一、磁盘
磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘。
1、机械磁盘
机械磁盘主要由盘片和读写磁头组成,数据就存储在盘片的环状磁道中。
在读写数据前,需要移动读写磁头,定位到数据所在的磁道,然后才能访问数据。
2、固态磁盘(SSD)
由固态电子元器件组成。
固态磁盘不需要磁道寻址,所以,不管是连续 I/O,还是随机 I/O 的性能,都比机械磁盘要好得多。
二、文件系统
1、一切皆文件
“一切皆是文件”是 Unix/Linux 的基本哲学之一。
不仅普通的文件,目录、字符设备、块设备、 套接字等在 Unix/Linux 中都是以文件被对待,它们虽然类型不同,但是对其提供的却是同一套操作界面。
这么设计的好处就是你可以使用同一套api(read, write)和工具(cat , 重定向, 管道)来处理unix中大多数的资源.
在Linux 文件系统中,为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。
它们主要用来记录文件的元信息和目录结构
1)索引节点,简称为 inode,用来记录文件的元数据,不包含文件名信息
主要包含:文件的归属关系、读写权限、文件类型以及 inode 描述的 file 在磁盘存储的数据块地址等信息
目录对象的数据区中即保存了相关文件的文件名。
2)目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。
多个关联的目录项,就构成了文件系统的目录结构。
不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
2、磁盘的格式化
磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区
1、超级块,存储整个文件系统的状态。
2、索引节点区,用来存储索引节点。
3、数据块区,则用来存储文件数据。
磁盘读写的最小单位是扇区,大小512B大小,为了提高读写效率,文件系统把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。
常见的逻辑块大小为 4KB,也就是由连续的8个扇区组成
3、文件系统的分类
按照存储位置的不同,可以分为三类
1、基于磁盘的文件系统,如:Ext4、XFS、OverlayFS
2、基于内存的文件系统,如:tmpfs
3、网络文件系统,如:NFS、SMB、iSCSI
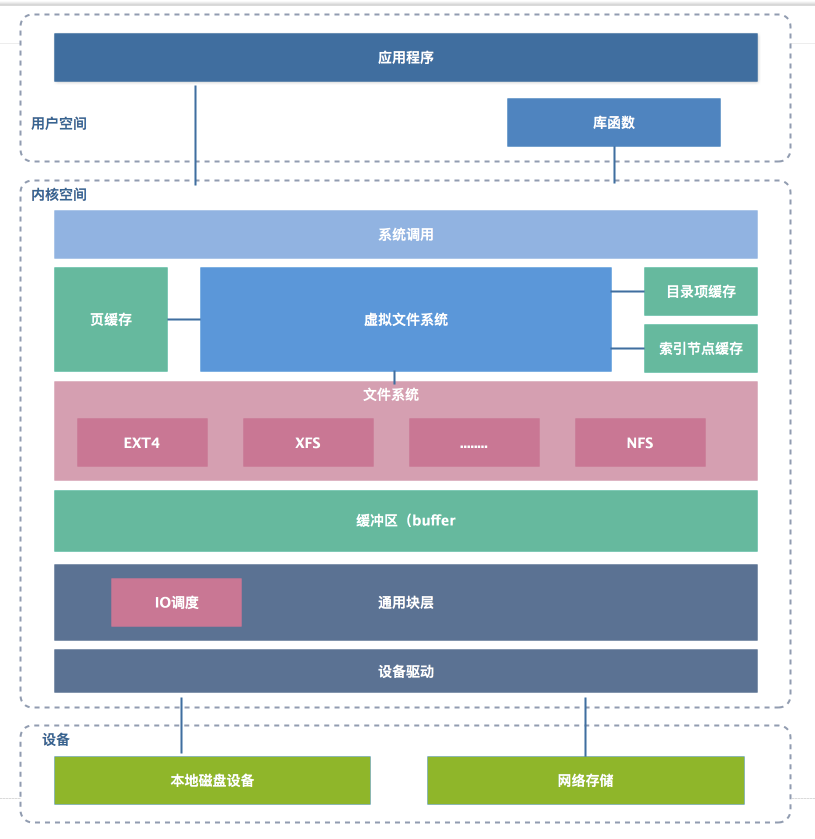
三、虚拟文件系统
操作系统中可以同时存在多种文件系统,为了方便管理,使用虚拟文件系统来进行统一的管理。
1、VFS(Virtual Filesystem Switch)
虚拟文件系统或虚拟文件系统转换,在具体的文件系统之上抽象的一层,定义了一组所有文件系统都支持的数据结构和标准接口,为用户进程和内核中的其他子系统访问文件系统提供一个通用的接口,屏蔽底层各种文件系统的实现细节。
2、统一文件模型
VFS的文件模型定义了四种对象,这四种对象构建起了统一文件模型。
1)superblock:存储文件系统基本的元数据。如文件系统类型、大小、状态,以及其他元数据相关的信息
2)inode:保存一个文件相关的元数据。包括文件的所有者(用户、组)、访问时间、文件类型等,但不包括这个文件的名称。文件和目录均有具体的inode对应
3)dentry:保存了文件(目录)名称和具体的inode的对应关系,用来粘合二者,同时可以实现目录与其包含的文件之间的映射关系。另外也作为缓存的对象,缓存最近最常访问的文件或目录,提示系统性能
4)file:一组逻辑上相关联的数据,被一个进程打开并关联使用
统一文件模型是一个标准,各种具体文件系统的实现必须以此模型定义的各种概念来实现。
四、通用块层
为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能 。
第一个功能跟虚拟文件系统的功能类似。
向上,为文件系统和应用程序,提供访问块设备的标准接口;
向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
五、IO调度算法
1、IO调度的原理
通过IO的合并或者重排,提高硬件设备的性能
2、调度算法
1)NONE
NONE ,更确切来说,并不能算 I/O 调度算法。
因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
2)CFQ
完全公平排队I/O调度程序
它试图为竞争块设备使用权的所有进程分配一个请求队列和一个时间片,在调度器分配给进程的时间片内,进程可以将其读写请求发送给底层块设备,当进程的时间片消耗完,进程的请求队列将被挂起,等待调度。
每个进程的时间片和每个进程的队列长度取决于进程的IO优先级,每个进程都会有一个IO优先级,CFQ调度器将会将其作为考虑的因素之一,来确定该进程的请求队列何时可以获取块设备的使用权。
3)NOOP
NOOP实现了一个简单的FIFO队列,它像电梯的工作主法一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质.NOOP倾向饿死读而利于写.
电梯算法饿死读请求的解释:
因为写请求比读请求更容易.写请求通过文件系统cache,不需要等一次写完成,就可以开始下一次写操作,写请求通过合并,堆积到I/O队列中.
读请求需要等到它前面所有的读操作完成,才能进行下一次读操作.在读操作之间有几毫秒时间,而写请求在这之间就到来,饿死了后面的读请求.
4)Deadline
deadline实现了四个队列,其中两个分别处理正常read和write,按扇区号排序,进行正常io的合并处理以提高吞吐量.
因为IO请求可能会集中在某些磁盘位置,这样会导致新来的请求一直被合并,于是可能会有其他磁盘位置的io请求被饿死。
于是实现了另外两个处理超时read和write的队列,按请求创建时间排序,如果有超时的请求出现,就放进这两个队列,调度算法保证超时(达到最终期限时间)的队列中的请求会优先被处理,防止请求被饿死。