2017-2018-1 20155227 《信息安全系统设计基础》第四周学习总结
补充完成课上没有完成的内容(2分)
myod-系统调用版本
1 参考教材第十章内容
2 用Linux IO相关系统调用编写myod.c 用myod XXX实现Linux下od -tx -tc XXX的功能,注意XXX是文件名,通过命令行传入,不要让用户输入文件名
3. 不要把代码都写入main函数中
4. 要分模块,不要把代码都写入一个.c中
5 提交测试代码和运行结果截图, 提交调试过程截图,要全屏,包含自己的学号信息
课上做实践的时候本来只需要就上周的代码做些修改,但是我对命令行传参的方法不太了解,一直无从下手,课下查了资料之后发现若要改为命令行传参对我上周的代码修改较大,所以参考资料重新写了一份代码,与上周不同。
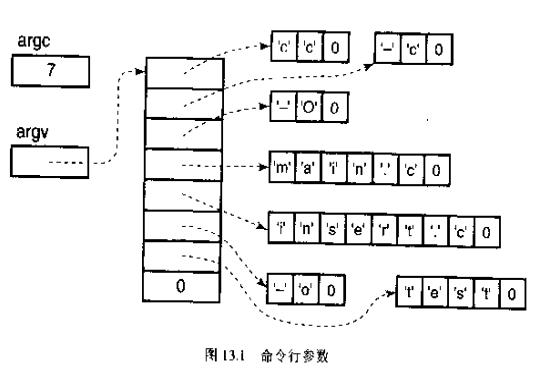
命令行传参
在支持C语言的环境中,可以在程序开始执行时将命令行参数传递给程序。
调用主函数main时,有两个参数,第一个参数表示运行程序时命令行中参数的数目;第二个参数表示指向字符串数组的指针,其中每个字符串对应一个参数。
main(int argc, char *argv[])
argc和argv是习惯性用法,可以更改。
argv是一个指向指针的指针,
这个数组的每个元素都是一个字符指针,指向的第一个参数就是程序的名称,最后一个是NULL。
什么是文件
在Linux中,一切(或几乎一切)都是文件。
系统调用
1、文件描述符
文件描述符是一些小数值,可以通过它们访问的打开的文件设备,而有多少文件描述符可用取决于系统的配置情况。但是当一个程序开始运行时,它一般会有3个已经打开的文件描述符,就是
0:标准输入
1:标准输出
2:标准错误
那些数字(即0、1、2)就是文件描述符,因为在Linux上一切都是文件,所以标准输入(stdin),标准输出(stdout)和标准错误(stderr)也可看作文件来对待。
