一、概述
本章使用的是JDK8。
阅读本章请先了解HashMap的实现原理【Java】HashMap 的实现原理
1.1 ConcurrentHashMap跟HashMap,HashTable的对比
1. HashMap不是线程安全:
在并发环境下,可能会形成环状链表(扩容时可能造成,具体原因自行百度google或查看源码分析),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的,实现原理参考:【Java】HashMap 的实现原理
2. HashTable是线程安全的:
HashTable和HashMap的实现原理几乎一样,
差别:
- 1.HashTable不允许key和value为null;
- 2.HashTable是线程安全的。
HashTable线程安全的策略实现代价却比较大,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞
3. ConcurrentHashMap是线程安全的:
直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,并发控制使用Synchronized和CAS来操作,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这 样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的"分段锁"思想
二、结构图
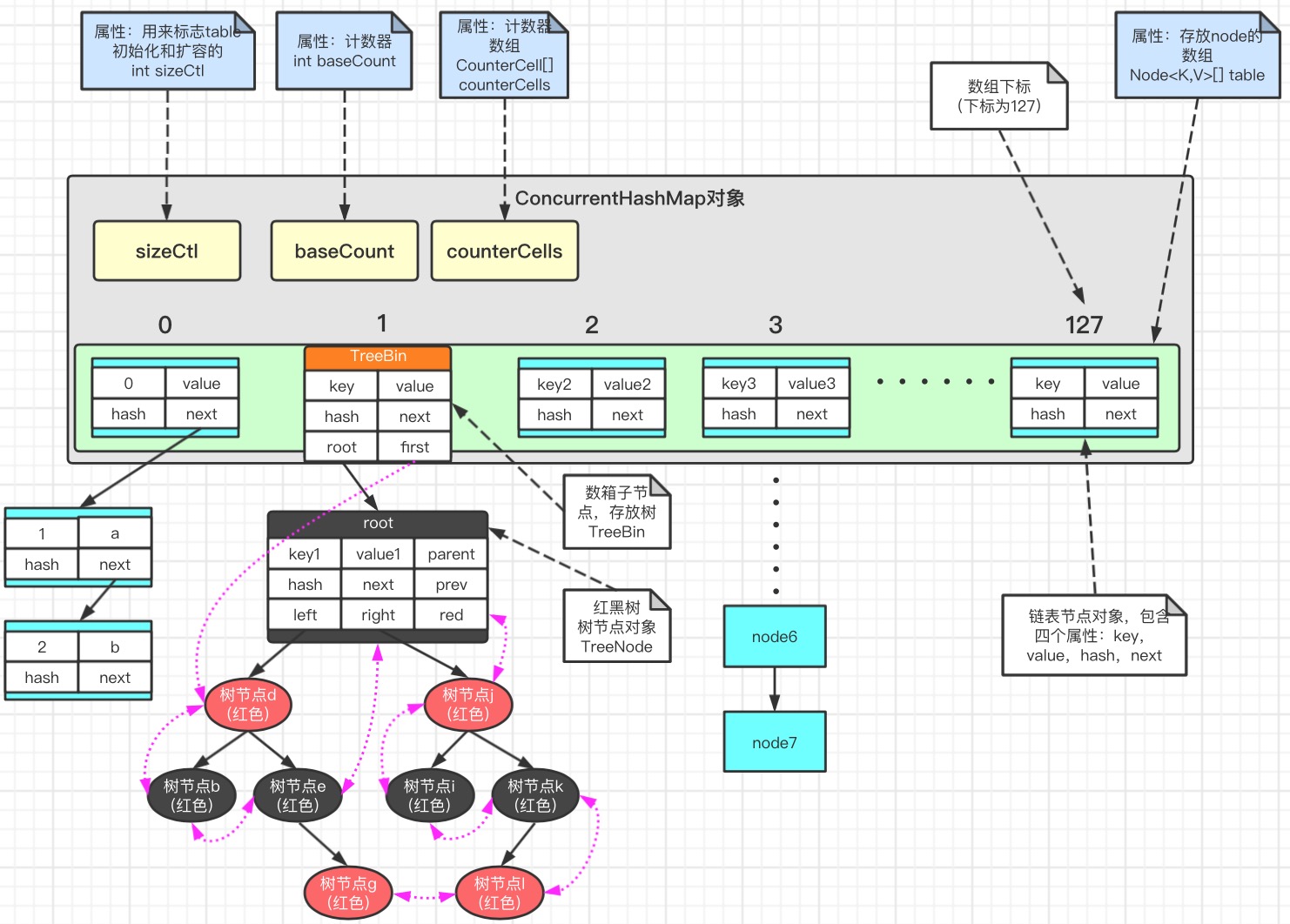
由图可以看出,ConcurrentHashMap的结构是:数组 + 链表 + 红黑树
三、属性
1 // node数组最大容量:2^30=1073741824 2 private static final int MAXIMUM_CAPACITY = 1 << 30; 3 4 // 默认初始值,必须是2的幕数 5 private static final int DEFAULT_CAPACITY = 16; 6 7 //数组可能最大值,需要与toArray()相关方法关联 8 static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; 9 10 //并发级别,遗留下来的,为兼容以前的版本 11 private static final int DEFAULT_CONCURRENCY_LEVEL = 16; 12 13 // 负载因子 14 private static final float LOAD_FACTOR = 0.75f; 15 16 // 链表转红黑树阀值,> 8 链表转换为红黑树 17 static final int TREEIFY_THRESHOLD = 8; 18 19 // 链表转红黑树时,最小容量阀值, >= 64 链表转换为红黑树 20 static final int MIN_TREEIFY_CAPACITY = 64; 21 22 // 树转链表阀值,小于等于6(tranfer时,lc、hc=0两个计数器分别++记录原bin、新binTreeNode数量,<=UNTREEIFY_THRESHOLD 则untreeify(lo)) 23 static final int UNTREEIFY_THRESHOLD = 6; 24 25 // 最小转移数组步长 26 private static final int MIN_TRANSFER_STRIDE = 16; 27 28 // 可以帮助调整大小的最大线程数,计算用到 29 private static int RESIZE_STAMP_BITS = 16; 30 31 // 2^15-1,help resize的最大线程数 32 private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; 33 34 // 32-16=16,sizeCtl中记录size大小的偏移量 35 private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; 36 37 // forwarding nodes的hash值 38 static final int MOVED = -1; 39 // 树根节点的hash值 40 static final int TREEBIN = -2; 41 // ReservationNode的hash值 42 static final int RESERVED = -3; 43 44 // 可用处理器数量 45 static final int NCPU = Runtime.getRuntime().availableProcessors(); 46 47 // 存放node的数组 48 transient volatile Node<K,V>[] table; 49 50 // 控制标识符,用来控制table的初始化和扩容的操作,不同的值有不同的含义 51 // 当为0时:代表当时的table还没有被初始化 52 // 当为负数时:-1代表正在初始化 53 // 小于-1时:实际值为resizeStamp(n) <<RESIZE_STAMP_SHIFT+2, 表明table正在扩容 54 // 当为正数时:未初始化,代表初始化大小,初始化完成后, 代表下一次扩容时的阀值, 默认为0.75*n 55 private transient volatile int sizeCtl; 56 57 // table容量从n扩到2n时, 是从索引n->1的元素开始迁移, transferIndex代表当前已经迁移的元素下标 58 private transient volatile int transferIndex; 59 60 // 基础计算器值 61 private transient volatile long baseCount; 62 63 // 计数器数组 64 private transient volatile CounterCell[] counterCells;
下面是 Node 类的定义,它是 HashMap 中的一个静态内部类,哈希表中的每一个 节点都是 Node 类型。我们可以看到,Node 类中有 4 个属性,其中除了 key 和 value 之外,还有 hash 和 next 两个属性。hash 是用来存储 key 的哈希值的,next 是在构建链表时用来指向后继节点的
