补充:
常量:,在Python中是没有定义的。
常量表示,经常用全部大写来表示,提示,是不能动的,实际上是可以动的。
文件的处理流程,
用普通的文本处理器处理文件,编辑器打开,进入内存,启动, 文件开始读入内存,由编辑器开始编辑,断电,则数据消失,要保存,则刷到硬盘里,
Python解释器的执行过程:
1.Python解释器启动,进入内存,与普通 的文本编辑器没有区别,
2.打开一个 .py 文件,文件从硬盘开始往内存读取,
3.Python解释器执行文件.py,开始执行加载到内存里代码,
Python解释器不仅可以读文件,还可以执行文件,
---------------------------------------------------------------------------------------------
一、字符编码
1.关于字符编码的来历
计算机通过高频电和低频电,来代表1和0 ,所以只认识1和0 ,人认识汉字,字母,数字,符号等,所以就需要计算机和人类之间进行一个翻译
所以必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为 ----字符编码
2.字符编码的发展
2.1
Ascll码 ,诞生在美国,基于英文的考虑,8个二进制来表示一个字节,既8bite=1bytes,
8bite就是8个1和0组成,可以代理256种状态,2*8=256,ASCII最初只用了后七位,127个数字,
已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了。
每一个字母,数字,符号,都对应了一个二进制,
2.2
中国的GBK, GBK:2Bytes代表一个字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,
问题,各种之间都有自己的标准,不统一,就产出了乱码,
2.3 unicode 的产生
Unicode全世界统一,2**16-1=65535,可代表6万多个字符,因而兼容万国语言,2个bytes代表一个字符,不存在语言问题,用Unicode代表英文字符就浪费了,占用空间多,但速度快,所以在内存里用Unicode处理,
utf-8是为了节省空间,英文用1个bytes,中文用3个bytes,占用空间小,处理速度就慢,所以在硬盘里,和网络中的数据都是utf-8
备注:
所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
Unicode与utf-8 之间存在一个对应关系
二、字符编码的使用

当文件全部加载到内存时,是Unicode,
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,
此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
以gbk保存的,就要告诉解释器用gbk编码格式打开,在文件开头写coding:gbk,
如果是utf-8,就告诉解释器用uft-8编码格式打开,在文件开头写coding:utf -8,
-----------------以上内容是文件读取到内存时候的过程-----------------------------
在文件开始执行时的过程,什么情况下全部是Unicode,
执行之前全是Unicode,y='egon'.encode('utf-8') ,--经过encode,转成了bytes类型,所以在encode阶段,可以成为任何类型
识别字符串是在执行阶段,在py3中是Unicode,Unicode 可以转成任意编码格式,默认情况下是Unicode,
注意:python3中使用utf-8编码,python2中用ASCII码编码
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,
如果 x='egon'.encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了,