2、用到的系统调用函数
A、open系统调用
open函数的原型为:
int open(const char *path, int oflags);
int open(const char *path, int oflags, mode_t mode);
open函数要使用的头文件有:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
函数说明:
O_RDONLY 以只读方式打开文件
O_WRONLY 以只写方式打开文件
O_RDWR 以可读写方式打开文件。上述三种旗标是互斥的,也就是不可同时使用,但可与下列的旗标利用OR(|)运算符组合。
O_CREAT 若欲打开的文件不存在则自动建立该文件。
O_EXCL 如果O_CREAT也被设置,此指令会去检查文件是否存在。文件若不存在则建立该文件,否则将导致打开文件错误。此外,若O_CREAT与O_EXCL同时设置,并且欲打开的文件为符号连接,则会打开文件失败。
O_NOCTTY 如果欲打开的文件为终端机设备时,则不会将该终端机当成进程控制终端机。
O_TRUNC 若文件存在并且以可写的方式打开时,此旗标会令文件长度清为0,而原来存于该文件的资料也会消失。
O_APPEND 当读写文件时会从文件尾开始移动,也就是所写入的数据会以附加的方式加入到文件后面。
O_NONBLOCK 以不可阻断的方式打开文件,也就是无论有无数据读取或等待,都会立即返回进程之中。
O_NDELAY 同O_NONBLOCK。
O_SYNC 以同步的方式打开文件。
O_NOFOLLOW 如果参数pathname 所指的文件为一符号连接,则会令打开文件失败。
O_DIRECTORY 如果参数pathname 所指的文件并非为一目录,则会令打开文件失败。
