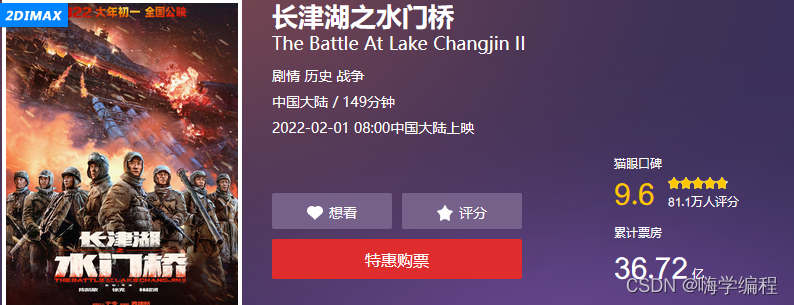
吴京近年拍的影视都是非常富有国家情怀的,大人小孩都爱看,每次都是票房新高,最新的长津湖两部曲大家都有看吗,第一步还可以,第二部水门桥也不差,截止目前已经36.72亿票房。
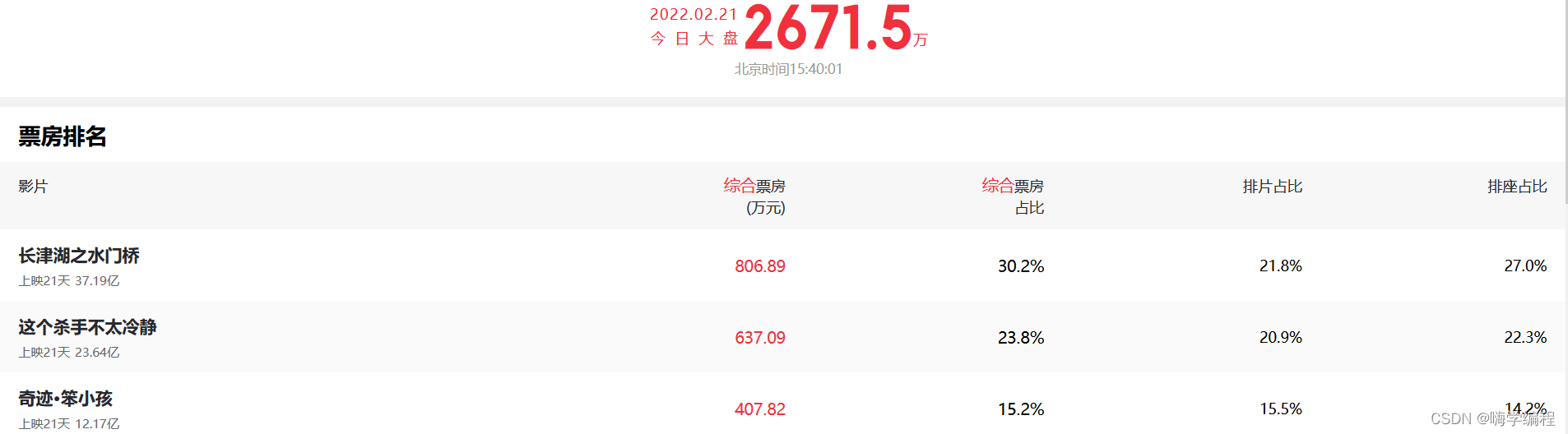
某眼评分9.6,某瓣评分7.2。2月每日票房基本每天第一,但是它为什么好看呢?让我们用python来看看,看过的人都在说什么~
爬虫部分需要使用这几个模块
requests
parsel
csv
前面两个需要安装,键盘上按 win+r 打开运行框,输入 cmd 然后确定,然后输入 pip install 模块名,回车即可安装。

代码仅供参考,我就不一一分析,录了一个十分钟的视频讲解,不会的兄弟可以跟着视频学习。
这也是一个视频合集,正在慢慢更新,大家可以三连一下~

爬虫代码
import csv import requests import parsel # Python学习交流群:924040232 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36' } for page in range(1, 20): url = f'...../subject/35613853/comments?start={page*20}&limit=20&status=P&sort=new_score' data_html = requests.get(url=url, headers=headers).text selector = parsel.Selector(data_html) comment_list = selector.css('.comment-item') for comment in comment_list: short = comment.css('.short::text').get().strip() name = comment.css('.comment-info a::text').get().strip() time = comment.css('.comment-time::text').get().strip() vote_count = comment.css('.votes.vote-count::text').get().strip() print(short, name, time, vote_count) with open('长津湖.csv', mode='a', encoding='utf-8', newline='') as f: csv_writer = csv.writer(f) csv_writer.writerow([short, name, time, vote_count])
词云图代码
import jieba from pyecharts.charts import WordCloud import pandas as pd from pyecharts import options as opts wordlist = [] data = pd.read_csv('长津湖.csv', encoding='utf-8')['short'] data data_list = data.values.tolist() data_str = ' '.join(data_list) words = jieba.lcut(data_str) #取出除每一个单词 for word in words: #去除小于2个字的词 if len(word) > 1: #数据的添加, wordlist.append({"word":word,"count":1}) #wordlist为列表类型,元素为字典类型[{"word":发展,"count":1},...,...,] df = pd.DataFrame(wordlist) # 以word的值作为关键词分组,再统计每组的(count)的总数sum #groupby DataFrame中的分组函数 dfword = df.groupby('word')['count'].sum() # sort_values以列的值排序,ascending为false时降序排序 dfword2 = dfword.sort_values(ascending=False) #将dfword2 的前100数据转为DataFrame。 dfword3 = pd.DataFrame(dfword2.head(100),columns=['count']) # 此时列”word“是作为列索引,可将其转为列 dfword3['word'] = dfword3.index #将word列转为列表 word = dfword3['word'].tolist() #将count列转为列表 count = dfword3['count'].tolist() #用for循环合并数据 a = [list(z) for z in zip(word,count)] c = ( #WordCloud类的实列化 WordCloud() #添加图名称、数据、字体的随机大小、图像类型 ,mask_image="demo.png" # 词云图轮廓,有 'circle', 'cardioid', 'diamond', 'triangle-forward', 'triangle', 'pentagon', 'star' 可选 .add("", a, word_size_range=[20, 100],shape='circle') #图像的具体设置也可以再全局设置中设置,其中还有一些好玩的设置,这里就不在深入了 .set_global_opts(title_opts=opts.TitleOpts(title="词云图")) ) #在jupyter上显示 c.render_notebook()
兄弟们快去试试吧,有什么问题欢迎三连后在评论区交流~