第二章 数据类型 字符编码 文件操作
第三部分
第六节 :数据类型—元祖类型
一、定义:元祖其实跟列表相似:也是一组字符串。不过它一旦创建便不能再修改,又称只读列表

例: >>> names = ("shangnan","wenpeng","longyang","yilong","xiaotian",["liuqiang",22]) >>> names ('shangnan', 'wenpeng', 'longyang', 'yilong', 'xiaotian', ['liuqiang', 22]) #创建元祖列表 >>> names.index("yilong") 3 >>> names[3] = 'xiaodong' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment #发现修改其中的值会报错说元祖类型不可修改 >>> names [-1] ['liuqiang', 22] >>> names [-1][0] = 'linminglong' #但是元祖内的包含的列表元素是可以修改的 >>> names ('shangnan', 'wenpeng', 'longyang', 'yilong', 'xiaotian', ['linminglong', 22]) >>>
第七节 hash (哈希) 函数 (md5文件加密)
用途:①文件签名,②md5加密:特征, 无法反解数据库的验证和(现在所有的网站登录密码,和写网页的源代码,都跟md5加密有关;典型的支付宝的用户验证)③密码验证:支付宝的数据库就是密文密码,无法反解(你在输入密码的时候,会被加密成密文和数据库的密文,能否登录取决于是否相等)
例: >>> hash('yilong') 1988588325535353625 #哈希字符串会返回加密文 >> hash('1,4,5,') -8005653040755405875 >>> hash(('A','C')) #哈希元祖类型 -7870207913792714445 >>> hash((['lingdong','mac']) SyntaxError: invalid syntax #哈希列表会报错,因为列表属于可变类型,而被哈希的必须是不可变的
第八节 : 数据类型—字典的特性和详细用法
1.字典的特性:
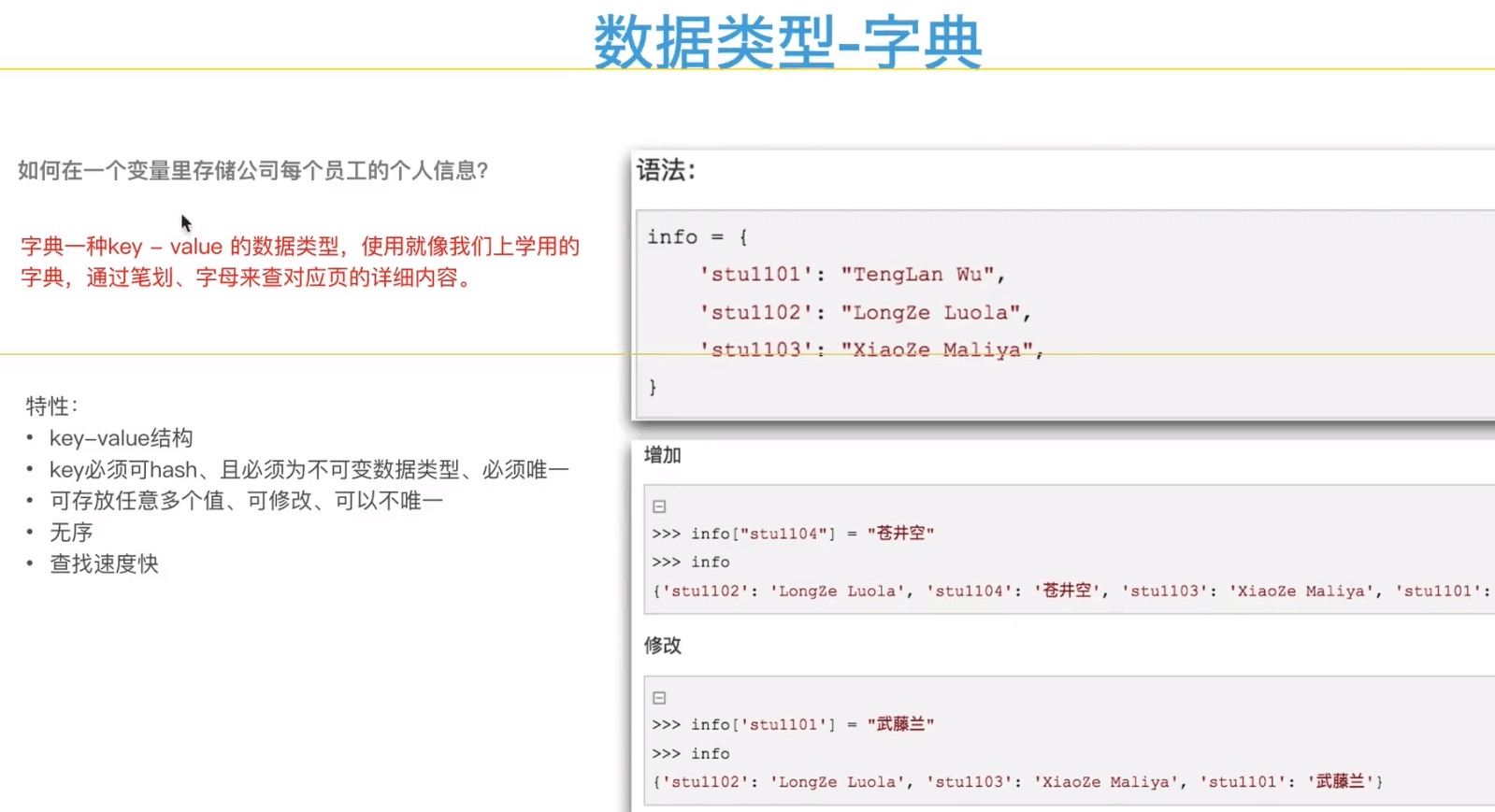
