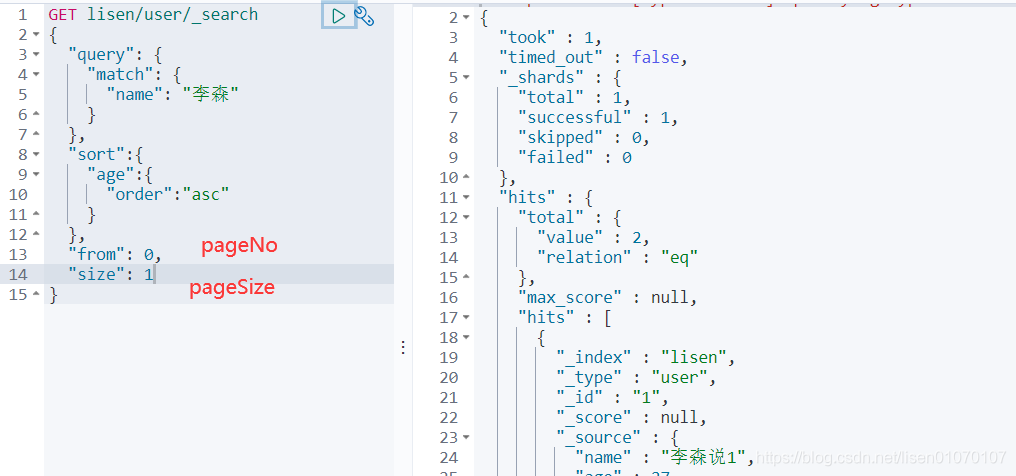
GET lisen/user/_search
{
"query": {
"match": {
"name": "李森"
}
}
}
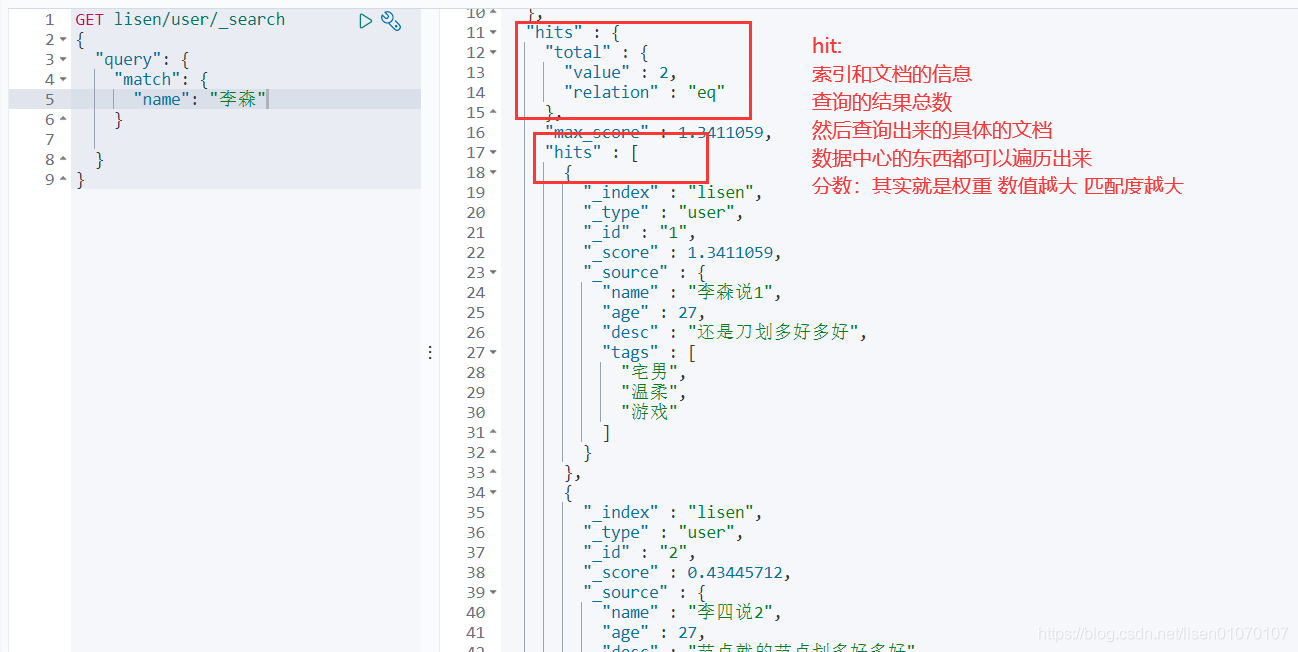
结果过滤,就是只展示列表中某些字段
GET /haima/user/_search
{
"query": {
"match": {
"name": "李四"
}
},
"_source":["name","age"]
}
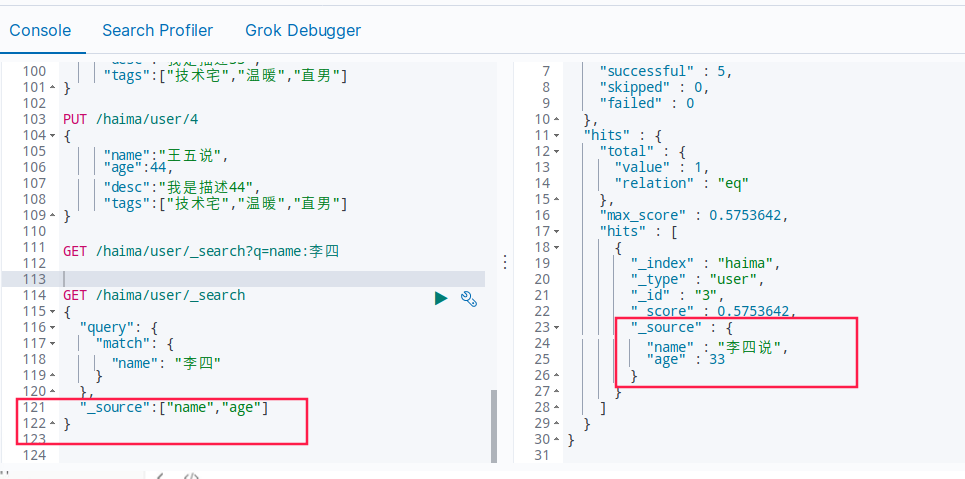
包含

不包含
GET /haima/user/_search
{
