文章一开始发表在微信公众号
https://mp.weixin.qq.com/s?__biz=MzUyNzc4Mzk3MQ==&mid=2247486189&idx=1&sn=135bcd6cbc4c911d267efff4b9772a23&chksm=fa7b0ba1cd0c82b75a406ce55b27a519595b7369f51fad12bff04054d1051a2f46e693fc1d0e&scene=21#wechat_redirect
Fuzz技术综述
Fuzzing是一种高效的漏洞挖掘方法,它通过不断地让被测程序处理各种畸形测试数据来挖掘软件漏洞。一个Fuzz工具由三个基础模块组成,分别是测试用例生成模块、程序执行模块以及异常检测模块。
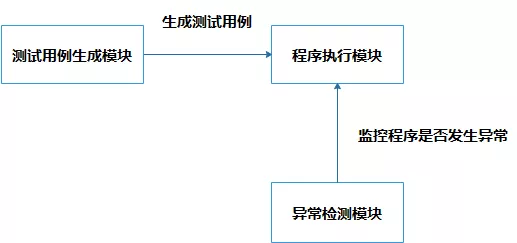
各个模块的作用以及模块间的交互如下:
- 测试用例生成模块负责不断的生成测试用例,然后会把测试用例交给程序执行模块。
- 程序执行模块根据被测程序接收数据的方式启动程序并把测试用例交给目标程序处理。
- 异常检测模块负责监控程序在处理测试用例时是否发生异常,如果发生了异常就保存异常信息。
Fuzz工具按照生成测试数据的方式可以分为基于生成的Fuzz工具(Generation Based Fuzzer)和基于变异的Fuzz工具(Mutation Based Fuzzer)。Generation Based Fuzzer通过用户提供的数据格式描述文档(比如peach的pit文件)来生成测试数据,如下所示是一个c语言表示的结构体
struct{
int ID;
int Size; // data 的长度
data[Size]; // data数组
}
该结构体用 pit 文件描述如下
<DataModel name="Chunk">
<Number name="ID" size="32" value="0x12345678" />
<Number name="Size" size="32" >
<Relation type="size" of="Data" />
</Number>
<Blob name="Data" valueType="hex" value="aa bb cc dd ee ff 11 22"/>
</DataModel>
pit文件写好后用peach解析就可以生成示例数据,比如该pit文件生成的测试数据如下
可以看到生成的数据和我们在pit文件中描述的默认值符合。
ID: 78 56 34 12 // 0x12345678的小端表示
Size: 08 00 00 00 // 4字节,表示Data的长度
Data: aa bb cc dd ee ff 11 22 // 8 个字节的Data数据
Mutation-Based Fuzzer通过对用户提供的初始数据进行一系列变换(比如Bit翻转,随机插入数据等)来生成测试数据,一个简单数据变异示例图如下
为了提升Fuzz的测试效率,基于覆盖率引导的Fuzz工具(Coverage Guided Fuzzer)应运而生。Coverage Guided Fuzzer会在Fuzz的过程中为Fuzzer提供覆盖率信息,之后Fuzzer会将能够产生新代码覆盖率的用例保存下来用于后续的Fuzz,通过这种方式可以逐步提升Fuzzing测试的覆盖率,此时的Fuzzing流程图如下所示:
当Fuzz时生成的测试用例产生了新的路径时,就把该用例添加到样本池用于后续的测试。
对于Fuzz测试而言有两个非常关键的因素:Fuzz的样本集和速度。一个比较好的样本集可以让程序在Fuzz的一开始就达到很高的覆盖率,一般来说覆盖率越高,挖出漏洞的概率也就越大。Fuzz的速度对漏洞挖掘的影响也是类似,Fuzz的速度越快,相同时间内Fuzz的次数也就越多,也就能测试更多的代码,一样可以提升挖出漏洞的概率。所以在Fuzz的过程中,我们始终要想办法提升Fuzz的速度和覆盖率。
为了获取到一个高质量的初始样本集首先我们需要获取到足够数量的样本,常见的样本获取途径有以下几种:
- 从一些提供样本集的在线站点获取
- 通过搜索引擎的语法爬取大量的样本文件
- 一些开源项目会带一些测试用例来测试程序
- Fuzz其他类似软件时生成的样本文件
- 目标程序或者类似程序的bug提交页面
- 用格式转换工具生成
一些常用的在线样本集获取网址
https://files.fuzzing-project.org/
http://samples.ffmpeg.org/
http://lcamtuf.coredump.cx/afl/demo/
https://github.com/MozillaSecurity/fuzzdata
