python全栈开发笔记第二模块
第三部分 :递归、内置函数
一、递归定义及使用
1、递归基础
定义:什么叫递归?递归就是在函数的执行中调用自己
下面代码举例说明:
例: def recursion(n): #设置计数 print(n) #为了能验证调用自己多少次,打印计数 recursion(n+1) #每次执行完加一 recursion(1)
执行代码结果: 1 2 3 #每执行一次就会+1,就像 for 循环(循环到边界)
....... 996 997 998raceback (most recent call last): RecursionError: maximum recursion depth exceeded while calling a Python object #发现报错,报错的意思是说递归到了最大 极限(系统默认1000次,除去上下被执行的2次,正好998次)
查看系统默认递归层:
例: import sys #导入python工具箱 sys print(sys.getrecursionlimit()) #打印系统默认递归层 def recursion(n): #再次执行 print(n) recursion(n+1) recursion(1)
执行代码结果: 1000 #打印系统默认递归层是1000次 1 2 3 #每执行一次就会+1,就像 for 循环(死循环到边界) ....... 996 997 998raceback (most recent call last): RecursionError: maximum recursion depth exceeded while calling a Python object
修改系统默认递归层:
例: import sys #导入python工具箱 sys print(sys.getrecursionlimit()) #打印系统默认递归层 sys.setrecursionlimit(1500) #系统默认递归层修改方法(修改成1500) def recursion(n): print(n) recursion(n+1) #再次执行 recursion(1)
执行代码结果: 1 2 ....... 996 ...... 1497 #发现已经修改了设置递归层 (1500) 1498raceback (most recent call last): RecursionError: maximum recursion depth exceeded while calling a Python object
为什么限制递归次数,因为函数在递归执行的过程中,
都是占用系统运行内存的(函数只有执行完才会释放内存,因为递归就是执行函数本身 ,所以,是执行不完的)
一旦达到内存极限,就会导致吧系统内存撑爆,所以限制了递归次数
2、递归与栈的关系
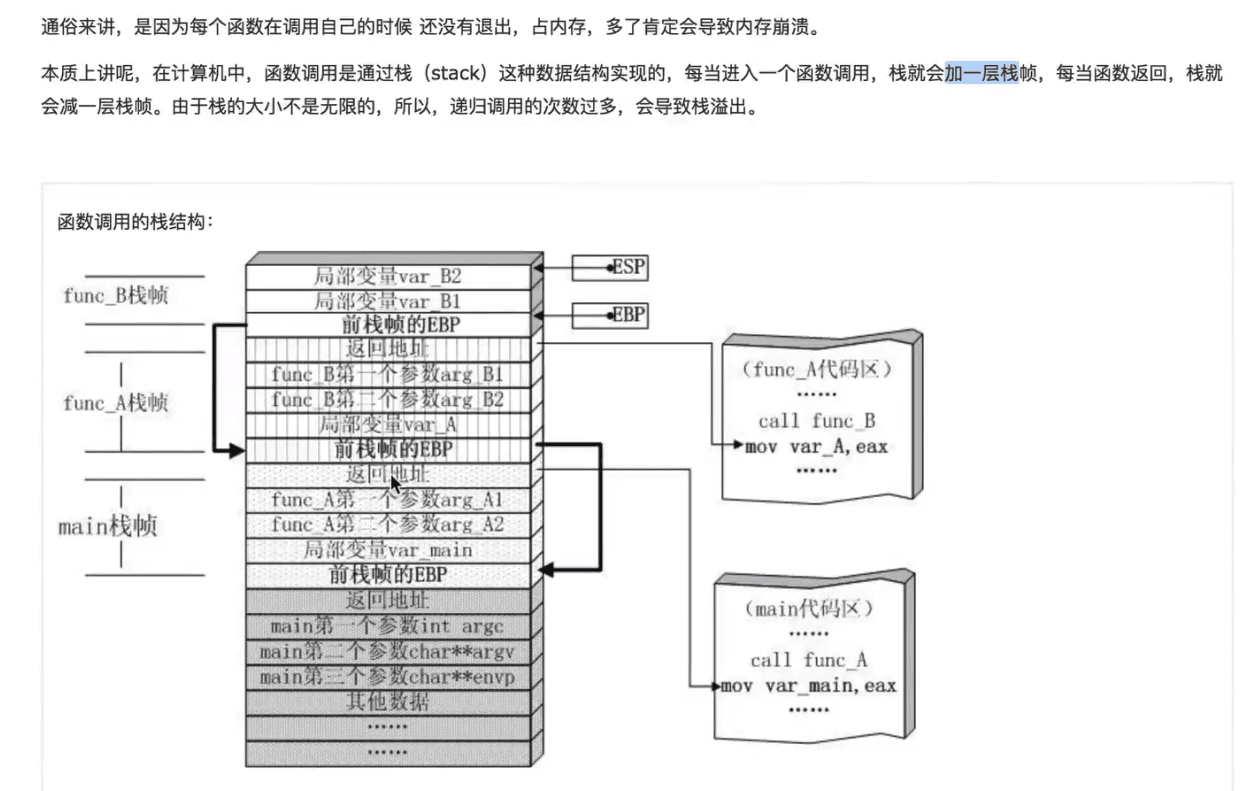
在计算机中,函数的调用时通过栈来实现的。
栈 :是一个概念词,不是真实存在的,是一个数据结构。他就像一个弹弹匣,有一定的限制,
每执行一次函数,就会往栈内压缩一次,就像往弹匣内压一颗子弹一样,一旦达到限制就会导致栈溢出。就是太满,会撑爆内存
下面一张图了解栈
3、递归的作用(一)
递归可以解决很多复杂的数学问题,在函数领域的作用就像 while 循环,
下面用代码举例说明:
#递归的作用 #递归可以解决很多复杂的数学问题,在函数领域的作用就像 while 循环, #一个需求实现递归的作用 # 10 整除 2 直到 0 为止 def calc(n): v = int(n/2) #设置公式 print(v) if v == 0: #增加判断 return "OK" #条件成立递归终止(return为递归的终止语句) calc(v) #递归 print(v) #打印反向值 calc(10) #传入参数
