数据流重导向
重导向redirect:就是将当前的所得数据输出到其他地方;
三种输出输入的状况,分别是:
—标准输入stdin:代码为0;使用<或<<
—标准输出stdout:代码为1;使用方式为1>或>>;
—标准输出stderror:代码为2;使用的方式为2>或2>>;
Find / -name file 1> list_right 2>list_error;
同时写入同一个档案
find / -name file 1>list 2>&1(推荐使用这个,后面这个命令使用会使错误信息输出不全);或find / -name file >list 2>list
(cat主要有三大功能:
1.一次显示整个文件。$ cat filename
2.从键盘创建一个文件。$ cat > filename
只能创建新文件,不能编辑已有文件.
3.将几个文件合并为一个文件: $cat file1 file2 > file
参数:
-n 或 --number 由 1 开始对所有输出的行数编号
-b 或 --number-nonblank 和 -n 相似,只不过对于空白行不编号
-s 或 --squeeze-blank 当遇到有连续两行以上的空白行,就代换为一行的空白行
-v 或 --show-nonprinting
)
双向重导向tee
tee :将数据流同时输出到屏幕和文件;
tee –a file
-a :以累加的方式,将数据加入file中;
命令执行的判断依据:;&& ||
Command1;command2 利用分号“;”来分隔,这个分号的意思,代表不论command1执行结果为何,command都会被执行;
Command1 &&command2 如果command1正确才执行command2;
Command1 ||command2 如果command1错误才执行command2;
管道命令(pipe)
切记:管道命令“|”只能处理通过前面一个命令传来的正确信息,也就是标准输出(STDOUT)的信息,对于标准错误,没有处理能力;
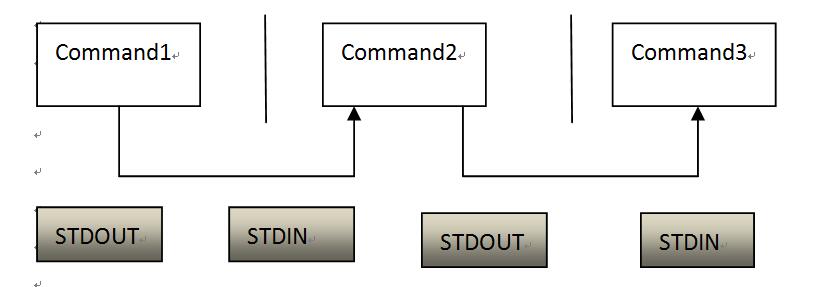
选取命令cut 和grep
选取命令:就是将一段数据分析后,取出我们想要的部分(cut),或者是,通过分析关键字,取得我们想要的行(grep)。选取信息通常是针对“逐行”分析得到的,而不是针对整个信息分析的。
Cut :就是切,这个命令可以将一段信息的某段切出来,消息以行为单位;
Cut –d “分隔字符” –f fields
Cut –c 字符范围
参数说明:
-d:后面接分隔符,预设是空格符,与-f一起使用;
-c:以字符为单位取出固定的字符范围;-f:根据-d分隔符一段消息分为数段,用-f是取出第几段的意思;
Grep 分析一行信息,若其中有需要的信息,就将这一行信息显示出来;
Grep [-acinv] ‘搜索字符串’ filename
-a 将二进制文件以文本的方式搜索数据;
-c 计算找到‘搜索字符串‘的次数;-i:忽略大小写的不同,所有大小写视为相同;-n:顺便输出行号;-v:反向选择,即显示没有‘搜索字符串的那一行’
排序命令:sort wc uniq
Sort [-fbMnrtuk] [file or stdin]
参数说明:-f:忽略大小写的差异,-b:忽略最前面的空格字符部分;-M:以月份的名字赖排序;-n:使用纯数字排序(默认使用文字类型来排序);-r:反向排序;-t:分隔符,默认是tab;-u:就是uniq,相同数据,只列出一次显示;-k:按那个字段(field)来排序;
Uniq [-ic]
-i 忽略大小写;-c 进行计数;
wc [-lwm]
-l 仅显示多少行;-w 仅显示有多少字;-m 多少字符;
字符转换命令
字符转化命令tr,col,join,paste,expand;
tr 可以用来删除一段信息当中的文字,或者是进行文字信息的替换;tr [-ds] str …
参数:-d :删除信息当中的str这个字符串;-s :取代掉重复的字符;