https://github.com/strongcourage/fuzzing-corpus
https://github.com/Cisco-Talos/clamav-fuzz-corpus
https://github.com/mozilla/pdf.js/tree/master/test/pdfs
https://github.com/codelibs/fess-testdata
https://github.com/google/honggfuzz/tree/master/examples/apache-httpd
在获取到大量的测试样本后还需要对样本集进行精简,因为其中的很多样本能触发的路径是一样的,这样会导致Fuzzer可能花了大量的时间在测试同一块代码,从而降低Fuzzing效率。常见的精简样本集的思路是让程序逐个处理样本,然后把能够产生新路径的样本保留下来,这样就能在保留代码覆盖率的前提下大大减少样本集的数量,如下图所示,初始样本有5个,其中样本A、B、E可以覆盖5个样本的总覆盖路径,那么样本精简后的结果就是A、B、E。
提升Fuzz测试的速度有很多种,其中比较通用的方法有内存磁盘、并行执行多个Fuzz任务。对AFL以及其衍生的Fuzz工具而言还可以通过延时初始化forkserver来提升Fuzz的速度,这些方式的具体应用我们在本章的后面逐一介绍。
文件Fuzz
Honeyview是一款流行的图片浏览器,支持多种图片文件格式,本节以Honeyview为例来介绍两种常见的文件Fuzz方式: Generation Based Fuzzing 和 Mutation Based Fuzzing。
Generation Based Fuzzing
本节介绍如何使用Peach来进行Generation Based Fuzzing。Peach是一款用C#开发的跨平台Fuzz工具,支持Windows、Linux、OS X等平台。 Peach支持对文件格式、网络协议等进行Fuzz测试 。Peach使用 pit 文件来描述数据的格式,然后在Fuzz过程中通过解析pit文件来生成测试用例去Fuzz。Peach的官方文档如下
http://community.peachfuzzer.com/v3/ref.html
本节以png文件格式为例介绍pit文件的编写,首先我们先看看png文件的格式,png文件由多个chunk组成
png文件的文件头是8个固定的字节
89 50 4E 47 0D 0A 1A 0A
后面紧接着的各种不同的 chunk, chunk的格式如下
struct{
int length; // chunk 的长度
type[4]; // chunk 的类型
data[length]; // chunk 的数据
int crc; // data 的 crc校验和
}
png文件中第一个chunk的类型是IHDR,最后一个chunk的类型是IEND,各种chunk的定义可以去官方文档查询
http://www.libpng.org/pub/png/spec/1.2/PNG-Chunks.html
那么描述chunk的Pit文件内容如下
<DataModel name="Chunk">
<Number name="Length" size="32" endian="big" mutable="true">
<Relation type="size" of="Data" />
</Number>
<Block name="TypeData">
<Blob name="Type" length="4" />
<Blob name="Data" />
</Block>
<Number name="crc" size="32" endian="big" mutable="true">
<Fixup class="Crc32Fixup">
<Param name="ref" value="TypeData"/>
</Fixup>
</Number>
</DataModel>
简单介绍下上面使用的一些 pit 语法
Number: 表示数字类型, size指定该字段的大小,单位是 bit(位),这里就是32bit,也就是4个字节
Blob: 表示一段二进制数据,length指定二进制数据的长度,单位是自己
Block: 用于组合表示一些字段
Relation: 表示字段之间的关系,比如上面表示Length是Data的长度
Fixup: 用于基于其他的字段计算一个值比如hash、crc等,文件中crc的值就是是TypeData的crc校验和
然后我们通过引用这个结构体来构建一些特定的 chunk 类型,比如 IHDR 类型的 chunk 和 IEND类型的chunk.