"query": {
"match": {
"name": "李四"
}
},
"_source":{"excludes":["name","age"]}
}
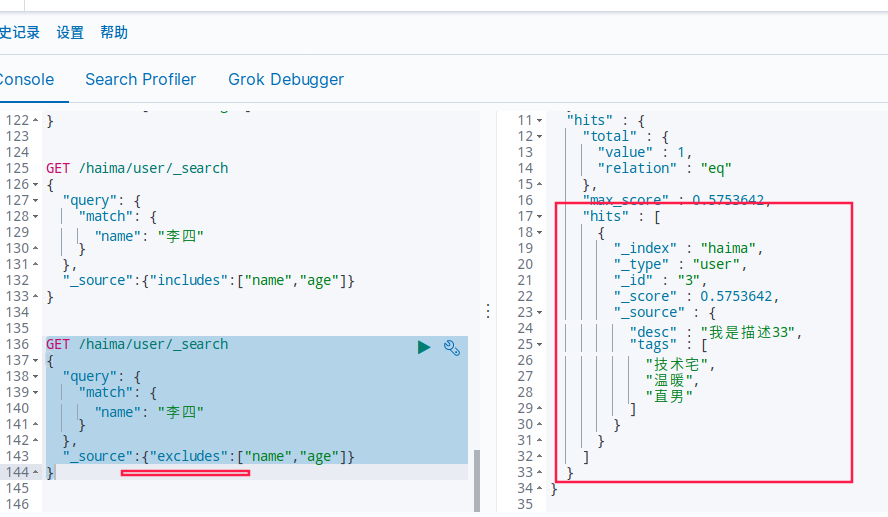
排序 asc(正序) / desc(倒序)

分页
GET /haima/user/_search
{
"query": {
"match": {
"name": "说"
}
},
"sort":{
"age":{
"order":"asc"
}
},
"from":0,
"size":2
}
多条件查询
布尔值查询
must(and),所有的条件都要符合
GET /haima/user/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "说"
