20155227 2016-2017-2 《Java程序设计》第五周学习总结
教材学习内容总结
语法与继承架构
- 使用try...catch
JVM会尝试执行try区块中的程序代码,如果发生错误,执行程序就会比对catch括号中声明的类型,是否符合被抛出的错误对象类型,如果是就执行catch中的程序代码。
使用try、catch语法,JVM会先尝试执行try区块中的代码,如果发生错误就会调理错误发生点,然后比较catch括号中声明类型是否符合被抛出的错误对象类型,如果是就执行catch区块中的代码。
- 异常架构
错误会被包装为对象,这些对象都是可抛出的。设计错误对象都继承自java.lang.Throwable类,Throwable定义了取得错误信息、堆栈追踪等方法,它有两个子类:java.lang.Error与java.lang.Exception。如果某个声明方法会抛出Throeable或子类实例,只要不属于Error或java.lang.RuntimeException或其子类实例,就必须明确使用try、catch语句加以处理,或用throws声明这个方法会抛出异常。
Error与其子类实例代表严重系统错误,Java应用程序本身无力回复。
Exception与其子类实例代表程序设计本身的错误,通常称错误处理为异常处理。受检异常要求明确使用语法加以处理,非受检异常也叫执行时期异常,编译程序不会强迫必须在语法上加以处理。
如果父类异常对象在子类异常对象前被捕捉,则catch子类异常对象的区块永远不会被执行。
catch括号中列出的异常不得有继承关系。
- 自定义异常
让异常更能表现应用程序特有的错误信息,用以更精确地表示出未处理的错误。自定义异常类别时,可以继承Throwable、Erroe或Exception,通常建议继承自Exception或其子类。
- 异常堆栈
得知异常发生的根源以及多重方法调用下异常的堆栈传播。
- printStackTrace 和fillInStackTrace
直接调用一场对象的printStackTrace()是查看堆栈追踪最简单的方法。堆栈追踪信息会显示异常类型,最顶层是异常的根源。
- assert
断言动能,使用assert作为关键字,默认执行时不启动,若要启动,可以在执行java指令时指定-enableassertions或是-ea自变量。
- finally
无论try区块中有无发生异常,若有撰写finally区块,则finally区块一定会被执行。
如果撰写的流程中先return后有finally区块,那finally区块会先执行完后再返回值。
- try with resources
尝试关闭资源语法。尝试自动关闭资源的对象撰写在try之后的括号中,如果无须catch处理任何异常可以不用撰写,也不用撰写finally自行尝试关闭资源。
使用Collection集合对象
- collection架构
目前为止已学过的收集对象的方式是使用object数组。收集对象的行为,如新增对象的add()方法、移除对象的remove()方法等,都是定义在java.util.Collection中。既然能收集对象,也能逐一取得对象,是java.lang.Iterable定义的行为。
收集时记录每个对象的索引顺序,并可依索引取回对象,此行为定义在java.util.List接口中;收集的对象不重复,具有集合的行为,则由java.util.Set定义;收集对象时以队列方式排列,收集的对象加入至尾端,取得对象时从前端,用java.util.Queue;对Queue的两端进行加入、移除等动作,用java.util.Deque。
- List
ArrayList特性:ArrayList搜集对象时使用数组,由于数组在内存中是连续线性空间,根据索引随机存取时速度快,所以适合排序的时候用,可得到较好的速度表现。
LinkedList特性:LinkedList采用了链接结构,每次新增对象后会形成链状结构,链接的每个元素会参考至下一个元素,有利于调整索引顺序。
- Set:判断对象是否重复时会调用hashCode()和equals()方法,且必须同时操作。
- Queue
offer:添加一个元素并返回true,如果队列已满,则返回false。