***代码来两行验证下:
例: >>> info = { ... '龙凤':[22,'公安','青'], ... '刘强':[16,'出差d'], #这就是完整的创建字典类型格式 ... '包安':[18,'ddd'], ... } >>> info {'龙凤': [22, '公安', '青'], '刘强': [16, '出差d'], '包安': [18, 'ddd']}
*****字典的特性重要的是必须可哈希:唯一的值不可重复,查找速度快是因为每输进去的字符串都被哈希成了数字串,
2.字典的用法:
*查询字典信息:
例: {'龙凤': [22, '公安', '青'], '刘强': [16, '出差d'], '包安': [18, 'ddd']} >>> info['刘强'] #跟查询列表索引一样格式,直接输入key [16, '出差d']
**修改字典信息:
例: >>> info {'龙凤': [22, '公安', '青'], '刘强': [16, '出差d'], '包安': [18, 'ddd']} >>> info['龙凤'][2] = '商业' #跟列表一样找到对应索引,直接赋值 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd']} >>>
***增加
例: >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd']} >>> info['千峰'] = '22,' #可以单独增加 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,'} >>> info['日本'] = [18,'东京'] #也可增加对应列表 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', '日本': [18, '东京']} >>>
**************还有一种新的增加语法—批量增加****************
例: >>> info {} >>> range(100) range(0, 100) >>> for i in range(100): ... info[i] = i*i ... >>> info {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100, 11: 121, 12: 144, 13: 169, 14: 196, 15: 225, 16: 256, 17: 289, 18: 324, 19: 361, 20: 400, 21: 441, 22: 484, 23: 529, 24: 576, 25: 