在日常开发工作中,我们经常会使用到XML,早已成为了一种标准。它的用途非常的广泛,但这些不是本文所重点讨论的。
相信大家在做开始时候经常碰到过“乱码”的问题,这是中国程序员非常头疼的问题。我一直很想深入研究关于“编码”的原理,无奈水平有限,那些枯燥的理论(二进制,ASCII,Unicode,UTF-8,gb2312,ISO ...光这些就让我看的两眼发黑了),实在看不下去,也很难真正搞懂搞明白。望各位网友多指点......
我将用工作中遇到的一个“XML文件乱码”的简单问题,解决问题,分析其背后的原理。
首先,我们在本地新建一个文本文件,将后缀名改为".XML”, 然后用用记事本打开,往里面添加一些符合XML文档规范的内容。如图所示:
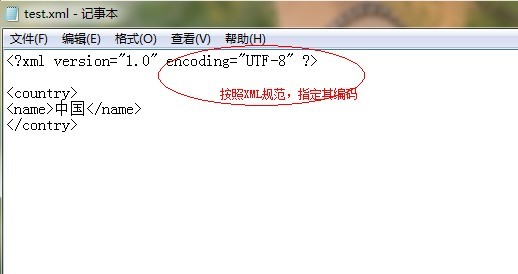
写好之后,按“ctrl+s”保存,然后使用IE浏览器打开该XML文件,验证该XML文档的规范及正确性。不料,居然解析出错了,如下:

这是咋回事呢?我的XML文档定义的格式好像没问题啊。无效字符?这肯定是典型的“编码”问题了。聪明的我第一就想到了,调整IE浏览器的“编码”嘛。
可是打开“查看”“编码”,发现那些编码格式全是灰色的,好像不能选择哦。这是因为,在定义XML文档的时候,指定了编码格式为"UTF-8",这就相当于告诉了浏览器(XML解析引擎):你必须使用"UTF-8"编码去解析我,所以无法使用其他的编码格式去查看了。
这是因为,我们在使用记事本保存该文档的时候,没有选择编码格式,默认使用的是操作系统编码(中文版的系统),也就是对应的"GB2312”编码。当我们的IE浏览器,再使用我们指定的UTF-8编码去解析该XML文档的时候,出现了乱码,所以造成了上面的错误。(Windows中的文件保存在硬盘上,默认使用操作系统编码。比如我们XML文档中定义的“中国”这两个字,保存好后,假如其对应的GB2312可能是"10001",而在UTF-8编码中的,“10001”对应的就不是“中国”了,要么找不到,要么是乱码,所以IE就拒绝显示了)。那我们应该怎么办呢?有两种办法可以解决。
第一,我们在xml文档定义时,指定其编码为gb2312,如下图所示:
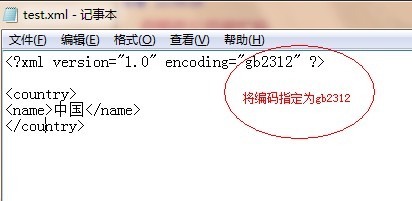
保存之后,我们再使用IE浏览器打开,结果如图:
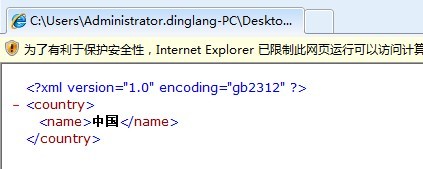
恭喜,这个问题解决了。但是这种方法不推荐使用。因为我们在定义XML文档时候,为了文档的通用性,我们一般使用UTF-8编码。
第二种方法:
我们再用记事本打开该文档,点击“另存为”,发现下面会有“编码”选项,选择“UTF-8”之后再试。
其实,我们在使用诸如 Eclipse 或者Microsoft Visual Studio之类的开发工具来定义XML文档,并不会碰到上面的问题。原因是这些IDE都非常“聪明”,你的XML文档指定的是那种编码格式,IDE在将XML文档保存到硬盘的时候,就自动使用那种格式。所以,很多局限于使用某种IDE开发的程序员,其实并不明白这些知识及其背后的原理,但他们做开发起来一样很顺手。早年据笔者了解,国内有很多大牛,写代码都是用EditPlus之类的文本编辑器,而那些在Linux/unix上面的大牛,很多都是用VI/VIM来编码。大概这就是差距吧。(呵呵。当然这不是本文讨论的重点)
补充一点理论知识,不晕的就继续读下去吧。