1 static class Node<K,V> implements Map.Entry<K,V> { 2 final int hash; 3 final K key; 4 volatile V val; 5 volatile Node<K,V> next; 6 7 Node(int hash, K key, V val, Node<K,V> next) { 8 this.hash = hash; 9 this.key = key; 10 this.val = val; 11 this.next = next; 12 } 13 14 ...... 15 }
树节点TreeNode


1 static final class TreeNode<K,V> extends Node<K,V> { 2 TreeNode<K,V> parent; // red-black tree links 3 TreeNode<K,V> left; 4 TreeNode<K,V> right; 5 TreeNode<K,V> prev; // needed to unlink next upon deletion 6 boolean red; 7 8 9 ...... 10 }
树箱子节点TreeBin
1 static final class TreeBin<K,V> extends Node<K,V> { 2 TreeNode<K,V> root; 3 volatile TreeNode<K,V> first; 4 volatile Thread waiter; 5 volatile int lockState; 6 // values for lockState 7 static final int WRITER = 1; // set while holding write lock 8 static final int WAITER = 2; // set when waiting for write lock 9 static final int READER = 4; // increment value for setting read lock 10 11 12 ...... 13 }
四、方法
1、构造方法
ConcurrentHashMap 提供了五种方式的构造器,但是都为初始化数组,如下:
// 创建一个空的哈希表 public ConcurrentHashMap() { } // 创建一个空的哈希表,指定初始容量 public ConcurrentHashMap(int initialCapacity) { if (initialCapacity < 0) throw new IllegalArgumentException(); int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); this.sizeCtl = cap; } // 创建一个新哈希表,将map的元素放入其中 public ConcurrentHashMap(Map<? extends K, ? extends V> m) { this.sizeCtl = DEFAULT_CAPACITY; putAll(m); } // 创建一个新哈希表,指定初始容量、加载因子; public ConcurrentHashMap(int initialCapacity, float loadFactor) { this(initialCapacity, loadFactor, 1); } // 创建一个新哈希表,指定初始容量、加载因子、并发级别 public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (initialCapacity < concurrencyLevel) // Use at least as many bins initialCapacity = concurrencyLevel; // as estimated threads long size = (long)(1.0 + (long)initialCapacity / loadFactor); int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size); this.sizeCtl = cap; }
2、put 方法
1 public V put(K key, V value) { 2 return putVal(key, value, false); 3 } 4 5 /** Implementation for put and putIfAbsent */ 6 final V putVal(K key, V value, boolean onlyIfAbsent) { 7 if (key == null || value == null) throw new NullPointerException(); 8 int hash = spread(key.hashCode()); 9 // binCount: i处结点数量, 10 // 或者TreeBin或链表结点数, 其它:链表结点数。主要用于每次加入结点后查看是否要由链表转为红黑树 11 int binCount = 0; 12 //CAS经典写法,不成功无限重试,让再次进行循环进行相应操作 13 for (Node<K,V>[] tab = table;;) { 14 Node<K,V> f; int n, i, fh; 15 // 除非构造时指定初始化集合,否则默认构造不初始化table,所以需要在添加时元素检查是否需要初始化。 16 if (tab == null || (n = tab.length) == 0) 17 // 初始化集合 18 tab = initTable(); 19 // table[i] 对应桶无元素 20 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { 21 // CAS操作得到对应table中元素 22 if (casTabAt(tab, i, null, 23 new Node<K,V>(hash, key, value, null))) 24 break; // no lock when adding to empty bin 25 } 26 // table[i]对应桶上节点 hash值 为MOVEN 表示集合正在扩容 27 else if ((fh = f.hash) == MOVED) 28 // 本线程去帮助集合扩容 29 tab = helpTransfer(tab, f); 30 else { 31 V oldVal = null; 32 // 给 table[i] 对应桶元素加锁,其他线程无法操作此桶中元素 33 synchronized (f) { 34 // 再次判断是否table[i]被改变 35 if (tabAt(tab, i) == f) { 36 // fh >= 0 表明是链表结点类型 37 // 节点hash值是大于等于0的,即spread()方法计算而来, 38 // 扩容时已迁移hash值为 -1 39 // 如果是TreeBin树节点hash值为 -2 40 // ReservationNode的hash值 -3 41 if (fh >= 0) { 42 binCount = 1; 43 for (Node<K,V> e = f;; ++binCount) { 44 K ek; 45 // 找到相等key值的节点 46 if (e.hash == hash && 47 ((ek = e.key) == key || 48 (ek != null && key.equals(ek)))) { 49 oldVal = e.val; 50 // onlyIfAbsent表示是新元素才加入,旧值不替换,默认为fase。 