open建立了一条到文件或设备的访问路径,如果调用成功,返回一个可以被read、write等其他系统调用的函数使用的文件描述符,而且这个文件描述是唯一的,不与任何其他运行中的进程共享,在失败时返回-1,并设置全局变量errno来指明失明的原因。
B、read系统调用
read函数的原型为:
size_t read(int fildes, void *buf, size_t nbytes);
read函数表头文件:
#include<unistd.h>
read系统调用的作用是从与文件描述符相关的文件里读入nbytes个字节的数据,并把它们放到数据区buf中,返回读入的字节数,失败时返回-1。 如果顺利read()会返回实际读到的字节数,最好能将返回值与参数count作比较,若返回的字节数比要求读取的字节数少,则有可能读到了文件尾、从管道(pipe)或终端机读取,或者是read()被信号中断了读取动作。当有错误发生时则返回-1,错误代码存入errno中,而文件读写位置则无法预期。
C、close系统调用
close调用的函数原型为:
int close(int fildes);
close函数的作用是终于文件描述符fildes一其对应的文件之间的关联。
close调用函数头文件:
#include <unistd.h>
遇到的问题
-
问题1 运行之后出现乱码,出现段错误。
1.出现的原因:linux系统为一个进程的分配的堆栈空间只有8k左右,我定义了的数组所占空间过大,肯定会把堆栈撑爆,故会出现核心已转储的错误提示。
2.解决办法:一般局部变量分配的空间不要超过1024字节大小,修改定义的数组大小,该问题得以解决。
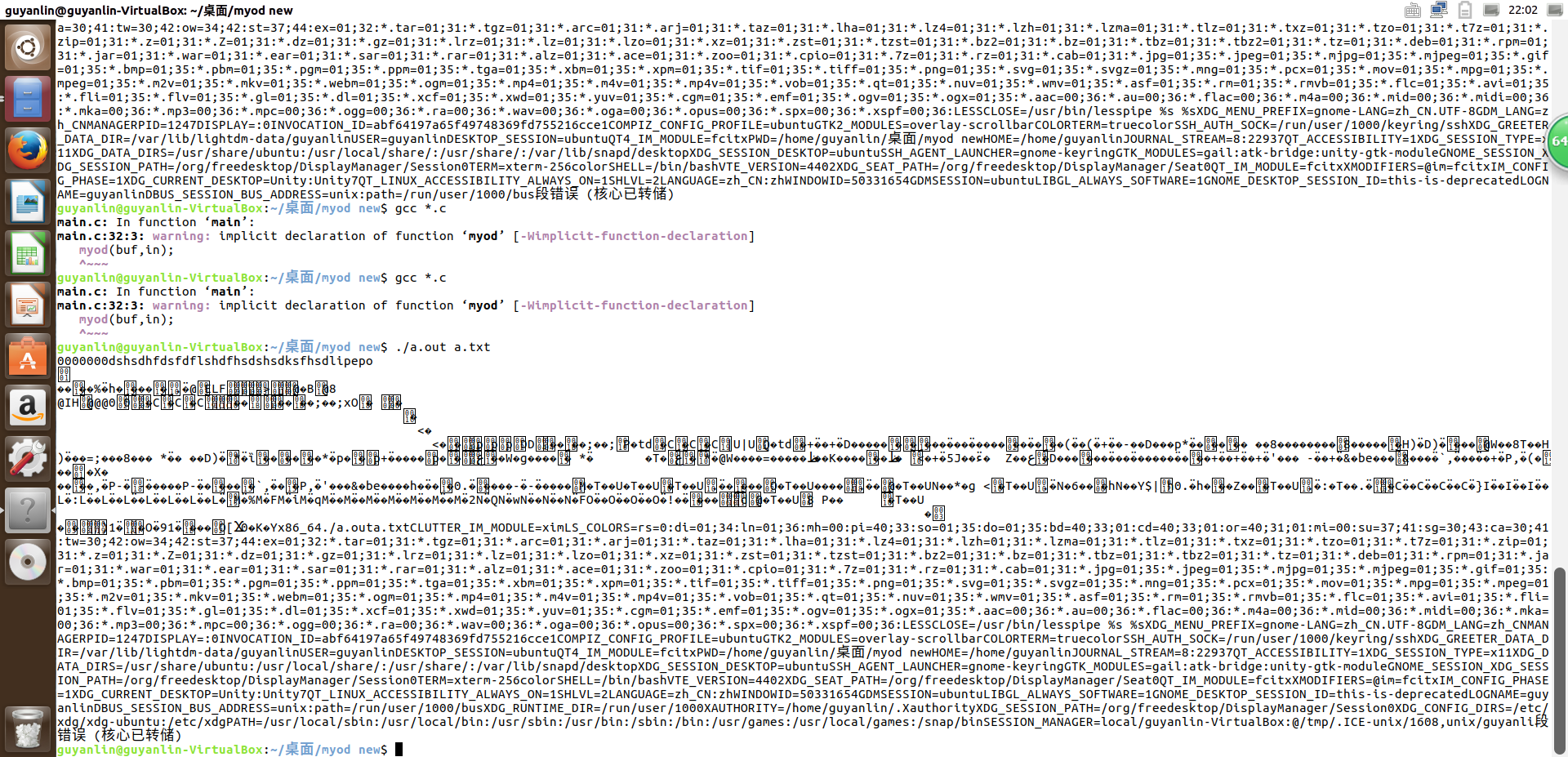
- 问题2 只能以16字节为单位输出一行。
- 解决办法:以一个变量count来计数不满16字节时一行输出的字节数。