执行代码结果: 5 2 1 0 #整除 0 退出做到了,但是为什么会打印反向值呢?下一节解释 1 2 5
上一个题为什么会出现反向打印值,下面一张图揭晓
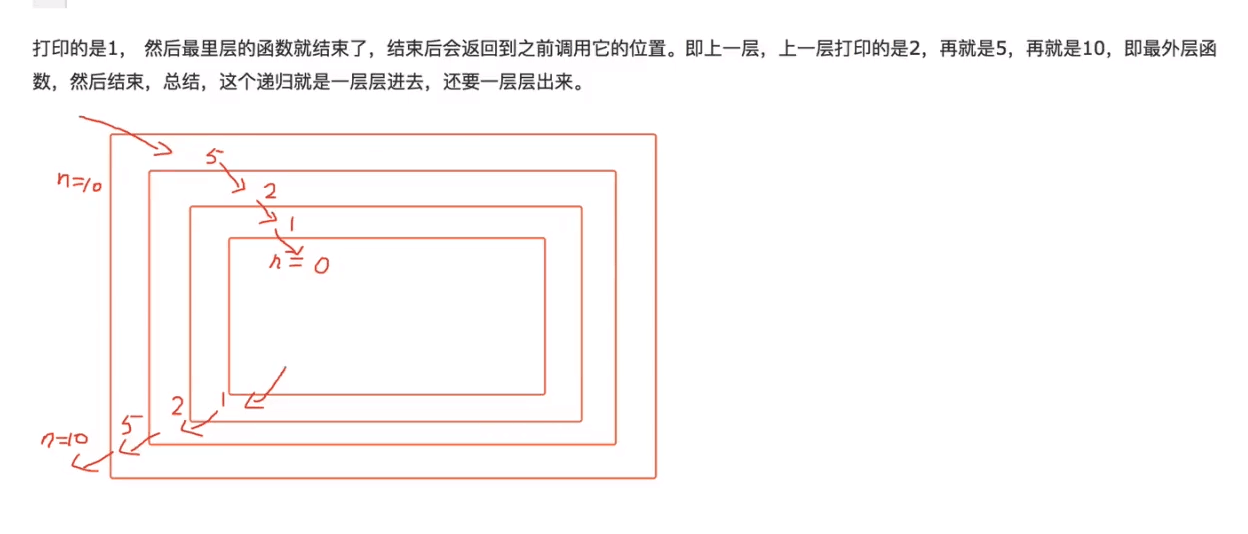
如图所示:
函数中,递归执行的中心点是在判断条件成立和 return 返回值的地方,
所以会形成以条件成立为中心向外辐射,先层层传进直到条件成立,再层层退出
形成 5 2 1 0中心点 1 2 5 这样的反射
***递归特性小结:
-
-
- 每一个正常的递归,都要有边界,都要有明确的判断条件,因为递归是无限制的,如果不设边界,会导致内存崩溃或者报错
- 每次进入更深一层递归时,问题规模相比上一层递归,都要有所减少(每进入更深一层递归,问题规模的圈子就要更集中,更小)
- 递归执行效率不高,慎用,递归层次过多会导致栈溢出
-
4、递归的作用(二)
递归的作用很多:求斐波那契数列、汉诺塔、多级评论树(这几个数据结构比较复杂,以后学的深入会讲)、二分查找、求阶乘等等。
求阶乘 任何大于1的自然数 n 阶乘方法公式:n! = 1 * 2 * 3 * 4 *......* n 或 n! = n * (n-1)! 例:4!= 4 * 3 * 2 * 1 = 24 就是说,4 的阶乘就等于 3 阶乘的和再乘以 4 以此类推(总体意思就是说先要把最小的阶乘算出来,依次往大乘)
下面代码验证下:
def factorial(n): if n == 1: #加判断,否则会报错 return 1 return n * factorial(n-1) # n! = n * (n-1)! print(factorial(10))
执行代码结果:
3628800
5、尾递归优化
递归执行效率低,会导致栈溢出,解决这个办法的方式就是尾递归优化。
函数的递归效率低是因为在函数每执行一层,就会把数据存进栈,等下一层调用,
优化的代码格式:
例: def calc(n): print(n) return calc(n+1) #如果这样写代码,直接返回上一层的结果,这层的执行就会与上一层没关系,
#这样,上一层就不会被调用,可以释放空间,只要保存当前层的数据即可 calc(1) #求阶乘,不属于尾递归优化,因为他的一些数据是活的,必须是上一层计算结果
注意:尾递归优化,不是所有语言都支持, c 语言有优化,
在python语言里是没有直接作用的,因为python语言没有优化,它是一个技术概念,
JS 是有尾递归优化的,不存在效率低递归不是所有场景都用你管得到,但是我们要知道
二、函数--内置方法
1、基本内置函数:
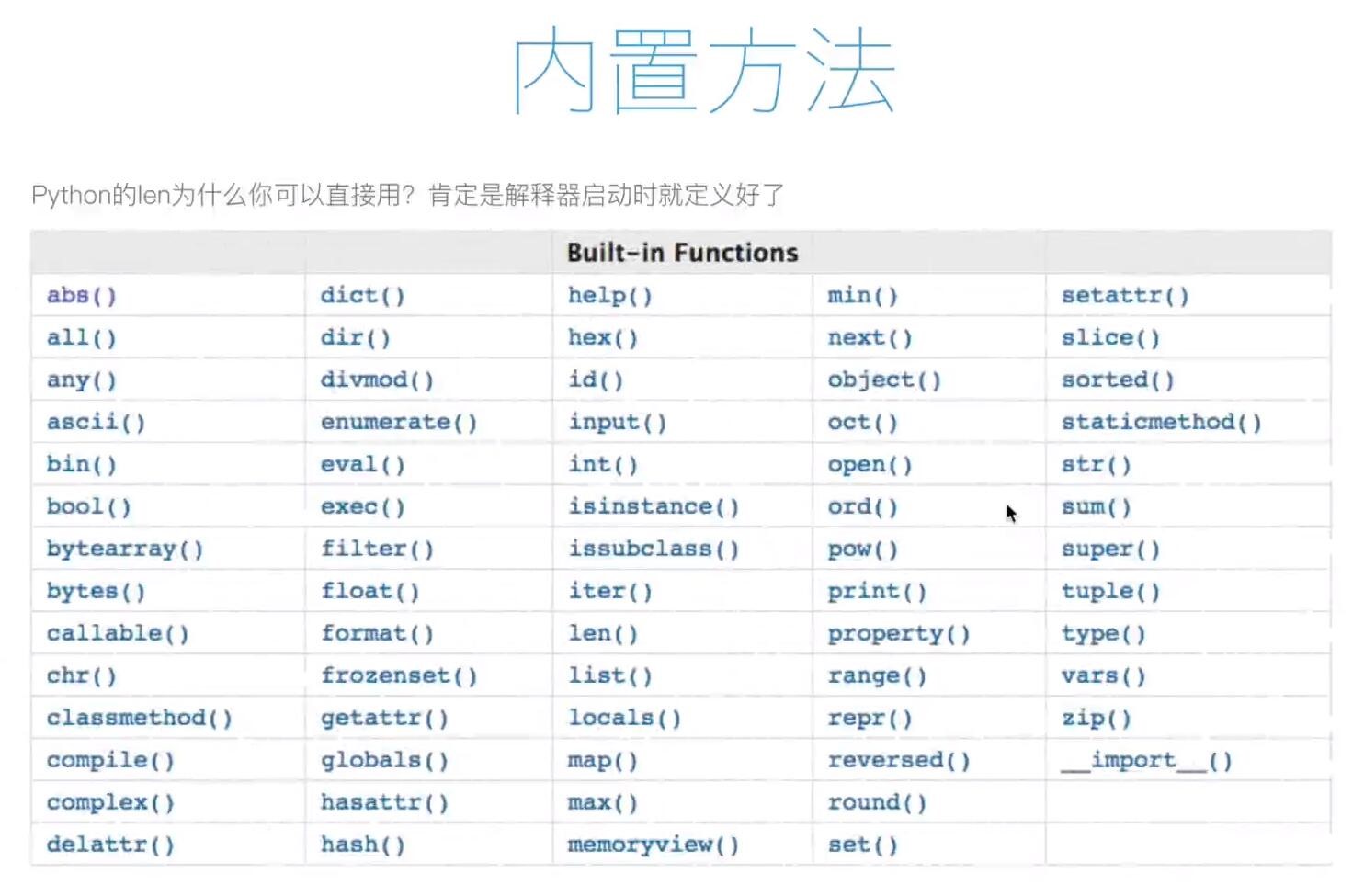
在python里,len(读取长度) 、str(字符串)、type(查看类型)、int(变成整数)
之所以能用这些,是因为调用了 python 里的内置函数,函数要调用需先定义,之所以这些不用定义,
是因为这些都是 python 里的内置函数(python 解释器系统定义好的),都有哪些呢?
下面一一对应作用:
abs() 绝对值,(负数也会以正数来表示)
dict() 把数据转成字典
help() 内置帮助功能(如果语法不会,可以在 python 解释器中 help(要帮助的语法))
min() 返回数据中最小的值
>>> s = [1, 2, 80, 5, 11, -8] >>> min(s) # min 一下 s -8 #返回了最小的值
max() 相反,返回数据中最大的值
bool() 判断是否布尔类型(布尔,所有的数据类型都自带布尔值,只有在0 、 None 或者 list、dict、set、tuple为空的时候返回 False)