51 if (!onlyIfAbsent) 52 e.val = value; 53 break; 54 } 55 Node<K,V> pred = e; 56 // 链表最后,未找到节点,加入链表尾 57 // jdk1.8版本是把新结点加入链表尾部,next由volatile修饰 58 if ((e = e.next) == null) { 59 pred.next = new Node<K,V>(hash, key, 60 value, null); 61 break; 62 } 63 } 64 } 65 // 红黑树结点类型 66 else if (f instanceof TreeBin) { 67 Node<K,V> p; 68 binCount = 2; 69 // 节点加入红黑树 70 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, 71 value)) != null) { 72 oldVal = p.val; 73 if (!onlyIfAbsent) 74 p.val = value; 75 } 76 } 77 } 78 } 79 if (binCount != 0) { 80 // 判断binCount是否大于等于8,即链表上节点树大于8,为大于等于9 81 if (binCount >= TREEIFY_THRESHOLD) 82 treeifyBin(tab, i); 83 if (oldVal != null) 84 return oldVal; 85 break; 86 } 87 } 88 } 89 // 集合大大小+1,即size+1 90 addCount(1L, binCount); 91 return null; 92 }
put 方法比较复杂,实现步骤大致如下:
1、先通过 hash 值计算出 key 映射到哪个桶。
2、如果桶上没有碰撞冲突,则直接CAS操作插入。
3、如果出现碰撞冲突了,则需要处理冲突:
(1) 如果该桶hash 值表示数组正在扩容,本线程去帮助集合扩容,扩容完成然后在重新插入
(2) 否则去获取锁,synchronized (table[i]),进入插入操作,然后解锁
- 如果该桶时采用传统的链式,从链表尾插入链表。如果链的长度到达临界值,则把链转变为红黑树
- 如果时使用红黑树处理冲突,则调用红黑树的方法插入。
4、如果桶中存在重复的键,则为该键替换新值。
5、添加记数值,如果集合大小大于等于阈值,则进行扩容。
3、initTable() 初始化表方法
1 private final Node<K,V>[] initTable() { 2 Node<K,V>[] tab; int sc; 3 while ((tab = table) == null || tab.length == 0) { 4 if ((sc = sizeCtl) < 0) 5 Thread.yield(); // lost initialization race; just spin 6 // 正在初始化时将sizeCtl设为-1 7 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { 8 try { 9 if ((tab = table) == null || tab.length == 0) { 10 int n = (sc > 0) ? sc : DEFAULT_CAPACITY; 11 // 创建节点数组 12 @SuppressWarnings("unchecked") 13 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; 14 table = tab = nt; 15 // 扩容阈值为新容量的0.75倍 16 sc = n - (n >>> 2); 17 } 18 } finally { 19 sizeCtl = sc; 20 } 21 break; 22 } 23 } 24 return tab; 25 }
4、addCount() 方法
1 // x 新添加的元素数量 2 // check 往往传入某个位置哈希桶的链表或者红黑树数量 3 // x为1表示添加一个新元素,-1表示删除 4 // x = 1,check = 0 5 // 添加计算数量 6 private final void addCount(long x, int check) { 7 CounterCell[] as; long b, s; 8 9 // 程序第一次counterCells必然为空 (as = counterCells) != null 为false 10 // !U.compareAndSwapLong(this...) cas 方式增加baseCount数量 11 // 在没有竞争的情况下修改完baseCount返回函数 12 13 // 存在竞争情况,条件满足,进入方法体 14 if ((as = counterCells) != null || 15 !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { 16 CounterCell a; long v; int m; 17 18 19 boolean uncontended = true; 20 // as 为null 所以直接进入方法体 21 22 //if 作用1:如果当前as为空证明多线程导致baseCount赋值失败,所以需要初始化一个counterCells数组进行统计 23 //if 作用2:如果当前as不为空,且当前线程对应as数组存储的对象不为空,那么直接用实例对象存储的数值加上当前插入的数据累加和即可 24 //if 作用3:如果当前as不为空,但是对应线程数组下标实例为空,那么调用fullAddCount构造一个实例再放入新加入的元素个数 25 if (as == null || (m = as.length - 1) < 0 || 26 (a = as[ThreadLocalRandom.getProbe() & m]) == null || 27 !