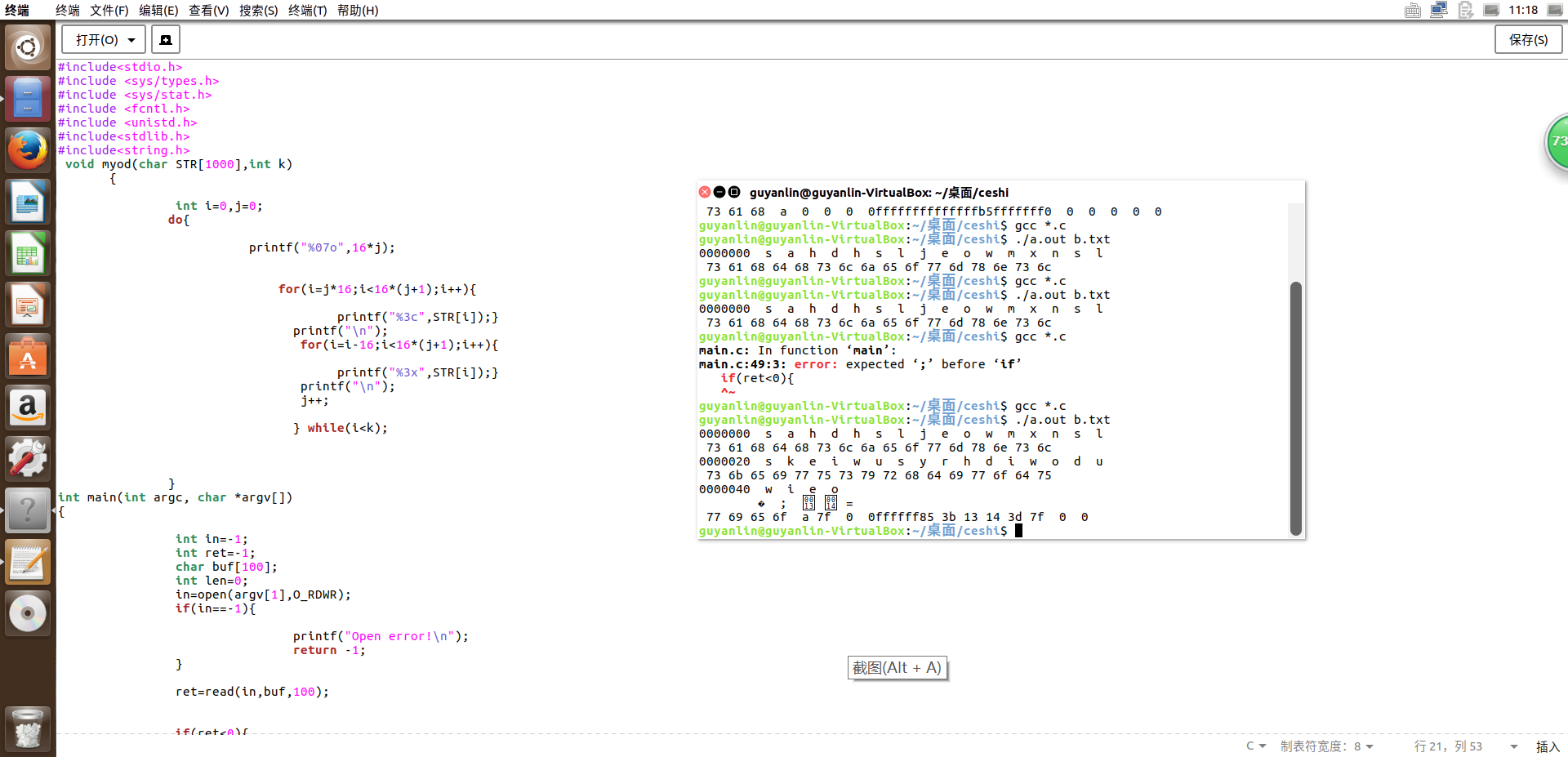

- 最终运行截图
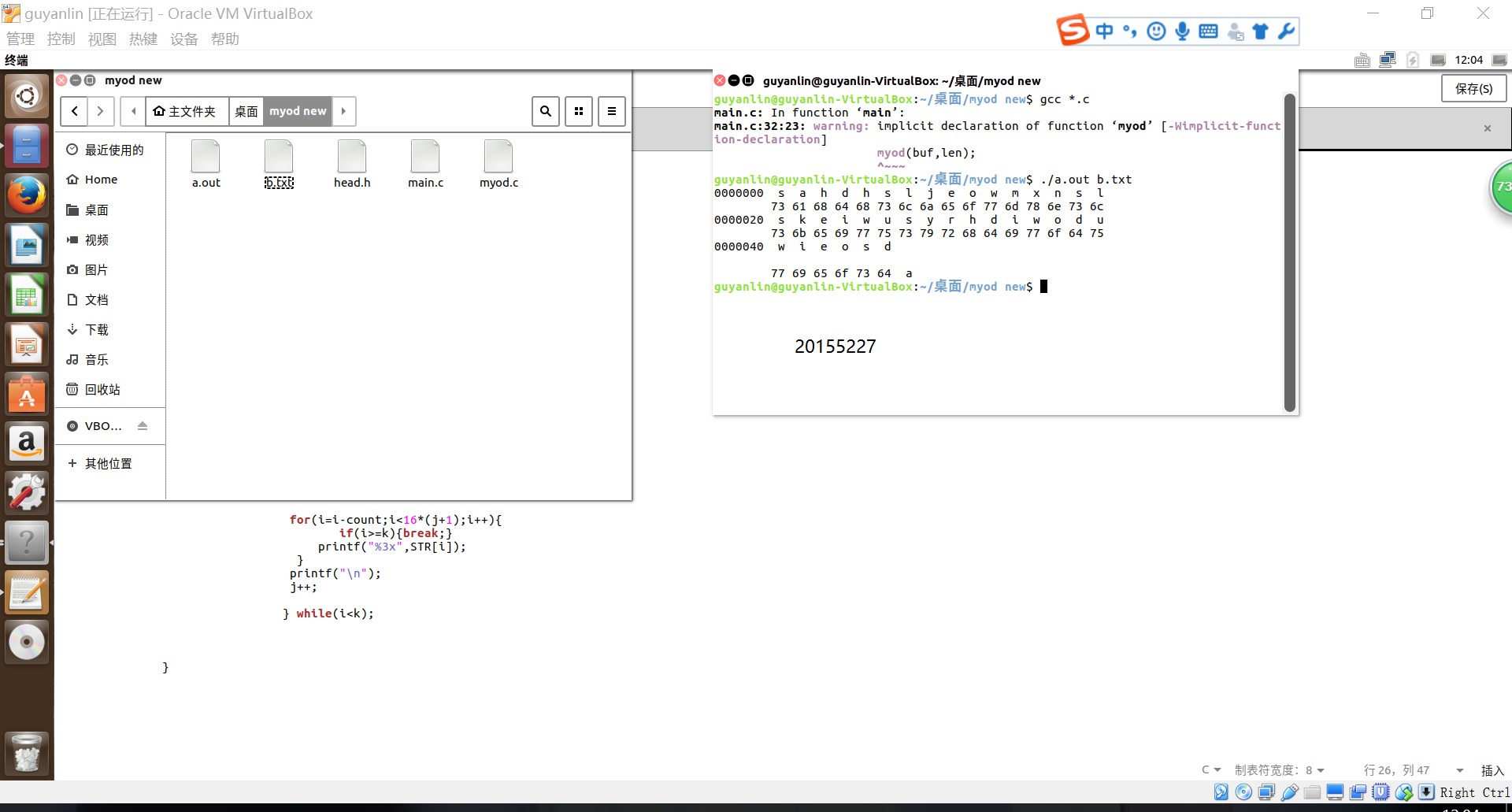
学习教材附录A,第十章内容
写文件
write原型(将数据写入已打开的文件内):
#include <unistd.h>
ssize_t write (int fd, const void *buf, size_t count);
fd代表open成功返回的文件描述符,也是要写入数据的文件
buf 存储要写入的数据
count 代表写入的数量
返回值:如果写入成功,返回写入的数据量,如果失败,返回-1,并设置errno
错误代码:
EINTR 此调用被信号所中断。
EAGAIN 当使用不可阻断I/O 时(O_NONBLOCK),若无数据可读取则返回此值。
EADF 参数fd非有效的文件描述词,或该文件已关闭。
linux基本I/O接口
在Linux中,read 和 write 是基本的系统级I/O函数。当用户进程使用read 和 write 读写linux的文件时,进程会从用户态进入内核态,通过I/O操作读取文件中的数据。内核态(内核模式)和用户态(用户模式)是linux的一种机制,用于限制应用可以执行的指令和可访问的地址空间,这通过设置某个控制寄存器的位来实现。进程处于用户模式下,它不允许发起I/O操作,所以它必须通过系统调用进入内核模式才能对文件进行读取。
RIO包
RIO,全称Robust I/,即健壮的IO包。它提供了与系统I/O类似的函数接口,在读取操作时,RIO包加入了读缓冲区,一定程度上增加了程序的读取效率。另外,带缓冲的输入函数是线程安全的。
RIO包中有专门的数据结构为每一个文件描述符都分配了相应的独立的读缓冲区,这样不同线程对不同文件描述符的读访问也就不会出现并发问题(然而若多线程同时读同一个文件描述符则有可能发生并发访问问题,需要利用锁机制封锁临界区)。
