自定义processFunction函数:
// 3.2 添加任务,使用{@link ProcessFunction}方便控制: 1. 忽略null数据,2. 旁路输出side output DetaiEventRuleExecutingProcessor executingProcessor = new DetaiEventRuleExecutingProcessor();
函数内部实现,进行数据的简单四舍五入:
public class DetaiEventRuleExecutingProcessor extends ProcessFunction<StartupInfoData, DetailData> { private static final OutputTag<StartupInfoData> APP_LOG_TAG = new OutputTag<>("RandomLessFive", TypeInformation.of(StartupInfoData.class)); private void sideOut(OutputTag<StartupInfoData> tag, StartupInfoData inputKV, Context ctx) { ctx.output(tag, inputKV); } @Override public void processElement(StartupInfoData startupInfoData, Context context, Collector<DetailData> collector) throws Exception { if(startupInfoData.getRandomNum() < 5) { sideOut(APP_LOG_TAG, startupInfoData, context); }else if(startupInfoData.getRandomNum() >= 5){ DetailData detailData = new DetailData(); detailData.setAppId(startupInfoData.getAppId()); detailData.setAppName(startupInfoData.getAppName()); detailData.setMsgtime(System.currentTimeMillis()); detailData.setRandomNum(startupInfoData.getRandomNum()); collector.collect(detailData); } } }
将处理的数据以及旁路数据写入到文件,4一下写入u4, 5以及以上写入b5:
//自定义processFunction,同时进行sideOut SingleOutputStreamOperator<DetailData> executeMainStream = startupInfoData.process(executingProcessor).name("processExecuteProcessor"); //输出5以上的数值 executeMainStream.writeAsText("D:\all\b5.txt").setParallelism(1); logger.info("丢弃分割线.........................."); //获取丢弃的原始数据 DataStream<StartupInfoData> leftLogStream = executeMainStream.getSideOutput(APP_LOG_TAG); leftLogStream.writeAsText("D:\all\u4.txt").setParallelism(1);
主函数配置以及kafka数据获取:
logger.info("------------------------------------------------------");
logger.info("------------- FlinkKafkaSource Start -----------------");
logger.info("------------------------------------------------------");
String ZOOKEEPER_HOST = kafkaConf.getZkhosts();
String KAFKA_BROKER = kafkaConf.getServers();
String TRANSACTION_GROUP = kafkaConf.getGroup();
String topic = kafkaConf.getTopic();
Properties prop = new Properties();
prop.setProperty("zookeeper.connect", ZOOKEEPER_HOST);
prop.setProperty("bootstrap.servers", KAFKA_BROKER);
prop.setProperty("group.id", TRANSACTION_GROUP);
//todo Flink的流运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//todo checkpoint配置 每5s checkpoint一次
// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为exactly-once (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许进行一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置statebackend
//env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop100:9000/flink/checkpoints",true));
//创建消费者
logger.info("%%%%%%% 消费topic: {}", topic);
FlinkKafkaConsumer011<String> consumer011 = new FlinkKafkaConsumer011<>(topic, new SimpleStringSchema(), prop);
//todo 默认消费策略--从上次消费组的偏移量进行继续消费
consumer011.setStartFromGroupOffsets();
DataStreamSource<String> text = env.addSource(consumer011);
//todo map 输入一个数据源,产生一个数据源
DataStream<StartupInfoData> startupInfoData = text.map(new MapFunction<String, StartupInfoData>() {
@Override
public StartupInfoData map(String input) throws Exception {
return JSON.parseObject(input, StartupInfoData.class);
}
});
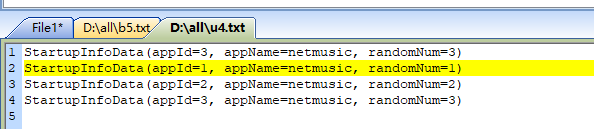
测试结果是否准确:
source,kafka生产的数据:

输出文件:

-------------------------------------------------------------------------------------------------------------------------------------------------------
范例二:
private static final OutputTag<LogEntity> APP_LOG_TAG = new OutputTag<>("appLog", TypeInformation.of(LogEntity.class)); private static final OutputTag<LogEntity> ANALYZE_METRIC_TAG = new OutputTag<>("analyzeMetricLog", TypeInformation.of(LogEntity.class));
private static SingleOutputStreamOperator<LogEntity> sideOutStream(DataStream<LogEntity> rawLogStream) { return rawLogStream .process(new ProcessFunction<LogEntity, LogEntity>() { @Override public void processElement(LogEntity entity, Context ctx, Collector<LogEntity> out) throws Exception { // 根据日志等级,给对象打上不同的标记 if (entity.getLevel().equals(ANALYZE_LOG_LEVEL)) { ctx.output(ANALYZE_METRIC_TAG, entity); } else { ctx.output(APP_LOG_TAG, entity); } } }) .name("RawLogEntitySplitStream"); } // 调用函数,对原始数据流中的对象进行标记 SingleOutputStreamOperator<LogEntity> sideOutLogStream = sideOutStream(rawLogStream); // 根据标记,获取不同的数据流,以便后续进行进一步分析 DataStream<LogEntity> appLogStream = sideOutLogStream.getSideOutput(APP_LOG_TAG); DataStream<LogEntity> rawAnalyzeMetricLogStream = sideOutLogStream.getSideOutput(ANALYZE_METRIC_TAG);