*a l l() 判断如果 bool()返回什么 all()就返回什么(除了空列表不同 bool 返回 False ,all 返回 True,只要有一个是错误的,都会返回 False )
*any() 判断 bool() 里面的每个值,只要有一个对的,就会返回 True ,(False和 0 都是错的)
***********************以上两个经常会用,判断数据集合内的真与假,请牢记*****************************
dir() 打印当前程序中的所有变量名(包括 python 解释器自带变量)
hex() 以 十六 进制显示数字
slice() 切片格式化
>>> l = list(range(10)) #定义一个列表 >>> l [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> s = slice(1,7) #定义切片范围 >>> l[s] #应用 [1, 2, 3, 4, 5, 6] #返回切片值
divmod() 写进去相除的2个值,会返回整除值 和 余数值
>>> divmod(17,3) #写进要相除的两个数 (5, 2) #返回整除值和余数
id() 返回内存地址
sorted() 排序,可自定义排序规则(默认从小到大,也可语法实现反转)
>>> t #设定字典变量 {0: -22, 1: -21, 2: -20, 3: -19, 4: -18, 5: -17, 6: -16, 7: -15, 8: 55, 9: -13, 10: -12,
11: -11, 12: -10, 13: -9, 14: -8, 15: -7, 16: -6, 17: -5, 18: 66, 19: -3} >>> sorted(t.items(),key=lambda x:x[1]) #通过语法实现默认排序(按照value排序,默认是 key 排序) [(0, -22), (1, -21), (2, -20), (3, -19), (4, -18), (5, -17), (6, -16), (7, -15), (9, -13), (10, -12),
(11, -11), (12, -10), (13, -9), (14, -8), (15, -7), (16, -6), (17, -5), (19, -3), (8, 55), (18, 66)] >>> sorted(t.items(),key=lambda x:x[1],reverse = True) #通过语法实现 value 反转排序 [(18, 66), (8, 55), (19, -3), (17, -5), (16, -6), (15, -7), (14, -8), (13, -9), (12, -10), (11, -11),
(10, -12), (9, -13), (7, -15), (6, -16), (5, -17), (4, -18), (3, -19), (2, -20), (1, -21), (0, -22)]
ascii() 除了ASCII 码表内的字符正常显示,其他字符转成 unicode 编码格式的二进制
>>> s = "abs毅龍" >>> ascii(s) "'abs\u6bc5\u9f8d'"
enumerate() 枚举,循环返回列表的索引值
input() 获取用户输入
oct() 返回整数的 8 进制格式
bin() 返回整数的二进制格式
eval() 按解释器规则把少量代码解析执行(处理单行代码)(能拿到返回值)
exec() 把多行代码解析执行(处理多行代码)(拿不到返回值)
print(exec("1+2*5")) #用exec 可以执行多行代码,但是拿不到返回值 print(eval("1+2*5")) #用eval 可以执行少量代码,但是能拿到返回值