标准IO库
绝大部分的系统都提供了C接口的标准IO库,与RIO包相比,标准IO库有更加健全的,带缓冲的并且支持格式化输入输出。标准IO和RIO包都是利用read, write等系统调用实现的。
标准IO操作的对象与Unix I/O的不太相同,标准IO接口的操作对象是围绕流(stream)进行的。
对于大多数应用程序而言,标准IO更简单,是优于Unix I/O的选择。然而在网络套接字的编程中,建议不要使用标准IO函数进行操作,而要使用健壮的RIO函数。RIO函数提供了带缓冲的读操作,与无缓冲的写操作(对于套接字来说不需要),且是线程安全的。
I/O重定向
在Unix系统中,每个进程都有STDIN、STDOUT和STDERR这3种标准I/O,它们是程序最通用的输入输出方式。几乎所有语言都有相应的标准I/O函数,比如,C语言可以通过scanf从终端输入字符,通过printf向终端输出字符。熟悉Shell的人可以方便地对Shell命令进行I/O重定向,比如 find -name "*.java" >testfile.txt 把当前目录下的Java文件列表重定向到testfile.txt。
参考别出心裁的Linux系统调用学习法,学习视频,掌握两个重要命令:
man -k key1 | grep key2| grep 2: 根据关键字检索系统调用grep -nr XXX /usr/include:查找宏定义,类型定义
课上跟着老师的讲解已大致理解这两个命令的使用方法。会在接下来的实践中通过练习来加深理解。
完成head,tail的使用,相关API的分析,伪代码,产品代码,测试代码的编写(3分)
通过查找man来学习这两个命令。
head命令
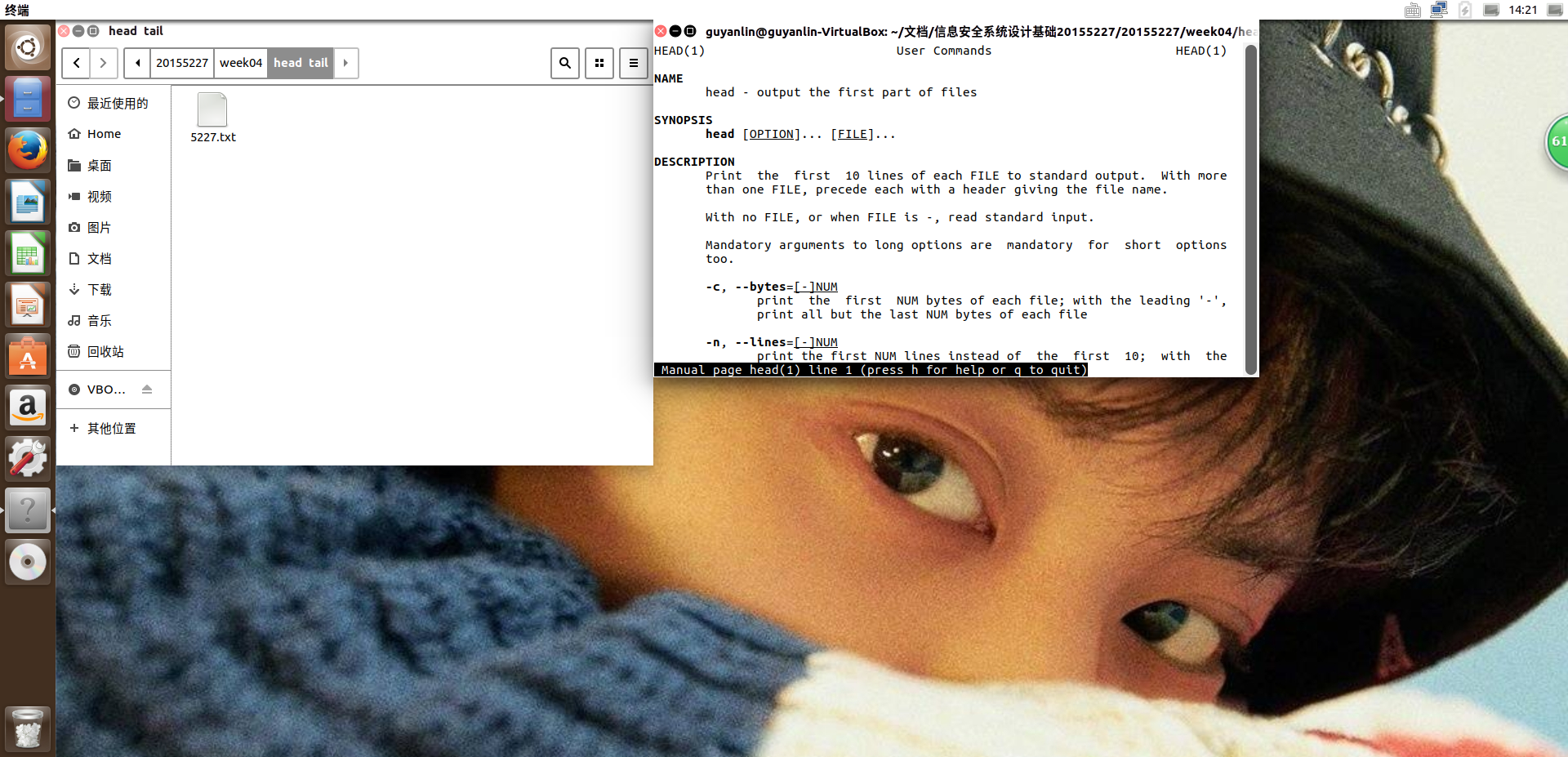