(uncontended = 28 U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { 29 // 方法体比较简单就是直接调用 fullAddCount 30 fullAddCount(x, uncontended); 31 // 返回 32 return; 33 } 34 // 上面if条件不满足,表示已经数值添加到baseCount 和 counterCells 数组中 35 // 很少情况check传入小于1,如果传入了那么证明不需要检查扩容,直接返回就好 36 if (check <= 1) 37 return; 38 // sumcount返回当前ConcurrentHashMap数量 39 // 即 baseCount 加 counterCells 数组的 数值之和 40 s = sumCount(); 41 } 42 // check >= 0进行扩容逻辑 43 if (check >= 0) { 44 Node<K,V>[] tab, nt; int n, sc; 45 // s表示 存储元素数量(表的大小) 46 // s >= (long)(sc = sizeCtl) 当前表的存储元素数量必须大于等于阈值 47 // (tab = table) != null 数组不为空 48 // (n = tab.length) < MAXIMUM_CAPACITY 数组容量当前小于最大扩容上限 49 while (s >= (long)(sc = sizeCtl) && (tab = table) != null && 50 (n = tab.length) < MAXIMUM_CAPACITY) { 51 52 //resizeStamp返回的rs低15位表示当前容量n扩容标识,用于表示是对n的扩容。(在数值不直接表示,而是表示n前面最高位为1前面有多少个0) 53 //resizeStamp返回的rs的从低位开始数的第16位一定为1(比如说0000 0000 0000 0000 1000 0000 0000 0000) 54 //resizeStamp具体看引用文章[3] 55 // 第一次n= 16,rs = 0000 0000 0000 0000 1000 0000 0001 1011 56 int rs = resizeStamp(n); 57 // 哈希表正在扩容 58 if (sc < 0) { 59 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || 60 sc == rs + MAX_RESIZERS || (nt = nextTable) == null || 61 transferIndex <= 0) 62 break; 63 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) 64 transfer(tab, nt); 65 } 66 // 哈希表未扩容 67 // sizeCtl 设置值 68 // 第一次扩容设置值 sizeCtl = 1000 0000 0001 1011 0000 0000 0000 0010(二进制) 69 // 高15位:容量n扩容标识 70 // 低16位:并行扩容线程数+1 71 else if (U.compareAndSwapInt(this, SIZECTL, sc, 72 (rs << RESIZE_STAMP_SHIFT) + 2)) 73 74 // 转移扩容 75 transfer(tab, null); 76 77 // s即 baseCount 加 counterCells 数组的 数值之和 78 s = sumCount(); 79 } 80 } 81 }
addCount 方法比较复杂,实现步骤大致如下:
1、添加计数值
(1) 将数值根据线程特有值,添加到counterCells 计数数组 对应的值中
(2) 如果失败或冲突,调用fullAddCount() 添加计数
2、进行扩容
(1) 判断是否hash表正在扩容,如果是帮组哈希表扩容
(2) 如果不是,去调用transfer() 方法扩容
关于resizeStamp():可以百度,或参考 https://blog.csdn.net/tp7309/article/details/76532366
累加方案可以参考:线程最快累加方案(二十三)
5、fulladdCount 方法
1 // x = 1,wasUncontended = false 2 // 添加计算数量,到baseCount 和 counterCells 数组中 3 private final void fullAddCount(long x, boolean wasUncontended) { 4 int h;// 线程指针哈希 5 if ((h = ThreadLocalRandom.getProbe()) == 0) { 6 ThreadLocalRandom.localInit(); // force initialization 7 h = ThreadLocalRandom.getProbe(); // 线程指针哈希 8 wasUncontended = true; // 无竞争 9 } 10 11 // 碰撞 12 boolean collide = false; // True if last slot nonempty 13 for (;;) { 14 15 16 CounterCell[] as; CounterCell a; int n; long v; 17 // as 不为空 & 18 // 初始化counterCells数组完成情况 19 if ((as = counterCells) != null && (n = as.length) > 0) { 20 // as[(n - 1) & h] 利用线程指针哈希计算在counterCells的数组位置。 21 // 如果当前位置为没有构造过CounterCell,那么近进入然后构造一个 22 if ((a = as[(n - 1) & h]) == null) { 23 // cellsBusy == 0 表示: 24 // 没有正在进行扩容CounterCell数组或者初始化CounterCell,或者正在插入新节点 25 if (cellsBusy == 0) { // Try to attach new Cell 26 // 创建一个计算单元格 27 CounterCell r = new CounterCell(x); // Optimistic create 28 // CAS设置标志位cellsBusy 29 if (cellsBusy == 0 && 30 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { 31 32 boolean created = false; 33 try { // Recheck under lock 34 // 再次检查是否符合条件,符合就创建放入然后break结束当前函数 35 CounterCell[] rs; int m, j; 36 if ((rs = counterCells) != null && 37 (m = rs.length) > 0 && 38 rs[j = (m - 1) & h] == null) { 39 rs[j] = r; 40 created = true; 41 } 42 } finally { 43 // 释放cellsBusy 修改值为 0 44 cellsBusy = 0; 45 } 46 if (created) 47 // 创建成功,结束循环,否则继续循环 48 break; 49 continue; 50 // Slot is now non-empty 51 } 52 } 53 // 有其他线程在操作 cellsBusy == 1的情况 54 collide = false; 55 } 56 // as[(n - 1) & h] 不为空,表示存在竞争 57 else if (!wasUncontended) // CAS already known to fail 58 // 修改竞争变量 59 wasUncontended = true; // Continue after rehash 60 61 // 如果当前线程对应CounterCell数组下标存在对应的实例, 62 // 那么直接用该实例的 value 相加即可 63 else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) 64 // value 相加成功 65 // 结束循环 66 break; 67 // counterCells数组已经更新 68 else if (counterCells != as || n >= NCPU) 69 collide = false; // At max size or stale 70 71 // 当前线程插入时,因为其他某种原因失败失败,重置标志重来 72 else if (!collide) 73 collide = true; 74 75 // 无人进行扩容CounterCell数组,获取CELLSBUSY 使用权 76 else if (cellsBusy == 0 && 77 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { 78 // 除了当前表被更新以外的其他原因来到这里那么进行扩容数组。 79 try { 80 // 这里扩容是由于哈希碰撞以上的else if 都没有解决 81 // 所以doug lea 再次扩容降低 并发所带来的自旋次数 82 if (counterCells == as) {// Expand table unless stale 83 // 新建一个是原计数器单元格表数组 2倍 的数组 84 CounterCell[] rs = new CounterCell[n << 1]; 85 // 复制原数组元素到新数组 86 for (int i = 0; i < n; ++i) 87 rs[i] = as[i]; 88 // 将新数组赋值给属性counterCells 89 counterCells = rs; 90 } 91 } finally { 92 // 释放cellsBusy 93 cellsBusy = 0; 94 } 95 // 碰撞标识设为false 96 collide = false; 97 continue; // Retry with expanded table 98 } 99 // 更新线程指针哈希,相当于换个位置插入值 100 h = ThreadLocalRandom.advanceProbe(h); 101 } 102 // 初始化counterCells数组 103 // 如果counterCells为空 那么进行初始化counterCells数组 104 // cellsBusy == 0标识 当前表没有在扩容操作等 105 // counterCells == as 防止多线程 已经修改counterCells 106 // U.compareAndSwapInt(this, CELLSBUSY, 0, 1) 标识正在对counterCells扩容或初始化 107 // 修改cellsBusy 的值为 1 108 else if (cellsBusy == 0 && counterCells == as && 109 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { 110 boolean init = false; 111 try { // Initialize table 112 113 if (counterCells == as) { 114 // 新建一个长度为2的计数器单元格表数组 115 CounterCell[] rs = new CounterCell[2]; 116 // 1 与 线程指针哈希 计算,得到 0 或 1 117 // h是线程的一个序列值,可以简单理解为线程特有的一个线程指针哈希 118 // 当前线程得到一个特定位置的CounterCell[] rs下标然后放置添加元素数量 119 rs[h & 1] = new CounterCell(x); 120 // 将新计数器单元格表数组 赋值给 counterCells 121 counterCells = rs; 122 // 初始化 完成 123 init = true; 124 } 125 } finally { 126 // 修改cellsBusy 的值为 0 127 cellsBusy = 0; 128 } 129 if (init) 130 // 结束循环 131 break; 132 } 133 // 修改 baseCount 的值 +1 134 else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x)) 135 break; // Fall back on using base 136 } 137 }
6、transfer() 方法
