无监督学习(Unsupervised learning)
无监督学习介绍(Unsupervised learning introdution)
无监督学习:数据并没有任何的标签,通过算法,找出隐含在这些数据中的结构。聚类算法是一种无监督学习算法。
聚类(clustering)分析将数据划分成有意义或有用的簇。聚类分析是一种分类的多元统计分析方法。按照个体或样品的特征将它们分类,使同一类别内的个体具有尽可能高的同质性(homogeneity),而类别之间则应具有尽可能高的异质性(heterogeneity)。
聚类的应用:市场划分(Market segmentation)、社交网络分析(Social network analysis)、组织计算机集群(Organize computing clusters)、天文学数据分析(astronomical data analysis)等
K-means算法
K-means算法是目前最热门的、应用最广泛的一共聚类算法。K-means算法是一种迭代算法。
随机初始化K个聚类中心。
重复:
1、聚类样本分配。把各样本x分配到最近的聚类中心。
2、移动族类中心。每个中心分配各x之后,对每个中心k分配的各x求平均,然后赋值给μ(k),相当于更新了聚类中心。
直到聚类中心不再改变。
如果遇到没有点的聚类中心,怎么办?最直接的做法是,把那个聚类中心移除掉!实际上很少会出现这种情况。大写的K表示簇类中心的个数,而小写的k则表示簇类中心的下标。

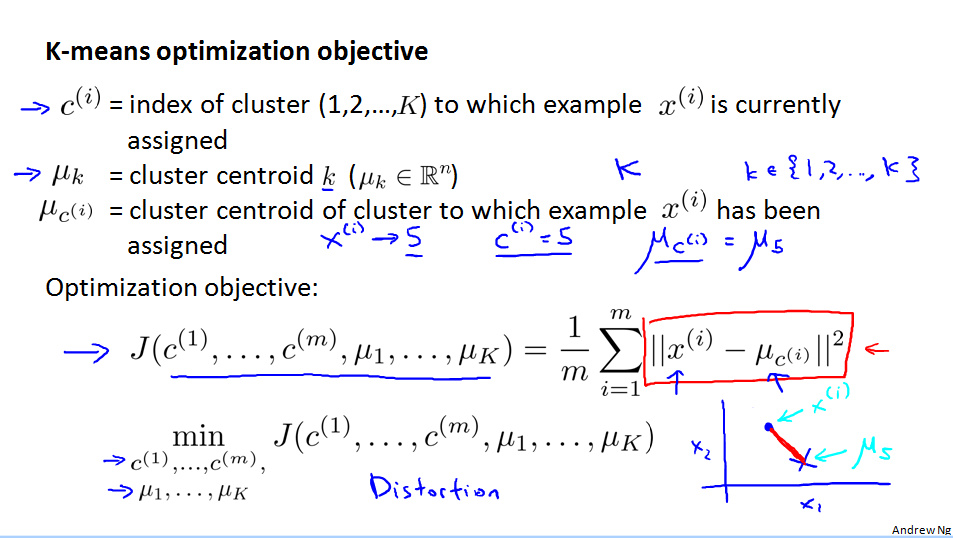
优化目标(Optimization objective)
K-means代价函数也叫失真代价函数,K-means算法的失真。
先最小化训练集到聚类中心的距离,再最小化聚类中心。
随机初始化(Random initialization)
首先,要求聚类中心K值小于训练集m值,然后,随机选择K个训练集元素作为K个聚类中心。

为了找到最优解,或者说,避免区部最优解,应该尝试进行多次初始化聚类中心,然后选择畸变最小的,即代价函数最小的,一般次数为50-1000次。
当K比较小时(2-10),多次初始化效果可能比较明显,当K比较大时,多次初始化效果可能不是很明显。

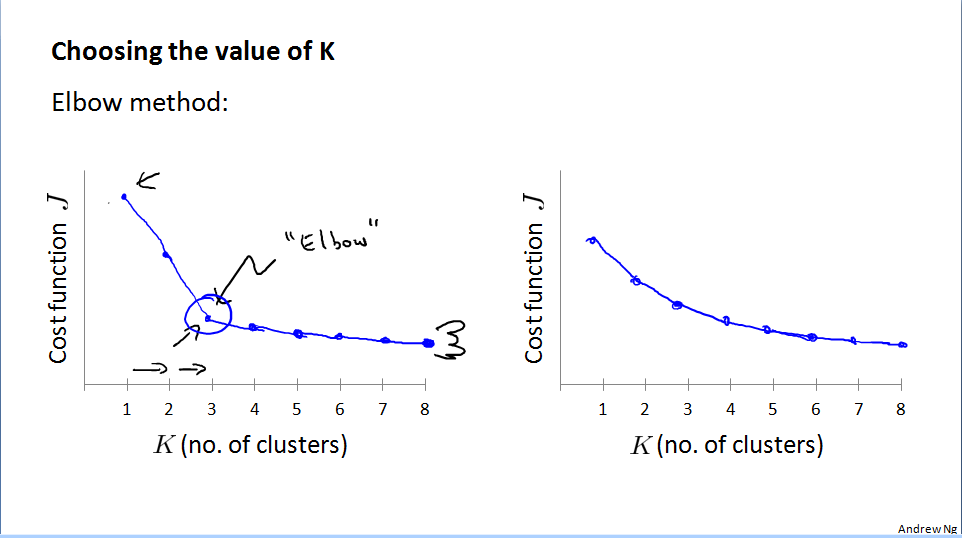
选择聚类数量(Choosing the number of clusters)
肘部方法(肘部法则),K数量选择在肘部,但J对K数量的下降曲线很平滑,就会遇到难以选择K的问题。
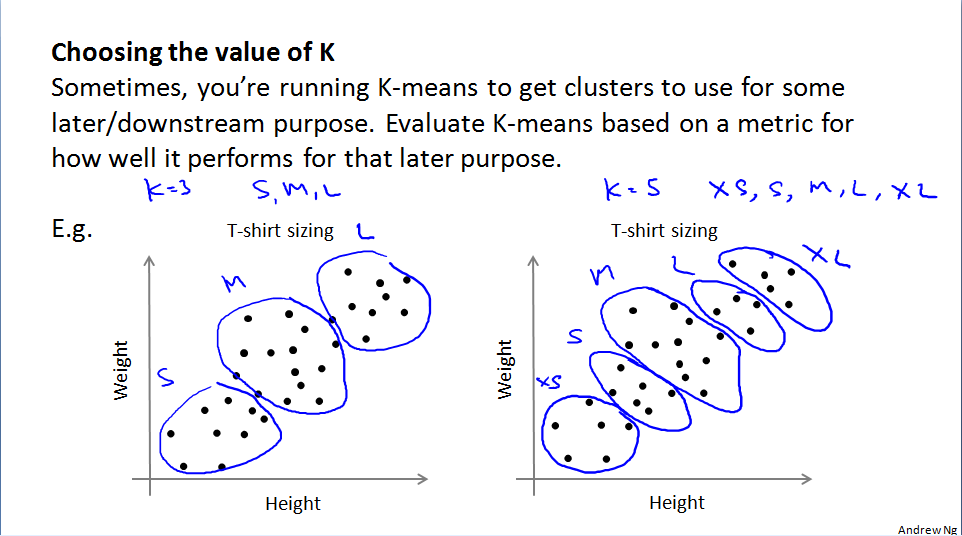
另一种选择聚类中心的方法是根据接下来的用途目的来作选择,哪个表现更好,就选哪个。例如,T恤尺寸的例子。