不是吧不是吧,不会有人不知道这本文学作品吧
金P梅作为古代精品文学作品,作者的笔功力确实厉害,小弟佩服至极,所以今天来爬一爬,但是不准备看,主要是看不懂。
相信各位也只是学学技术,书有什么好看的~

首先你要安装这两个模块
requests
parsel
键盘上按住win+r ,在弹出来的运行框输入cmd,确定后在弹出的命令提示符窗口输入 pip install 模块名 ,回车即可。
下载时间太长了就加上镜像源 ,例如这是清华镜像源https://pypi.tuna.tsinghua.edu.cn/simple
在模块名前面加上 -i 镜像源地址,如:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 模块名
————————————————————————————————————————————————————————————
目标地址
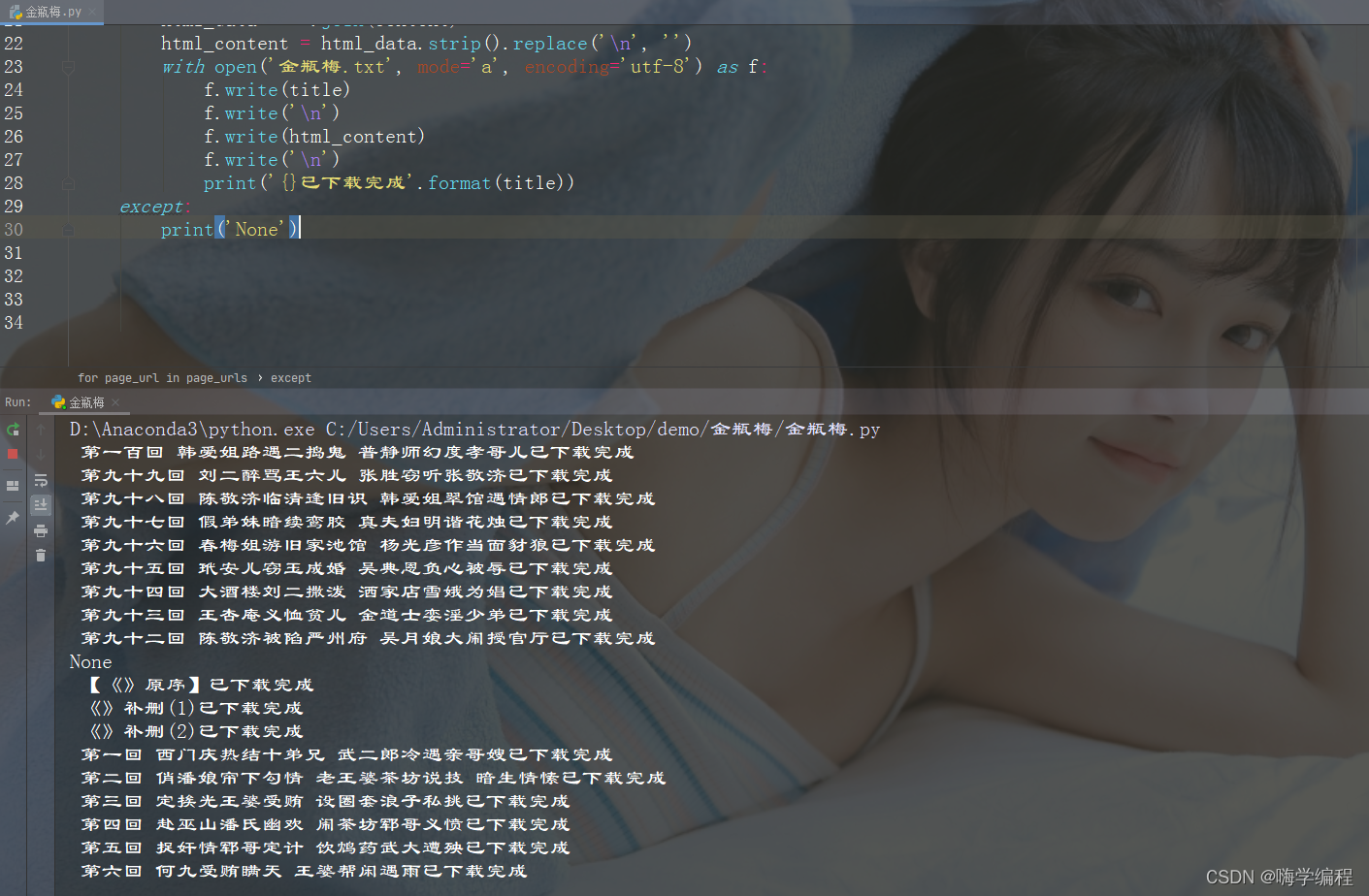
爬取过程
爬取结果
import requests import parsel url = 'https://www.改成目标地址.com/shu/3801.html' headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, headers=headers) selector = parsel.Selector(response.text) page_urls = selector.css('.panel-body dd a::attr(href)').getall() for page_url in page_urls: # print(page_url) try: new_url = 'https://www.tianyabook.com' + page_url response = requests.get(url=new_url, headers=headers) response.encoding = response.apparent_encoding selector = parsel.Selector(response.text) content = selector.css('#htmlContent::text').getall() title = selector.css('.page-header h1::text').get() html_data = ''.join(content) html_content = html_data.strip().replace('\n', '') with open('金p梅.txt', mode='a', encoding='utf-8') as f: f.write(title) f.write('\n') f.write(html_content) f.write('\n') print('{}已下载完成'.format(title)) except: print('None')
#兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。 #那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码! #还会有大佬解答! #都在这个群里了 924040232 #欢迎加入,一起讨论 一起学习!
本次分享就到这里结束了,兄弟们赶紧试试吧~