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { int n = tab.length, stride; // 每个线程处理桶的最小数目,可以看出核数越高步长越小,最小16个。 if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // subdivide range // 如果新数组参数为空,去创建数组 if (nextTab == null) { try { //扩容到2倍 @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; nextTab = nt; } catch (Throwable ex) { // try to cope with OOME //扩容保护 sizeCtl = Integer.MAX_VALUE; return; } // 给属性nextTable 赋值 nextTable = nextTab; // 扩容总进度,>=transferIndex的桶都已分配出去。 transferIndex = n; } // 新数组长度 int nextn = nextTab.length; // 扩容时的特殊节点,扩容期间的元素查找要调用其find()方法在nextTable中查找元素。 ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); // 当前线程是否需要继续寻找下一个可处理的节点 boolean advance = true; // 所有桶是否都已迁移完成。 boolean finishing = false; // i从0开始循环旧数组------- for (int i = 0, bound = 0;;) { Node<K,V> f; int fh; // 此循环的作用是确定当前线程要迁移的桶的范围或通过更新i的值确定当前范围内下一个要处理的节点。 while (advance) { int nextIndex, nextBound; // 每次循环都检查结束条件 if (--i >= bound || finishing) advance = false; // 迁移总进度<=0,表示所有桶都已迁移完成 // nextIndex 初始值为 tab.length else if ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } // CAS修改 transferIndex // transferIndex减去已分配出去的桶 else if (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { // 确定当前线程每次分配的待迁移桶的范围为[bound, nextIndex) // 从尾部开始分配移动范围 ,比如 n = 16,步长stride 是 8 // 第一次的移桶范围就是 [8,16) bound = nextBound; // bound 8 i = nextIndex - 1; // 15 advance = false; } } // 当前线程自己的活已经做完或所有线程的活都已做完, // 第二与第三个条件应该是下面让"i = n"后,再次进入循环时要做的边界检查。 if (i < 0 || i >= n || i + n >= nextn) { int sc; //所有线程已干完活,最后才走这里。 if (finishing) { // 给属性nextTable 清空值 nextTable = null; // 替换新table table = nextTab; // 调sizeCtl为新容量0.75倍。 sizeCtl = (n << 1) - (n >>> 1); return; } //当前线程已结束扩容,sizeCtl-1表示参与扩容线程数-1。 if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { //还记得addCount()处给sizeCtl赋的初值吗?相等时说明没有线程在参与扩容了, // 置finishing=advance=true,为保险让i=n再检查一次。 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; finishing = advance = true; i = n; // recheck before commit } } // f指向 tab[i] else if ((f = tabAt(tab, i)) == null) // 如果i处是ForwardingNode表示第i个桶已经有线程在负责迁移了。 advance = casTabAt(tab, i, null, fwd); else if ((fh = f.hash) == MOVED) advance = true; // already processed else { synchronized (f) { //桶内元素迁移需要加锁。 if (tabAt(tab, i) == f) { Node<K,V> ln, hn; if (fh >= 0) { //>=0表示是链表结点 // 由于n是2的幂次方(所有二进制位中只有一个1), // 如 n=16(0001 0000), // 因为节点在同一个桶中,因为(n - 1) & hash),值是相同的,即二进制后面4位相同 // 第5位为1,那么(hash & 16) 后的值第5位只能为0或1。所以可以根据hash&n的结果将所有结点分为两部分。 int runBit = fh & n; // f指向 tab[i] Node<K,V> lastRun = f; // 循环查找 // 找出最后一段完整的fh&n不变的链表,这样最后这一段链表就不用重新创建新结点了。 for (Node<K,V> p = f.next; p != null; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } } if (runBit == 0) { ln = lastRun; hn = null; } else { hn = lastRun; ln = null; } //lastRun之前的结点因为 fh&n 不确定,所以全部需要重新迁移。 for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); } // 低位链表放在i处 setTabAt(nextTab, i, ln); // 高位链表放在i+n处 setTabAt(nextTab, i + n, hn); // 在原table中设置ForwardingNode节点以提示该桶扩容完成。 setTabAt(tab, i, fwd); advance = true; } else if (f instanceof TreeBin) { //红黑树处理。 ...
