字符编码问题
ASCII:
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统。 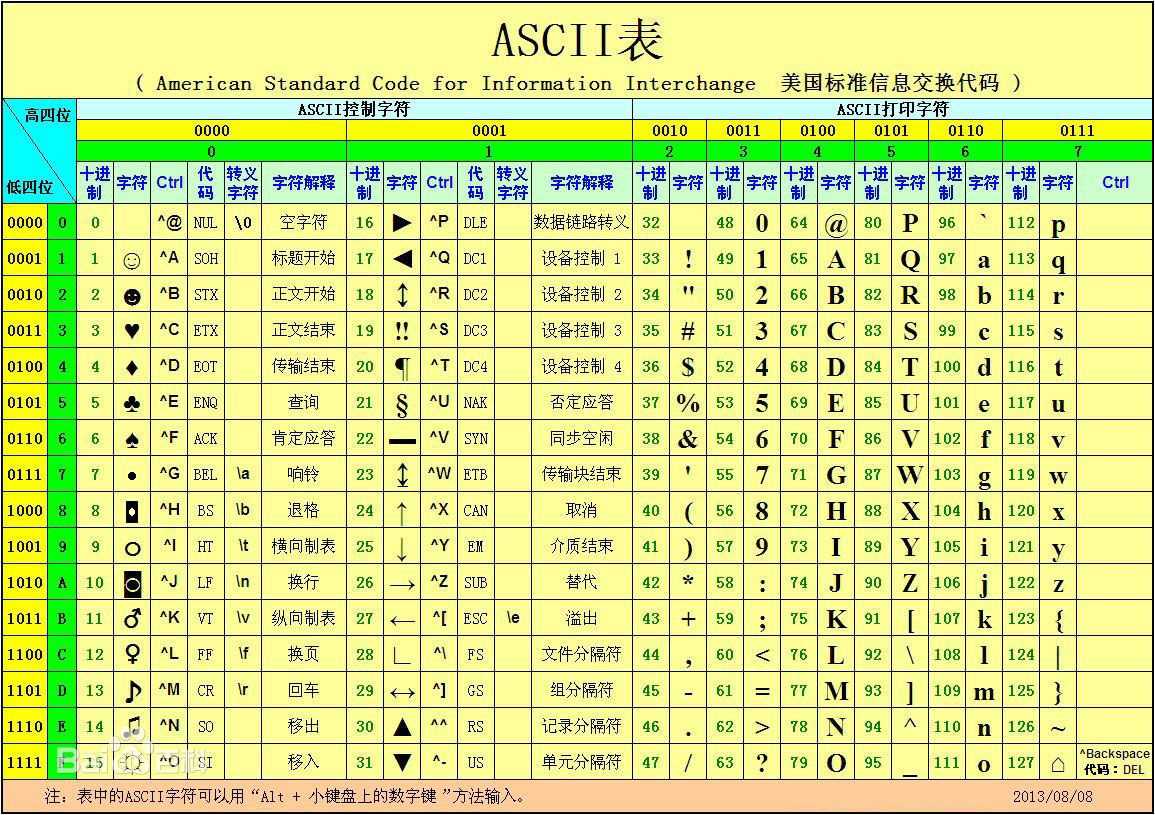
ASCII码和字符之间的转换:
-
ord() 将字符转换为ASCII码(十进制) chr() 将ASCII码(十进制)转换为字符 例如: print(ord('a')) #打印 97 print(chr(97)) #打印 a
GBK编码:
GBK2312(6700多汉字) --> GBK1.0(1995年推出,20000余汉字) --> GBK18030 (2000年推出,27000余汉字)
unicode:
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。支持所有的国家和地区的编码;2**16次方即支持65535个字符位;所有字符统一占用2个字节;
UTF-8:
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。原本西方国家的ASCII字符占用一个字符,改用unicode之后,变成了2个字符,为了解决占用内存空间的问题,才产生了utf-8字符集。统一规定,原本ASCII的字符占用一个字节,欧洲国家(德语等)占用2个字节,东亚国家的占用3个字节。
python中的字符编码
python2中,默认字符编码为ASCII
python3中,默认字符编码为unicode;文件默认编码是utf8
字符编码转换
-
python2中:
decode()方法将其他编码字符转化为Unicode编码字符。 encode()方法将Unicode编码字符转化为其他编码字符。 -
python3中:
decode()方法将其他编码字符转化为Unicode编码字符。字符串 encode()方法将Unicode编码字符转化为其他编码字符。字节码
例如(python3中):
"hello world".encode('utf8') # 指定encode到utf8编码格式;python3中默认的unicode的;

python3 除了把字符串的默认编码改成了unicode, 还把 str 和 bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制;