<DataModel name="Chunk_IHDR" ref="Chunk">
<Block name="TypeData">
<String name="Type" value="IHDR" length="4" token="true"/>
<Block name="Data">
<Number name="width" size="32" mutable="true"/>
<Number name="height" size="32" mutable="true"/>
<Number name="bits" size="8" mutable="false"/>
<Number name="color_type" size="8" />
<Number name="compression" size="8" />
<Number name="filter" size="8" />
<Number name="interlace" size="8" />
</Block>
</Block>
</DataModel>
<DataModel name="Chunk_IEND" ref="Chunk">
<Block name="TypeData">
<String name="Type" value="IEND" length="4" token="true" />
<Blob name="Data" length="0" />
</Block>
</DataModel>
最后我们把这些组合起来构建一个 png 的 DataModel
<DataModel name="Png">
<Number name="Signature" valueType="hex" value="89504e470d0a1a0a" size="64" token="true" />
<Block name="IHDR" ref="Chunk_IHDR"/>
<Choice name="DataChunks" minOccurs="2" maxOccurs="30000">
<Block name="PLTE" ref="Chunk"/>
</Choice>
<Block name="IEND" ref="Chunk_IEND"/>
</DataModel>
描述的内容如下
- 首先8个字节的Signature开头
- 然后以一个IHDR的chunk开始
- 然后使用Choice随机生成多个chunk
- 最后生成一个type为IEND的chunk
定义好后 DataModel 后就需要配置pit文件来生成测试用例并将测试用例传递给目标程序进行处理,具体可以看下面的注释
<StateModel name="TheState" initialState="Initial">
<State name="Initial">
<Action type="output">
<DataModel ref="Png"/>
</Action>
<Action type="close"/>
# 输出样本后 call LaunchViewer 通知 Agent
<Action type="call" method="LaunchViewer" publisher="Peach.Agent"/>
</State>
</StateModel>
<Agent name="WinAgent">
<Monitor class="WindowsDebugger">
# 被测程序执行的命令行
<Param name="CommandLine" value='"C:Program FilesHoneyviewHoneyview.exe" "C:\Users\XinSai\Desktop\honeyview.png"' />
# 当接收到 call LaunchViewer 后才启动被测程序
<Param name="StartOnCall" value="LaunchViewer" />
<Param name="CpuKill" value="true"/>
</Monitor>
</Agent>
<Test name="Default">
<Agent ref="WinAgent" platform="windows"/>
<StateModel ref="TheState"/>
# 定义输出样本数据到 C:UsersXinSaiDesktophoneyview.png
<Publisher class="File">
<Param name="FileName" value="C:\Users\XinSai\Desktop\honeyview.png"/>
</Publisher>
<Logger class="Filesystem">
<Param name="Path" value="logs" />
</Logger>
</Test>
写好配置文件后使用 peach.exe 解析xml文件就可以开始Fuzzing了。
Peach.exe samplesdemo.xml
参考
https://github.com/aflsmart/aflsmart/blob/master/input_models/png.xml
Mutation Based Fuzzing
基于变异的Fuzzing原理很简单,它通过对初始样本进行随机变换(比如比特翻转、随机插值等方式)来生成新样本,本节将介绍如何从头开始实现一个基于变异的文件Fuzzer。前面提到过一个Fuzzer有三个基础组件测试用例生成模块、程序执行模块以及异常检测模块,下面逐一介绍其实现。
测试用例生成模块通过对初始数据进行一系列变异操作来生成新的测试用例,为了实现变异,我们需要先定义一系列变异操作函数
MANGLE_FUNCS = [
lambda data: mangle_bytes(data),
lambda data: mangle_magic(data),
lambda data: mangle_add_sub(data),
lambda data: mangle_mem_copy(data),
lambda data: mangle_mem_insert(data),
lambda data: mangle_memset_max(data),
lambda data: mangle_random(data),
lambda data: mangle_clonebyte(data),
lambda data: mangle_expand(data),
lambda data: mangle_shrink(data),
lambda data: mangle_insert_rnd(data),
lambda data: mangle_copy_token(data),
lambda data: mangle_insert_token(data)
]
这些函数都接收待变异的初始数据,然后返回变异后的数据。如下所示是一个示例函数,其作用是往原始数据的随机位置覆写2~4字节的随机数据.