1.命令格式:
head [参数]... [文件]...
2.命令功能:
head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
3.命令参数:
-q 隐藏文件名
-v 显示文件名
-c<字节> 显示字节数
-n<行数> 显示的行数
4.使用实例:
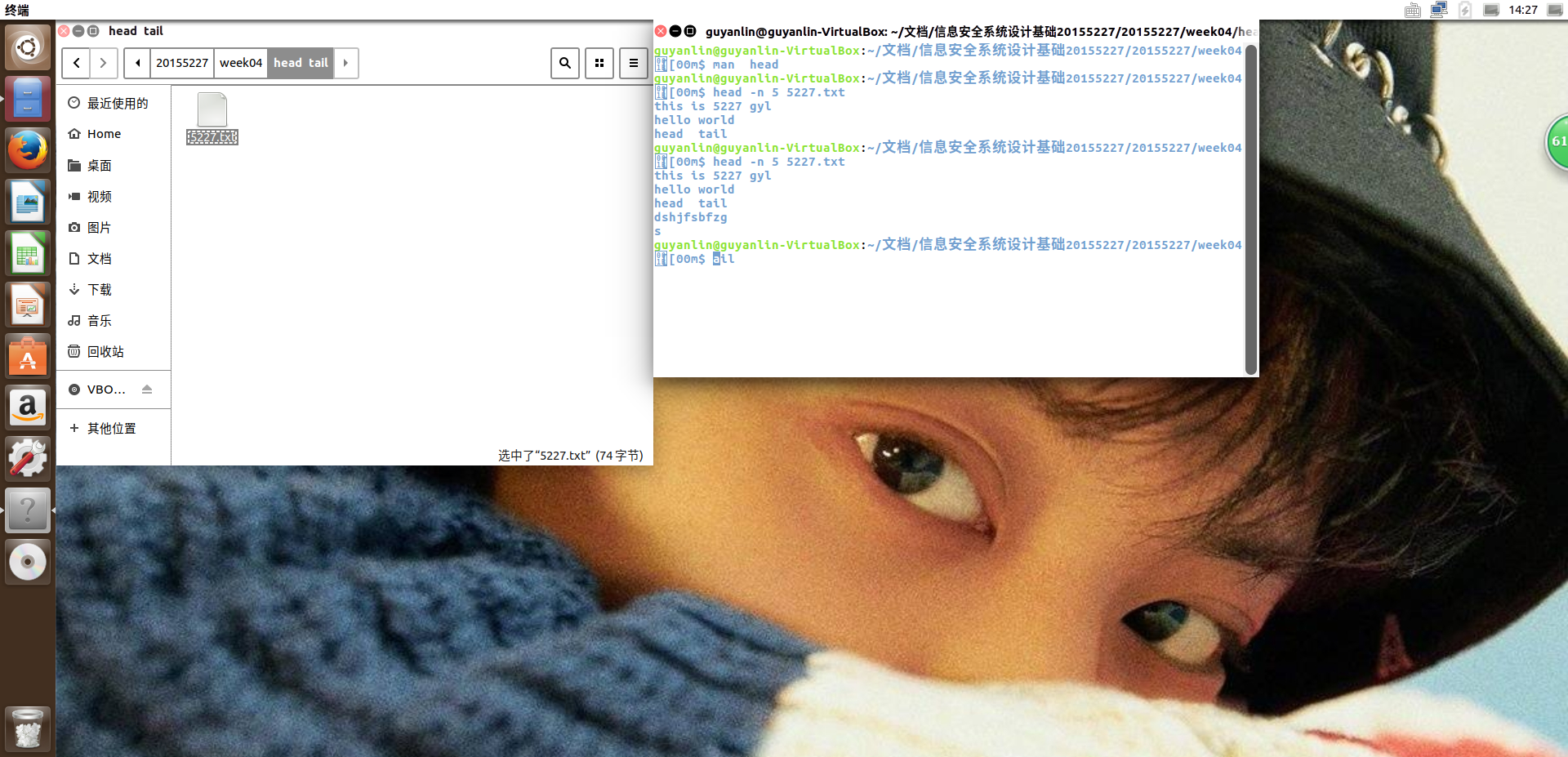
实例1:显示文件的前n行
命令:
head -n 5 5227.txt
实例2:显示文件前n个字节
命令:
head -c 16 5227.txt

实例3:文件的除了最后n个字节以外的内容
命令:
head -c -32 5227.txt

实例4:输出文件除了最后n行的全部内容
命令:
head -n -6 5227.txt

tail命令
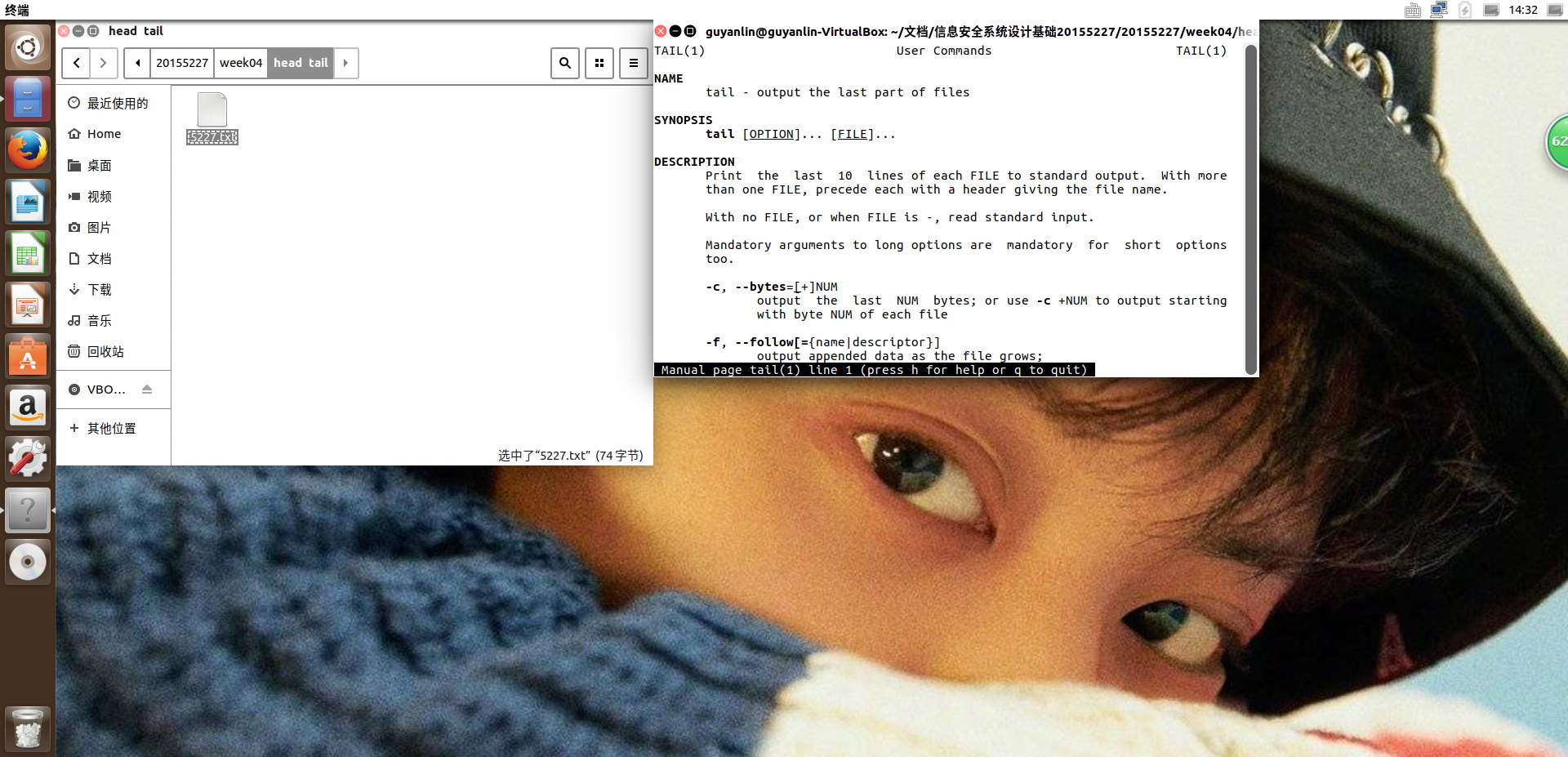
1.命令格式:
tail [ -f ] [ -c Number | -n Number | -m Number | -b Number | -k Number ] [ File ]tail [ -f ] [ -c Number | -n Number | -m Number | -b Number | -k Number ] [ File ]
以逆序显示行:
tail [ -r ] [ -n Number ] [ File ]
2.命令功能:
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
3.命令参数:
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示行数
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束.
