兄弟们,最近女朋友迷上了这玩意,结果化身败家子,她家里给她准备的嫁妆都给贴进去了,这我能忍?
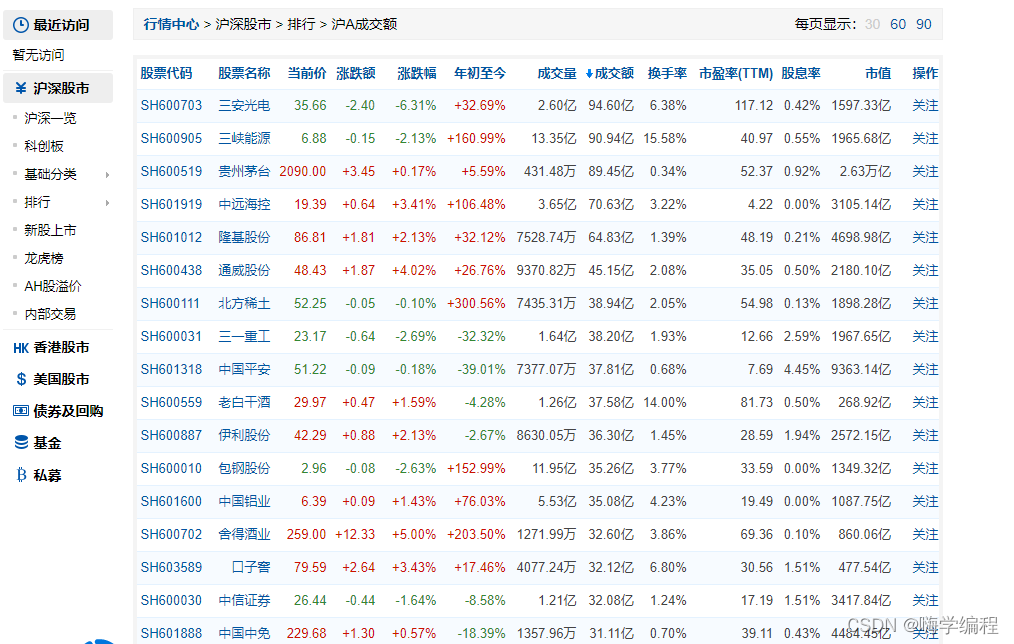
我国股票投资者数量为15975.24万户,如此多的股民热衷于炒股,首先抛开炒股技术不说,那么多股票数据也非常难找,密密麻麻的数据会让你看着头都大了。
我国股票投资者数量为15975.24万户,如此多的股民热衷于炒股,首先抛开炒股技术不说,那么多股票数据也非常难找,密密麻麻的数据会让你看着头都大了。
解释器版本: python 3.8
代码编辑器: pycharm 2021.2
requests
csv
不会安装软件看这篇:Python入门到精通最全最详细合集
不会安装模块看这篇:如何安装python模块, python模块安装失败的原因以及解决办法
目标地址
https://xueqiu.com/hq#exchange=CN&plate=1_3_2&firstName=1&secondName=1_3&type=sha&order=desc&order_by=amount
1.确定url地址(链接地址)
2.发送网络请求
3.数据解析(筛选数据)
4.数据的保存(数据库(mysql\mongodb\redis), 本地文件)
import requests # 发送网络请求 import csv file = open('data2.csv', mode='a', encoding='utf-8', newline='') csv_write = csv.DictWriter(file, fieldnames=['股票代码','股票名称','当前价','涨跌额','涨跌幅','年初至今','成交量','成交额','换手率','市盈率(TTM)','股息率','市值']) csv_write.writeheader() # 1.确定url地址(链接地址) for page in range(1, 56): url = f'https://xueqiu.com/service/v5/stock/screener/quote/list?page={page}&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha&_=1637908787379' # 2.发送网络请求 # 伪装 headers = { # 浏览器伪装 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36' } response = requests.get(url, headers=headers) json_data = response.json() # print(json_data) # 3.