}
},{
"match": {
"age": "22"
}
}
]
}
}
}
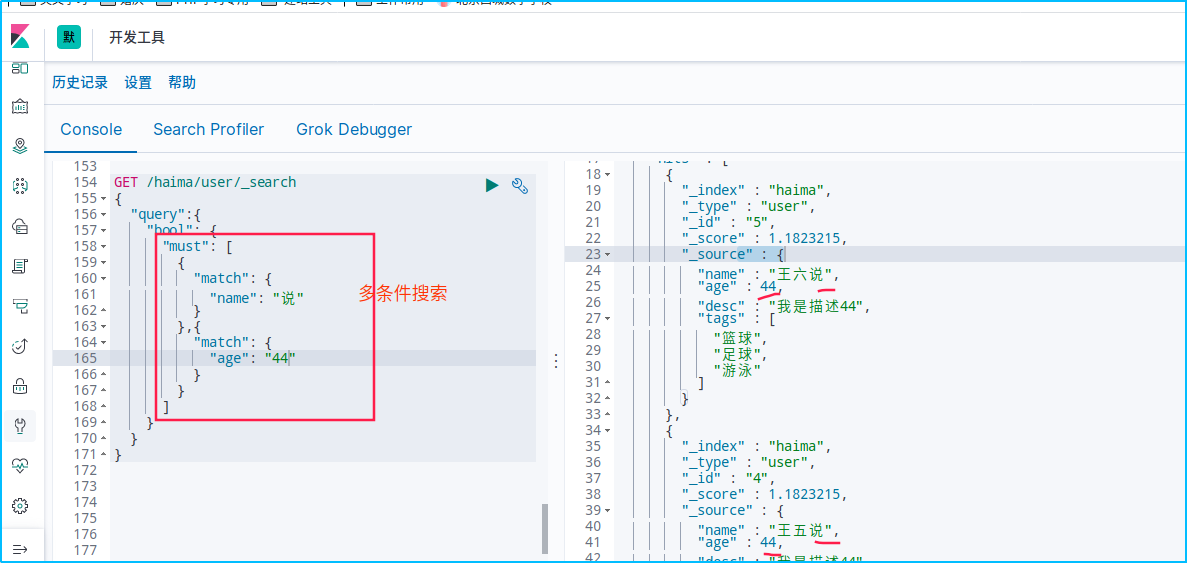
should(or)或者的关系,有一个条件成立即可
GET /haima/user/_search
{
"query":{
"bool": {
"should": [
{
"match": {
"name": "王五"
}
},{
"match": {
"age": "44"
}
}
]
}
}
}
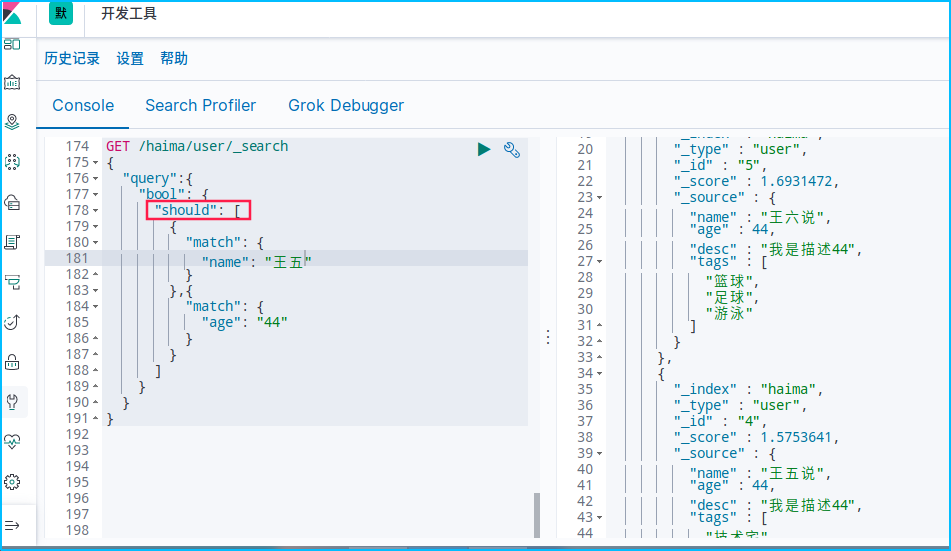
must_not(not)不等于
GET /haima/user/_search
