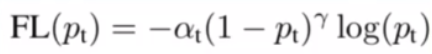阅读论文注意事项:
(1)对于一篇好的论文,首先会介绍之前的研究有什么问题,这篇论文解决了什么问题,他的有点在什么地方。
(2)在复现一篇论文之前,应该仔细去阅读论文实验部分。因为直觉阅读方法部分就去复现,往往难以达到论文所提出的那个效果。在细节上的处理,作者会在实验部分介绍。
1、Introduction
1.作者:Ross Girshick(RGB)代表作R-CNN,何凯明ResNet
2.两阶段流行算法:R-CNN系列
2.1 Faster R-CNN系列
a.输入图片,提取特征图;
b.特征图经过RPN得到候选框;
c.候选框映射回特征图,对框内图像分类。
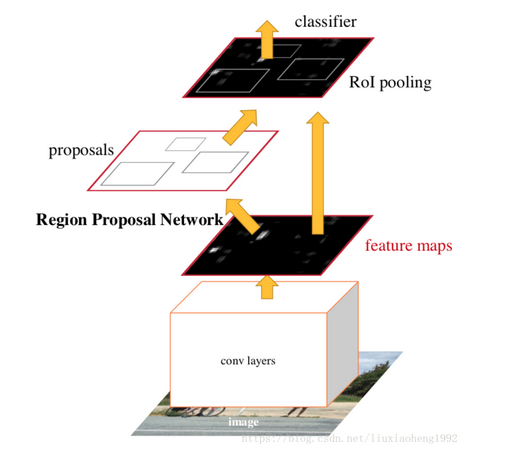 左边的rpn网络找框,右边做分类。由于两个分支,导致检测速度较慢。
左边的rpn网络找框,右边做分类。由于两个分支,导致检测速度较慢。
3.单阶段流行的算法:YOLO, SSD
3.1 SSD
a.输入图片,得到不同层,不同尺寸的特征图;
b.在不同尺寸的特征图上密集的选取候选框;(现在称之为锚框)
c.得到所有后选框和ground truth的交并比,大于阈值的为正样本;(下图灰色的就是负样本)
d.最后的损失值为边框回归损失和分类损失的和。(ground truth 候选框大小需要根据feature maps 按比例调整)
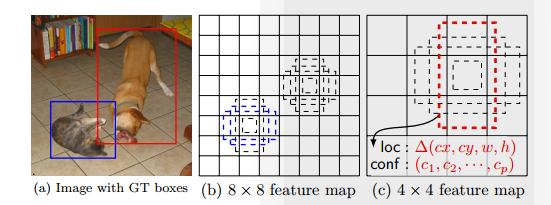
问题是:对于每一层的特征图都要去设置密集的候选框,这样产生的问题就是,产生了太多的负样本,使得单阶段目标检测器的准确率较低。优点在于它只有一路网络,速度比两阶段目标检测器更快。
××××××××××××××为了解决正负样本不平衡的问题,作者提出了Focal Loss。××××××××××××××××××××
4.相关算法:
4.1交叉熵损失函数(Cross Entropy Loss Function, CE)
4.2全卷积网络(Fully Convolution Network, FCN)最早提出是为了解决语义分割的问题,最后通过上采样生成与原图片一样大小的feature map替换了全连接层。从像素级对图像每个像素进行分类,达到分割的效果。另外一个优点在于:全卷积网络对于输入图片的大小没有要求,输入图片大最后特征就多,输入图片小最后特征就少。但是全连接层必须要接受固定数量的输入,使得在做检测和训练时必须要将图片转换为固定的大小。
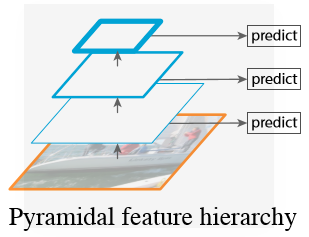
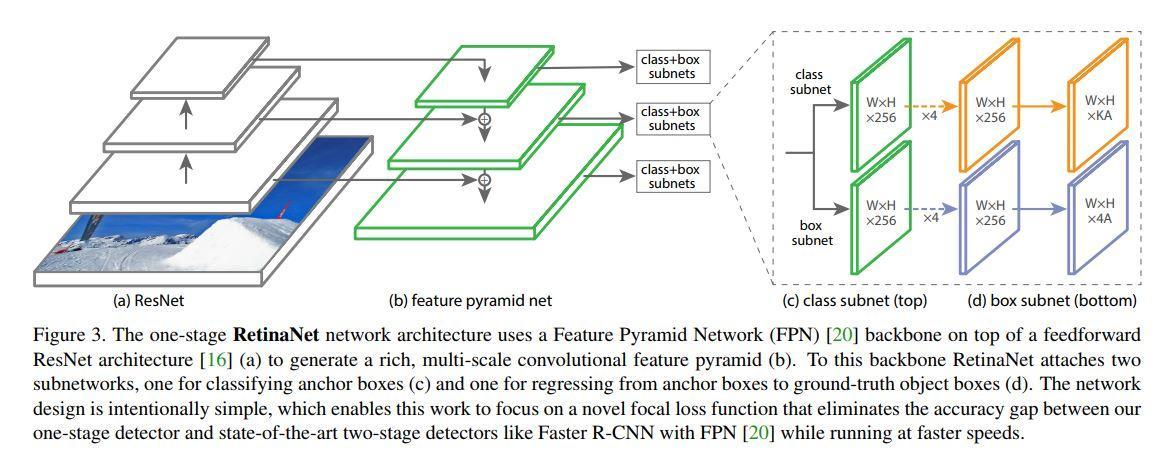
4.3特征金字塔网络(Feature Pyramid Network, FPN)(问题:为什么要用特征金字塔?)(处理尺度问题)
(a).图像金字塔,时间和存储成本高;
(b).传统方法;(卷积池化卷积池化等一顿乱七八糟的操作)(问题在于,物体尺度问题难以解决,适合做分类问题)
(c).SSD采用的特征金字塔,忽略了其它层的特征表达;
(d).FPN (卷积层每层输出的特征图的通道跟尺寸大小不同,需要先通过1X1的卷积层调整通道数量,使所有层的通道数量一致。这样就可以进行相加啦。

5.Focal Loss为解决但阶段检测中,正负样本数量和分类难易程度极度不平衡引起的损失值被大量容易分类的负样本损失淹没的问题。

6.单阶段目标检测框架:RetinaNet(ResNet + FPN + FCN)
7.Focal Loss
(1)Cross-Entropy Loss:在单阶段目标检测中,它会被大量的容易分类的样本控制,导致少量的不容易分类的样本被淹没。
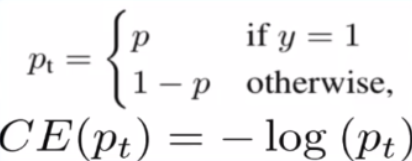
(2)Balanced CE Loss:对正样本的损失值使用权重因子α( [0,1] ), 对负样本使用权重因子1-α.从数量角度平衡了样本损失值。
但是,只考虑了正负样本的平衡,没有考虑到对难易预测的样本的特殊考虑。正样本中有难预测的,负样本中也有难预测的。
![]()
(3)Focal Loss:对于难分类的样本,其损失值就大。对于容易分类的样本使得其损失值接近于零。同时使用了Balanced CE Loss,处理正负样本不平衡的问题。