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
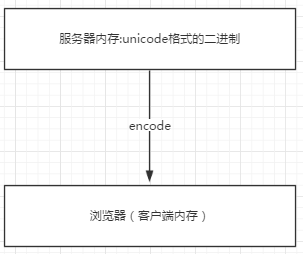
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制
2.1 在python2中有两种字符串类型str和unicode
str类型
当python解释器执行到产生字符串的代码时(例如s='林'),会申请新的内存地址,然后将'林'encode成文件开头指定的编码格式,这已经是encode之后的结果了,所以s只能decode
所以很重要的一点是:
在python2中,str就是编码后的结果bytes,str=bytes,所以在python2中,unicode字符编码的结果是str/bytes
unicode类型
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
打印到终端
对于print需要特别说明的是:
当程序执行时,比如
x='林'
print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存->内存,unicode->unicode
----------------------------------------------------------------------------------------------------------------------------------------------------------------
python3中的字符串与python2中的'字符串',都是unicode,所以无论如何打印都不会乱码
encode是Unicode编码的一个结果,是 bytes类型
byte类型的decode的结果是Unicode
--------------------------------------------------------------------------------------------------------
文件操作,
文件的 读 操作
f=open('1.txt','r')
print(f)
---结果 <_io.TextIOWrapper name='1.txt' mode='r' encoding='cp936'>
1.文件的打开与关闭
f=open('1.txt','r') -----如果读的这个文件不存在,就会报错
print(f)
# f.read()
f.close()-----------打开文件后一定要关掉,占用系统资源内存空间
f=open('1.txt','r',encoding='utf-8')-----告诉解释器,用encoding='utf-8'编码,取决文件存档的方式
------------------------------------------------------------------------------------------
2.文件读取
f=open('1.txt','r',encoding='utf-8')
# print(f)
print(f.read())----打印出读取文件的内容
-------------------------------------------------------------------------------------
3.文件每次的读取从开头开始读,第二次开始读时,没有结果,因为第一次读完文件后,光标已经移动到文件的最后
f=open('1.txt','r',encoding='utf-8')
# print(f)
print("1:",f.read())
print("2:",f.read())
结果
1: 111111
222222
aaaaaa
vvvvvv
2: ---------2后面的结果都为空,1 已经把文件一下子全部执行完
----------------------------------------------------------------------------------------
4.
f=open('1.txt','r',encoding='utf-8')
print(f.readline(),end='')
print(f.readline(),end='')
----------------一次读一行,print后面默认空一行,加end去掉空行-
--------------------------------------------------------------------------------------------
5.文件 读 的操作
f=open('1.txt','r',encoding='utf-8')
print(f.readlines(),end='')-------读出所有行,以列表形式输出
---------------------------------------------------------------------------------------
6.文件 写 的操作
f=open('1.txt','r',encoding='utf-8') ----文件是以读的方式打开,所以不能写
print(f.write('wwwwwwwww'))
print(f.write('wwwwwwwww'))
io.UnsupportedOperation: not writable ----结果报错,
--------------------------------------------------------------------------------------
7.
f=open('b.txt','r',encoding='utf-8')
f.write('
44444
')
f.flush() ------------flush 是把写的文件立即刷到硬盘里
f.close()
-----------------------------------------------------------------------------------------
文件的 写 操作
1. 如果操作一个不存在的文件,就会新建这个文件,如果文件存在,就把该文件的内容清掉,才开始写
f=open('b.txt','w',encoding='utf-8')
print(f.write())
--------------------------------------------------------------------------------------
2.文件不能写数字,只能写字符
f=open('b.txt','w',encoding='utf-8')
print(f.write(11111111)
SyntaxError: invalid syntax ------报错
------------------------------------------------------------------------------------------
3. 写入内容,不加
不会换行,加上
换行
f=open('b.txt','w',encoding='utf-8')
f.write('11111111 ')
f.write('22222222 ')
f.close()
结果
11111111
22222222
--------------------------------------------------------------------------
4. 以列表的形式写,每次写都会覆盖之前的内容
f=open('b.txt','w',encoding='utf-8')
print(f.writelines(['11111 ','aaaa ','bbbb ']))
f.close()
结果
11111
aaaa
bbbb
----------------------------------------------------------------------------------------
文件的 a 模式,,文件不存在,就新建, ,如果文件存在,就不动之前的文件,
在 a 的模式下,写 是追加的方式写,
1.
f=open('b.txt','a',encoding='utf-8')
print(f.write('44444 '))
print(f.write('555555 '))
f.close()
结果
11111
cccc
bbbb
44444
555555 追加,
----------------------------------------------------------------------------
2.查看文件的关闭状态
f=open('b.txt','r',encoding='utf-8')
f.close() ------关闭文件
print(f.closed) --------查看文件是否关闭
结果----True 关闭
--------------------------------------------------------------------------------
3.
f=open('b.txt','r',encoding='utf-8') -----查看文件的名字。编码格式
print(f.name,f.encoding)
print(f.readable()) ---- True 查看是否可读
print(f.writable()) ----- False 查看是否可写 ,读的模式下,不能读,写的模式下,可以
结果 b.txt utf-8
----------------------------------------------------------------------------
关于seek的操作
1.
f=open('c.txt','r',encoding='utf-8')
print(f.read(9)) ----read指定参数,就是从哪个字符开始读取,以字符为单位开始读取
结果
44444
555
c.txt的文件内容如下
文件内光标移动都是以字节为单位------seek,tell,read,truncate
用read命令时,读到文件最后,再读第二次就读不到了,
要把光标移到开头,就要用到 f.seek(),括号里加数字,表示位置
seek ()参数,0默认从头开始,1从当前开始,2从末尾开始
1.
f=open('c.txt','r',encoding='utf-8')
f.seek(12) --seek以字节为 读取单位,一个汉字是3个字节,12 代表了4
个汉字,所以结果就从 月开始显示
print(f.read())
结果
月44444
555555
44444
555555

-------------------------------------------------------------------------------------
2.
f=open('c.txt','r',encoding='utf-8')
print(f.seek(4))
print(f.tell())-----------tell告诉光标显示的位置
-------------------------------------------------------------------------------------------
3. 截断
f=open('c.txt','w',encoding='utf-8') -----一定要找 写 的模式下
print(f.truncate(2)) --------把文件从光标的位置开始向后截断,,但必须是在 写 的模式下
直接把截断,就没有了
---------------------------------------------------------------------------------------
4.
f=open('c.txt','w',encoding='utf-8')
f.write('1111111
')
f.write('1144444
')
f.write('11133333
')
f.write('1222222
')
print(f.truncate(3))----------------------把追加的都删除了,只有光标前的3个字节

----------------------------------------------------------------------------------
5.
f=open('c.txt','rb') --------,以rb的模式读,不需要再(encode编码)
print(f.read())
结果
b'xe5x8dxb3xe5xb0x86xe7xbbx93
xe6x9dx9fxe5xbcx80xe5xa7x8b
111111
222222
333333'
---------------------------------------------------------------------------------
6.
f=open('c.txt','rb')
print(f.read().decode('utf-8')) -----从utf-8解码(decode)
结果
练习.py
即将结束开始
111111
222222
333333
--------------------------------------------------------------------------
7.wb 模式写
f=open('c.txt','wb')
f.write('hello world') ----写文件,以bytes的形式写,字符串是Unicode,必须 encode(utf-8)
f.close()
结果
f.write('hello world')
TypeError: a bytes-like object is required, not 'str'
f=open('c.txt','wb') ---- wb 的模式,
f.write('hello world'.encode('utf-8')) ----写文件,必须是encode 编码后才能写到文件里
f.close()
-------------------------------------------------------------------------------
8.
复制文件的过程,
read_file=open('c.txt','rb') -----打开一个 文件,以读的方式,rb ,指定一个文件
write_file=open('c1.txt','wb') -----写文件,copy的结果,
write_file.write(read_file.read()) -----把写的内容从read的文件里读出来,

------------------------------------------------------------------------------9.文件打开的位置 ,绝对路径,win里是双斜杠,可以加 r ,反转

---------------------------------------------------------------------------------------
10.
读取文件内容
f=open('c.txt','r',encoding='utf-8')
for line in f :
print(line, end='')
结果
hello world
alex
dddd
111
alex66666