{
"query":{
"bool": {
"must_not": [
{
"match": {
"name": "王五"
}
}
]
}
}
}
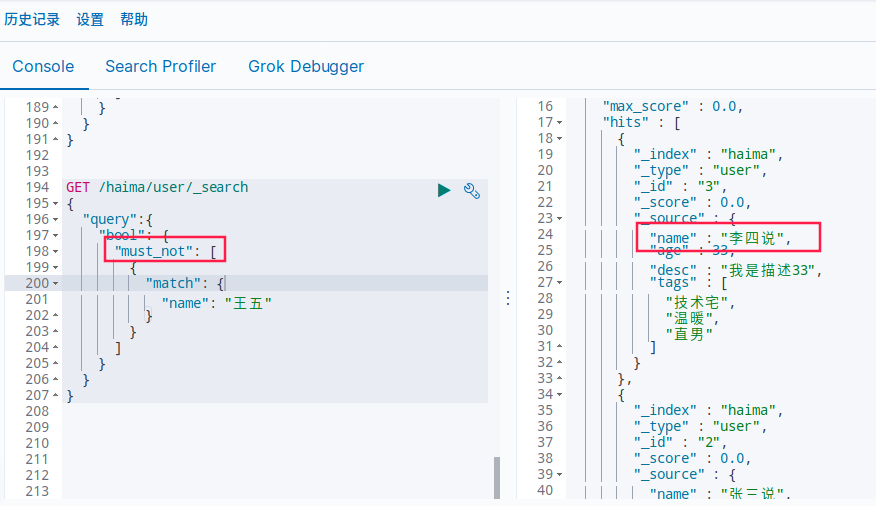
条件区间
过滤年龄区间符合条件的
GET /haima/user/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "王五"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 50
}
}
}
}
}
}

- 大于 gt
- 大于等于 gte
- 小于 lt
- 小于等于 lte
匹配多个条件(数组)