def mangle_bytes(data):
"""
在随机位置覆盖写2~4字节数据
"""
length = len(data)
if length < 4:
return data
# 获取要填充的数据的长度
size = random.randint(2, 4)
# 获取插入位置, length - size 确保不会越界
idx = random.randint(0, length - size)
# 获取 size 长的随机字符串, 然后复写到指定位置
return replace_string(data, get_random_string(size), idx)
在进行数据变异时,Fuzzer会随机选择其中的几个函数依次变异数据。
def mutate(self, data, maxlen=0xffffffff, fuzz_rate=1):
"""
对 data 进行变异
:param data: 待变异的数据
:param callback: 对变异后的数据进行修正的callback 函数,比如 crc, header等
:param fuzz_rate: 数据变异的比率, 用于决定变异的数据长度 , len(data) * fuzz_rate
:return:
"""
length = len(data)
fuzz_len = int(length * fuzz_rate)
# 选取数据中的某个区域传给数据变异函数去进行变异操作
off = random.randint(0, length - fuzz_len)
pre = data[:off]
post = data[off + fuzz_len:]
data = data[off:off + fuzz_len]
count = random.randint(1, self.mutate_max_count)
for i in xrange(count):
# 随机选取一个变异函数
func = self.mutate_funcs[random.randint(0, self.mutate_func_count - 1)]
data = func(data)
if len(data) >= maxlen:
data = data[:maxlen - 1]
data = pre + data + post
# 对数据进行后处理,比如计算校验和等
if self.callback:
data = self.callback(data)
return data
生成好测试数据后就需要把测试数据交给目标程序去处理并监控程序在处理数据时是否发生了异常,这里我们使用 winappdbg 来启动程序并监控程序的执行,主要代码如下
def fuzz(self):
count = 1
start = time.time()
while True:
seed = self.read_file_data(random.choice(self.seeds))
for i in range(10):
print "test: {}".format(count)
# 从 seed 变异出测试用例
self.testcase = self.mutater.mutate(seed, fuzz_rate=0.3)
# 把测试用例写入文件
self.write_file_data(self.target_read_from, self.testcase)
# 用调试器加载程序让它去处理数据
debugger = winappdbg.Debug(self.exception_handler, bKillOnExit=True)
proc = debugger.execv(self.cmdline)
# 开一个线程超时就 kill 掉进程
thread.start_new_thread(self.timeout_killer, (proc,))
debugger.loop()
if count % 10 == 0:
delta = time.time() - float(start)
# print delta
print "test rate: {}/s".format(delta / count)
count += 1
代码流程为
- 随机从初始样本集中选取一个样本进行变异。
- 把生成的变异数据写入文件。
- 然后用winappdbg启动目标程序处理数据。
- 然后新建一个线程 timeout_killer ,这个线程在指定的超时时间后杀掉目标进程。
- debugger.loop()用于等待被测进程结束。
这样一来我们的 Fuzzer 基本功能就完成了,下面组合一下就可以开始fuzzing了。
if __name__ == "__main__":
cmd = '"C:\Program Files\HoneyviewHoneyview.exe" "C:\Users\XinSai\Desktop\honeyview.gif"'
print shlex.split(cmd)
fuzzer = FileFuzzer("C:\fuzz\afl_testcases\gif\full\", shlex.split(cmd),
"C:\Users\XinSai\Desktop\honeyview.gif")
fuzzer.fuzz()
