笔者第一份工作就是以java工程师的名义写爬虫,不得不说第一份工作很重要啊,现在除了爬虫不会干别的,到现在已经干了近5年了,期间经历了不少与反爬策略的斗争。最近又耗时两周成功搞定了某网站的反爬策略后,心里有点莫名的惆怅。今日无心工作,就总结下这些年与网站互怼的经验吧。
无反爬裸站
现在一个网站或多或少都会配置一定的反爬措施,毕竟现在一台笔记本的性能比某些小站的服务器都强,如果不加以限制,分分钟就能把你的资源耗尽。前两年的工商网站有个省份没有限制,没多久就把服务器抓瘫了(只能说服务器配置太太太次了);如果你服务器能抗那就更好了,用不了多久就能把你全站数据抓下来。记得两年前收集企业名录,一个网站几百万条用了不到两个小时就抓完了。但现在心态变了,如果遇到一个没有验证码的网站,我都会尽量抓得慢一点。毕竟都是搞编程的,你如果把人家抓急了,逼得他改网站,改完后自己还得跟着改,冤冤相报何时了?在此也希望大家能手下留情,不要遇见个好欺负的就往死里整,毕竟咱们要的是数据,又不是来寻仇的。
验证码
验证码可以说是最基本最常见的反爬策略了,但在某种程度上也是最容易破解的。
弱验证码
这里说的弱验证码就是那种直接扔给tesseract就能识别出来的,或者经过简单处理。比如
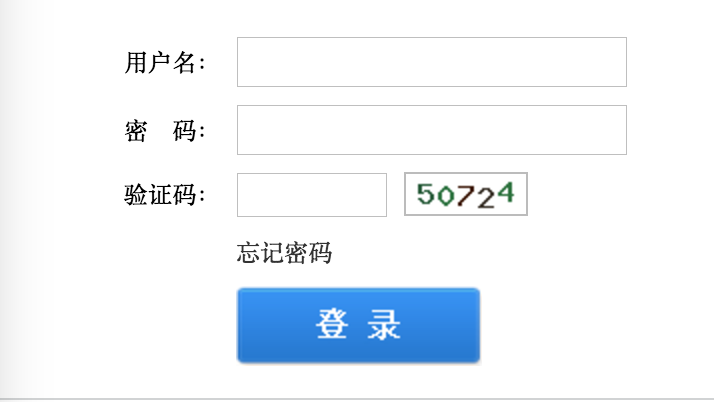
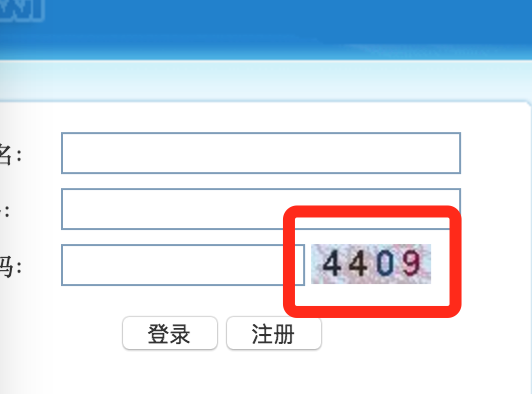
上面两种验证码,第一种不用任何处理直接用pytesseract就可以识别。第二种经过简单的灰度变换->二值化后能得到比较干净清晰的图像,再用tesseract就可以识别了。如下图
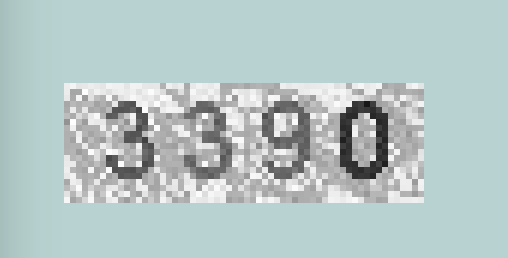

假验证码
假验证码就是那种用来吓唬人的验证码。比如之前某汽活动页上面的验证码会隐藏在页面中,点击提交时会用js判断验证码是否正确。还有的网站验证码就是摆设,提交的表单中根本就没有验证码参数。
强验证码
像下面这种验证码可以算是正常的验证码了,由于有变形与粘连,简单的处理已经无法识别了。
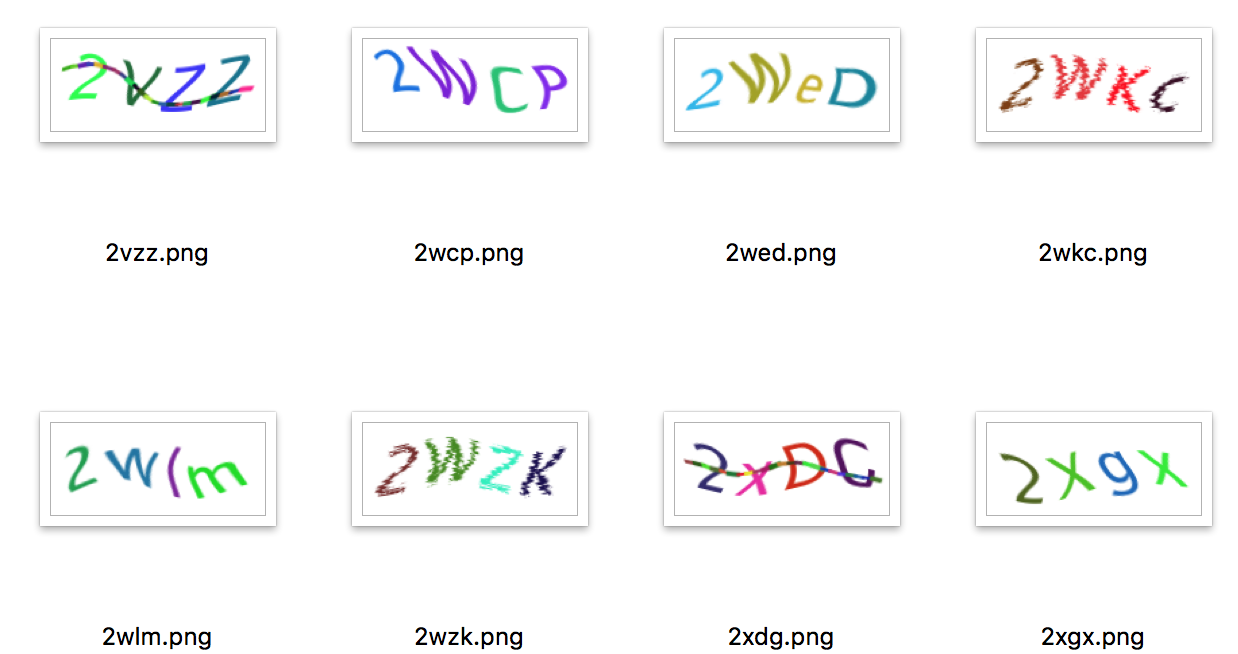
对于这种验证码用神经网络可以达到很高的识别率,但训练耗时较长(如果有gpu会快很多),而且需要大量标注的样本。笔者用了2万个样本做训练,识别率能达到86%左右。
神经网络有个缺陷是只能识别“学习”过的样本,对于英文加数字来说除去大小写只有36种可能,所以识别率会很高。但识别难度与训练强度会随着分类数量成指数级提高。所以笔者认为,使用中文做验证码并对图像做混淆粘连处理后就可以算是强验证码了(话不能说太满,毕竟我只是个数学很差的专科生)。