GET /haima/user/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"tags": "技术 女"
}
}
]
}
}
}

match没用倒排索引 这边改正一下
精确查找
term查询是直接通过倒排索引指定的词条进程精确查找的
关于分词
- term,直接查询精确的
- match,会使用分词器解析!(先分析文档,然后通过分析的文档进行查询)
GET _analyze
{
"analyzer":"standard",
"text":"张三说"
}
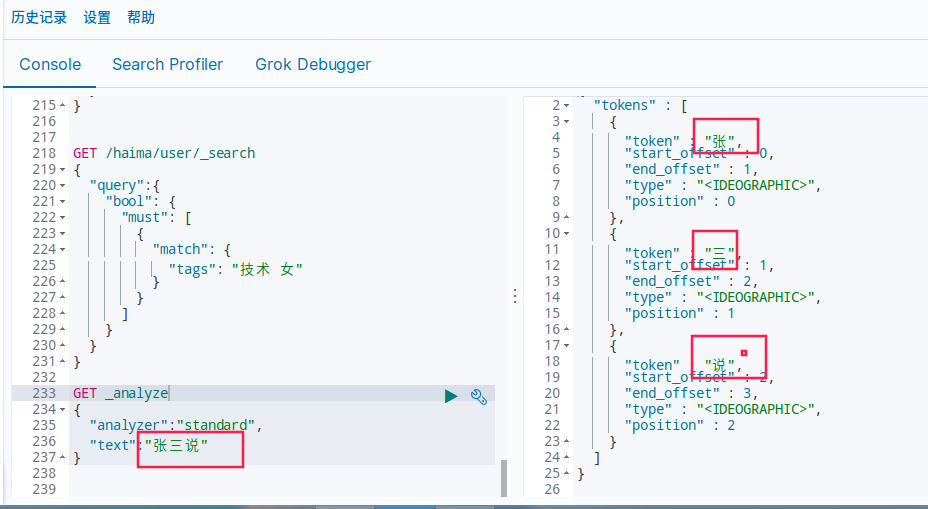
默认的是被分词了
GET _analyze
{
"analyzer":"keyword",
