一、算法详解
1.什么是K临近算法
- Cover 和 Hart在1968年提出了最初的临近算法
- 属于分类(classification)算法
- 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。
- 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
- kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
- 该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
- kNN方法在类别决策时,只与极少量的相邻样本有关。
- 由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
- 输入基于实例的学习(instance-based learning),懒惰学习(lazy learning)
2.算法流程
对每一个未知点执行:(为了判断未知实例的类别,以所有已知类别的实例作为参照)
-
- 选择参数 K
- 计算未知点到所有已知类别点的距离
- 按距离排序(升序)
- 选取与未知点离得最近的K个的点
- 统计k个点中各个类别的个数
- 根据少数服从多数的投票法则,上述k个点里类别出现频率最高的作为未知点的类别
3. 算法细节-关于K的计算
K:临近数,即在预测目标点时取几个临近的点来预测。
K值得选取非常重要,因为:
- 如果当K的取值过小时,一旦有噪声得成分存在们将会对预测产生比较大影响,例如取K值为1时,一旦最近的一个点是噪声,那么就会出现偏差,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果K的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大。这时与输入目标点较远实例也会对预测起作用,使预测发生错误。K值的增大就意味着整体的模型变得简单;
- 如果K==N的时候,那么就是取全部的实例,即为取实例中某分类下最多的点,就对预测没有什么实际的意义了;
- K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。
K的取法:
- 常用的方法是从k=1开始,使用检验集估计分类器的误差率。重复该过程,每次K增值1,允许增加一个近邻。选取产生最小误差率的K。
- 一般k的取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大。
4. 算法细节-关于距离的计算
距离就是平面上两个点的直线距离
关于距离的度量方法,常用的有:欧几里得距离、余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)或其他。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:
欧氏距离:
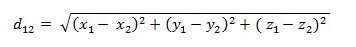
曼哈顿距离:
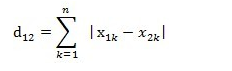
5.算法优缺点
优点:
简单有效、易理解、易于实现,无需估计参数,无需训练
适合对稀有事件进行分类
特别适合于多分类问题,KNN比SVM表现要好
缺点:
需要大量空间储存所有的已知实例。(k近邻需要保存全部数据集,因此对内存消耗大,当数据集较大时对设备要求非常高)
算法计算量较大(需要计算每个未知点到全部已知点的距离,可能会很耗时 )
当样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归为这个主导样本(因为这类样本实例的数量过大,但这个新的未知实例实际并未接近目标样本)
针对上述缺点,采用权值得方法,根据距离加上权重,比如1/d(d:距离),这样一来,距离越近,所占的比重就会增加。
二、利用sklearn中模块实现KNN
1. 数据集的介绍
- Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。
- Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
- 数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。
- 可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
iris以鸢尾花的特征作为数据来源,常用在分类操作中。该数据集由3种不同类型的鸢尾花的50个样本数据构成。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的。
该数据集包含了5个属性:
& Sepal.Length(花萼长度),单位是cm;
& Sepal.Width(花萼宽度),单位是cm;
& Petal.Length(花瓣长度),单位是cm;
& Petal.Width(花瓣宽度),单位是cm;
& 种类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),以及Iris Virginica(维吉尼亚鸢尾)。
2.利用sklearn中的KNN库实现KNN
scikit-learn 中KNN相关的类库概述
在scikit-learn 中,与近邻法这一大类相关的类库都在sklearn.neighbors包之中。
KNN分类树的类是KNeighborsClassifier,KNN回归树的类是KNeighborsRegressor。
除此之外,还有KNN的扩展,即限定半径最近邻分类树的类RadiusNeighborsClassifier和限定半径最近邻回归树的类RadiusNeighborsRegressor, 以及最近质心分类算法NearestCentroid。
sklearn中自带iris的数据集,可以直接调用来实现分类功能
代码实现:
from sklearn import neighbors from sklearn import datasets knn = neighbors.KNeighborsClassifier() #调用KNN分类器 iris = datasets.load_iris() #载入iris数据集 print("featureList: " + " " + str(iris.data)) print("labelList: " + " " + str(iris.target)) knn.fit(iris.data, iris.target) #将数据传入Knn分类器 predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]]) #进行预测 print ("predictedLabel is : " + str(predictedLabel)) #打印预测结果
三、利用Python程序自己实现KNN
1 import csv 2 import random 3 import math 4 import operator 5 6 #载入数据集 7 def loadDataset(filename, split, trainingSet=[], testSet=[]): 8 with open (filename) as csvfile: 9 lines = csv.reader(csvfile) 10 dataset = list(lines) 11 for x in range(len(dataset)-1): 12 for y in range(4): 13 dataset[x][y] = float(dataset[x][y]) 14 if random.random() < split: #通过split比较,随机将数据集分成训练集(占约三分之二)和测试集(占约三分之一) 15 trainingSet.append(dataset[x]) 16 else: 17 testSet.append(dataset[x]) 18 19 #计算任意两个实例间的欧氏距离 20 def euclideanDistance(instance1, instance2, length): 21 distance = 0 22 for x in range(length): #实现任意维度距离的计算 23 distance += pow((instance1[x]-instance2[x]), 2) 24 return math.sqrt(distance) 25 26 #获取待测实例最临近的K个已知点 27 def getNeighbors(trainingSet, testInstance, k): 28 distances = [] 29 length = len(testInstance)-1 30 for x in range(len(trainingSet)): 31 dist = euclideanDistance(testInstance, trainingSet[x], length) #计算每一个待测实例与已知实例的欧氏距离 32 distances.append((trainingSet[x], dist)) 33 distances.sort(key=operator.itemgetter(1)) #list.sort(*, key=None, reverse=None),sort()是Python列表的一个内置的排序方法,key是带一个参数的函数,返回一个值用来排序,默认为 None。reverse表示排序结果是否反转 34 neighbors = [] 35 for x in range(k): 36 neighbors.append(distances[x][0]) 37 return neighbors 38 39 #每一个测试实例所对应的分类结果根据临近样本的结果进行获取(少数服从多数原则) 40 def getResponse(neighbors): 41 classVotes = {} 42 for x in range(len(neighbors)): 43 response = neighbors[x][-1] #测试实例周围已知实例的结果获取 44 if response in classVotes: 45 classVotes[response] += 1 46 else: 47 classVotes[response] = 1 48 sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) 49 return sortedVotes[0][0] 50 51 #测试集准确率的计算 52 def getAccuracy(testSet, predictions): 53 correct = 0 54 for x in range(len(testSet)): 55 if testSet[x][-1] == predictions[x]: 56 correct += 1 57 return (correct/float(len(testSet)))*100.0 58 59 def main(): 60 trainingSet = [] 61 testSet = [] 62 split = 0.70 63 loadDataset(r'irisdata.txt', split, trainingSet, testSet) #数据集载入 64 print('Train set: ' + repr(len(trainingSet))) 65 print('Test set: ' + repr(len(testSet))) 66 67 predictions = [] 68 k = 3 #选3个临近的样本点 69 for x in range(len(testSet)): 70 neighbors = getNeighbors(trainingSet, testSet[x], k) 71 result = getResponse(neighbors) 72 predictions.append(result) 73 print('>predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1])) 74 accuracy = getAccuracy(testSet, predictions) 75 print('Accuracy: ' + repr(accuracy) + '%') 76 77 if __name__ == '__main__': 78 main() 79
执行结果:


Train set: 106 Test set: 44 >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-setosa', actual='Iris-setosa' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-virginica', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-versicolor', actual='Iris-versicolor' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' >predicted='Iris-virginica', actual='Iris-virginica' Accuracy: 97.72727272727273%