正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

------------------------正文开始---------------------------
1、flume的特点:
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。Event是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
flume的可靠性 :
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
flume的可恢复性:
还是靠Channel。推荐使用FileChannel,事件Event持久化在本地文件系统里(性能较差)。
flume的一些核心概念:
Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
Client生产数据,运行在一个独立的线程。
Source从Client收集数据,传递给Channel。
Sink从Channel收集数据,运行在一个独立线程。
Channel连接 sources 和 sinks ,这个有点像一个队列。
Events可以是日志记录、 avro 对象等。
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
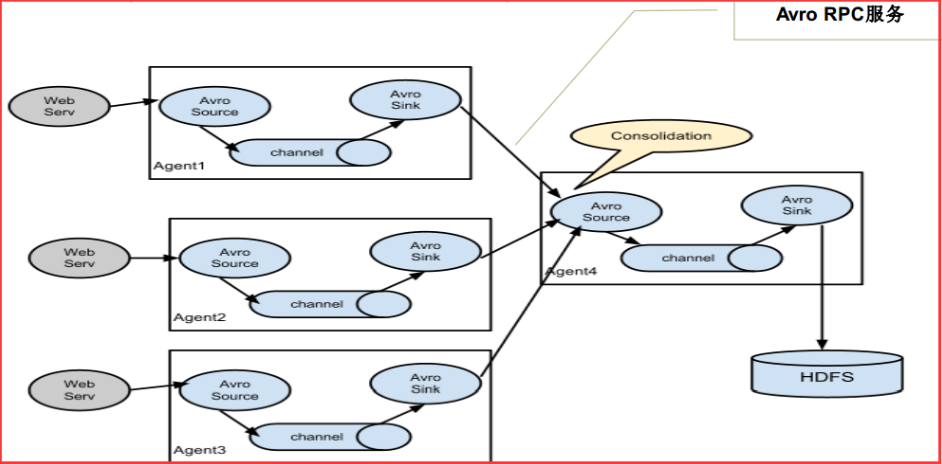
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source、Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是NB之处。如下图所示:
2、flume的案例
Spool 监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:
1) 拷贝到spool目录下的文件不可以再打开编辑。
2) spool目录下不可包含相应的子目录。
############################################
(a)log4j配置:
我使用log4j的DailyRollingFileAppender去每分钟生成一个日志到配置的目录下,代码如下:
#输出信息到文件
log4j.appender.file = org.apache.log4j.DailyRollingFileAppender
#这个是生成日志文件的目录及文件名
log4j.appender.file.File = /Users/jsj/eclipse-workspace/log4j/src/main/java/testlog.log
log4j.appender.file.Append = true
#每分钟产生一个日志文件
#当前的文件名是testlog.log,前面分钟产生的文件是这种命名形式testlog.log.2018-08-20-18-16。
log4j.appender.file.DatePattern = '.'yyyy-MM-dd-HH-mm
log4j.appender.file.layout = org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern = [%-5p] %-d{yyyy-MM-dd HH:mm:ss} %m%n(b)模拟产生日志:
日志的内容(不含log4j中的配置)为:0a58f82b-ff6f-4feb-abe2-7c6ac9a0c24d####ERH####qhp####6677062格式为:用户ID--县号--镇号--收入
public class Main { public static void main(String[] args) throws Exception { Thread thread = new Thread(new GenerateRecord()); thread.start(); } } class GenerateRecord extends Thread { private final Logger log = Logger.getLogger(GenerateRecord.class); public void run() { while (true) { // 随机产生一个用户uuid UUID userId = UUID.randomUUID(); System.out.println(userId.toString().length()); // 产生一个随机的用户总资产 int num = (int) (Math.random() * 10000000) + 100000; // 产生一个随意的县名 StringBuilder sb = new StringBuilder(); for (int i = 0; i < 3; i++) { char a = (char) (Math.random() * (90 - 65) + 65); sb.append(a); } String county = sb.toString(); // 产生一个随机的镇名 StringBuilder sb1 = new StringBuilder(); for (int i = 0; i < 3; i++) { char a = (char) (Math.random() * (122 - 97) + 97); sb1.append(a); } String town = sb1.toString(); // 生成日志 log.info(userId + "####" + county + "####" + town + "####" + num); // 停1秒钟 try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }
在几分钟后停掉程序,在终端输入cd /Users/jsj/eclipse-workspace/log4j/src/main/java/查看生成的文件 ls -1 ,如下:

(c)创建agent配置文件:
在flume安装目录的conf/flume.conf下加入如下代码:
----------------------------------------------------------------
# my application flume configuration
#agent2是我们给agent起的名字
agent2.sources=source2
agent2.sinks=sink2
agent2.channels=channel2
#Spooling Directory
#set source2
#设置type为spooldir,这个值是flume给定的alias
agent2.sources.source2.type=spooldir
#设置监控目录,注意和前面log4j的目录不同
agent2.sources.source2.spoolDir=/Users/jsj/eclipse-workspace/logs
agent2.sources.source2.channels=channel2
agent2.sources.source2.fileHeader = false
#set sink2
agent2.sinks.sink2.type=hdfs
agent2.sinks.sink2.hdfs.path=hdfs://localhost:9000/flume
agent2.sinks.sink2.hdfs.fileType=DataStream
agent2.sinks.sink2.hdfs.writeFormat=TEXT
agent2.sinks.sink2.hdfs.rollInterval=60
agent2.sinks.sink2.channel=channel2
#设置存储到HDFS后文件的前缀
agent2.sinks.sink2.hdfs.filePrefix=%Y-%m-%d
#set channel2
#设置内存通道
agent2.channels.channel2.type=memory
agent2.channels.channel2.capacity=10000
agent2.channels.channel2.transactionCapacity=1000
agent2.channels.channel2.keep-alive=30----------------------------------------------------------------
启动服务:
|
./flume-ng agent -c ../conf -f ../conf/flume.conf -Dflume.root.logger=INFO,console -n agent2 |
观察日志:
此时flume的终端会嗖嗖嗖的刷日志,我截下来几条,主要是打开文件,对正在处理的文件改名为.tmp后缀,上传到HDFS后把HDFS上文件的.tmp删掉,本地的监控目录下文件加.COMPLETED后缀。
观察HDFS:
这时候我们去HDFS上检查一下:新开个终端输入hadoop fs -ls /flume,发现生成了比我们文件数多的多的文件,原来只有11个,现在有62个文件。