625, 26: 676, 27: 729, 28: 784, 29: 841, 30: 900, 31: 961, 32: 1024, 33: 1089, 34: 1156, 35: 1225, 36: 1296, 37: 1369, 38: 1444, 39: 1521, 40: 1600, 41: 1681, 42: 1764, 43: 1849, 44: 1936, 45: 2025, 46: 2116, 47: 2209, 48: 2304, 49: 2401, 50: 2500, 51: 2601, 52: 2704, 53: 2809, 54: 2916, 55: 3025, 56: 3136, 57: 3249, 58: 3364, 59: 3481, 60: 3600, 61: 3721, 62: 3844, 63: 3969, 64: 4096, 65: 4225, 66: 4356, 67: 4489, 68: 4624, 69: 4761, 70: 4900, 71: 5041, 72: 5184, 73: 5329, 74: 5476, 75: 5625, 76: 5776, 77: 5929, 78: 6084, 79: 6241, 80: 6400, 81: 6561, 82: 6724, 83: 6889, 84: 7056, 85: 7225, 86: 7396, 87: 7569, 88: 7744, 89: 7921, 90: 8100, 91: 8281, 92: 8464, 93: 8649, 94: 8836, 95: 9025, 96: 9216, 97: 9409, 98: 9604, 99: 9801} >>>
**判断与获取:
例: **判断 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', '日本': [18, '东京']} >>> '刘强' in info #判断名字是否在字典内 True #在返回True 不在返回False ***获取 >>> info.get('日本') #第一种用法 get (常用语法,因为方便不会报错)(推荐) [18, '东京'] >>> info.get('日本1') #如果没有什么不返回 >>> print(info.get('日本1')) #看下结果 None #返回的英文意思是什么都没有 ****第二种: >>> info['龙凤'] [22, '公安', '商业'] >>> info['龙凤1'] #如果没有就会报错导致程序不能正常运行(不推荐) Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: '龙凤1'