在最初的时候,Internet上只有一种字符集——ANSI的ASCII字符集,它使用7 bits来表示一个字符,总共表示128个字符,其中包括了英文字母、数字、标点符号等常用字符。之后,又进行扩展,使用8 bits表示一个字符,可以表示256个字符,主要在原来的7 bits字符集的基础上加入了一些特殊符号例如制表符。
后来,由于各国语言的加入,ASCII已经不能满足信息交流的需要,因此,为了能够表示其它国家的文字,各国在ASCII的基础上制定了自己的字符集,这些从ANSI标准派生的字符集被习惯的统称为ANSI字符集,它们正式的名称应该是MBCS(Multi-Byte Chactacter System,即多字节字符系统)。这些派生字符集的特点是以ASCII 127 bits为基础,兼容ASCII 127,他们使用大于128的编码作为一个Leading Byte,紧跟在Leading Byte后的第二(甚至第三)个字符与Leading Byte一起作为实际的编码。这样的字符集有很多,我们常见的GB-2312就是其中之一。
而其UTF-8编码为:E8 BF 9E E9 80 9A
开头字节 Charset/encoding
EF BB BF UTF-8
FE FF UTF-16/UCS-2, little endian
FF FE UTF-16/UCS-2, big endian
FF FE 00 00 UTF-32/UCS-4, little endian.
00 00 FE FF UTF-32/UCS-4, big-endian.
例如插入标记后,连通”两个字的UTF-16 (big endian)和UTF-8码分别为:
FF FE DE 8F 1A 90
EF BB BF E8 BF 9E E9 80 9A
但是MBCS文本没有这些位于开头的字符集标记,更不幸的是,一些早期的和一些设计不良的软件在保存Unicode文本时不插入这些位于开头的字符集标记。因此,软件不能依赖于这种途径。这时,软件可以采取一种比较安全的方式来决定字符集及其编码,那就是弹出一个对话框来请示用户,例如将那个“连通”文件拖到MS Word中,Word就会弹出一个对话框。
如果软件不想麻烦用户,或者它不方便向用户请示,那它只能采取自己“猜”的方法,软件可以根据整个文本的特征来猜测它可能属于哪个charset,这就很可能不准了。使用记事本打开那个“连通”文件就属于这种情况。
我们可以证明这一点:在记事本中键入“连通”后,选择“Save As”,会看到最后一个下拉框中显示有“ANSI”,这时保存。当再当打开“连通”文件出现乱码后,再点击“File”->“Save As”,会看到最后一个下拉框中显示有“UTF-8”,这说明记事本认为当前打开的这个文本是一个UTF-8编码的文本。而我们刚才保存时是用ANSI字符集保存的。这说明,记事本猜测了“连通”文件的字符集,认为它更像一个UTF-8编码文本。这是因为“连通”两个字的GB-2312编码看起来更像UTF-8编码导致的,这是一个巧合,不是所有文字都这样。可以使用记事本的打开功能,在打开“连通”文件时在最后一个下拉框中选择ANSI,就能正常显示了。反过来,如果之前保存时保存为UTF-8编码,则直接打开也不会出现问题。
如果将“连通”文件放入MS Word中,Word也会认为它是一个UTF-8编码的文件,但它不能确定,因此会弹出一个对话框询问用户,这时选择“简体中文(GB2312)”,就能正常打开了。记事本在这一点上做得比较简化罢了,这与这个程序的定位是一致的。