请求限制
即对请求速度有限制,或封禁的手段
伪封ip
为什么要加个“伪”字呢?因为对于某些网站,它们会将某些请求头中的ip看作用户的真实ip,比如X-Forwarded-For, X-Real-IP, Via。对于这种网站该怎么做不用我多说了吧。之前某些省份的工商网站就用了这种手段。
ua限制
即User-Agent,有些网站用User-Agent当作用户的惟一标识,这种手段会有很大的误伤,所以很少见,一般只出现在小网站上。
cookie
某些网站会通过set-cookie将请求次数写在用户的cookie里,写代码时只要禁用cookie就行了。
加密
常用的加密算法也就那几种:对称加密的AES, DES;消息摘要的md5, sha1;此外还有使用定制的base64编码;笔者在网页中还没见过到使用非对称加密的,在app中也很少见到。
对于对称加密只要找到密钥就没事了,如果AES使用的CBC模式,还需要找出iv。关于AES的ECB, CBC工作模式大家可以百度下。
消息摘要一般用来作签名,服务端会用它判断请求参数是否被非法篡改。这也不难,一般是把参数值(有时也包含参数名)按一定顺序再加上某些计算就能得到。
对于定制的base64,只要找出未公开的码表就行了,这个之前有人分享过。好像新版的极验里就有用到。
非对称加密一般很少见,但现在的app更多的会用到SSL Certificate Pinning技术。不知大家有没有遇到过某些app,一使用burp suite或fiddler抓包就无法联网,关上代理后就正常了,这就是ssl证书绑定,简单来说就是app使用自签名的证书与服务端建立ssl。https协议在建立连接之前客户端会将预置的公钥和服务端返回的证书做比较。如果一致,就建立连接,否则就拒绝连接,从而导致程序无法联网。关于SSL pinning的详情与破解可以参考这篇文章突破https——https抓包
其他渠道
有时网站的反爬做得比较厉害,继续怼的话要么太费时要么太费力,这时不妨换个路子。比如去年有段时间裁判文书网用了某数的waf,分析了将近一个月没有成果,但发现该网站还有个app,做得特别low,经过简单抓包逆向后成功拿到数据,而且数据还是json格式化后的,连解析都省了。还有的网站pc端是www.xxx.com,如果换成移动端的ua会变成m.xxx.com,而一般移动端的页面比较简洁,反爬策略可能与主站不一样。通过查找子域名可能会有收获。
以上是暂时想到的一些经验,希望能有所帮助,同时也希望大家在抓数据的时候能够手留情别抓得太狠,如果把一个数据源抓废了对大家都不好,正好那句话说的,IT人何苦为难IT人。