*****清空、 删除:指定删、随机删以及全局删。
例: >>> info {0: 2401, 50: 2500, 51: 2601, 52: 2704, 53:5555} {} #已清空
**删除
例: **指定删除 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', '日本': [18, '东京']} >>> info.pop('日本') #指定删除输入删除的 key [18, '东京'] #删除同时返回要删除的值 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,'} #已被删除 ***随机删 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} >>> info.popitem() (2, 1) >>> info.popitem() (6, 1) >>> info.popitem() #随机删是无序的 (8, 1) >>> info.popitem() ('千峰', '22,') >>> info.popitem() ('包安', [18, 'ddd']) >>> info.popitem() ('刘强', [16, '出差d']) >>> info.popitem() ('龙凤', [22, '公安', '商业']) #字典删除完了会报错
***全局删:和列表一样,del
例:>>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} >>> del info['千峰'] #输入删除的key。 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], 8: 1, 6: 1, 2: 1}
****多级字典嵌套:就是字典里面套字典,查找和修的时候也是根据每一个 key一级一级找和修改
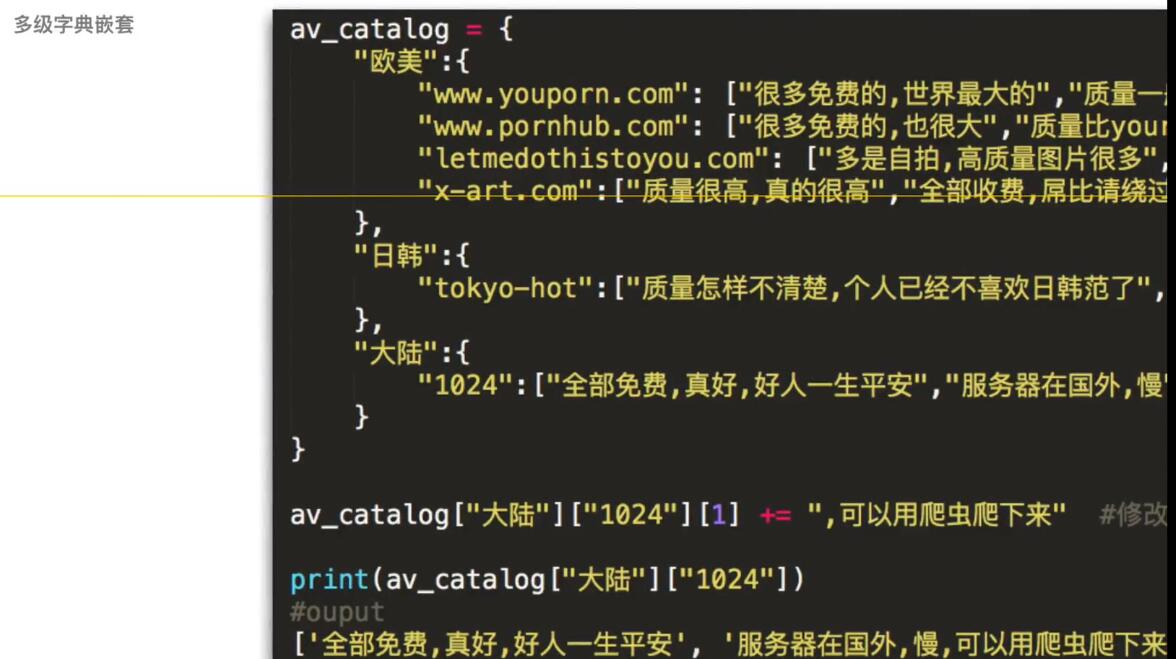 2
2
********其他方法
例: *copy(拷贝) >>> n2 = info.copy() #拷贝 n2 >>> n2 {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} **返回字典 key (索引) >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} >>> info.keys() #返回 key 的语法 dict_keys(['龙凤', '刘强', '包安', '千峰', 8, 6, 2]) ***返回字典对应的 value (值)3 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} >>> info.values() #返回 value 值得语法 dict_values([[22, '公安', '商业'], [16, '出差d'], [18, 'ddd'], '22,', 1, 1, 1]) ****把 key 和 value 变成元祖 放进列表内 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} >>> info.items() dict_items([('龙凤', [22, '公安', '商业']), ('刘强', [16, '出差d']), ('包安', [18, 'ddd']), ('千峰', '22,'), (8, 1), (6, 1), (2, 1)]) *****扩展(2合1) >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1} >>> n {11: 'aaa', 22: 'bb', 33: 'cc', '千峰': '22,'} >>> info.update(n) >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1, 11: 'aaa', 22: 'bb', 33: 'cc'} #已经合并,重复的值覆盖,没有对应的自动生成 ******查找与创建 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1, 11: 'aaa', 22: 'bb', 33: 'cc'} >>> >>> info.setdefault(8,19) #找到 key 就会返回对应的值,不会修改 1 >>> info.setdefault('刘明','梁山') #找不到 key 就会重新创建 '梁山' >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1, 11: 'aaa', 22: 'bb', 33: 'cc', '刘明': '梁山'} *******生成字典并批量赋值 >>> info.fromkeys(['a','b','c'],'dit') {'a': 'dit', 'b': 'dit', 'c': 'dit'}
*最后**字典的循环**循环有2种方法
例: *第一种: #常用循环方法 >>> info {'龙凤': [22, '公安', '商业'], '刘强': [16, '出差d'], '包安': [18, 'ddd'], '千峰': '22,', 8: 1, 6: 1, 2: 1, 11: 'aaa', 22: 'bb', 33: 'cc', '刘明': '梁山'} >>> for k in info: ... print(k,info[k]) ... 龙凤 [22, '公安', '商业'] 刘强 [16, '出差d'] 包安 [18, 'ddd'] 千峰 22, 8 1 6 1 2 1 11 aaa 22 bb 33 cc 刘明 梁山 第二种: >>> for k,v in info.items(): #低效的循环方法:因为需要先把字典变成列表再去循环, ... print(k,v) ... 龙凤 [22, '公安', '商业'] 刘强 [16, '出差d'] 包安 [18, 'ddd'] 千峰 22, 8 1 6 1 2 1 11 aaa 22 bb 33 cc 刘明 梁山
**************************字典、列表是以后只要写程序都会用到的东西,一定要熟悉******************************
第九节 数据类型 — 集合 与 集合关系测试
一、集合的特征与语法

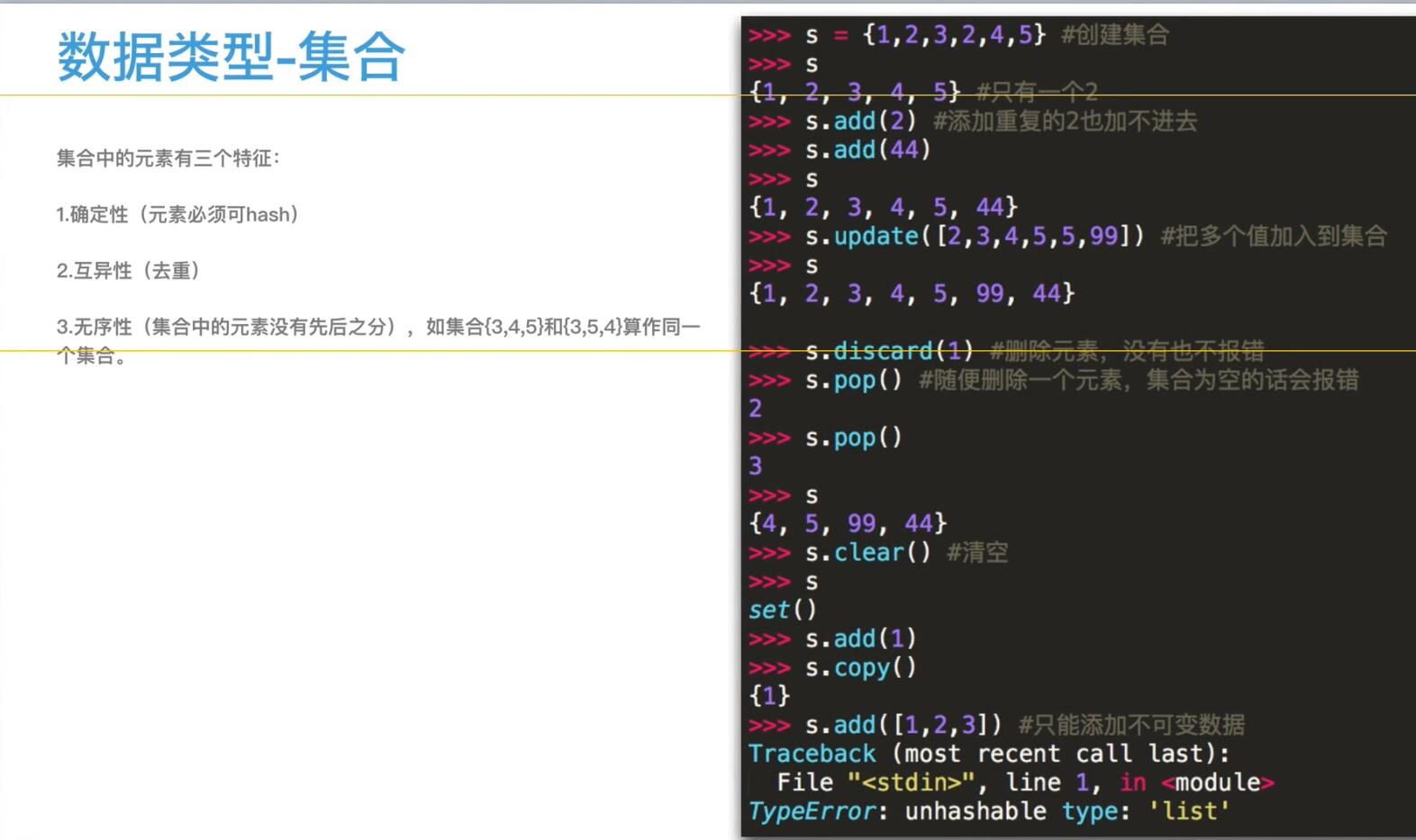
1.集合的语法:语法有两种
****下面一一验证下:
例: *第一种:直接创建 >>> s = {1,2,3,5,5,7,4,1,8,5} #集合语法,与字典相似,输入相同数值 >>> s {1, 2, 3, 4, 5, 7, 8} #发现相同的已经覆盖,因为集合的特点就是去除重复的 **第二种:其他类型转集合(列表、元祖)
1.列表转集合
>>> m = [1,4,7,2,5,6,3,2,1,4,7,9] >>> m [1, 4, 7, 2, 5, 6, 3, 2, 1, 4, 7, 9] >>> set(m) {1, 2, 3, 4, 5, 6, 7, 9} #转集合新语法,发现也覆盖重复数据 >>> k = set(m) >>> k {1, 2, 3, 4, 5, 6, 7, 9}
2.元祖转集合
>>> n = (1,7,8,5,4,12,3,9,2,5,8,4)
>>> n