transfer 方法,实现步骤大致如下:
1、计算单线程扩容是,处理桶的数量,即步长,最小值为16
2、创建新数组,数组长度是原来的2倍
3、从table数组后面开始分配,一步步长数量的同,交由当前线程进行扩容处理
(1) 如果table[i]是链表节点,将链表拆开成高位与低位,2个链表,处理放到新数组中
(2) 如果table[i]是树节点,将链表拆开成高位与低位,2个链表
- 链表数量小于等于6,转换成链表节点,放到新数组中
- 链表数量大于6,处理成黑红树,挂在TreeNode节点下,放到数组中
注:加载因子,固定是0.75,由大量研究试验所得经验,不能改变
并发扩容总结
-
单线程新建nextTable,新容量一般为原table容量的两倍。
-
每个线程想增/删元素时,如果访问的桶是ForwardingNode节点,则表明当前正处于扩容状态,协助一起扩容完成后再完成相应的数据更改操作。
-
扩容时将原table的所有桶倒序分配,每个线程每次最小分配16个桶,防止资源竞争导致的效率下降。单个桶内元素的迁移是加锁的,但桶范围处理分配可以多线程,在没有迁移完成所有桶之前每个线程需要重复获取迁移桶范围,直至所有桶迁移完成。
-
一个旧桶内的数据迁移完成但不是所有桶都迁移完成时,查询数据委托给ForwardingNode结点查询nextTable完成(可以find()方法)。
-
迁移过程中sizeCtl用于记录参与扩容线程的数量,全部迁移完成后sizeCtl更新为新table容量的0.75倍。
7、helpTransfer() 方法
1 final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { 2 Node<K,V>[] nextTab; int sc; 3 // 根据节点类型是否正在扩容 4 if (tab != null && (f instanceof ForwardingNode) && 5 (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) { 6 int rs = resizeStamp(tab.length); 7 while (nextTab == nextTable && table == tab && 8 (sc = sizeCtl) < 0) { 9 // 计算,判断扩容是否结束 10 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || 11 sc == rs + MAX_RESIZERS || transferIndex <= 0) 12 break; 13 // CAS修改sizeCtl,线程数+1,帮忙扩容 14 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) { 15 transfer(tab, nextTab); 16 break; 17 } 18 } 19 return nextTab; 20 } 21 return table; 22 }
8、gei() 方法
1 public V get(Object key) { 2 Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; 3 // 获取hash 值 4 int h = spread(key.hashCode()); 5 // 判断table 与 对应table[i] 是否为空 6 if ((tab = table) != null && (n = tab.length) > 0 && 7 (e = tabAt(tab, (n - 1) & h)) != null) { 8 // 判断hash值是否相等 9 if ((eh = e.hash) == h) { 10 if ((ek = e.key) == key || (ek != null && key.equals(ek))) 11 return e.val; 12 } 13 // 判断是否在扩容 14 else if (eh < 0) 15 return (p = e.find(h, key)) != null ? p.val : null; 16 // 循环查找链表(红黑树中也存在链表) 17 while ((e = e.next) != null) { 18 if (e.hash == h && 19 ((ek = e.key) == key || (ek != null && key.equals(ek)))) 20 return e.val; 21 } 22 } 23 return null; 24 }
get实现步骤大致如下:
1、通过 hash 值获取该 key 映射到的桶。
2、桶上的 key 就是要查找的 key,则直接命中。
3、桶上的 hash 表示正在扩容,则帮哈希表扩容。
4、桶上的 key 不是要查找的 key,则查看后续节点,通过循环遍历链查找该 key
9、remove() 方法