poll:移除并返问队列头部的元素,如果队列为空,则返回null。
peek:返回队列头部的元素,如果队列为空,则返回null。
- 泛型与继承:设计API时可以指定类或方法支持泛型,会使客户端在语法上更为简洁,并得到编译时期检查。声明与建立对象时使用角括号告知编译程序,只要声明参考时有指定类型,创建对象时就不用再写了。
- Lambda表达式:Request request=()->out.printf("处理数据 %f",Math.random());,Lambda表达式的语法省略了接口类型和方法名称。—>左边是参数列,右边是方法本体,编译程序可以由Request request的声明中得知语法上被省略的信息。可以使用区块{}符号包括演算流程,使用区块时如果方法必须返回值,在区块中就必须使用return。
- Iterable与Iterator
iterator()方法定义在Collection接口中,会返回java.util.Iterator接口的操作对象,这个对象包括了Collection收集的所有对象。可以使用Iterator的hasNext()看看有无下一个对象,若有的话,再使用next()取得下一个对象,因此无论List、Set、Queue还是任何Collection,都可以使用forEach()来显示所收集的对象。增强式for循环还可以运用在操作Iterable接口的对象上,JDK8演进了interface语法,允许接口定义默认方法。
- Comparable与Comparator
sort:Java中对象排序,要么对象实现了Comparable可以直接sort要么提供Comparator对象告知sort如何排序。
键值对应的Map
- 常用的Map操作类为java.util.HashMap与java.util.TreeMap,其继承自抽象类java.util.AbstractMap。Map支持泛型语法,建立Map操作对象时,可以使用泛型语法指定键与值的类型。
- 在hashMap中建立键值对应后,键是无序的。
- 使用TreeMap建立键值对应,则键的部分将会排序,条件是作为键的对象必须操作Comparable接口,或者是在建立TreeMap时指定操作Comparator接口的对象。
- 访问Map键值
- 如果想取得Map中所有的键,可以调用Map的keySet() 返回Set对象。
- 键是不重复的。
- .如果想取得Map中所有的值,则可以使用values()返回Collection对象。如果想同时取得Map的键与值,可以使用entrySet()方法,会返回一个Set对象,每个元素都是Map.Entry实例,可以调用getKey()取得键,调用getValue()取得值。
教材学习中的问题和解决过程
- 1问题
看不太懂Lambda的用法。
- 1解决方案
问了同学之后了解到Lambda表达式的语法省略了接口类型与方法名称,->左边是参数列,而右边是方法本体;在Lambda表达式中使用区方法必须有返回值,在区块中就必须使用return。
代码调试中的问题和解决过程
- 1问题
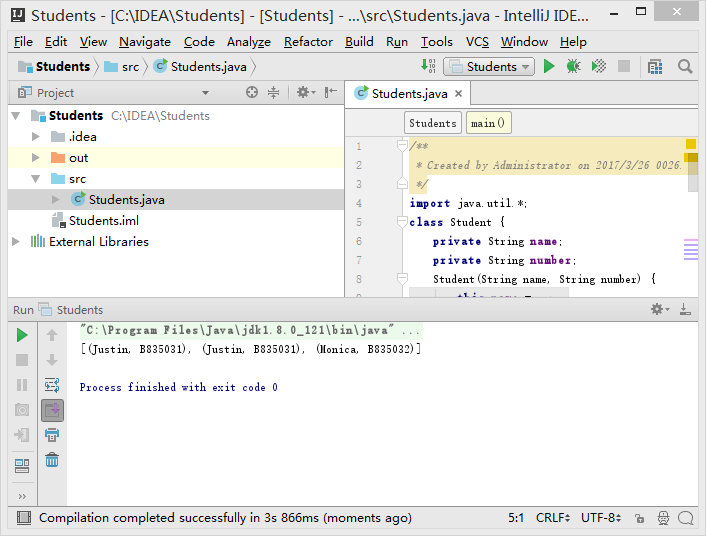
书上p269Students按照书上在IDEA中输入后显示有错误。
import java.util.*;
class Student {
private String name;
private String number;
Student(String name, String number) {
this.name = name;
this.number = number;
}
@Override
public String toString() {
return String.format("(%s, %s)", name, number);
}
}
public class Students {
public static void main(String[] args) {
Set students = new HashSet();
students.add(new Student("Justin", "B835031"));