(1, 7, 8, 5, 4, 12, 3, 9, 2, 5, 8, 4)
>>> v = set(n)
>>> v
{1, 2, 3, 4, 5, 7, 8, 9, 12}
2.集合的 增、删、改、查
****下面用代码验证下:
例: 1.增加与扩展 * 增加 >>> s {1, 2, 3, 4, 5, 7, 8} >>> s.add(5) #增加重复的值会被覆盖 >>> s {1, 2, 3, 4, 5, 7, 8} >>> s.add(6) >>> s {1, 2, 3, 4, 5, 6, 7, 8} #要增加不重复的值 ** 扩展(合并或增加多个值) >>> s {4,5, 6, 8} >>> s.update([1,2,3,5,6,8]) #可增加一个列表的值 >>> s {1, 2, 3, 4, 5, 6, 8} 2.随机删除,指定删除 * 随机删 >>> s {1, 2, 3, 4, 5, 6, 7, 8} >>> s.pop() #一般不用的语法 1 >>> s.pop() 2 >>> s.pop() #注意:因为集合是无序的,所以他的随机删也是无序的 3 ** 指定删除分两种: * 指定删除:第一种 >>> s {4,5,6,7,8} >>> s.remove(7) #常用语法 >>> s {4,5, 6, 8} **指定删除:第二种 >>> s.discard(7) #与上一种删除的区别是:上一种删除不存在的会报错,这一种有就删除,没有就略过,不会报错 >>> s {4,5, 6, 8} 3.清空 >>> s {1, 2, 3, 5, 6, 8} >>> s.clear() >>> s set()
二、集合的关系测试:集合的重点
*****图例:
1.交集与 差集
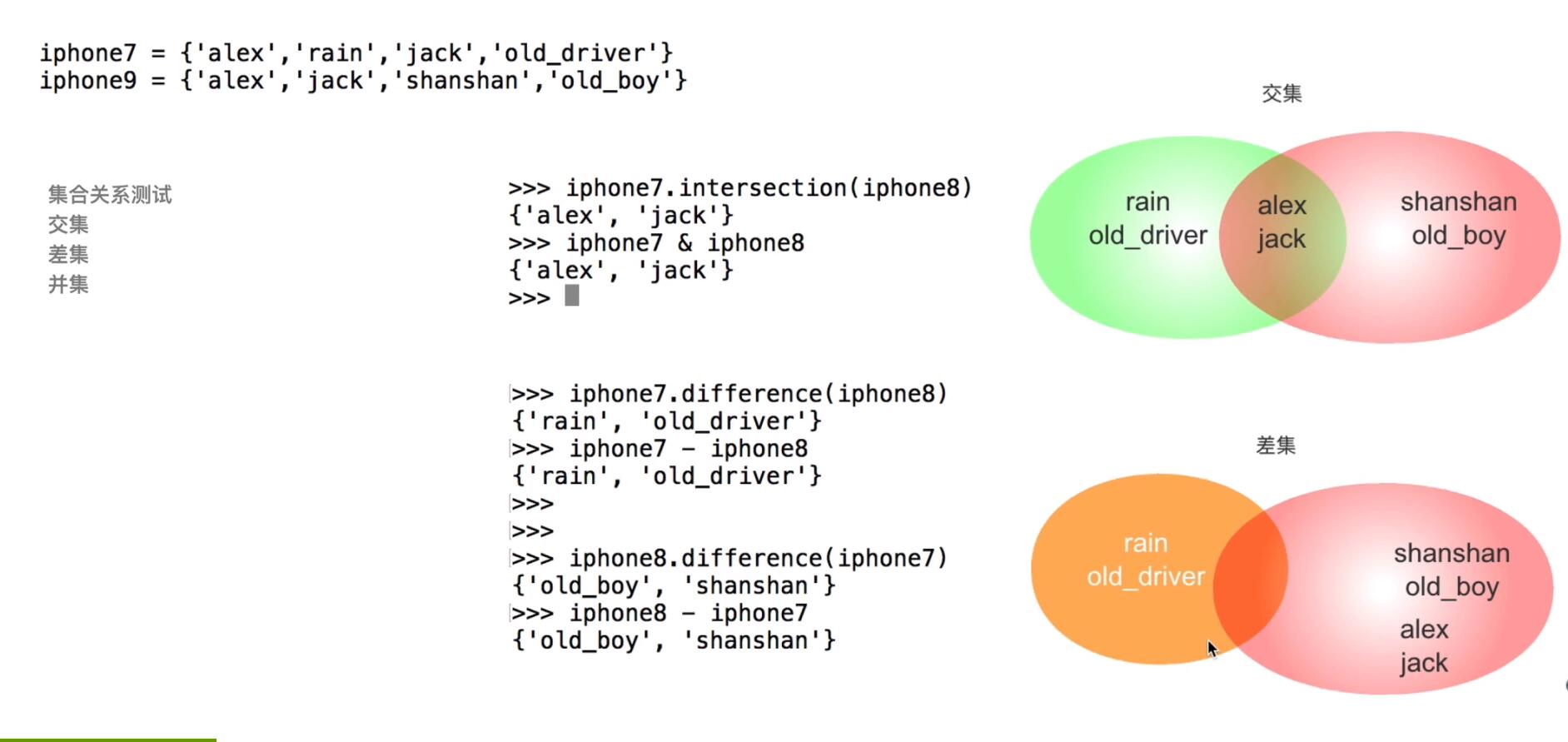
交集、差集****代码验证
例: 1.交集(&) >>> s {1, 2, 3, 5, 6, 8} >>> s2 {0, 5, 6, 7, 8, 9, -1} s >>> s&s2 #语法(&)可以直接取出交集 (简单方便) 两个集合部分左右谁都可以 & {8, 5, 6} >>> s.intersection(s2) #也是集合的语法,两个集合部分左右谁都可以 intersection {8, 5, 6} 2.差集(-) >>> s {1, 2, 3, 5, 6, 8} >>> s2 {0, 5, 6, 7, 8, 9, -1} >>> s - s2 #直接相减取差集,很方便 {1, 2, 3} >>> s2 - s {0, 9, -1, 7} >>> >>> s.difference(s2) #用语法取 s 与 s2 的差集 {1, 2, 3} >>> s2.difference(s) #s2 与 s 的差集 {0, 9, -1, 7}