1 public V remove(Object key) { 2 return replaceNode(key, null, null); 3 } 4 5 6 final V replaceNode(Object key, V value, Object cv) { 7 int hash = spread(key.hashCode()); 8 for (Node<K,V>[] tab = table;;) { 9 Node<K,V> f; int n, i, fh; 10 // 判断table 和 hash对应的table[i] 是否为空 11 if (tab == null || (n = tab.length) == 0 || 12 (f = tabAt(tab, i = (n - 1) & hash)) == null) 13 break; 14 // 判断哈希表是否正在扩容 15 else if ((fh = f.hash) == MOVED) 16 tab = helpTransfer(tab, f); 17 else { 18 V oldVal = null; 19 boolean validated = false; 20 // 获取锁 21 synchronized (f) { 22 if (tabAt(tab, i) == f) { 23 // fh>=0,表示节点所在的是链表 24 if (fh >= 0) { 25 validated = true; 26 // 遍历链表,查找对应的key,value 27 for (Node<K,V> e = f, pred = null;;) { 28 K ek; 29 if (e.hash == hash && 30 ((ek = e.key) == key || 31 (ek != null && key.equals(ek)))) { 32 V ev = e.val; 33 if (cv == null || cv == ev || 34 (ev != null && cv.equals(ev))) { 35 oldVal = ev; 36 if (value != null) 37 e.val = value; 38 else if (pred != null) 39 pred.next = e.next; 40 else 41 setTabAt(tab, i, e.next); 42 } 43 break; 44 } 45 pred = e; 46 if ((e = e.next) == null) 47 break; 48 } 49 } 50 // 判断是否是树节点 51 else if (f instanceof TreeBin) { 52 validated = true; 53 TreeBin<K,V> t = (TreeBin<K,V>)f; 54 TreeNode<K,V> r, p; 55 // 根据root节点去查找 56 if ((r = t.root) != null && 57 (p = r.findTreeNode(hash, key, null)) != null) { 58 V pv = p.val; 59 if (cv == null || cv == pv || 60 (pv != null && cv.equals(pv))) { 61 oldVal = pv; 62 if (value != null) 63 p.val = value; 64 // 移除树上的节点 65 else if (t.removeTreeNode(p)) 66 // 返回真,表示树节点太少,将其转换成链表 67 setTabAt(tab, i, untreeify(t.first)); 68 } 69 } 70 } 71 } 72 } 73 if (validated) { 74 if (oldVal != null) { 75 if (value == null) 76 // 计数减1 77 addCount(-1L, -1); 78 return oldVal; 79 } 80 break; 81 } 82 } 83 } 84 return null; 85 }
10、size() 方法
1 public int size() { 2 // 统计元素数量 3 long n = sumCount(); 4 return ((n < 0L) ? 0 : 5 (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : 6 (int)n); 7 } 8 9 final long sumCount() { 10 CounterCell[] as = counterCells; CounterCell a; 11 // 基本计数器 12 long sum = baseCount; 13 if (as != null) { 14 // 循环遍历 计数器数组,累加 15 for (int i = 0; i < as.length; ++i) { 16 if ((a = as[i]) != null) 17 sum += a.value; 18 } 19 } 20 return sum; 21 }
五、ConcurrentHashMap源码分析
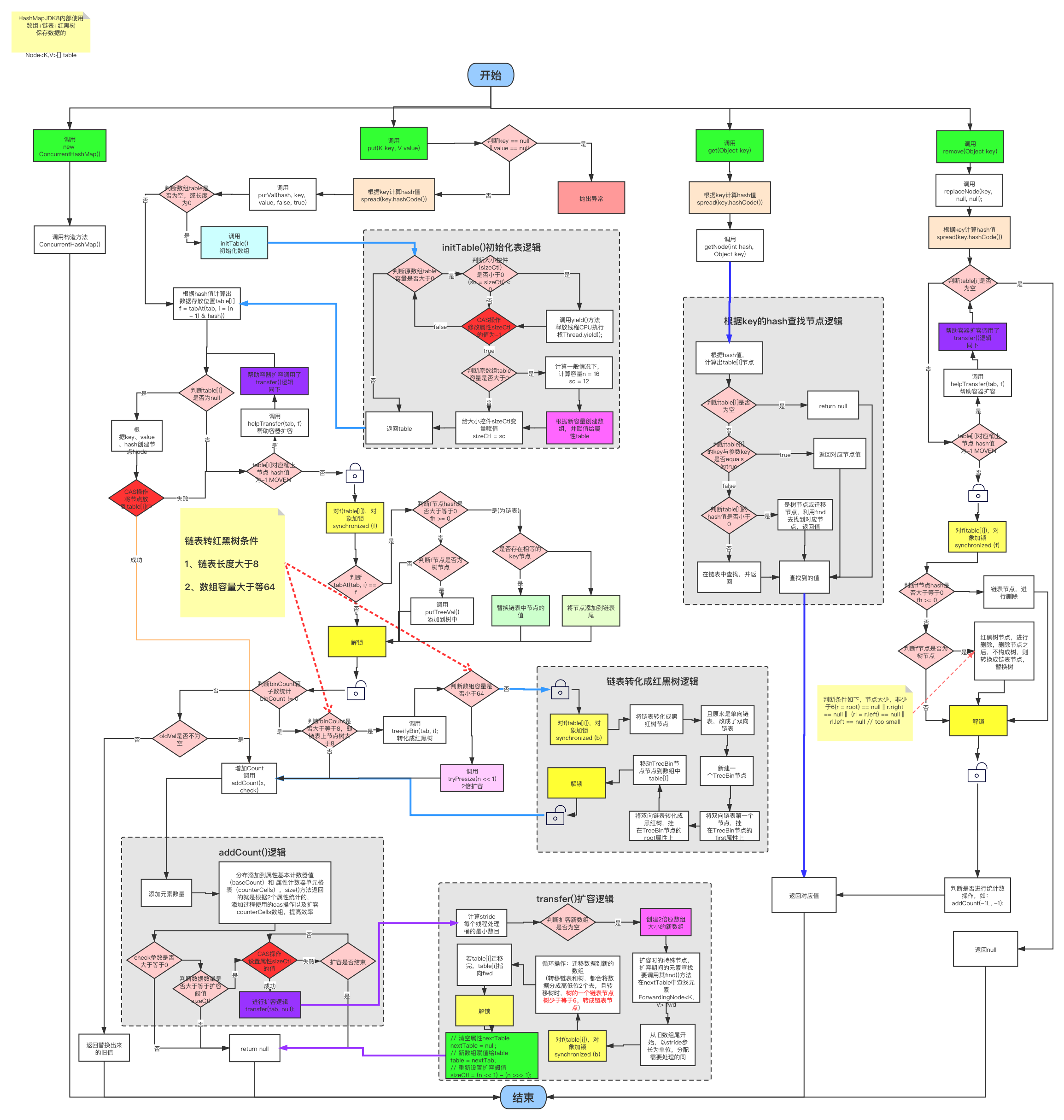
五、ConcurrentHashMap源码总结
1、ConcurrentHashMap 创建时的数组为空; 当加入第一个元素时,进行第一次扩容时,创建数组,默认容 量大小为 16。
2、ConcurrentHashMap 阀值固定是容量n的0.75倍,加载因子0.75是固定的
3、ConcurrentHashMap 每次扩容都以当前数组大小的 2 倍去扩容,多线程参与,各线程的扩容步长最小值为16。
4、ConcurrentHashMap 在扩容是,其他put线程与remove线程会参与到扩容中来。
5、ConcurrentHashMap 的 链表长度大于8,且数组容量大于等于64,链表转化成红黑树,红黑树是挂在TreeNode节点下的。
6、ConcurrentHashMap 是线程安全的,在put 或 remove 操作时,使用的是synchronized关键字,锁住的对象是table[i](数组上的桶),不影响其他桶的使用。
参考文章
1、https://blog.csdn.net/tp7309/article/details/76532366
2、https://blog.csdn.net/weixin_43185598/article/details/87938882