前言
主存存取原理、磁盘存取原理、MySql 使用的B+/-Tree原理
数据库索引为何采用B+Tree
- 红黑树等数据结构可以用来实现索引
- 文件系统及数据库系统普遍采用B-/B+ Tree 作为索引结构
- MySql 普遍采用 B+Tree 实现
- 索引本身很大,不可能全部存储内存,因此需要以索引文件的形式存储磁盘
- 相对于内存读取,I/O存取的消耗要高几个数量级(两个,内存1s,磁盘100多s),因此索引的结构组织尽量减少查找过程中的磁盘I/O操作
主存存取原理
- 主存基本就是随机读写存储器(RAM),简化之,如下:
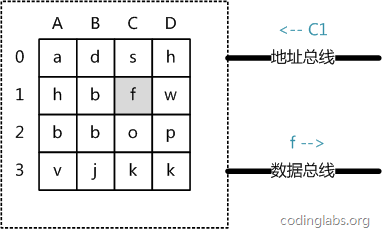
- 抽象角度看,主存是一系列的存储单元(晶体管)组成的矩阵,通过行地址和列地址可以定位唯一存储单元
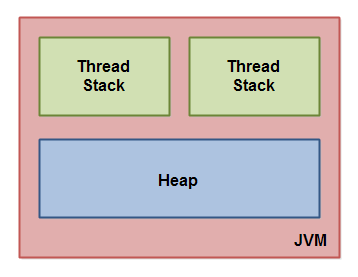
- 主存存取过程:当系统需要读取主存时,将地址信号放到地址总线,主存读到地址信号,后解析信号并定位指定存储单元,然后将此存储单元数据放到数据总线,供其它部件读取;
- 写主存:系统将要写入单元地址和数据分别放在地址总线和数据总线,主存读取两个总线的内容,做相应的写操作
磁盘存储原理
- 磁盘整体结构示意图:

- 一个磁盘由大小相同且同轴的圆形盘片组成,圆盘可以转动,磁头可以沿磁盘半径方向运动(寻道)
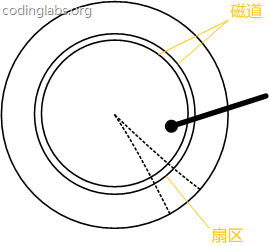
- 圆片被划分一系列同心圆,每个同心环叫做一个磁道,所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小段,每个段叫做一个扇区
- 为了读取这个扇区的数据,需要将磁头放到这个扇区上方,这个过程叫做寻道,花费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗时叫旋转耗时。
局部性原理和磁盘预读
- 由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费(寻道+ 旋转),磁盘的存取速度往往是主存的几百分之一
- 计算机科学著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。(磁盘读取会有被预读,相比如寻道时间,只需很少的旋转时间就能完成磁盘顺序读取,减少IO操作。)
- 预读的长度一般为页(page)的整数倍。页是计算机存储器的逻辑块,页的大小通常为4K。
计算机存储缓存
- 寄存器 64bit: CPU工作台,存放计算数据的地方
- 一级缓存L1 4x 64K
- 二级缓存L2 4x 256K
- 三级缓存L3 8MB
- 内存 4GB
- 磁盘 500GB
B-/+ Tree 索引的性能分析
- 巧妙地利用磁盘预读原理,将一个树节点大小设为一个页(4k),使得每个节点只需要一次IO 就可以完全载入
- 通常B-/+Tree的高(h)为3,而度(d)会很大,度越大索引性能越好
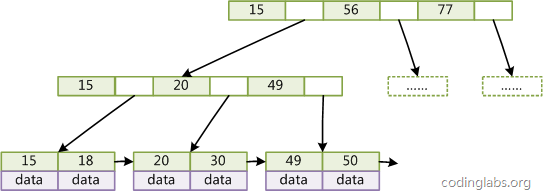
- 存储引擎MylSAM 索引方式,key 域存储主键,data域存储值得地址,非聚集,索引文件和数据文件是分离的。

- 存储引擎InnoDB,data域存储完整的数据逻辑。聚集型,数据文件本身就是索引文件。
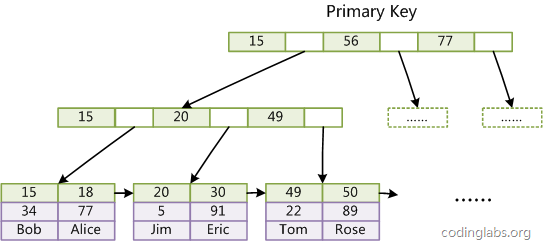
InnoDB 索引引擎主键的选择
- 自增主键 pk 业务主键(身份证)
- 自增主键,每次 insert 操作会按顺序添加到当前索引节点的后续位置,当一页写满,自动开辟一个新的页。
- 非自增主键(身份证号或学号),由于每次插入主键的值都近似随机,因此每次新记录都会查到现有索引页的中间位置,不得不产生一次数据移动