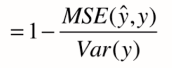本文转自:mse、rmse、mae、r2指标的总结以及局限性
衡量线性回归法的指标:MSE, RMSE和MAE
举个栗子:
对于简单线性回归,目标是找到a,b 使得
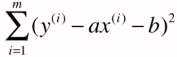
尽可能小
其实相当于是对训练数据集而言的,即
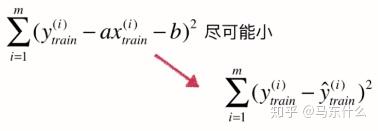
当我们找到a,b后,对于测试数据集而言
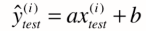
,理所当然,其衡量标准可以是
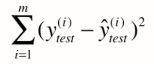
但问题是,这个衡量标准和m相关。
(当10000个样本误差累积是100,而1000个样本误差累积却达到了80,虽然80<100,但我们却不能说第二个模型优于第一个)
改进==> 对式子除以m,使得其与测试样本m无关
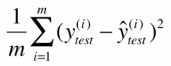
->

但又有一个问题,之前算这个公式时为了保证其每项为正,且可导(所以没用绝对值的表示方法),我们对式子加了一个平方。但这可能会导致量纲的问题,如房子价格为万元,平方后就成了万元的平方。
又改进==> 对MSE开方,使量纲相同
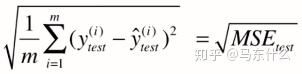
->

MSE与RMSE的区别仅在于对量纲是否敏感
又一思路,通过加绝对值
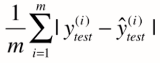
->

在推导a,b的式子时(对train数据集),没用求绝对值的方法是因为其不是处处可导,不方便用来求极值。但评价模型时,对test数据集我们完全可以使用求绝对值的方式。
P.S. 评价模型的标准和训练模型时最优化的目标函数是可以完全不一样的。
RMSE vs MAE

RMSE 与 MAE 的量纲相同,但求出结果后我们会发现RMSE比MAE的要大一些。
这是因为RMSE是先对误差进行平方的累加后再开方,它其实是放大了较大误差之间的差距。
而MAE反应的就是真实误差。因此在衡量中使RMSE的值越小其意义越大,因为它的值能反映其最大误差也是比较小的。
衡量线性回归法最好的指标 R Squared
对于上述的衡量方法,都存在的问题在于,没有一个上下限,比如我们使用auc,其上限为1,则越接近1代表模型越好,0.5附近代表模型和随机猜测基本差不多性能很差,实际上回归中也是存在这样一中指标的。
解决方法==> 新的指标:R方
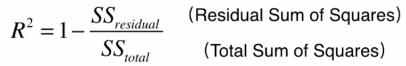
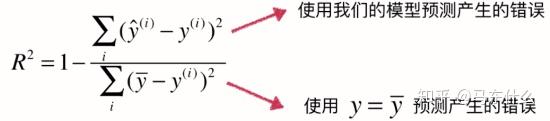
(上:y预测-y真,our model,下:y真平均-y真,baseline model)
使用baseline模型肯定会产生很多错误,我们自己的模型产生的错误会少一些。
1 - ourModelError / baselineModelError = 我们模型拟合住的部分

R方将回归结果归约到了0~1间,允许我们对不同问题的预测结果进行比对了。
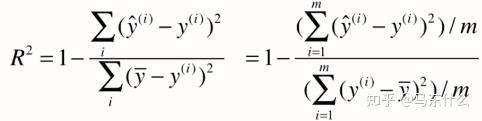
我们可发现,上面其实就是MSE,下面就是方差