int() 将数字或字符串转换成整数
open() 打开文件
str() 转换字符串
ord() 返回字符在 ASCII 码表对应数字
chr() 返回数字在 ASCII 码表对应字
sum() 求和
>>> a (1, 8, -4, 22, 58, 33, 5552, -5555, 444) >>> sum(a) 559
bytearray() 不开辟内存地址修改字符串
s = "aasd,路飞" s = s.encode('utf-8') #先转换代码 s = bytearray(s) s[5] = 233 s[2] = 116 #修改字符串 s[6]= 185 s = s.decode() print(s)
map() 执行传进去的函数计算公式和数值
print(list(map(lambda x:x*x, [1,4,5,2,6,8,7]))) # map 内传进去2个参数
filter() 过滤,拿出想要的值
print(list(filter(lambda x: x>3, [0.5,1,2,1,5,8,99,6,4,3]))) # filter 内传进去2个参数
reduce () 可设置一个函数公式让两个参数相加或相乘
import functools #需导入工具包 f = functools.reduce(lambda x,y:x+y,[1,2,5,8,7,4,]) #可以是2个数相乘(累乘) f1 = functools.reduce(lambda x,y:x+y,[1,2,5,8,7,4,],77) #可设置两个参数 print(f,f1)
pow() 返回值的次方
bytes() 字节类型
float() 浮点类型
print() 打印除了打印,打印完自动换行,有很多参数,
可以设置结尾去除默认换行(end=) 可以设置字符串间的连接(sep=) 还可直接把数据打印到文件内
1、(end=) s = "hello my name is Guoyilong age 28 join lambda " s1 = print(s,end="ss")
执行代码结果: hello my name is Guoyilong age 28 join lambda s
2、 (sep=) print("wages","names",sep="->") #需传进去2个值 和 sep="连接"
执行代码结果:
wages->names
(3) 直接把数据打印到本地文件 msg = "缺少奋斗的人,是没有理想的" f = open("print_tofilee","w") #在pycharm 内创建文件 print(msg,"缺少毅力的人,即使奋斗了也不会有结果",end="=======",sep="*******",file=f) #把上面2个知识点也加进去 print(msg,"缺少毅力,奋斗不会有结果,没有坚持,但曾经拥有",end="=======",sep="*******",file=f) #证明是否换行
执行代码结果:(打开文件内显示结果)
缺少奋斗的人,是没有理想的*******缺少毅力的人,即使奋斗了也不会有结果=======缺少奋斗的人,是没有理想的*******缺少毅力,奋斗不会有结果,没有坚持,但曾经拥有=======
tuple() 转成元祖并把字符逐个分割
msg = "缺少奋斗的人是没有理想的" print(tuple(msg)) #打印加了内置函数后的结果
执行代码结果: ('缺', '少', '奋', '斗', '的', '人', '是', '没', '有', '理', '想', '的')
callable() 判断变量是否可调用(主要测试函数)