2.并集
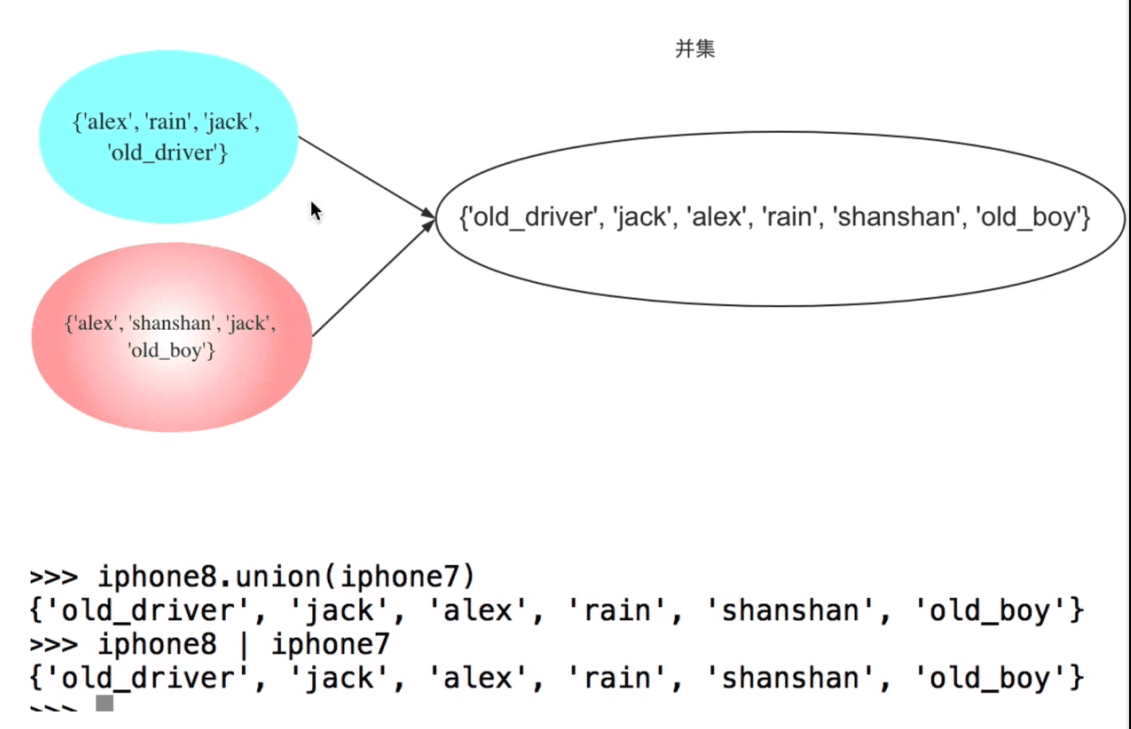
并集***代码验证
例: >>> s {1, 2, 3, 5, 6, 8} >>> s2 {0, 5, 6, 7, 8, 9, -1} >>> s.union(s2) {0, 1, 2, 3, 5, 6, 7, 8, 9, -1} #新语法谁都可以在前面,不分左右 >>> s | s2 {0, 1, 2, 3, 5, 6, 7, 8, 9, -1} #(“|”称之为:管道符)简单快捷的语法,不分左右
3.对称差集

对称差集***代码验证
例: >>> s {1, 2, 3, 5, 6, 8} >>> s2 {0, 5, 6, 7, 8, 9, -1} >>> s.symmetric_difference(s2) #新语法:取出两者不相交的总和,不分左右 {0, 1, 2, 3, 7, 9, -1} >>> s ^s2 # (^ )简单快捷的语法,不分左右 {0, 1, 2, 3, 7, 9, -1}
4.超集与子集:包含关系

超集与子集 以及其他方法****代码验证
例: 1.判断是否不相交 >>> s {1, 2, 3, 5, 6, 8} >>> s2 {0, 1, 2, 3, 5, 6, 7, 8, 9, -1} >>> s2.isdisjoint(s) #判断是否不相交 False 2.判断是否为对方的子集或父集 >>> s {1, 2, 3, 5, 6, 8} >>> s2 {0, 1, 2, 3, 5, 6, 7, 8, 9, -1} >>> s2.issuperset(s) #判 s2 是否是 s 的父集 True >>> s.issuperset(s2) #相反判断 False >>> s2.issubset(s) #判断 s2 是否是 s 的子集 False >>> s.issubset(s2) #相反判断 True **便捷方法 **(>=/<=) >>> s2>=s #( >= / <= )简单便捷的方法 True >>> s<=s2 True 3.其他方法 >>> s.difference_update(s2) #把不相交的值赋给一方 >>> s {11, -4} >>> s2 {0, 1, 2, 3, 5, 6, 7, 8, 9, -1}