什么是视图
可以通过创建表的视图来表现数据的逻辑子集或数据的组合。视图是基于表或另一个视图的逻辑表,一个视图并不包含它自己的数据,它象一个窗口,通过该窗口可以查看或改变表中的数据。视图基于其上的表称为基表。
视图的索引是基于所依赖的表的索引
视图View
视图是从若干基本表和(或)其他视图构造出来的表
视图存放的都是查询语句,并没有真实的数据
虚表
作用
限制对数据的操作
复杂查询变简单
提供相同数据的不同显示
UNION ALL
直接添加到一起
UNION
添加到一起并去重
--赋予scott用户创建视图的权限 sqlplus / as sysdba; GRANT CREATE VIEW TO SCOTT; --创建视图 CREATE OR REPLACE VIEW V_EMP AS SELECT * FROM EMP WHERE ENAME LIKE '%A%' UNION ALL SELECT * FROM EMP WHERE ENAME LIKE '%S%' UNION ALL SELECT * FROM EMP WHERE SAL >= 3000; CREATE OR REPLACE VIEW V_EMP AS SELECT * FROM EMP WHERE ENAME LIKE '%A%' UNION SELECT * FROM EMP WHERE ENAME LIKE '%S%' UNION SELECT * FROM EMP WHERE SAL >= 3000; --删除视图 DROP VIEW V_EMP; /* 序列 一个连续递增的数列 */ --创建序列 CREATE SEQUENCE SEQ_BJSXT START WITH 20001 INCREMENT BY 2 MAXVALUE 99999999 MINVALUE 1 CYCLE CACHE 50 --删除数列 DROP SEQUENCE SEQ_BJSXT; --查询数列 SELECT SEQ_BJSXT.NEXTVAL FROM DUAL; /* 索引 饕餮 就类似于字典的索引 大大提高了数据库的查询性能 索引会占单独的存储空间,如果建立不合适有可能导致索引数据远大于真实数据 索引会降低数据库的增删改性能 */ SELECT E.*,ROWID FROM EMP E; --创建索引 CREATE INDEX IDX_EMP_ENAME ON EMP(ENAME);
视图的优越性
• 视图限制数据的访问,因为视图能够选择性的显示表中的列。
• 视图可以用来构成简单的查询以取回复杂查询的结果。例如,视图能用于从多表中查询信息,而用户不必知道怎样写连接语句。
• 视图对特别的用户和应用程序提供数据独立性,一个视图可以从几个表中取回数据。
视图类型
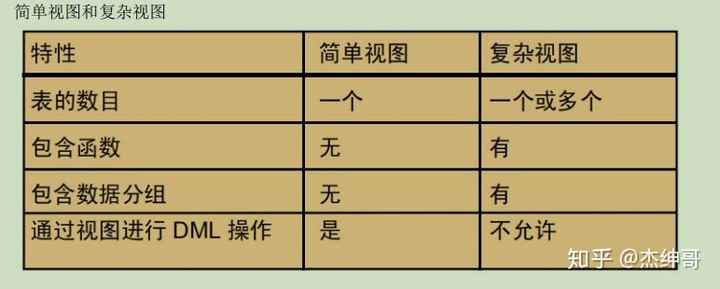
视图有两种分类:简单和复杂,基本区别涉及 DML (INSERT、UPDATE 和 DELETE)操作。
简单视图:
− 数据仅来自一个表
− 不包含函数或数据分组
− 能通过视图执行 DML 操作
复杂视图:
− 数据来自多个表
− 包含函数或数据分组
− 不允许通过视图进行 DML 操作
简单视图:

创建复杂视图:

视图中 DML 操作的执行规则
如果视图中包含下面的部分就不能修改数据:
• 组函数
• GROUP BY 子句
• DISTINCT 关键字
• 用表达式定义的列
内建视图
什么内建视图 :就是将查询结果作为另一个查询的表
• 内建视图是一个带有别名 (或相关名) 的可以在 SQL 语句中使用的子查询。
• 一个主查询的在 FROM 子句中指定的子查询就是一个内建视图。
内建视图:内建视图由位于 FROM 子句中命名了别名的子查询创建。该子查询定义一个可以在主查询中引用数据源。
Oracle 的分页查询
什么是分页查询
当查询的结果集数据量过大时,可能会导致各种各样的问题发生,例如:服务器资源被耗尽,因数据传输量过大而使处理超时,等等。最终都会导致查询无法完成。解决这个问题的一个策略就是“分页查询”,也就是说不要一次性查询所有的数据,每次只查询一部分数据。这样分批次地进行处理,可以呈现出很好的用户体验,对服务器资源的消耗也不大。