脚本中的一些参数信息如下
cmd: 执行目标程序处理数据的命令行
C:fuzzafl_testcasesgiffull: 初始样本集所在的目录
C:UsersXinSaiDesktophoneyview.gif: 执行cmd后目标程序读取文件的路径,后面Fuzzer会把生成的测试数据写入这里
执行时的截图如下
Fuzzing优化
由于Honeyview在解析完图片后不会退出程序,而是会停留在GUI界面等待用户操作,这样会大大减少Fuzz的测试速度。本节实现的Fuzzer的解决方案是在启动程序前设置一个超时时间(比如3秒),当超时时间达到后就调用相应的函数结束目标进程。这种方案的缺点在于程序每次执行的时间都是固定的,当Honeyview在处理小样本(执行时间小于3秒)时会导致时间浪费,而在处理大样本(执行时间大于3秒)时又会导致程序对图片的解析不完全而影响Fuzz的结果。为了解决这个问题,下面提出两种优化方法:基于二进制patch的方案和基于进程cpu监控的方案。
基于二进制patch的方案
我们可以通过patch程序的方式来让程序在解析完文件后就退出程序,具体的方法是找到目标程序解析完文件后紧接着执行的代码,然后把代码patch为进程退出代码,这样在程序解析完图片后就会自动结束进程。
为了能够方便的找到程序处理完图片后紧接着执行的代码区域,本节基于dynamorio实现了一个小工具来记录程序执行的基本块信息。dynamorio是一款二进制插桩工具,基于dynamorio用户可以实现覆盖率获取、程序执行路径追踪、函数hook等功能,dynamorio的工作示意图如下:
dynamorio的工作机制是不断地去翻译被插桩程序的代码来构建基本块,然后对构建好的基本块进行操作(比如增删代码等),最后把基本块转换成二进制代码保存到code cache里面,之后被插桩程序会从code cache里面执行代码,而被插桩程序原始的代码则永远不会被执行,使用dynamorio来插桩程序时的执行流程如下:
- 首先系统会从dynamorio的代码开始执行,dynamorio会把目标程序加载起来并获取到程序的入口点。
- dynamorio从被插桩程序的代码区域读取代码并解析指令,然后对解析得到的指令进行增加和修改,构建基本块。
- 然后把构建好的基本块的代码存放到 dynamorio的code cache里面。
- dynamorio转移cpu的控制权,被插桩程序去code cache里面执行基本块。
- 如果发现要接下来要执行的基本块不在code cache里面,被插桩程序会转移cpu控制权给dynamorio,进入第2步不断翻译基本块。
用户通过编写插件来使用dynamorio提供的能力,插件的入口函数为dr_client_main函数
DR_EXPORT void
dr_client_main(client_id_t id, int argc, const char *argv[])
{
// 一些初始化操作
dr_set_client_name("BBLOG", "");
drmgr_init();
drx_init();
drwrap_init();
dr_register_exit_event(event_exit);
// 注册模块加载回调函数,当有新模块加载时会调用 event_module_load
drmgr_register_module_load_event(event_module_load);
// 打开 log.txt, 用于存放bbl信息
LOG_FD = dr_open_file("log.txt", DR_FILE_WRITE_APPEND);
//注册基本块构建函数,每当有新的基本块构建好后会调用 event_bb_analysis 函数
drmgr_register_bb_instrumentation_event(event_bb_analysis, NULL, NULL);
}
主要就是注册了一堆回调函数,event_bb_analysis会在每一个基本块构建好之后调用,在这个函数里面会把bbl记录下来
static dr_emit_flags_t
event_bb_analysis(void *drcontext, void *tag, instrlist_t *bb, bool for_trace,
bool translating, void **user_data)
{
app_pc pc = dr_fragment_app_pc(tag);
if (pc > target.start && pc < target.end) {
dr_fprintf(LOG_FD, "%p
", pc - target.start);
}
return DR_EMIT_DEFAULT;
}
target结构体在event_module_load函数里面初始化,里面保存着Honeyview.exe在内存中的起始地址
static void
event_module_load(void *drcontext, const module_data_t *info, bool loaded)
{
const char *module_name = info->names.exe_name;
if (module_name == NULL) {