"text":"狂神说"
}
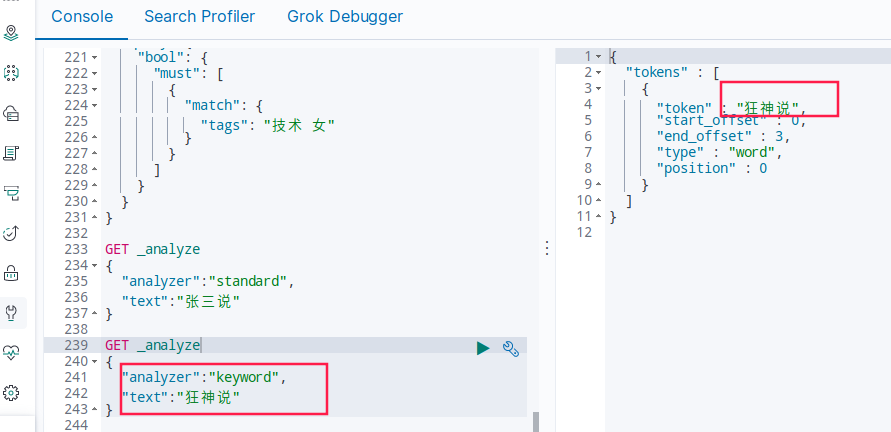
keyword没有被分词
精确查询多个值
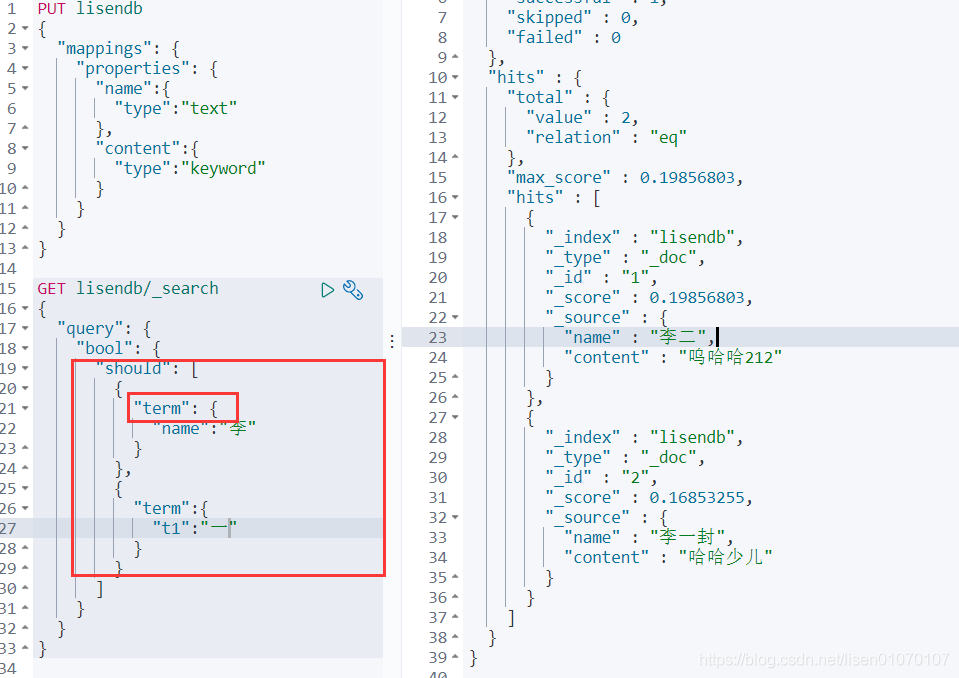
高亮
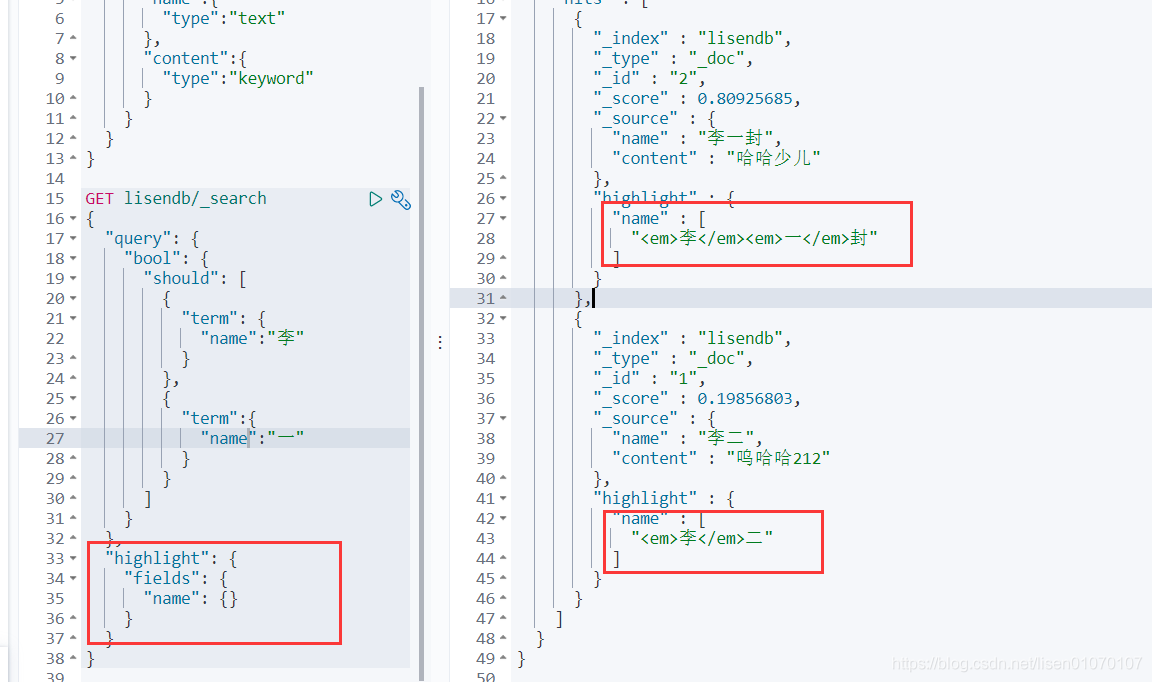
还能自定义高亮的样式
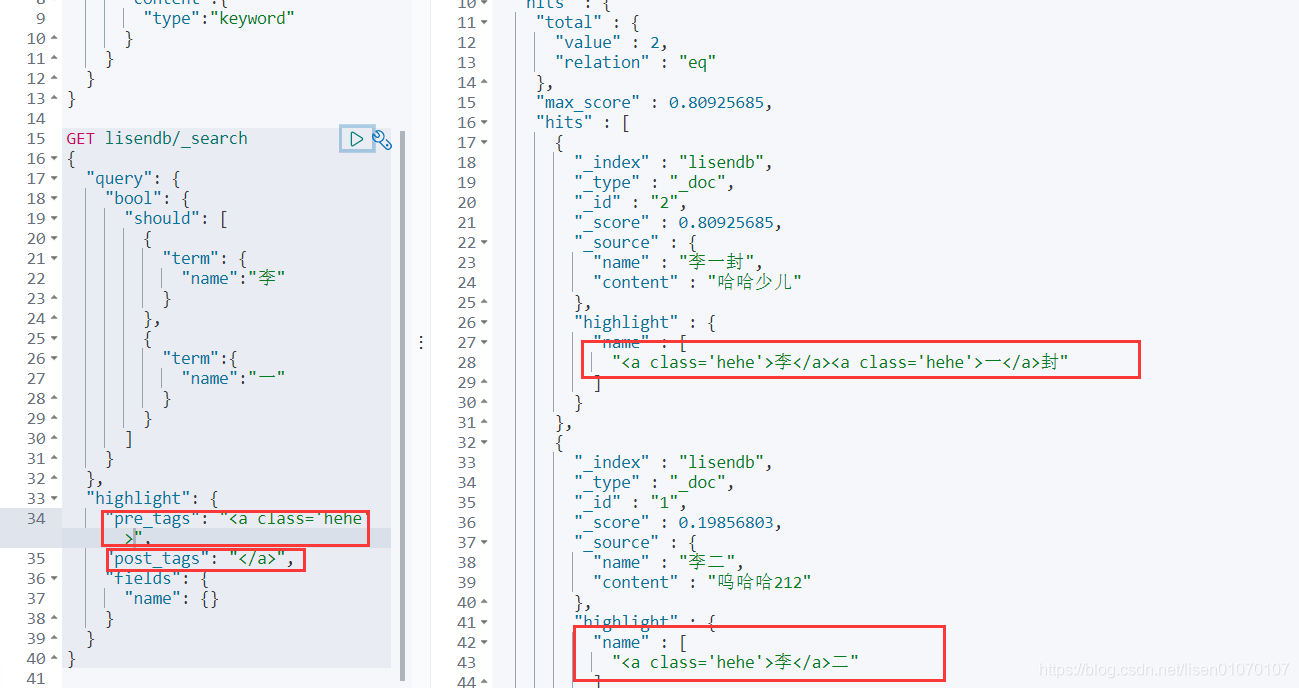
参考笔记:
https://blog.csdn.net/lisen01070107/article/details/108288037
https://blog.csdn.net/mgdj25/article/details/105740191