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
使用实例
实例1:显示文件最后10行
命令:
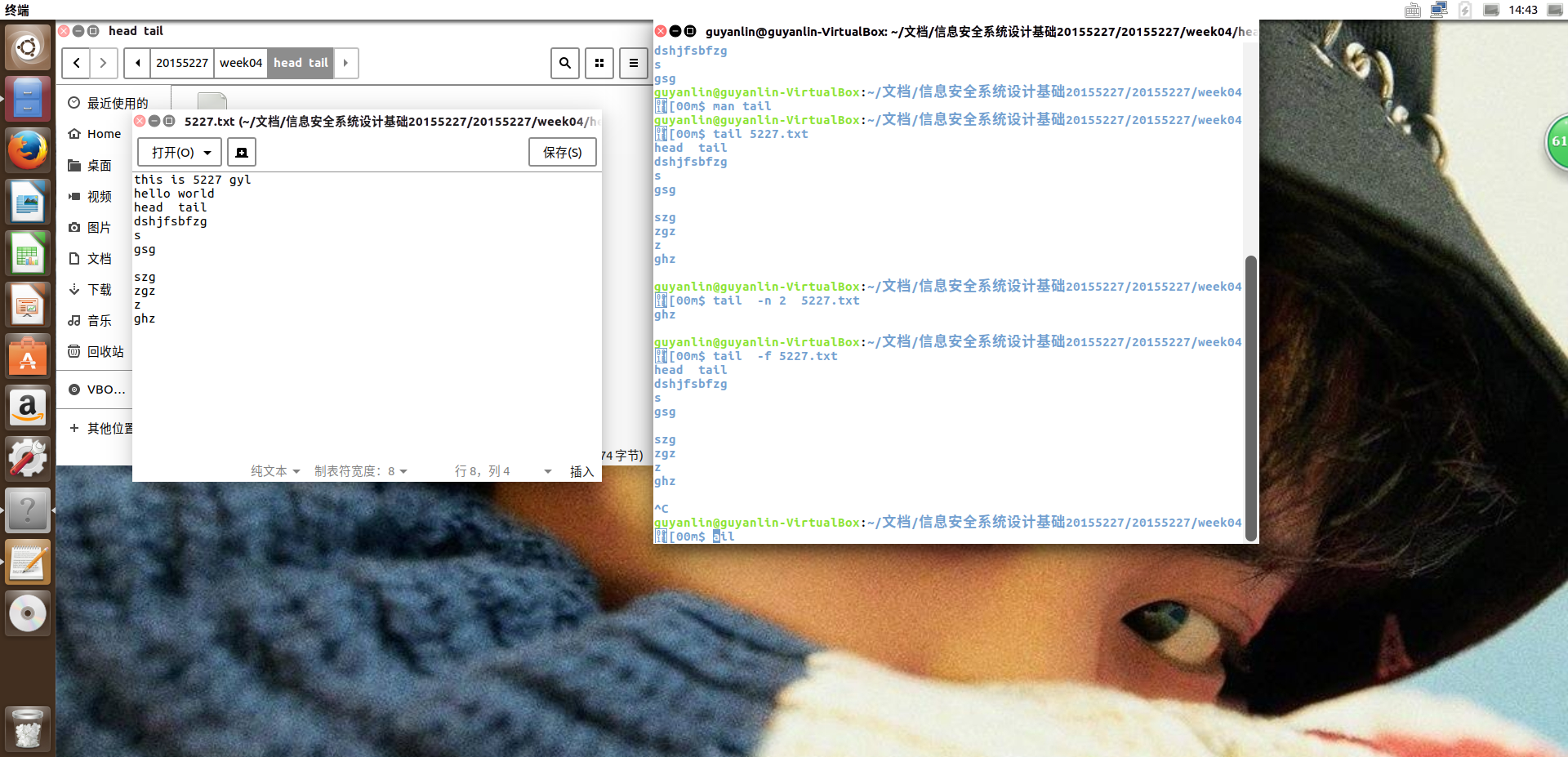
tail 5227.txt
实例2:要指定从文件末尾开始读取的行数
命令:
tail -n 2 5227.txt
实例3:要跟踪文件的增长
显示文件的最后十行。tail 命令继续显示添加到 文件中的行。显示会一直继续,直到按下 Ctrl-C 按键顺序来停止。
