引子:
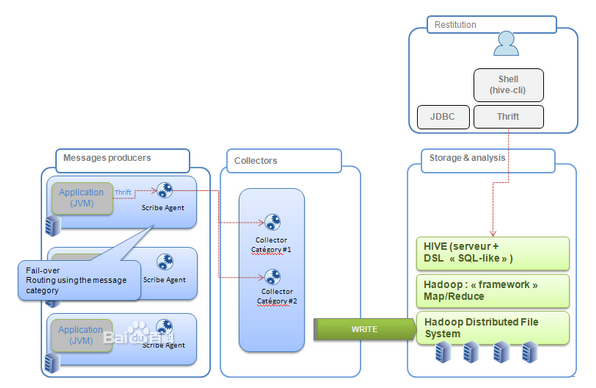
Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,scribe会将日志转存到本地或者另一个位置,当中央存储系统恢复后,scribe会将转存的日志重新传输给中央存储系统。其通常与Hadoop结合使用,scribe用于向HDFS中push日志,而Hadoop通过MapReduce作业进行定期处理。
Scribe从各种数据源上收集数据,放到一个共享队列上,然后push到后端的中央存储系统上。当中央存储系统出现故障时,scribe可以暂时把日志写到本地文件中,待中央存储系统恢复性能后,scribe把本地日志续传到中央存储系统上。需要注意的是,各个数据源须通过thrift(由于采用了thrift,客户端可以采用各种语言编写向scribe传输数据(每条数据记录包含一个category和一个message)。可以在scribe配置用于监听端口的thrift线程数(默认为3)。在后端,scribe可以将不同category的数据存放到不同目录中,以便于进行分别处理。后端的日志存储方 式可以是各种各样的store,包括file(文件),buffer(双层存储,一个主储存,一个副存储),network(另一个scribe服务 器),bucket(包含多个store,通过hash的将数据存到不同store中),null(忽略数据),thriftfile(写到一个 Thrift TFileTransport文件中)和multi(把数据同时存放到不同store中)。
本文通过3个实例程序,分别演示scribe后端存储为file、network和buffer时的操作方法和流程,演示示例程序位于scribe/examples目录,目录结构如下所示:[hadoop@hadoop1 examples]$ ls
example1.conf example2client.conf hdfs_example.conf scribe_cat
example2central.conf hdfs_example2.conf README scribe_ctrl
一、Example1:file
#step_01:创建消息文件存放目录
mkdir /tmp/scribetest
#step_02:启动Scribe
src/scribed examples/example1.conf
#step_03:发送消息到scribe
echo "hello world" | ./scribe_cat test
#step_04: 验证消息记录
cat /tmp/scribetest/test/test_current
#step_05: 检查scribe状态
./scribe_ctrl status
#step_06: 查看scribe计数
./scribe_ctrl counters
#step_07: 停止scribe运行
./scribe_ctrl stop
二、Example2:Network
#step_01:创建工作目录
mkdir /tmp/scribetest2
#step_02:启动中心scribe程序,服务端口1463,记录方式为file
src/scribed examples/example2central.conf
#step_03:启动中心client程序,服务端口1464,存储模式为Network,写入消息到中心scribe
src/scribed examples/example2client.conf
#step_04:发送消息到client scribe
echo "test message" | ./scribe_cat -h localhost:1464 test2
echo "this message will be ignored" | ./scribe_cat -h localhost:1464 ignore_me
echo "123:this message will be bucketed" | ./scribe_cat -h localhost:1464 bucket_me
#step_05:验证消息被中心scribe接收和记录到文件
cat /tmp/scribetest/test2/test2_current
#step_06:验证消息分组,不同category的数据存放到不同目录中
cat /tmp/scribetest/bucket*/bucket_me_current
#step_07:状态检查消息计数检查,如果管理命令不加参数默认为1643
./scribe_ctrl status 1463
./scribe_ctrl status 1464
./scribe_ctrl counters 1463
./scribe_ctrl counters 1464
#step_08:关闭服务进程
./scribe_ctrl stop 1463
./scribe_ctrl stop 1464
三、Example3:buffer
#step_01:启动中心scribe,服务端口1463
src/scribed examples/example2central.conf
#step_02:启动客户端scribe,服务端口1464
src/scribed examples/example2client.conf
#step_03:发送消息到客户端scribe
echo "test message 1" | ./scribe_cat -h localhost:1464 test3
#step_04:验证消息是否接受,在中心scribe消息存储目录查找
cat /tmp/scribetest/test3/test3_current
#step_05:停止中心scribe服务,我们期待看到结果是缓存
./scribe_ctrl stop 1463
#step_06:验证中心scribe运行状态
./scribe_ctrl status 1463
#step_07:发送消息到客户端-此时消息期待结果是缓存
echo "test message 2" | ./scribe_cat -h localhost:1464 test3
#step_08:超时客户端scribe会有报警信息
./scribe_ctrl status 1464
#step_09:重启中心scribe
src/scribed examples/example2central.conf
#step_10:验证scribe状态
./scribe_ctrl status 1463
./scribe_ctrl status 1464
#step_10:验证中心scribe是否接收到缓存的消息
cat /tmp/scribetest/test3/test3_current
#step_11:关闭服务进程
./scribe_ctrl stop 1463
./scribe_ctrl stop 1464
四、工作流程
通过以上实例,我们可以看到scribe核心的工作原理和处理流程,具体流程如下图所示: