转:http://blog.csdn.net/xiaoshunzi111/article/details/48198105

由上图可知;写入文件分为三个角色,分别是clientnode namenode 和datanode
cliennode本质为java虚拟机.namenode 和datanode则是Hadoop数据集群存储块
第一步:create实际是客户端创建DistributedFileSystem实例化对象
第二步 create通过实例化对象录取调用对象中create()方法,此方法访问namenode,namenode收到命令,首先判断datanode中所写的文件是否有重复,然后在检查namenode是否有可写入空余的空间.当二者同时满足是,namenode写将datanode路径信息,文件数等记录,并确认信息返回DistributedFileSystem,否则返回异常,DistributedFileSystem收到确认信息后向客户端返回一个FSDataOutputStream FSDataOutputStream对象
第三步:实例化FSDataOutputStream对象(该对象负责处理 datanode 和 namenode 之间的通信 ),调用该对象的write()方法, 即是图中write实现过程该对象负责处理 datanode 和 namenode 之间的通信
第四步:方法将数据分成多个数据包,并写入内部队列. DFDataOutStream 将写入的数据分成多个数据包,并写入内部队列中,同时开启datanode中DataStreamer处理数据队列,它负责根据datanode列来要求namenode分配合适的新块存储数据备份开启管道机制依次执行步骤4,同时即是write packet完整过程
第五步:每执行一次4就有一次步骤5返回确认信息.
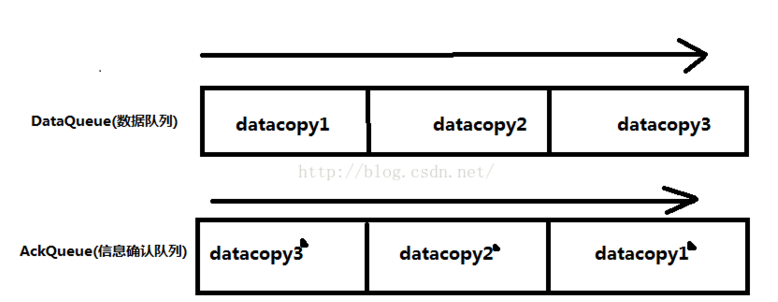
4和5属于分别在DataQueue队列和ACKQueue队列,当每执行一次4就将此步确认信息放到ACKQueue队列中
如图:
第六步:当FSDataOutputStream收到确认信息后,执行close()方法关闭输出流,
第七步:DistributeFileStream 返回给namenode确认信息.
注释:第4-5部分实现在后台完成步不一定在第七步之前,
当执行第四步就就收第5步确认信息,告诉namenode 数据写入成功,即是第七步.