命令:
tail -f 5227.txt
伪代码,产品代码,测试代码的编写
head命令 显示文件的前n行
命令:head -n X 5227.txt
代码运行截图:
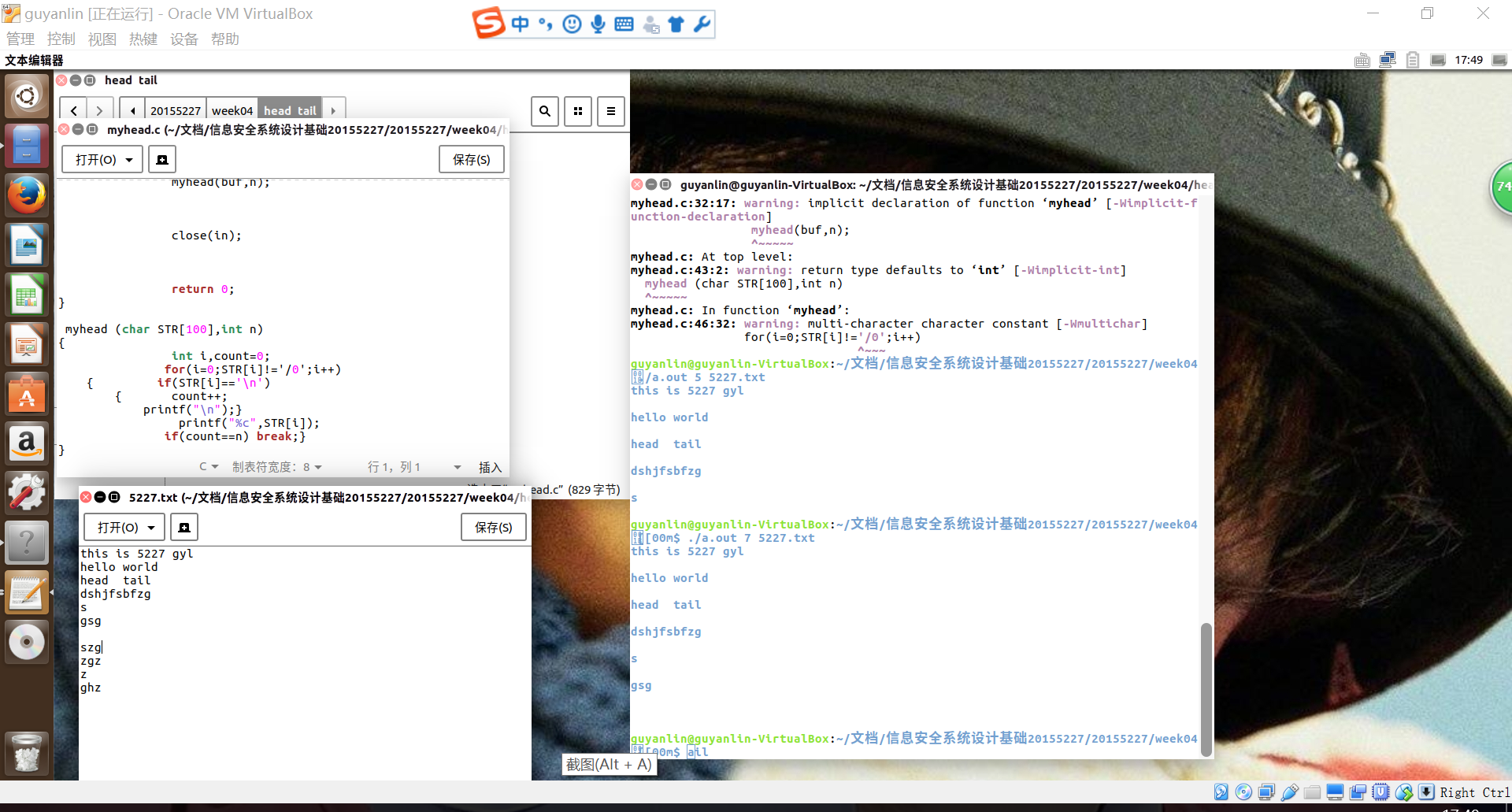
tail命令 从第n行开始显示文件内容
命令:tail -n +5 5227.txt
代码运行截图:
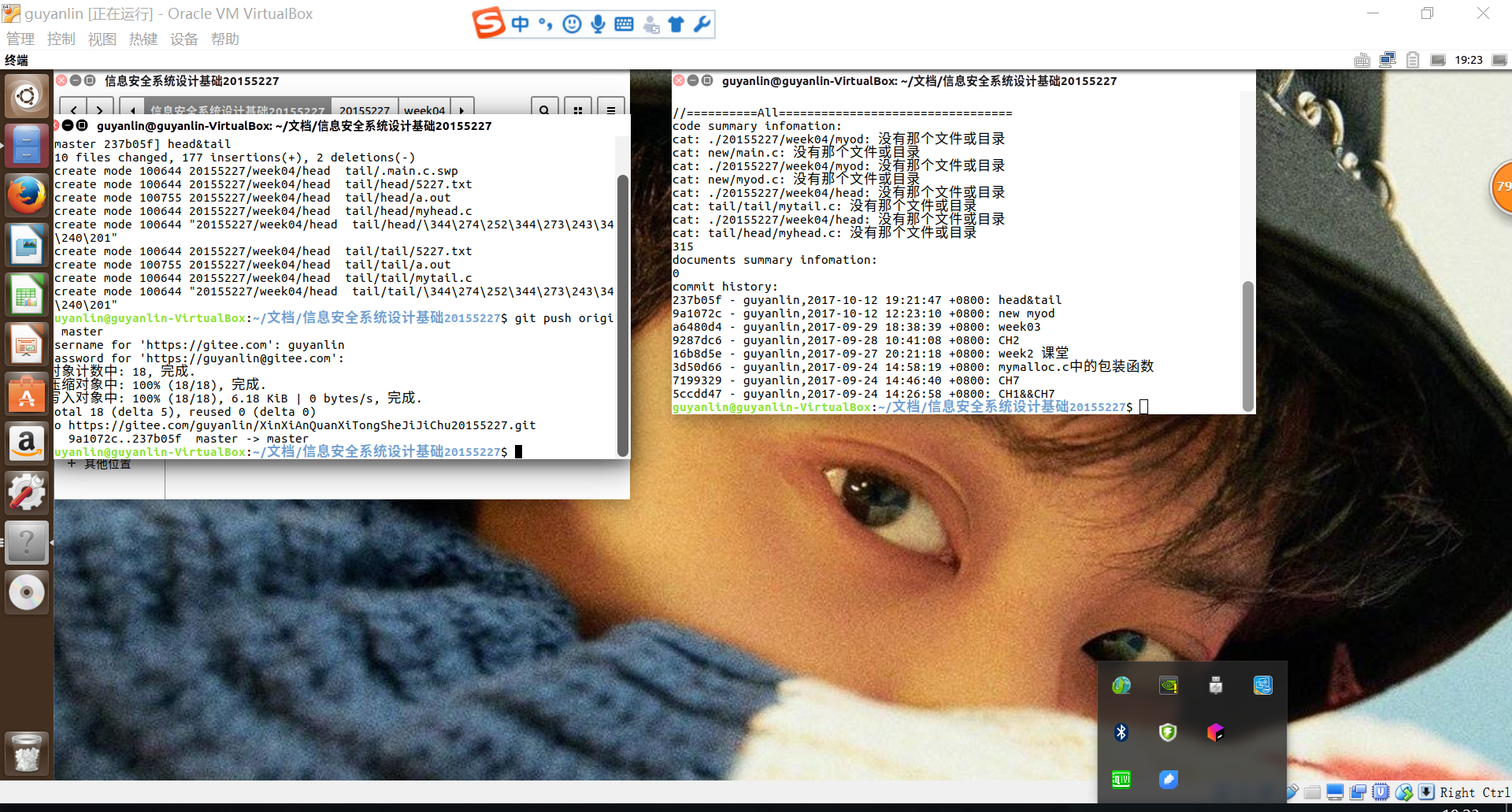
代码托管
(statistics.sh脚本的运行结果截图)