分页查询原则:
在内建视图中通过 rownum 伪劣值的判断来指定获取数据的数量。
什么是 ROWID
ROWID 是由 Oracle 自动加在表中每行最后的一列伪列,既然是伪列,就说明表中并不会物理存储 ROWID 的值。你可以像使用其它列一样使用它,只是不能对该列的值进行增、删、改操作。一旦一行数据插入后,则其对应的 ROWID 在该行的生命周期内是唯一的,即使发生行迁移,该行的 ROWID 值也不变。
ROWNUM 表示查询某条记录在整个结果集中的位置, 同一条记录查询条件不同对应的 rownum 是不同的而 ROWID是不会变的
--分页查询第一页数据;前三条rownum:[1,3] select t.* from (select e.ename,e.job,e.sal,rownum r from emp e where rownum<=3) t where t.r>0 and t.r<=3; --分页查询第二页数据,去掉第一页展示的数据再展示前三条;rownum:[3,6] select t.* from (select e.ename,e.job,e.sal,rownum r from emp e where rownum<=6) t where t.r>3 and t.r<=6; --分页查询第三页数据,去掉第二页展示的数据再展示前三条;rownum:[6,9] select t.* from (select e.ename,e.job,e.sal,rownum r from emp e where rownum<=9) t where t.r>6 and t.r<=9;
序列(Sequence)
什么是序列
序列是用户创建的数据库对象,序列会产生唯一的整数。序列的一个典型的用途是创建一个主键的值,它对于每一行必须是唯一的。序列由一个 Oracle 内部程序产生并增加或减少。
序列是一个节省时间的对象,因为它可以减少应用程序中产生序列程序的代码量。序列号独立于表被存储和产生,因此,相同的序列可以被多个表使用。
创建序列
通过 DDL 语句创建序列
通过工具创建序列
查询序列
使用序列
NEXTVAL 和 CURRVAL 伪列
• NEXTVAL 返回下一个可用的序列值,它每次返回一个唯一的被引用值,即使对于不同的用户也是如此
• CURRVAL 获得当前的序列值
• 在 CURRVAL 获得一个值以前,NEXTVAL 对该序列必须发布
索引(Index)
什么是索引
在关系型数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引提供对表中行的直接和快速访问,它的目的是用已索引的路径快速定位数据以减少磁盘 I/O。索引由 Oracle 服务器自动使用和维护,索引逻辑地和物理地独立于他们索引的表,这意味者索引可以在任何时候被创建或删除,并且不影响基表或其它的索引。当删除表时,相应的索引也被删除。
索引的类型
唯一性索引:当你在一个表中定义一个列为主键,或者定义一个唯一键约束时 Oracle服务器自动创建该索引,索引的名字习惯上是约束的名字。
非唯一索引:由用户创建,例如,可以创建一个 FOREIGN KEY 列索引用于一个查询中的连接来改进数据取回的速度。
创建索引的方式
• 自动:在一个表的定义中,当定义一个 PRIMARY KEY 或 UNIQUE 约束时,一个唯一索引被自动创建
• 手动:用户能够在列上创建非唯一的索引来加速对行的访问。
什么时候创建索引
• 一个列包含一个大范围的值
• 一个列包含很多的空值
• 一个或多个列经常同时在一个 WHERE 子句中或一个连接条件中被使用
• 表很大,并且经常的查询期望取回少于百分之 2 到 4 的行。
3.4.2什么时候不创建索引
• 表很小
• 不经常在查询中作为条件被使用的列
• 大多数查询期望取回多于表中百分之 2 到 4 的行
• 表经常被更新
• 被索引的列作为表达式的的一部分被引用