msg = "缺少奋斗的人是没有理想的" def clac(): a = 5 b = 7 a + b return a,b clac print(callable(msg)) #判断普通变量 print(callable((clac))) #判断函数变量(如果给了你一个变量,判断是否为函数的时候,可以用这样的方法解决)
执行代码结果: False #普通变量不可执行返错误 True #函数代码可执行返回正确
format() 格式化方法
len() 返回参数的长度
type() 查看数据类型
frozenset() 不可变的集合
s = {1,77,4,52,6,5,8}
s.pop() #随机删除1个值
print(s) #已成功删除
s = frozenset(s)
print(s.pop())
执行代码结果: {4, 5, 6, 8, 77, 52} #第一个print可正常打印 File "python学习第二模块第三章递归、内置函数.py", line 223, in <module> print(s.pop()) AttributeError: 'frozenset' object has no attribute 'pop'
#报错提醒经过 frozenset() 函数处理的变量不可被修改
list() 转成列表
range() 返回给定整数的列表(默认从小到大)
for i in range(8): #给定8的意思就是 >= 0 , <8 print(i)
执行代码结果:
0
1
2
3
4
5
6
7
vars() 返回当前编译器所有变量与对应的值
locals() 函数内打印局部变量,函数外打印全局变量(包含局部变量)
f = "wages" def calc(): n = 72 print(locals()) print(locals(),calc())
globals() 打印全局变量(不分函数内外)
repr() 以字符串形式返回对象
zip() 压缩(2合1)
a = [1,8,5] b = ["ca","vv","re","bb"] #设置2个不同长度的列表 c = dict(zip(a,b)) c1 = list(zip(a,b)) #可以设置不同类型创建压缩的对应值 print(c,c1) #列表内多余的值会丢弃(删除没有对应的值)
执行代码结果: {1: 'ca', 8: 'vv', 5: 're'} [(1, 'ca'), (8, 'vv'), (5, 're')]
reversed() 反转(默认反向排序
complex() 返回一个实数和一个虚数
round(1.555582,3 ) 设定浮点数的取值范围(2个参数,一个浮点数,一个要保留几位小数的值)
delattr(),hasattr(),getattr(),setattr() 面对对象四剑客,学对象时再说
hash("ssddde") 生成唯一的数字值
memoryview() 现在用不到(大数据拷贝的时候可以进行内存映射)
set() 转集合类型
n = (1,0,2,5,6,4,7,"wage","hello") #设一个元祖 n2 = [1,0,5,8,6,3,"yes","world"] #设一个列表 print(set(n)) print(set(n2))
执行代码结果: {0, 1, 2, 4, 5, 6, 7, 'hello', 'wage'} #元祖转成集合 {0, 1, 3, 'world', 5, 6, 8, 'yes'} #列表转成集合
**函数基础作业:
登录账号后修改个人信息:
choice = None def info(): _list = [] with open("成员信息","r",encoding="gbk") as f: for i in f: i = i.strip().split(",") _list.append(i) return _list _list = info() def wafe(nm, age, job, phone, time): print("""-------- 个人信息 -------- 1.姓名:%s 2.年龄:%s 3.职位:%s 4.电话:%s 5.入职时间:%s -----------end-----------""" % (nm,age,job,phone,time)) def revise(): for li in _list: if choice[0] == li[0]: _list.remove(li) _list.append(choice) with open("成员信息", "w", encoding="gbk") as f: for user in _list: f.write('%s ' % (','.join(user))) count = 0 while count < 3: name = input("user name:").strip() pas = input("pass word:").strip() for user in _list: if name == user[0] and pas == user[1]: choice = user print(""" --------------------welcome %s------------------------""" % name) while True: inp = input(""" 选择功能:( b返回 q 退出) 1、打印信息 2、修改信息 3、修改密码 >>>: """) if inp == "1": wafe(user[2], user[3], user[4], user[5], user[6]) pass elif inp == "2": while True: print(user) wafe(user[2], user[3], user[4], user[5], user[6]) inp2 = input("请输入要修改的编号:").strip() if inp2 == "1": print("当前名字:%s" % user[2]) ip1 = input("请输入新名字:").strip() choice[2] = ip1 revise() elif inp2 == "2": print("当前年龄:%s" % user[3]) ip2 = input("请输入新的年龄:").strip() choice[3] = ip2 revise() elif inp2 == "3": print("当前职位:%s" % user[4]) ip3 = input("请输入新职位:").strip() choice[4] = ip3 revise() elif inp2 == "4": print("当前电话为:%s" % user[5]) ip4 = input("请输入新的电话:").strip() choice[5] = ip4 revise() elif inp2 == "5": print("当前入职时间为:%s" % user[6]) ip5 = input("请输入新的入职时间:").strip() choice[6] = ip5 revise() elif inp2 == "b": break else: print("没有当前选项!") elif inp == "3": print("当前密码:%s" % user[1]) inp3 = input("请输入新密码:").strip() choice[1] = inp3 revise() elif inp == "q": exit() else: print("没有当前选项") else: print("输入错误请重试!") count += 1
————————————————————————结束线————————————————————————————