students.add(new Student("Monica", "B835032"));
students.add(new Student("Justin", "B835031"));
System.out.println(set);
}

- 1解决方案
将最后一行的set改为students之后运行成功。结果为
[(Monica, B835032), (Justin, B835031), (Justin, B835031)
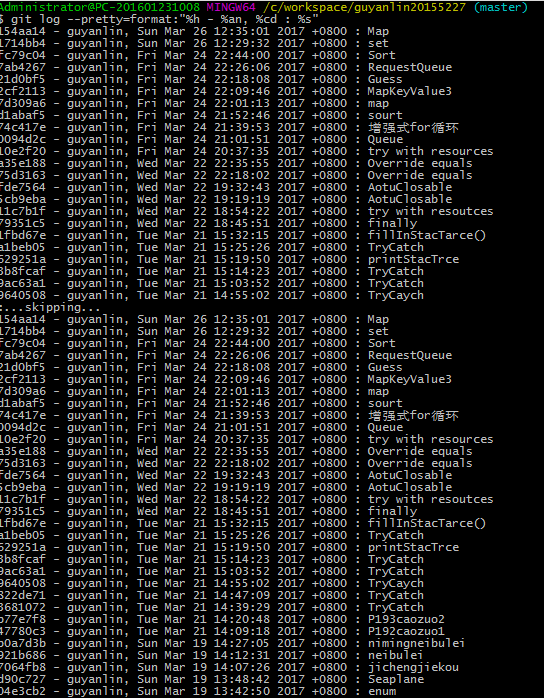
代码托管
- 代码提交过程截图:
- 运行 git log --pretty=format:"%h - %an, %cd : %s" 并截图
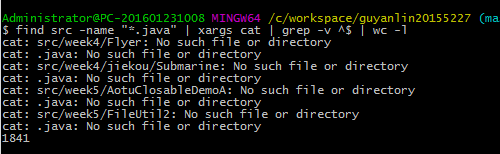
- 代码量截图:
- 运行 find src -name "*.java" | xargs cat | grep -v ^$ | wc -l 并截图
上周考试错题总结
- 错题1:
填空:”Hello”.substring( 0,2 )的值是“He”。
这道题错误的原因是不太清楚substring的用法和定义。
substring() 方法用于提取字符串中介于两个指定下标之间的字符。substring() 方法返回的子串包括 start 处的字符,但不包括 stop 处的字符。
如果参数 start 与 stop 相等,那么该方法返回的就是一个空串(即长度为 0 的字符串)。如果 start 比 stop 大,那么该方法在提取子串之前会先交换这两个参数。与 slice() 和 substr() 方法不同的是,substring() 不接受负的参数。
- 错题2:System.out.println( “HELLO”.( toLowerCase() ) ) 会输出“hello”。
结对及互评
- 与20155213结对
评分标准(满分10分)
-
从0分加到10分为止
-
正确使用Markdown语法(加1分):
- 不使用Markdown不加分
- 有语法错误的不加分(链接打不开,表格不对,列表不正确...)
- 排版混乱的不加分
-
模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
-
教材学习中的问题和解决过程, 一个问题加1分
-
代码调试中的问题和解决过程, 一个问题加1分
-
本周有效代码超过300分行的(加2分)
- 一周提交次数少于20次的不加分
6 其他加分:
- 周五前发博客的加1分
- 感想,体会不假大空的加1分
- 排版精美的加一分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 课后选择题有验证的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
7 扣分:
- 有抄袭的扣至0分
- 代码作弊的扣至0分
点评模板:
-
基于评分标准,我给本博客打分:(0-10)。得分情况如下:xxx
点评过的同学博客和代码
其他(感悟、思考等,可选)
第八章主要是介绍异常情况,以及解决方法。第九章主要是用介绍一些具体的API接口。通过这两周的学习,感觉Java越来越复杂难懂,还是得多花时间,多动脑多动手。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 10/10 | 1/1 | 20/20 | |
| 第二周 | 98/108 | 1/2 | 20/40 | |
| 第三周 | 401/509 | 1/3 | 15/55 | |
| 第四周 | 700/1209 | 1/4 | 20/75 | |
| 第五周 | 632/1841 | 1/5 | 20/95 | 了解Java的异常处理,学习Collection和Map架构 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:30小时
-
实际学习时间:20小时
-
改进情况:还是得多敲代码,也不能只照着书上敲代码,要学着自己写代码。