数据解析(筛选数据) data_list = json_data['data']['list'] for data in data_list: data1 = data['symbol'] data2 = data['name'] data3 = data['current'] data4 = data['chg'] data5 = data['percent'] data6 = data['current_year_percent'] data7 = data['volume'] data8 = data['amount'] data9 = data['turnover_rate'] data10 = data['pe_ttm'] data11 = data['dividend_yield'] data12 = data['market_capital'] print(data1, data2, data3, data4, data5, data6, data7, data8, data9, data10, data11, data12) data_dict = { '股票代码': data1, '股票名称': data2, '当前价': data3, '涨跌额': data4, '涨跌幅': data5, '年初至今': data6, '成交量': data7, '成交额': data8, '换手率': data9, '市盈率(TTM)': data10, '股息率': data11, '市值': data12, } csv_write.writerow(data_dict) file.close()
#我还给大家准备了这些资料,直接在群里就可以免费领取了。 #一群:872937351 (群满了的话加二群) #二群:924040232 #python学习路线汇总 #精品Python学习书籍100本 #Python入门视频合集 #Python实战案例 #Python面试题 #Python相关软件工具/pycharm永久激活
数据有点多,展示部分,这是数据已经保存到Excel了。

import pandas as pd # 做表格处理 data_df = pd.read_csv('data2.csv') print(data_df)
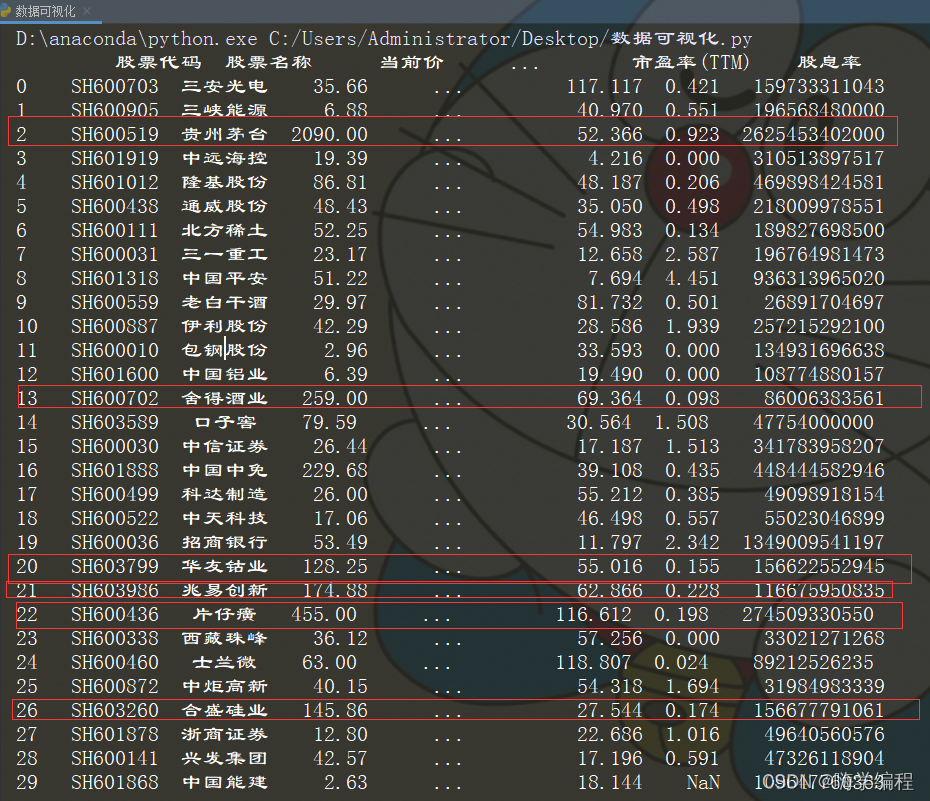
可以看到现在高居不下的依然是白酒、高科技、药业这几类,但是股票有风险,投资需谨慎,大家不是家里有矿,不建议买。