module_name = dr_module_preferred_name(info);
}
dr_fprintf(LOG_FD, "Module loaded, %s
", module_name);
if (strstr(module_name, "Honeyview.exe")) {
target.start = info->start;
target.end = info->end;
dr_fprintf(LOG_FD, "Honeyview.exe:%p-----%p
", target.start, target.end);
}
}
官方推荐使用cmake编译client, vs2015下的编译命令如下
cmake -G"Visual Studio 14 2015" .. -DDynamoRIO_DIR=C:UsersXinSaiDesktopwinafl-masterDynamoRIO-Windows-7.91.18187-0cmake
其中 -DDynamoRIO_DIR 指定dynamorio的全路径,编译64位client的命令如下
cmake -G"Visual Studio 14 2015 Win64" .. -DDynamoRIO_DIR=C:UsersXinSaiDesktopwinafl-masterDynamoRIO-Windows-7.91.18187-0cmake
执行dynamorio并加载client的命令如下
DynamoRIO-Windows-7.91.18187-0in64drrun.exe -c C:UsersXinSaiDesktophoneyviewbloguild64Debugblog.dll -- "C:Program FilesHoneyviewHoneyview.exe" C:UsersXinSaiDesktophoneyviewpnggrad16rgb.png
其中-c指定client模块的全路径,执行后会在当前目录下生成log.txt文件,里面保存进程执行的BBL信息,某次执行的日志文件的最后几行如下
0x00000000001eed32
0x00000000001e7008
0x00000000001e7028
0x00000000001e7066
0x00000000001ec1af
0x00000000001eed3c
0x0000000000283744
0x0000000000290950
0x0000000000290965
当程序处于等待用户交互时,其程序会处在一个循环里面,其简单的流程如下
while True:
if 有用户请求:
处理
else:
休息一段时间
所以为了找到程序解析完文件然后等待用户操作的代码区域,我们可以去关注那些位于循环中基本块。通过不断的分析和patch尝试,找到 1eed3c 的调用者处于一个循环内
.text:00000001401E885E mov rcx, rdi
.text:00000001401E8861 mov [rdi+393Ch], ebp
.text:00000001401E8867 call sub_1401EBE70 //会执行到 1eed3c
.text:00000001401E886C test eax, eax
.text:00000001401E886E jnz short loc_1401E8878
.text:00000001401E8870 mov rcx, rdi
其对应的f5代码如下
然后把这个函数调用patch为ExitProcess(0)
.text:00000001401E8861 xor rcx, rcx
.text:00000001401E8864 nop
.text:00000001401E8865 nop
.text:00000001401E8866 nop
.text:00000001401E8867 call ExitProcess
这样当程序解析完图片进入GUI界面之后就会退出。通过这种方式我们的Fuzzer的测试时间从3.2秒每次降到了1.6秒每次。
基于进程cpu监控的方案
当进程在解析图片时,进程的CPU使用率会比较高,当进程解析完图片等待用户交互时其CPU占用率会非常低,接近百分之0。在python中我们可以使用 psutil 库获取到目标进程的CPU使用率,当CPU使用率为0时就结束进程,主要的代码如下
def get_cpu_usage_by_pid_no(self, pid):
p = psutil.Process(pid)
p.cpu_percent(None)
sleep(0.5)
usage = p.cpu_percent(None)
return usage
def kill_when_cpu_free(self, proc):
"""
当cpu使用率为0时 kill 进程
:param proc:
:return:
"""
count = 0
while count < 1:
usage = self.get_cpu_usage_by_pid_no(proc.get_pid())
print usage
if usage == 0:
count += 1
try:
proc.kill()
except:
pass
使用这种方式Fuzzer的执行速度为 1.2秒每次,速度提升还是比较明显的。